
RLPD——利用离线数据实现高效的在线RL:不进行离线RL预训练,直接应用离策略方法SAC,在线学习时对称采样离线数据
摘要:本文介绍了两项强化学习前沿工作RLPD和RLDG。RLPD提出了一种高效融合离线数据的在线强化学习方法,通过"对称采样"机制(50%在线数据+50%离线数据)和层归一化技术,有效缓解了价值函数过度外推问题,在多个基准测试中实现了SOTA性能。RLDG则采用知识蒸馏框架,先训练精密任务RL策略生成数据,再微调视觉语言模型,性能超越人类演示数据。两项工作分别从数据利用效率和知
前言
之所以写此文,原因在于下面两篇文章都涉及到本文要介绍的RLPD
- UC伯克利HIL-SERL——结合视觉和人类示教与纠正的RL方法(直接真实环境中RL开训,可组装电脑主板和插拔USB)
- RLDG——RL知识蒸馏通用体:先基于精密任务训练RL策略,后让其自动生成数据,最后微调VLA,效果超越人类演示数据
正因为其重要些,故写本文
RLPD『Ball等,2023,即Efficient online reinforcement learning with offline data,相当于利用离线数据实现高效的在线RL,即Online RL with Offline Data 』,之所以选择它,是因为其样本效率高,且能够融合先验数据
- 该工作关注的是,是否可以在在线学习时,直接应用现有的离策略方法以充分利用离线数据,作者从头开始在线强化学习,同时将离线数据包含在回放缓冲区中,从而展示了online off-policy RL algorithms利用离线数据进行学习时表现出极高的效率
- 且在每一步训练中,RLPD 在先验(离线)数据和on-policy数据之间等概率采样,以形成一个训练批次「Song等,2023——Hybrid RL: Using both offline and online data can make RL efficient」
即“对称采样”,即每个批次有50%的数据来自(在线)回放缓冲区,另外50%来自离线数据缓冲区「We call this ‘symmetric sampling’, whereby for each batch we sample 50% of the data from our replay buffer, and the remaining 50% fromthe offline data buffer」
第一部分 RLPD:基于先验数据的强化学习
1.1 引言、相关工作
1.1.1 引言
如原论文所说,深度强化学习(RL)在多个复杂领域取得了成功,例如Atari(Mnih等,2015)和围棋(Silver等,2016),以及现实世界中的应用,如芯片设计(Mirhoseini等,2021)和人类偏好对齐(Ouyang等2022,即instructGPT,详见此文)
- 在许多这些场景中,强化学习的优异表现依赖于与环境进行大量的在线交互,这通常通过使用模拟器来实现
然而,在实际问题中,常常面临样本获取成本高昂的情况。此外,奖励信号稀疏,且高维的状态和动作空间往往使这一问题更加严重 - 解决该问题的一种有前景的方法,是在训练深度强化学习算法时,纳入由先前策略或人类专家生成的数据——通常被称为离线数据(Levine 等2020,即Offline reinforcement learning: Tutorial, review, and perspectives onopen proble)
理论上
Wagenmaker & Pacchiano 2022,即Leveraging offline data in online reinforcement learning
Song等2023,即Hybrid RL: Using both off line and online data can make RL efficient
以及现实案例中
Cabi等2019,即caling data-drivenrobotics with reward sketching and batch reinforcementlearning
Nair 等2020,即AWAC:Accelerating online reinforcement learning with offlinedatasets
Lu 等,2021,即Challenges and oppor-tunities in offline reinforcement learning from visualobservations
均已证实,这一做法可以通过为算法提供初始数据集来“启动”学习过程,从而缓解样本效率和探索方面的挑战
该初始数据集可以是高质量的专家演示,甚至是低质量但覆盖面广的探索性轨迹。此外,这也为作者利用大量预先收集的数据集以学习有用的策略提供了途径
一些先前的研究致力于通过预训练利用这些数据,而其他方法则在在线训练时引入约束,以应对分布转移问题。然而,每种方法都有其缺点,例如需要额外的训练时间和超参数,或者在行为策略之外的提升有限
回过头来看,来自1 University of Oxford、2 UC Berkeley的研究者Philip J. Ball * 1 Laura Smith * 2、Ilya Kostrikov *2、Sergey Levine 2注意到
- “ 标准的离策略算法本应能够利用这些离线数据,此外相关问题在该场景下,由于可以在线探索环境,因此分布偏移的问题应当得到缓解 ”
- 然而,迄今为止,此类方法在该问题设定下取得的成功有限。因此,在本研究中,作者提出如下问题:在不进行离线强化学习预训练或显式的模仿项以优先利用先前离线数据的情况下,是否可以直接应用现有的离策略方法(比如SAC),在在线学习时充分利用离线数据?
通过在一系列广泛研究的基准测试上进行详尽的实验,作者宣称,他们证明了这个问题的答案是肯定的
然而,直接应用现有的online off-policy RL算法可能会导致相对较差的性能,正如图1中‘SAC + 离线数据’与‘IQL + 微调’的对比所示
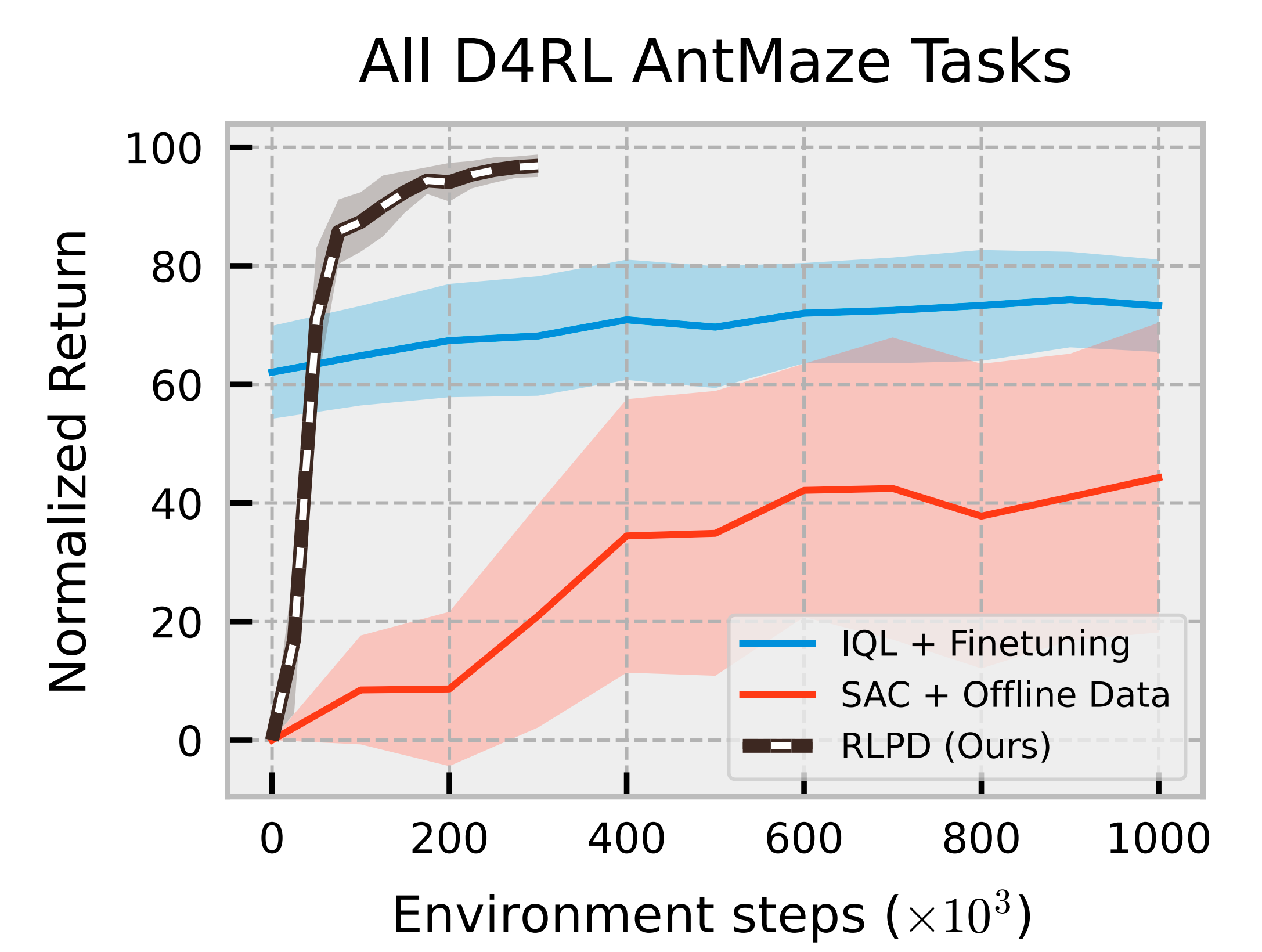
因此,必须考虑一组关键的设计选择,才能确保算法的成功
- 具体来说,作者首先提出了一种极其简单的离线数据采样方法,称之为“对称采样”,该方法在多种领域中无需超参数调整即可表现良好
- 接着,作者发现,在复杂场景——例如稀疏奖励、离线数据量少、高维度等下,必须防止价值函数的过度外推
为此,作者从一个新颖的视角分析了层归一化(LayerNormalization,Ba等,2016)如何在隐式上防止灾难性的价值过度外推,从而在许多场景下极大地提升了样本效率与稳定性,同时对现有方法的改动最小
然后,为了提升离线数据的利用效率,作者整合并比较了最新的高效无模型强化学习进展,发现大规模集成方法在多种领域中都表现出色
总之,作者展示了在线离策略(online off-policy)RL算法在利用离线数据进行学习时表现出极高的效率。然而,作者也指出,其可靠性能依赖于若干关键的设计选择
- 即离线数据的采样方式、对评论者critic更新进行关键归一化的方法,以及利用大型集成模型以提升样本效率
并最终发布此篇论文《Efficient Online Reinforcement Learning with Offline Data》,其Submitted on 6 Feb 2023 (v1), last revised 31 May 2023 (this version, v4),简称RLPD - 尽管 RLPD 的各个组成部分只是对现有强化学习组件的简单改进,作者宣称他们却证明了这些要素的组合能够在多个主流的基于离线数据的在线强化学习基准测试中实现最先进的性能
1.1.2 相关工作
首先,对于离线RL预训练
- 作者注意到与离线强化学习的联系
Ernst 等2005,即Tree-based batchmode reinforcement learning
Fujimoto 等2019,即Off-policy deep reinforcement learning without exploration
Levine等2020,即Offline reinforcement learning: Tutorial, review, and perspectives onopen proble
许多先前的研究采用离线强化学习,随后进行在线微调
Hester 等2018,即Deep q-learning from demonstrations
Kalashnikov 等2018,即Scalable deep reinforce-ment learning for vision-based robotic manipulation
Nair 等,2020,即AWAC:Accelerating online reinforcement learning with offline datasets
Lee 等2021,即Offline-to-online reinforcement learning via balanced replay andpessimistic q-ensemble
Kostrikov 等2022,即Offline reinforcementlearning with implicit q-learning. - 值得注意的是,Lee 等2021(即Offline-to-online reinforcement learning via balanced replay andpessimistic q-ensemble)
在进行在线学习时,也考虑了大规模集成和每步多次梯度更新的机制
然而,RLPD的方法采用了更为简洁的采样机制,无需超参数设置,并且不依赖于代价高昂的离线预训练,这通常会引入更多超参数
作者还强调,他们的归一化更新方法并不是一种离线强化学习方法——即没有进行任何离线预训练,而是从头开始在线强化学习,同时将离线数据包含在回放缓冲区中
其次,对于约束于先前数据的工作
- 离线强化学习预训练范式的另一种替代方法是,明确约束在线智能体的更新,使其行为表现类似于离线数据
Levine & Koltun,2013,即Guided policy search
Fox 等2016,即Taming the noise inreinforcement learning via soft update
Hester 等2018,即Deep q-learning from demonstra-tions
Nair等2018a,即Over coming exploration in reinforcement learning with demonstration
Rajeswaran 等2018,即Learning Complex Dexterous Manipulation with Deep Reinforcement Learn-ing and Demonstration
Rudner 等2021,即On pathologies in KL-regularized reinforcement learningfrom expert demonstrations
与RLPD方法特别相关的是Rajeswaran等人(2018)的工作,他们在策略梯度更新中加入了一个显式包含示范数据的加权更新
相比之下,作者采用的是一种样本高效的离策略范式,并且不进行任何预训练 - 与RLPD相似的还有Nair等人2018a),他们同样使用了带有固定离线回放缓冲区的离策略算法。然而,作者并未通过行为克隆项来限制策略,也不会重置到示范状态
此外,作者注意到这些方法通常要求离线数据具有较高质量,即“从示范数据中学习”
Asada & Hanafusa,1979,即Playback control of forceteachable robots
Schaal, 1996,即Learning from demonstration
而RLPD则重要的是对数据质量不敏感
最后,对于无约束方法结合先验数据
已有研究还探讨了在没有任何约束的情况下整合离线数据的方法
- 一些方法侧重于用离线数据初始化回放缓冲区
Veˇcer´ık 等,2017,即Leveraging demonstrations for deep reinforcementlearning on robotics problems with sparse rewards
Hester 等2018年,即Deep q-learning from demonstra-tions - 而其他研究则采用了平衡采样策略来处理在线与离线数据
Nair等2018b,即Overcoming exploration in reinforcementlearning with demonstrations
Kalashnikov等2018,即Scalable deep reinforce-ment learning for vision-based robotic manipulation
Hansen等2022,即Modem: Accelerating visual model-based reinforcement learning with demonstrations
Zhang等2023,即Policy expansion for bridgingoffline-to-online reinforcement learning - 最近,Song等人2023(即Hybrid RL: Using both offline and onlinedata can make RL efficient)对这类方法进行了理论分析,表明平衡采样在理论和实践中都非常重要
在作者的实验中,作者同样发现平衡采样能够提升结合离线数据的在线强化学习效果;然而,直接将该方法应用于一系列基准任务时并不足够,作者提出的其他设计决策对于在所有任务上获得良好性能同样至关重要
1.1.3 预备知识
本问题可以表述为马尔可夫决策过程MDP(Bellman, 1957)的问题,该过程被描述为一个元组
- 其中S 是状态空间,A 是动作空间,γ ∈(0, 1) 是折扣因子
- 动态由转移函数
控制
- 有一个奖励函数
和初始状态分布
强化学习的目标是最大化期望的折扣奖励和:
- 在本研究中,作者关注于在获取离线数据集D(Levine等人,2020) 的情况下进行强化学习,该数据集是由特定马尔可夫决策过程生成的一组
元组
- 离线数据集的一个关键特性是通常不提供完整的状态-动作覆盖,即,
只是S × A 的一个小子集。由于缺乏策略覆盖,使用函数逼近的方法在该数据上学习时可能会对数值进行过度外推,从而对学习性能产生显著影响(Fujimoto 等人,2019)
1.2 基于离线数据的在线强化学习
如上文所述,作者考虑在标准RL设置的基础上,增加了一个预先收集的数据集。在本研究中,作者旨在设计一种对该预收集数据的质量和数量均不敏感的通用方法。例如,这些数据可以是少量的人类演示,或大量次优的探索性数据
此外,作者希望提出的方法对于问题设置的性质也具有通用性,无论观测是基于状态还是像素,奖励是稀疏还是密集
为此,作者提出了一种基于离策略无模型强化学习的方法,无需预训练或显式约束,我们称之为RLPD(利用先验数据的强化学习)
下文将介绍,其算法设计基于SAC(Haarnoja等人,2018a;b),但原则上这些设计选择也可能提升其他离策略强化学习方法
- 首先,作者提出了一种简单的机制来融合先验数据
- 随后,作者发现,在对该问题直接应用离策略方法时会出现一种病态现象,并提出一个简单且最小化侵入性的解决方案
故作者通过结合最新的高样本效率强化学习方法,提高了离线数据的利用率 - 最后,作者指出,近期深度强化学习中的一些常见设计选择实际上对环境具有敏感性,因此实践者应根据具体环境进行相应调整
1.2.1 设计选择一:一种简单高效的离线数据融合策略
作者首先提出了一种简单的方法,该方法融合了先前的数据,不会增加任何计算开销,并且对离线数据的类型具有通用性。作者称之为“对称采样”,即每个批次有50%的数据来自(在线)回放缓冲区,另外50%来自离线数据缓冲区,这与Ross & Bagnell (2012)采用的方案类似——且这也印证了我之前的判定或解读是对的(详见本文开头)
正如后续章节所示,这种采样策略在多种场景下出乎意料地有效,作者对该方案的不同要素进行了广泛的消融实验(见第5.1节)
然而,将该方法直接应用于经典的离策略方法(如SAC,Haarnoja等,2018a)时,效果并不理想,如图1所示,因此还需要进一步考虑其他设计选择
1.2.2 设计选择2:层归一化缓解灾难性高估
标准的离策略强化学习算法会对分布外(OOD)的动作查询已学习的Q函数,而这些动作在学习过程中可能并未被明确定义
- 因此,由于采用了函数逼近方法(Thrun & Schwartz, 1993),实际值可能会被严重高估。在实际操作中,这一现象会导致训练过程不稳定,甚至在评论者试图追赶不断上升的数值时引发发散
- 特别是,当在复杂任务中天真地应用对称采样方法时,会发现确实会出现这种情况(见图2)。评论者分歧是一个被广泛研究的问题,尤其是在离线场景下,即策略无法生成新的经验
即采用对称采样方法结合SAC时,可能由于Q值发散导致不稳定性——其实关于Q值发散,在作者后续的工作中也被阐述过,详见此文第一部分的开头《WSRL——热启动的RL如何20分钟内控制机器人:先离线RL预训练,之后离线策略热身(模拟离线数据保留),最后丢弃离线数据做在线RL微调》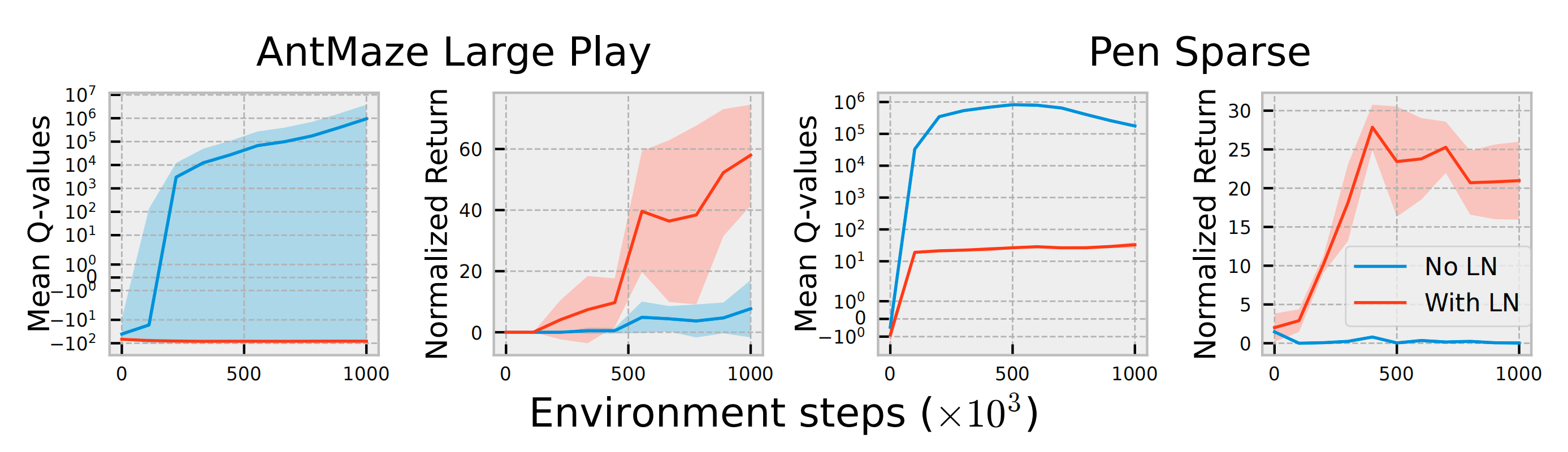
而在评论器中加入LayerNorm后,这种现象消失,性能得以提升
然而,在RLPD的问题设定中,可以从环境中采样。因此,与其专门设计机制明确抑制OOD动作(这可以被视为反探索,参见Rezaeifar等,2022),实际上只需要确保习到的函数不会以无约束的方式进行外推
为此,作者展示了层归一化(LayerNormalization,LayerNorm)可以对网络的外推进行约束,但关键在于,它并不会显式约束策略保持在离线数据附近。因此,这并不会阻止策略去探索状态-动作空间中未知且可能有价值的区域
具体来说,作者证明了 LayerNorm可以对值函数进行约束,并在实证上防止灾难性价值外推
- 具体而言,考虑一个由 θ、w 参数化的 Q函数 Q,并对中间表示
应用 LayerNorm
对于任意的 a 和 s,可以说: - 因此,由于层归一化(Layer Normalization)的作用,Q值被权重层的范数所限制,即使对于数据集之外的动作也是如此。因此,错误动作的外推效应被极大地减轻,因为这些动作的Q值不太可能显著高于数据中已经见过的值
实际上,回顾图2可以看到,将LayerNorm引入评论器能够通过缓解评论器发散显著提升性能
为了说明这一点,作者生成了一个输入x 分布在半径为0.5 的圆上的数据集,标签为y =∥x ∥。且作者研究了一个带有ReLU 激活函数的标准两层MLP(在深度强化学习中常见)在数据分布之外的外推行为,以及添加LayerNorm 的效果
在下图图3 中,标准参数化导致在支持范围之外的外推结果无界,而LayerNorm 对数值进行了约束,大大减少了不可控外推的影响
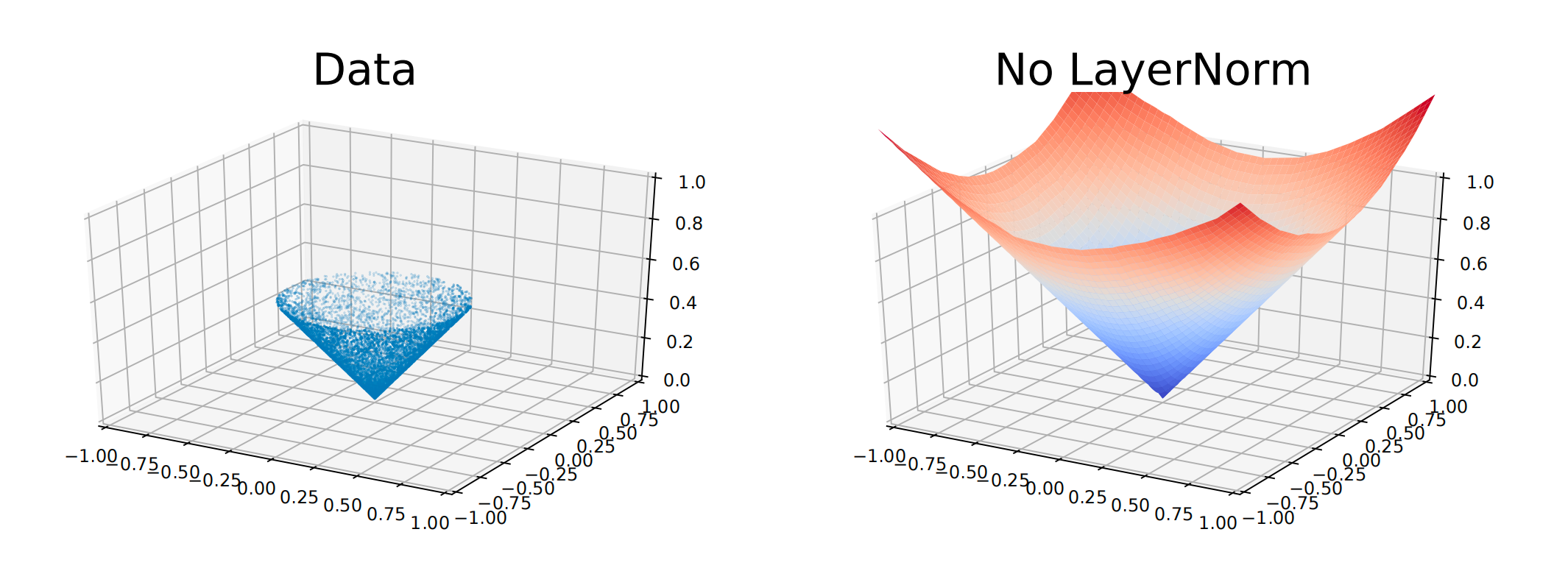
1.2.3 涉及选择三:样本高效的强化学习
作者现在提出了一种利用离线数据的在线方法,该方法不仅抑制了极端的价值外推,同时还保持了非约束式离策略方法的灵活性
然而,离线和受约束的方法的一个优势在于,它们具备显式机制来高效地整合先验数据,例如通过预训练(Hester 等,2018;Lee 等,2021)或辅助监督项(Nair 等,2018a;Rudner 等,2021)
- 在RLPD的方案中,先验数据的整合是通过在离线转移上执行在线Bellman 备份隐式实现的。因此,务必保证这些Bellman 备份的执行具有尽可能高的样本效率
实现这一目标的一种方法是,在每个环境步中增加执行的更新次数(也称为更新与数据比,UTD比),从而使离线数据能够被——可以更快地进行“回传” - 然而,正如近期在线强化学习文献中所强调的,这可能会在优化过程中引发问题,并具有讽刺意味地降低样本效率,其原因在于统计过拟合(Li 等,2022)
为了解决这一问题,已有研究提出了多种正则化方法,例如
简单的 L2 归一化(Večerík 等,2017)
Dropout(Srivastava等,2014;Hiraoka 等,2022)
以及随机集成蒸馏(Chen 等,2021)
在本研究中,作者选择了最后一种随机集成蒸馏的方法;通过消融实验,作者将展示该方法在稀疏奖励任务中表现最佳
且作者还注意到,在基于图像进行时序差分(TD)学习时会存在价值过拟合问题(Cetin 等,2022)。因此,在这些设置中,作者进一步引入了随机平移增强(Kostrikov等,2021;Yarats 等,2022)
1.2.4 针对每个环境的设计选择
在前文中,作者已经强调了三项关键的设计选择,这些选择可以广泛适用于所有环境和离线数据集
- 现在,作者将关注那些常被视为理所当然、但实际上可能对环境敏感的设计选择。已有大量文献表明,深度强化学习算法对实现细节非常敏感(Henderson 等,2018;Engstrom 等,2020;Andrychowicz 等,2021;Furuta 等,2021)
因此,许多深度强化学习研究都需要针对每个环境进行超参数调整 - 鉴于实验中涉及的任务种类繁多,作者认为有必要参与这一讨论,并强调某些设计选择——这些选择往往直接沿袭自以往的实现——实际上应当被认真重新考量。这也可能解释了为何在咱们所关注的问题上,离策略方法至今未能具备竞争力
因此,鉴于深度强化学习的敏感性已有充分文献记录,作者认为有必要展示在评估新环境时需要关注的关键设计路径,并为实践者提供简化此流程的工作方法
首先,对于裁剪双Q学习(CDQ)
基于价值的方法在结合函数逼近和随机优化时,会受到估计不确定性的影响,而Q学习的最大化目标又会导致价值高估(van Hasselt等,2016)——如上文1.2.2 设计选择2:层归一化缓解灾难性高估,至于原论文则对应于第4.2节的讨论
为了解决这一问题,Fujimoto 等人(2018)提出了裁剪双Q学习(ClippedDouble Q-Learning,CDQ)以解决该问题,该方法在计算时序差分(TD)回报时,采用两个Q函数集合中的最小值。他们定义了用于更新评论器的目标如下
然而,这相当于拟合目标 Q 值时,将其设置为实际目标值下方 1 个标准差。近期的研究(Moskovitz等,2021)表明,这一设计选择可能并非在所有情况下都适用,因为它可能过于保守
因此,尤其是在其最初设计的领域之外(例如在作者问题设置中普遍存在的稀疏奖励任务),这一点值得重新审视
其次,对于最大熵强化学习
最大熵强化学习在传统的回报目标中增加了一个熵项:
这对应于在每个时间步最大化折扣奖励和期望的策略熵。这类方法的动机主要集中在鲁棒性和探索性上(即在尽可能随机的行为下最大化奖励)。依赖该目标的方法在实证中表现出色(Haarnoja 等,2018a;2018b;Chen 等,2021;Hiraoka 等,2022)
因此,作者认为在在线微调的背景下,这一设计选择具有重要意义,因为此时奖励往往稀疏且需要探索
最后,对于架构
- 网络架构对深度强化学习的性能有显著影响,同一架构在某些环境中可能是最优的,但在其他环境中则可能表现不佳(Furuta 等,2021)
- 为简化搜索空间,作者考察了在 actor 和 critic 中使用 2 层或 3层的影响,已有研究表明,这种层数的变化即使在经典任务中也会影响性能(Ball & Roberts,2021)
1.3 RLPD:方法概述
在此,作者展示了他们方法的伪代码,并用绿色突出显示对他们方法至关重要的要素,用紫色标注环境特定的设计选择
RLPD的关键因素体现在Algorithm1的第1行和第13行,包括采用LayerNorm、大规模集成、样本高效学习以及一种对称采样方法以融合在线和离线数据。针对不同环境的具体选择,作者建议以以下内容作为起点:
- 第3行:子集2评论者
- 第16行:移除熵
- 第1行:使用更深的3层MLP
作为一种实用的工作流程,作者建议首先按上述顺序消融这些Purple design设计选择(其中,人类离线演示数据放在demo buffer里,用D表示,在线数据放在RL buffer里,用R表示)


// 待更
更多推荐
 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)