
RPT:拿强化学习做 LLM 预训练
结合预训练的规模优势与强化学习的决策优势
论文标题
Reinforcement Pre-Training
论文地址
https://arxiv.org/pdf/2506.08007
作者背景
微软研究院,北京大学,清华大学
动机
Yann Lecun曾在前几年的演讲中,多次将人工智能比作一块蛋糕,其中无监督学习是蛋糕的本体,监督学习是蛋糕上面的糖霜,而强化学习则是中间点缀的樱桃
这一比喻体现了三种训练方法的差异:无监督预训练能够从海量数据中获取稠密的学习信号,适合作为模型的基础部分;监督训练利用带人工标注的数据让模型学会具体的任务,实现对智能体的“塑形”;强化学习赋予了模型自主探索的能力,但因反馈信息非常稀疏,只能作为精致而少量的“点缀”
进入大模型时代,强化学习的重要性越发明显,但当前的主流做法还是将其应用于微调阶段,并且难以推动规模化训练:RLHF(对齐人类偏好)虽然效果显著,但训练数据需要精心构造,成本较大且容易发生奖励劫持;RLVR(对齐验证结果)虽然缓解了 RM 失真的问题,某些场景下(比如编程)可以只构建环境而不用标注数据,但其应用范围非常有限(大部分工作都是数学、编程、推理领域),无法作为通用方案扩展
于是作者提出了强化预训练(Reinforcement Pre-Training),在预训练阶段引入强化学习信号,融合自监督学习的规模优势与强化学习的决策优势,构建规模可扩展的通用预训练新范式。就好比直接拿樱桃做蛋糕

本文方法
预训练的规模优势源于自回归方法能通过 Next Token Prediction 充分利用海量的无监督数据,所以 RPT 的核心思想就是用强化学习的方式做 NTP 任务:

如上图所示,RPT 将 NPT 视作推理任务:对于每个 Next Token 的预测,都先生成一段思考,再输出最终答案(也可以一次性预测多个token);验证时如同常规 RLVR 一样,对比预测结果与语料中的真实词是否严格一致,进而产生奖励(0或1)。通过这种设计,海量未标注文本就转化为了规模空前的强化学习训练数据
作者实际上尝试了多种奖励设计,包括未完全命中时使用预言模型概率代替0作为奖励等,后续实验结果差不多,所以最终选择了上述最简单的做法
考虑到大部分 token 无需推理便可轻松预测,作者使用了一个代理模型来做筛选,具体地,使用小尺寸的 DeepSeek-R1-Distill-Qwen-1.5B 计算每次 NTP 任务中,top-16候选词概率分布形成的熵,过滤掉熵值较低的简单 token,生成更具挑战性的训练任务。这样便模拟了人类对复杂问题的表述过程:在某些关键结点“边说边想”
最后,使用 Deepseek-R1-Distill-Qwen-14B 作为基础模型,作为强化学习的一个良好起点,使用 verl 实现训练框架,并使用 vllm 进行推理。使用 GRPO 算法更新策略模型,训练长度 8k,学习率 1×10^−6,去除 KL 惩罚,batch-size为 256,每个问题采样8次,温度0.8,500 步以后使用动态采样,总共训练 1000 步
实验结果
为了让模型获得更强的推理能力,作者在需要大量推理的数学竞赛数据集 OmniMATH 上做上述强化预训练,然后分别验证预训练效果、模型 zero-shot 能力、对下游任务训练效果的影响,以及 RPT 训练对 LLM 行为模式的具体改变
一、预训练效果
预训练效果由 NTP 任务准确率来衡量,在不同难度的预测任务上(难度通过上述 top-16 熵来衡量)效果如下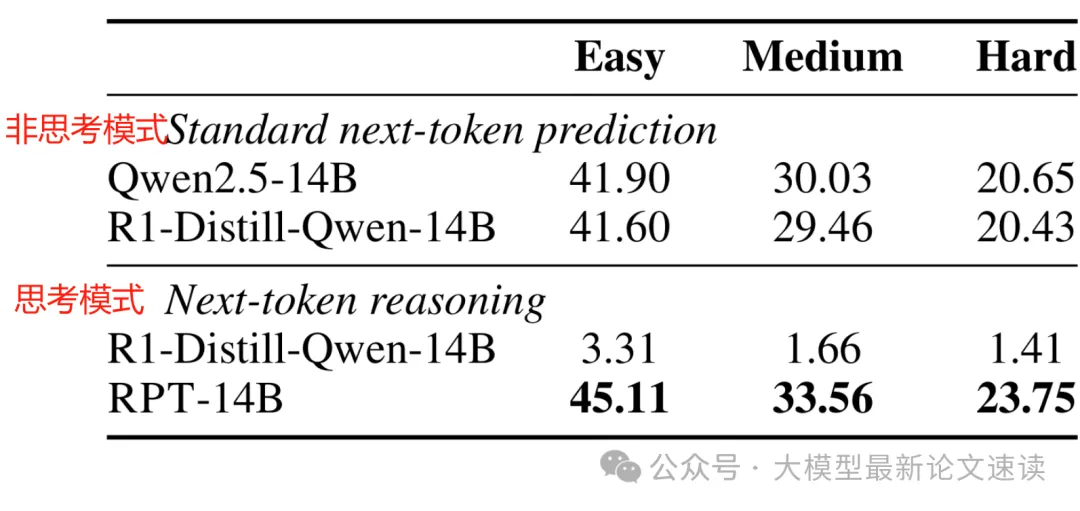
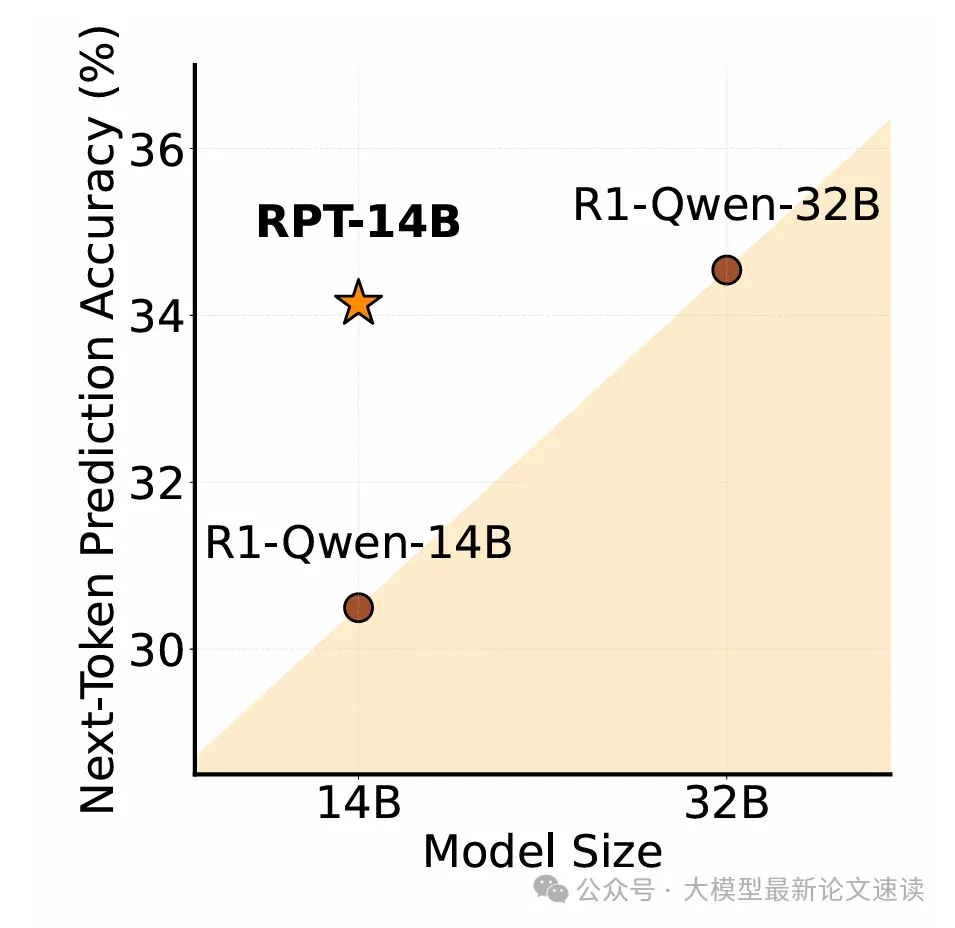
可见经过强化预训练的模型,NTP 能力明显提升,与更大尺寸的模型效果相当,并且符合幂律,意味着可以投入更大计算成本,RPT 便能取得更好的预训练效果
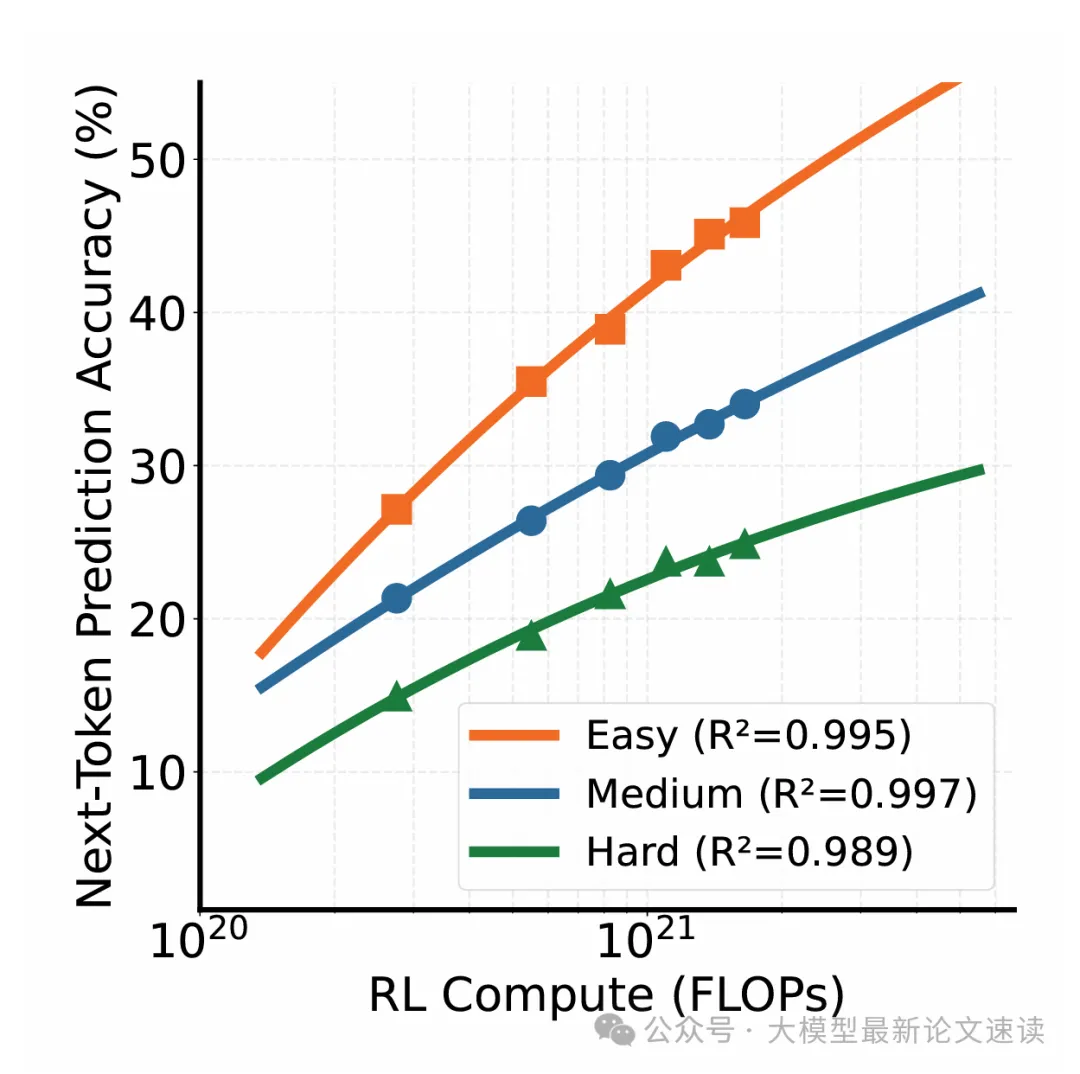
应该是受限于计算资源,上图只展示了一个指数刻度内的 NTP 准确性,不知道这里能否像 LLM 预训练一样有一根很长的幂律曲线
此外,NTP 上满足幂律,能否像 LLM 一样使下游任务受益,论文也未作探讨
二、预训练改变的行为模式
作者统计了 RPT 前后模型在做 NTP 推理时行为模式的变化,具体地,统计了六种思维方式的出现频率:
- 转移: 策略切换
- 反思: 自我检查
- 分解: 问题拆分
- 假设: 提出并验证假设
- 发散思维: 探索可能性
- 演绎: 逻辑推理
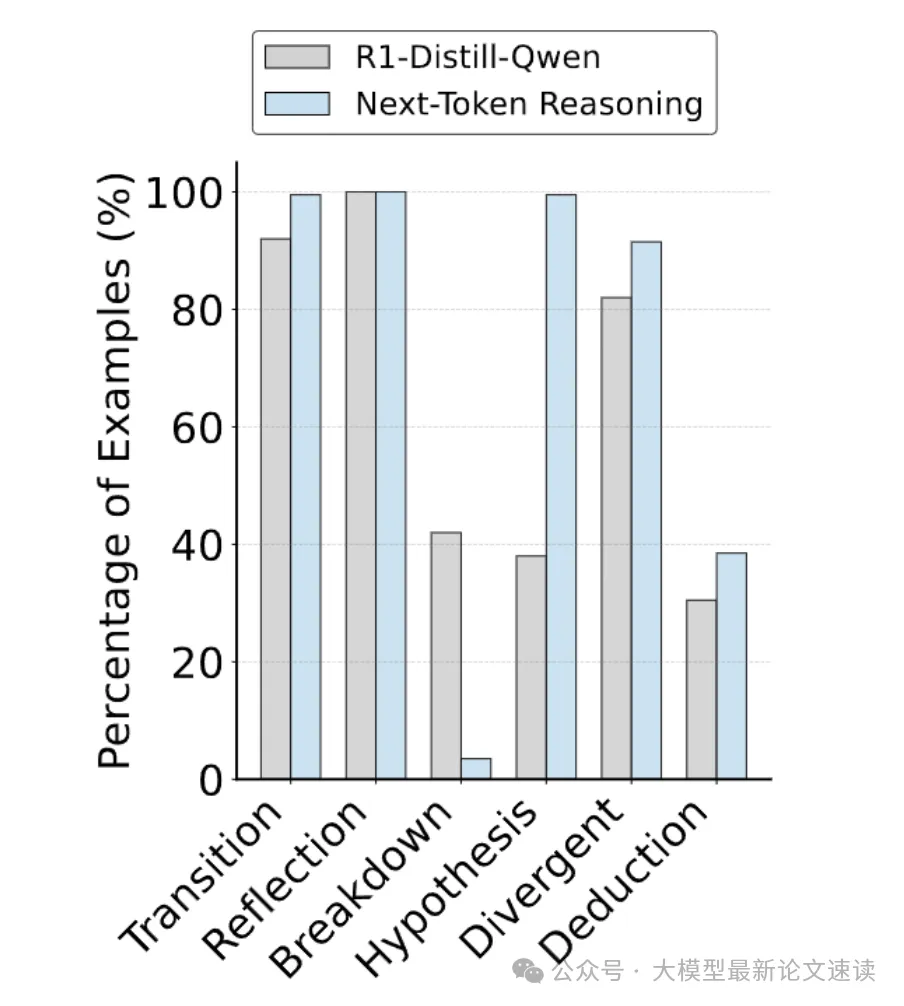
如上图所示,RPT 模型在推理时,假设模式的使用率高出 161.8%,演绎模式的使用率高出 26.2%;相比之下,RPT 前的模型更依赖于分解模式,这表明 RPT 的确显著改变了模型的推理形式
三、下游任务 zero-shot 效果
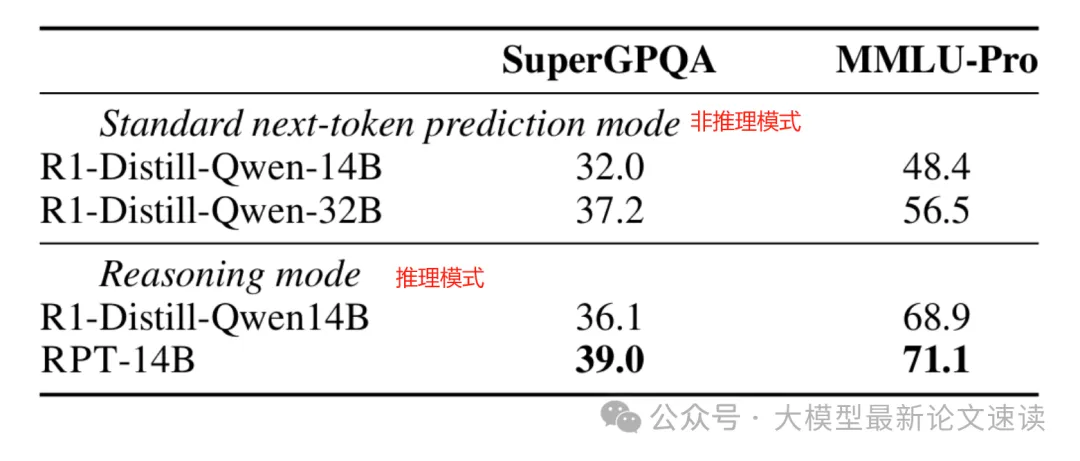
在 MMLU-Pro(全面的多任务理解基准)与 SuperGPQA(涵盖 285 个学科的大规模研 究生水平推理问题基准)上进行 zero-shot 测试,结果表明经过 RPT 训练(而且是在与测试问题无关的其他领域),模型获得了更好的推理能力
四、下游任务 RL 效果
作者在 Skywork-OR1(昆仑万维发布的数学、代码数据集)上进行 RL 训练,最终效果如下表所示,其中第二行是指在 RL 训练前先对模型进行 NTP 的微调训练(模拟 RLHF 流程)

可见如果 RPT 是在类似领域上做的预训练,那么对下游的 RL 训练将会有明显的改进
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)