
知识蒸馏RLDG:先基于精密任务训练RL策略(HIL-SERL),得到的RL数据去微调VLA,最终效果超越人类演示数据
论文《RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning》提出通过强化学习生成高质量训练数据,以提升通用机器人策略(如OpenVLA/Octo)在精密操作任务中的性能。传统基于人类演示的微调存在精度不足、数据不一致等问题,而RLDG先训练任务专用RL策略生成优化轨迹,再蒸馏至通用模型,实验显示其成功率比人类
前言
本周三8.27日,微信上一篇朋友问:“ RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning,这个你们能复现吗?”
我仔细看了下,应该可以,毕竟我们本身就有复现服务,比如之前复现ACT的服务(给客户打包全部的硬件和全部的软件,包括我司为把ACT适配国产机械臂的全部代码)
七月具身:训练ACT抓瓶子的全套硬件和全部代码
当然了,我司「七月在线」的主业自然是:具身智能的场景落地与定制开发,侧重机器人的软件开发与软硬一体集成
- 对于其中的软件开发,特指具身大脑层面的开发:让机器人更聪明的干活,目前主要围绕机械臂上的精密插拔、智能装配,与人形上的展厅讲解、灵巧操作、箱子搬运等等
- 对于其中的软硬集成,特指集成最适合特定场景的本体、配件、软件,最终为实用落地服务,而非像 “有的(注意,只是有的,非全部)硬件制造厂商” 那样,无论什么场景,只执着于兜售自家的机器——比如哪怕固定机械臂更合适 他们也可能强推自家人形,哪怕轮式人形更合适 他们也可能强推自家双足人形
说白了,在很多场景的落地上(注意这个“很多场景”的前提,不是所有或任何场景 ),我司更适合定义硬件设计,因为我们离最终的场景、落地更近,故更懂得硬件应该怎么设计、怎么选择,才能让特定场景下的最终落地效果更好
PS,类似亚信最早期的在「系统集成」方面的发家史,进一步而言,车企本质上也是软硬集成商,组装各种零部件、软件功能
而为了更好的复现RLDG,故本文特地来解读下这个RLDG,如原论文中所说,虽然RLDG本身不依赖于特定算法,但作者采用HIL-SERL来实现RLDG
- HIL-SERL结合了RLPD(下一篇文章会解读)
- HIL-SERL的介绍详见此文《UC伯克利HIL-SERL——结合视觉和人类示教与纠正的RL方法(直接真实环境中RL开训,可组装电脑主板和插拔USB)》
说的通俗点,其实就是通过HIL-SERL生成的RL精准数据去微调VLA,毕竟HIL-SERL虽然精准可靠,但其对环境过于挑剔,泛化性不足,故把HIL-SERL的精准能力赋予给VLA,如此兼具精准和泛化性,一举两得 何乐不为
当然,很快,我还会再解读几篇RL微调VLA的paper
顺带,有两点值得一提
- 对于本文标题中说的“最后微调VLA,效果超越人类演示数据”
值得注意的是,RLDG论文的发表时间只是24年年底,openvla终究是比较老了(虽然,其实也没过多久,也就24年6月份才提出来的),其精密操作能力确实比较弱
但本文标题并没有毛病,因为通过RL微调过后的openvla 再做精密操作时 做得更好- VLA现在发展迅猛,比如本博客内解读过:Tactile-VLA——将触觉作为原生模态引入VLA:触觉参与动作生成,且根据触觉推理出合适的力度大小,以高成功率搞定充电器和USB插拔
我的个人看法是
对于孔较大的,vla + 触觉基本可以解决
对于孔比较细的1 单纯RL hil-serl可以,但对环境过于挑剔,泛化性不足
我估计,RL结合VLA的方法,很快会成为工厂里 智能机械臂的主流落地方法
第一部分 RLDG:通过强化学习实现机器人通用策略蒸馏
1.1 引言、相关工作
1.1.1 引言:RL微调VLA,可结合各自的精准、泛化优势
近年来,机器人基础模型取得了显著进展,展现出在理解和执行多样化操作技能方面的卓越能力
- Collaboration 等2024,即Open X-Embodiment
- Brohan 等2023b;a,即RT-1、RT-2
- Team 等2024,即Octo
- Kim 等2024,即Openvla
- Black 等2024,即π0
- Wen 等2024,即Tinyvla
- Liu 等2024,即Rdt-1b
- Cheang等,2024,即Gr-2
- 通过利用互联网规模的预训练以及与机器人动作的结合,这些模型能够在不同领域实现零样本和少样本的泛化能力。部署这些模型通常需要使用任务特定的数据进行微调,以适应目标任务或领域
因此,微调数据的质量对最终策略的性能至关重要 - 虽然人类遥操作是一种常见且易获取的数据来源,但人类演示往往存在执行质量和风格上的不一致
这些差异使得基础模型在学习稳健策略时面临挑战,因为它们必须应对人类演示中固有的不完美和不一致性
这一挑战影响所有机器人任务,但在需要精确控制和灵巧操作的场景中尤为突出,例如涉及复杂接触操作的任务。这类任务对细粒度、实时响应控制有极高要求,因此演示数据的质量和一致性变得更加重要
为了解决这一挑战,来自UC伯克利的研究者Charles Xu 1†, Qiyang Li 1, Jianlan Luo 1† and Sergey Levine 1提出了强化学习蒸馏通用体RLDG,这是一种简单而有效的方法,利用强化学习为机器人基础模型生成高质量的训练数据
- 其paper为:RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning,其Submitted on 13 Dec 2024
- 其项目地址为:generalist-distillation.github.io
其生成的RL数据地址为:huggingface.co/datasets/charlesxu0124/RLDG
即,This repository contains the RL policy generated datasets from the paper RLDG. All datasets are in RLDS format and can be directly used to fine-tune Octo and OpenVLA models.——so,是不意味着可以直接拿这部分数据微调更好的VLA呢,比如π0,有兴趣的同学可以试下,当然,也欢迎私我一两句简介,邀你加「精密插拔与装配交流群」
数据集具体包括以下
Connector Insertion: ethernet_insert_rl_dataset, usba_insert_rl_dataset, vga_insert_rl_dataset
Pick and Place: pepper_pick_place_rl_dataset
FMB Insertion: fmb300_rl_insert_dataset
FMB Assembly: fmb_rl_composition_dataset
虽然原则上可以直接用RL对基础模型进行微调,但这会带来诸多挑战,包括优化不稳定、计算成本高昂以及可能出现对预训练能力的灾难性遗忘,因此目前仍是一个悬而未决的问题
作者的核心观点是,RL智能体可以通过最大化奖励自主生成高质量的轨迹,因此相比于人工演示,更适合用于微调通用策略
具体方法很直接:作者首先利用样本高效的现实世界RL框架(Luo等2024b-即SERL;d-即HIL-SERL)训练基于视觉的操作策略,直至收敛,然后收集这些策略的数据来微调机器人基础模型
该流程简单灵活,具有多项优势
- 首先,它为生成大量高质量训练数据提供了自动化手段,无需人工远程操作,尤其有价值,因为自主RL训练在成本效益上远高于人工采集人类示范数据
- 其次,通过将RL的优化能力与基础(VLA)模型的强泛化能力相结合,RLDG能够生成在新颖场景中表现优异的策略
- 最后,RLDG通过利用RL数据解决制约整体任务表现的“瓶颈”步骤,为复杂的多阶段任务提供了有价值的解决方案
总之,作者宣称,他们在多个具有明确定义奖励函数的操作任务上进行了大量实验,结果表明,像OpenVLA(Kim等,2024)和Octo(Team等,2024)这样的通用策略,在使用RL数据进行微调后,相较于仅基于人类示范,能够获得更优的性能,特别是在RL能够学习到有效控制器的任务中
对于如图3所示的高精度操作任务(如紧密配合连接器插入),RLDG的平均成功率高出30%。在泛化能力评估中,这一性能差距进一步扩大:RLDG训练的策略在新场景中的迁移表现明显更好,平均成功率高出50%
值得注意的是,正如下文即将讲到的(对应于原论文第4节),要达到与RLDG相当的表现,至少需要6-10倍的人类示范数据。对于如精确插入等复杂任务,RLDG能够实现100%的完美成功率,而仅用人类示范训练的策略即使数据量显著增加,成功率也只能达到90%的平台期
1.1.2 相关工作
首先,对于机器人领域的基础模型
近期在视觉-语言基础模型方面的进展,使得开发能够通过自然语言指令理解并执行多样化任务的通用型机器人策略成为可能
- 这类模型
Brohan等2023b;a,即RT-1、RT-2
Kim等2024,即Openvla
Team等2024,即Octo
Black等2024,即π0
Wen等2024,Tinyvla
Liu等2024,即Rdt-1b
Cheang等2024,即Gr-2
Driess等2023,即Palm-e
利用基于互联网大规模视觉-语言数据的预训练,并在机器人演示数据上进行微调 - 虽然这些方法在广泛任务上的泛化能力令人印象深刻,但作者宣称,他们的实验表明,在需要精确对齐和丰富接触交互的精细操作任务中,它们往往表现不佳——注意,此文的发表时间只是24年年底,我想表达的意思是,VLA技术发展迅猛,三个月就可以变得强大许多
这一挑战源自基于演示学习方法的根本性局限——人类演示虽然多样且适应性强,但通常缺乏完成接触丰富操作任务所需的精度和可重复性
RLDG通过将基础模型的语义理解与强化学习中获得的稳健行为相结合,弥补了这一不足,从而在保持基础模型灵活性和泛化能力的同时,实现了高精度的操作
其次,对于用于机器人操作的强化学习
- 强化学习已被成功应用于通过与环境的直接交互,在现实世界中学习复杂的机器人操作技能Luo等2024b;d;,即Serl
再比如
1 Rajeswaran 等2017,即Learning complex dexterous manipulation with deep reinforcement learning and demonstrations
2 Levine等2016,即End-to-end training of deep visuomotor policies
3 Hu 等2024b,即REBOOT: reuse data for bootstrapping efficient real world dexterous manipulation4 Johannink 等2019,即Residual reinforcement learning for robot control
5 Hu 等2024a,即Imitation bootstrapped reinforcement learning
6 Rajeswaran 等2018,即Learning complex dexterous manipulation with deep reinforcement learning and demonstrations
7 Schoettler 等2020,即Deep reinforcement learning for industrial insertion tasks with visual inputs and natural rewards. - 以往的研究已经证明,强化学习在学习诸如高精度插入
Luo 等2021;,即Robust multi-modal policies for industrial assembly via reinforcementlearning and demonstrations: A large-scale studyZhao 等2022,即Offline metareinforcement learning for industrial insertion
Luo 等2019;2018,即Reinforcement learning on variable impedance controller for high-precision robotic assembly,和Deep reinforcement learning for robotic assembly of mixed deformable and rigid objects
多阶段装配
Gupta 等2021
Reset-free reinforcement learning via multi-task learning: Learning dexterous manipulation behaviors without human intervention
和灵巧的手内操作
Hu 等2024b,即REBOOT: reuse data for bootstrapping efficient realworld dexterous manipulation
等具有挑战性的任务中具有有效性
强化学习的一大优势在于其能够通过试错探索发现最优动作分布,从而相比纯模仿学习得到更为健壮和高效的策略
Luo 等2024a,即RLIF: Interactive imitation learning as reinforcement learning.
然而,强化学习策略通常难以泛化到其训练分布之外,因此需要针对不同任务变体或环境条件单独训练策略 - 然而,尽管RL策略能够在特定任务上实现卓越的性能,但要将强化学习扩展到能够高效处理用于基础模型训练的大规模数据集仍然具有挑战性。这主要是因为在扩展价值函数学习和策略优化以处理如此大量且多样化的数据时,存在计算和算法上的困难
因此,强化学习方法往往难以达到基础模型在互联网规模数据集上训练所展现出的广泛泛化能力。RLDG通过结合两种方法的优势来弥补这一差距——先利用强化学习为特定的复杂任务学习最优行为,然后将这些精确能力蒸馏到基础模型中,同时保留其广泛的泛化能力
最后,对于策略蒸馏与知识迁移
- 将多个专用策略蒸馏为单一的、更通用的策略这一思想,在强化学习和机器人学文献中得到了广泛探讨(Levine 和 Abbeel,2014),包括
- 这些方法已经证明,经过精心设计的蒸馏过程能够在保留专家策略基本行为特征的同时,潜在地带来如提升泛化能力或降低计算需求等有益属性
尽管先前的研究在不同情境下探讨了策略蒸馏,作者的工作提出了两个关键创新点:
- 作者认为,他们证明了,将RL策略蒸馏到利用大规模预训练的基础模型中,比从零开始训练能够获得更好的效果
- 作者进一步表明,对于精密操作任务,采用RL生成的数据对基础模型进行微调,其性能优于使用人工演示,即使高质量的人类演示数据已经可用
综上,这些发现确立了RLDG作为一种实用方法,能够在保持基础模型广泛泛化能力的同时,赋予其专业的RL能力
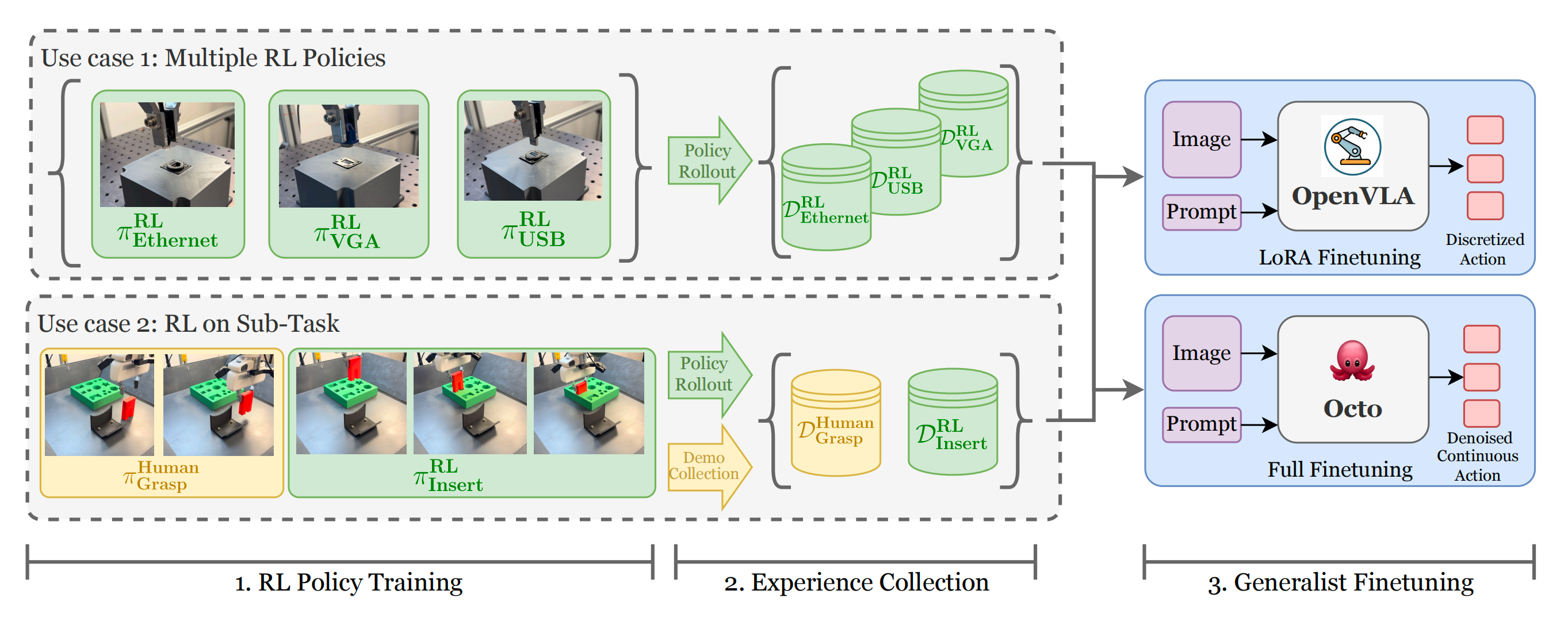
1.2 强化学习蒸馏的通用体:含训练流程
强化学习精炼通用体RLDG是一种简单而有效的方法,通过对专用强化学习策略的蒸馏,提升通用策略的性能
在他们的系统中,作者首先为单独任务训练RL策略,然后利用这些策略生成训练数据,用于微调单一的通用机器人操作策略,如OpenVLA,或Octo
- 虽然专用强化学习策略在特定任务上可以取得很高的性能,但它们通常缺乏零样本泛化能力和对干扰的鲁棒性
- 相反,通用策略在泛化能力上表现优异,但在以人类演示为基础进行训练时,往往难以达到高性能,例如由于数据次优或人类演示者与机器人策略之间存在模态不匹配(如视角、记忆和任务知识等差异)
RLDG 通过知识蒸馏弥合了这一差距,使通用体在性能上优于仅通过人类演示微调的策略,同时在泛化能力上也优于原始的强化学习策略(结合RL和VLA各自的优势,前者精准、后者泛化好)
- 这种通过强化学习生成数据的蒸馏方法对强化学习算法和通用策略架构均不敏感,因此适用于任何模型选择
此外,该方法还允许针对多个范围较窄的任务分别训练和收集数据(例如,在连接器插入任务中为每个连接器训练一个策略) - 还可以选择仅针对长时序任务中最为关键、最需精确的“瓶颈”环节进行强化学习训练并生成数据,而将非关键部分留给人类演示——如此,便算是结合了IL RL VLA
这不仅简化了强化学习的训练复杂度,还提升了数据多样性,从而改善通用体的性能,并避免了在不必要的长时序任务上进行强化学习训练
1.2.1 在线RL训练
可以将每个机器人任务建模为马尔可夫决策过程MDP,其中状态由RGB图像和本体感知信息组成,动作
表示期望的末端执行器运动
策略目标旨在最大化期望的折扣回报:
其中, 定义了机器人的初始配置,
表示系统的转移动力学,
是一个奖励函数,用于编码任务目标
- 虽然RLDG本身不依赖于特定算法,但作者采用HIL-SERL(Luo等人,2024d)来实现RLDG,这是因为其在从像素输入中学习精确的真实世界操作技能方面具有高样本效率和卓越性能
- HIL-SERL方法结合了RLPD(Ball等人,2023),从而高效地学习视觉运动策略,通过最大化期望的折扣回报(如上面公式所述),始终实现100%的成功率
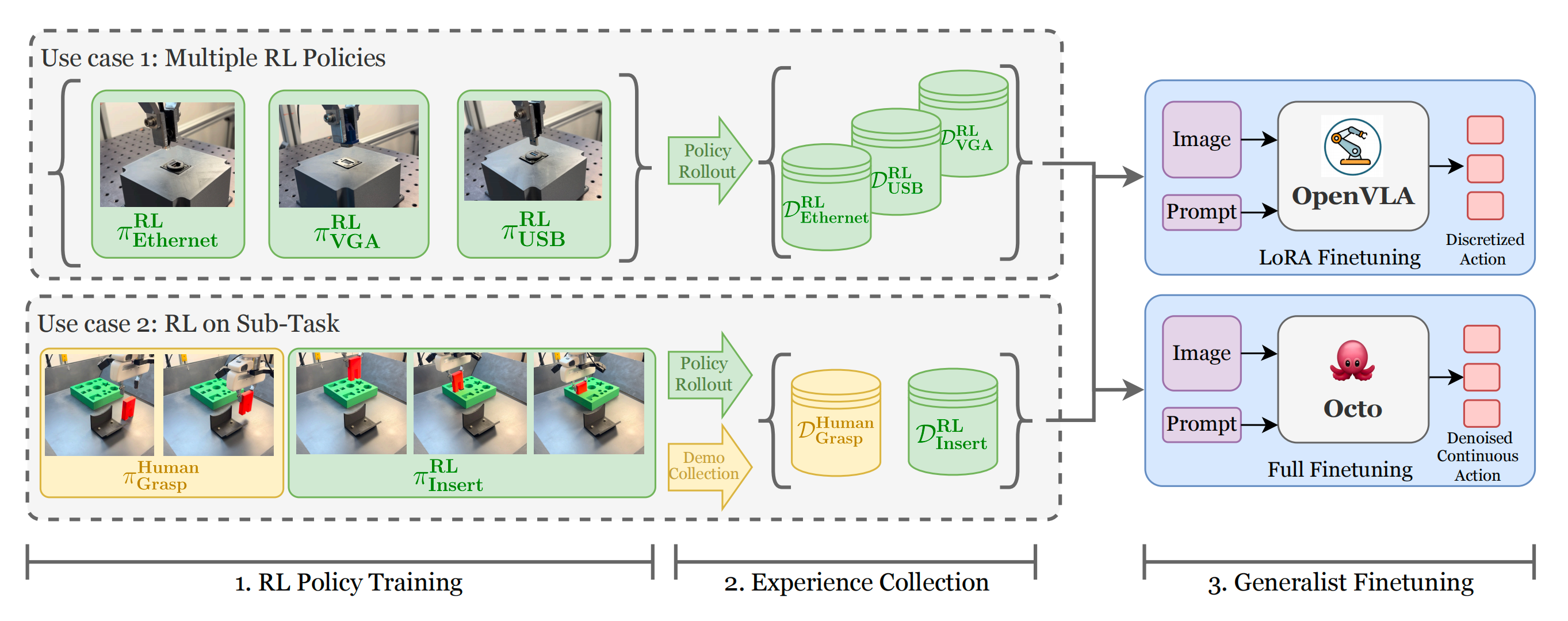
1.2.2 经验收集
在为RLDG提供的每个任务训练RL专家后,作者通过执行收敛的RL策略收集高质量的微调数据集
- 由于仅通过这些数据将RL中的知识迁移到通用策略中,因此可以灵活地混合来自多个来源的经验。对于涉及每个操作对象独立RL策略的任务(如连接器插入),作者分别执行每个策略,并构建一个包含每个对象等量回合的均衡微调数据集
- 在RL只针对任务某一部分进行训练的情况下(如FMB组装),作者将RL的回合与人类演示结合,用于任务剩余部分的数据收集
1.2.3 通用策略微调
通用机器人模型通常在多样化的大规模数据集上进行预训练,然后通过微调提升其在特定任务上的性能,同时保留来自多样化预训练的泛化能力
在RLDG 中,作者使用上节所述收集的数据对这些通用模型进行微调
具体而言,假设有一个预训练策略π0,然后用任务特定的数据集对其进行微调,采用以下监督学习目标
作者通过对两个预训练的机器人通用模型采用不同动作参数化方式进行微调,展示了RLDG方法的有效性
- OpenVLA
OpenVLA是一种基于 Llama 2 的 70 亿参数视觉-语言-动作模型。该模型以单张图像作为观测输入,并结合语言指令,能够预测七维动作
其每个维度通过自回归方式离散化为256个区间,并采用标准交叉熵损失函数
为了在作者基于强化学习生成的数据集上对模型进行微调,作者使用了公开的、在97万条Open X-Embodiment数据集上预训练的模型权重,并采用了LowRank Adaptation(即LoRA)这一广泛应用的参数高效微调方法 - Octo
Octo 是另一种开源的通用型机器人策略,旨在高效适应多样化的感知输入和动作空间。与 OpenVLA 不同,Octo 通过扩散头预测连续动作,该方法在建模多模态分布方面表现出色,有助于模仿人类演示(Chi 等,2024)
为预测动作,transformer 主干网络接收经过分词的观测和目标,然后输出一个读出嵌入,该嵌入用于标准 DDPM 目标(Ho 等,2020)训练下的去噪过程调节
作者采用预训练的Octo-Base 模型,移除其二级图像分词器,并屏蔽图像目标,以匹配RLDG的输入模态,随后直接在作者基于强化学习生成的数据集上对剩余网络进行微调
1.3 实验与结果
实验旨在评估RLDG在以下两个方面的能力:
- 一是利用RL数据训练通用策略的RLDG方法,是否比传统的基于示范数据的训练方法更有效
- 二是经过RLDG训练得到的通用策略,其泛化能力是否优于专门化的强化学习策略
1.3.1 实验设置与任务
所有实验的机器人设置如图2所示「使用一台配备平行夹爪的Franka Emika Panda机械臂,通过3Dconnexion SpaceMouse设备进行远程操作。机器人手腕上安装有一台RealSense D405相机,用于图像观测」
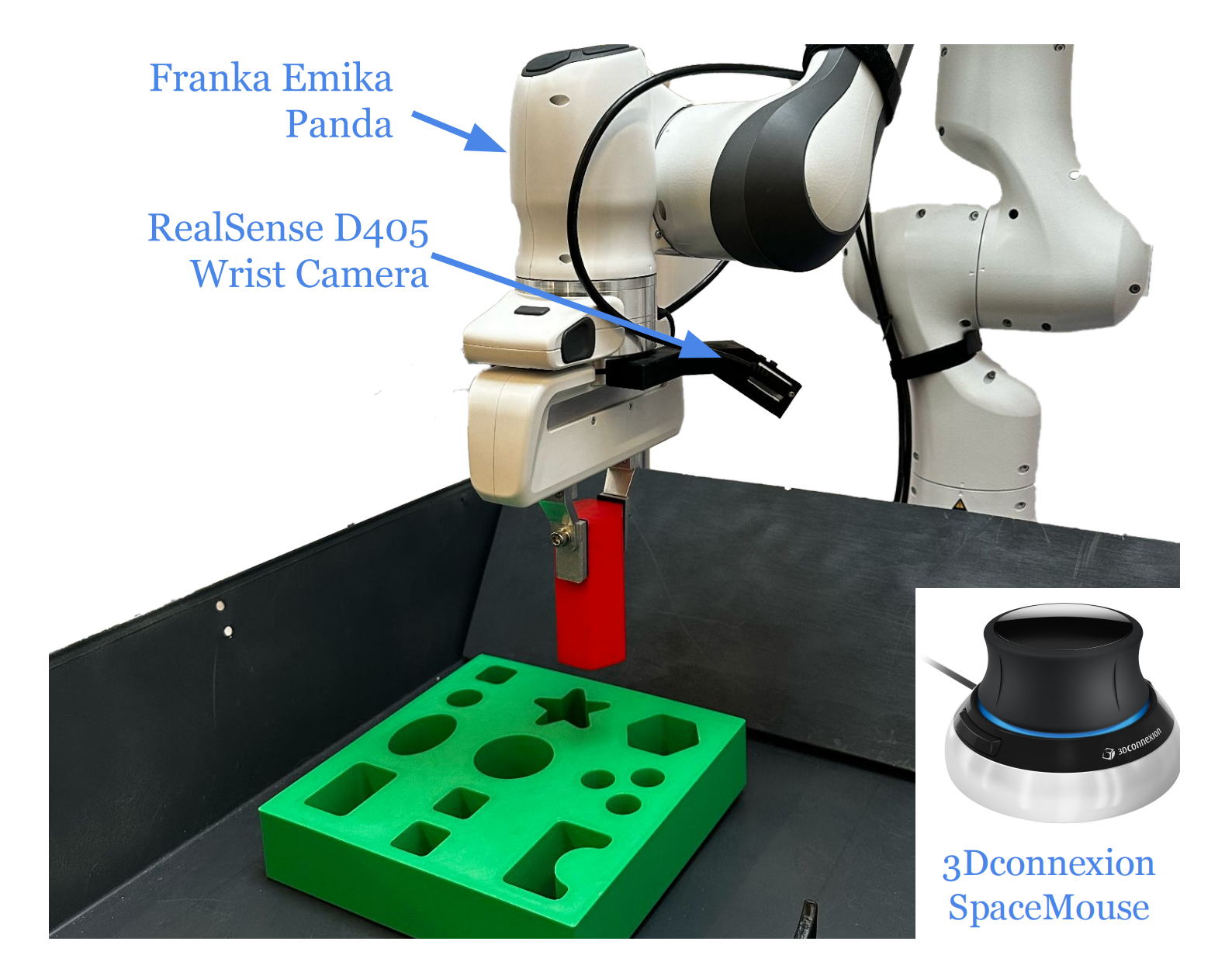
- 机械臂通过1kHz的低层阻抗控制器跟踪末端执行器指令。数据采集、强化学习(RL)和Octo策略以10Hz的频率下达动作指令,而由于推理速度的限制,OpenVLA以4Hz运行
- 所有策略的动作空间均为6维手腕末端执行器的增量位姿——对于涉及抓取的任务,每一帧包含1个二进制夹爪动作
- 强化学习策略的观测空间包括一张128×128像素的手腕RGB图像,以及末端执行器的位姿、速度和力矩测量
对于通用策略,我们仅使用手腕摄像头图像作为输入进行微调
作者在4项具有不同挑战的真实世界操作任务上评估了RLDG。这些任务包括对高精度、丰富接触的操作任务,这类任务通常对通用模型构成挑战;还包括抓取与放置任务,在这些任务中作者展示了RLDG能够进一步提升性能;以及多阶段装配任务,这些任务则利用了RLDG组合技能的能力
通过这些任务,作者还评估了该方法对未见配置的泛化能力
- 连接器插入
本任务要求将各种电子连接器插入其匹配的端口,这需要亚毫米级的精度和灵巧性,以应对对齐过程中复杂的接触动态
作者分别训练了不同的强化学习策略,并利用这些策略收集了USB、以太网和VGA连接器的数据,随后将它们融合为一个通用策略
同时,作者还使用Type-C、HDMI、Display Port和3针XLR连接器来评估该策略的零样本泛化能力 - 抓取与放置
作者还在抓取与放置任务上测试了他们的方法,在该任务中,机器人需要从一个随机位置抓取物体并将其放入碗中
为了测试泛化能力,作者还在一个未见过的场景中进行了评估,即更换了训练用的物体和背景 - FMB 插入
作者还采用了 FMB 中的单物体插入任务,这是比较机器人操作方法时常用且可复现的基准测试。该任务要求将已抓取的物体插入到具有±1.5毫米公差的匹配开口中,且位置为随机分布
- FMB单物体装配
本任务源自FMB单物体多阶段装配任务,在上述FMB插入力任务基础上增加了抓取阶段。作者采用这一多阶段任务来展示RLDG通过为精度要求极高的插入力阶段提炼RL数据,同时在抓取和搬运阶段利用人类演示,从而提升整体任务性能的能力
1.3.2 RLDG 与传统微调的对比:成功率、扩展性、周期时间
对于每个任务,作者分别在RL生成的数据和专家人类演示数据上对OpenVLA和Octo进行微调
为了公平比较,作者在两种方法中采用相同的任务设置、训练配置、观测空间和动作空间,以及成功的回合数。唯一的区别在于数据来源(RL与人类)
作者的目标是评估,与传统的人类演示相比,RL策略是否能为通用模型提供更优质的训练数据,从而提升最终策略的性能
- 成功率
作者在图4中展示了每种策略和方法的成功率。在每项任务中,无论是已见还是未见的评估场景,使用RL生成数据进行微调的OpenVLA和Octo,其成功率始终高于使用人工演示训练的对应方法
在preciseFMB插入和Connector插入任务中,作者预期通用模型能从更高质量的训练数据中获益最大,结果显示,采用RLDG的OpenVLA成功率分别比基线高出33%和23%。RLDG对Octo的提升同样显著,其成功率分别提高了10%和分别为37%,尽管整体成功率仍低于OpenVLA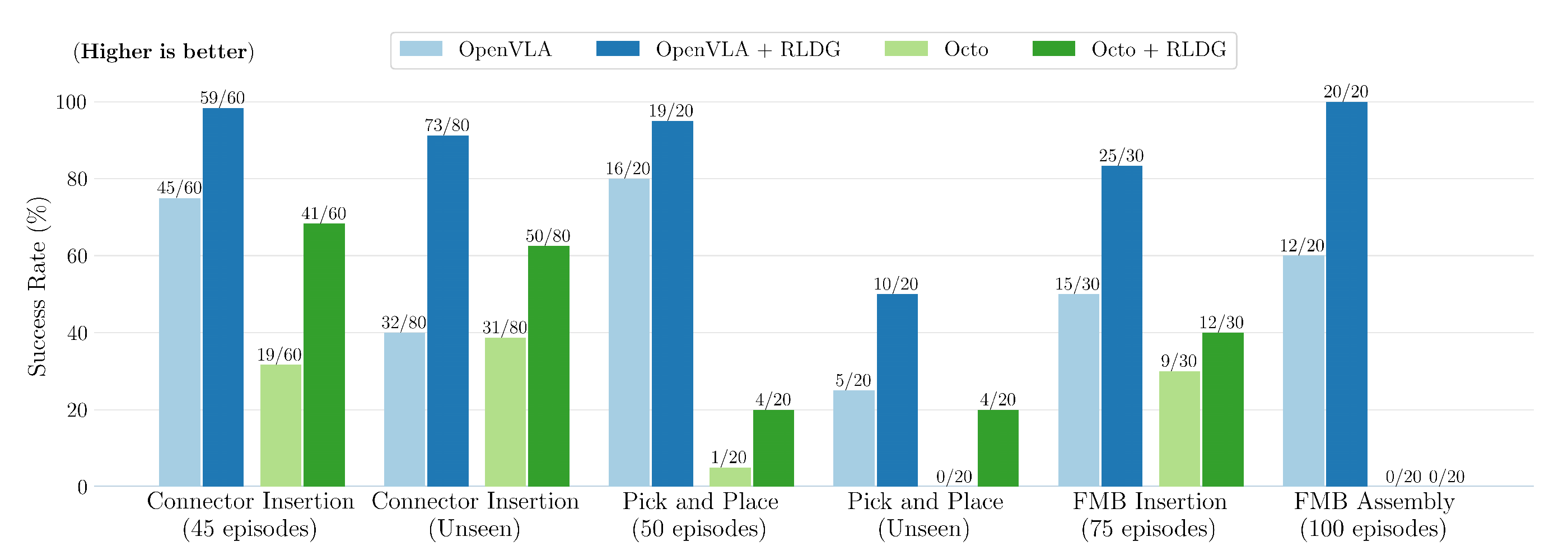
作者发现,RLDG同样提升了抓取与放置任务的成功率,在OpenVLA上由16/20提升至19/20,在Octo上由1/20提升至4/20
此外,RLDG在训练任务中的性能提升也延续到了未见过的评估场景。在未见过的连接器插入任务中,结合RLDG的OpenVLA取得了超过OpenVLA结合人类数据两倍以上的成功率,而将RLDG应用于Octo,则在未见过的抓取与放置任务中将成功率从0/20提升至4/20
且当有策略地结合人工演示与RL生成的数据应用于FMB装配任务时,所得的Open-VLA策略同样显著优于仅用人工演示训练的版本。它在使用RL生成数据时实现了20/20的成功率,而仅用人工演示时为12/20,这表明RLDG在提升长时序任务“瓶颈”方面具有灵活性和有效性 - 扩展性分析
为进一步研究RLDG的有效性,作者进行了扩展性实验,考察了在对不同数量的RL生成和人工收集的训练集进行微调时,OpenVLA策略在已知VGA连接器和未知Type-C连接器上的成功率
结果如图5所示
对于VGA连接器,采用RLDG的OpenVLA仅需45个RL训练集就实现了100%的成功率,而要达到相同成功率,人工演示则需要300个训练集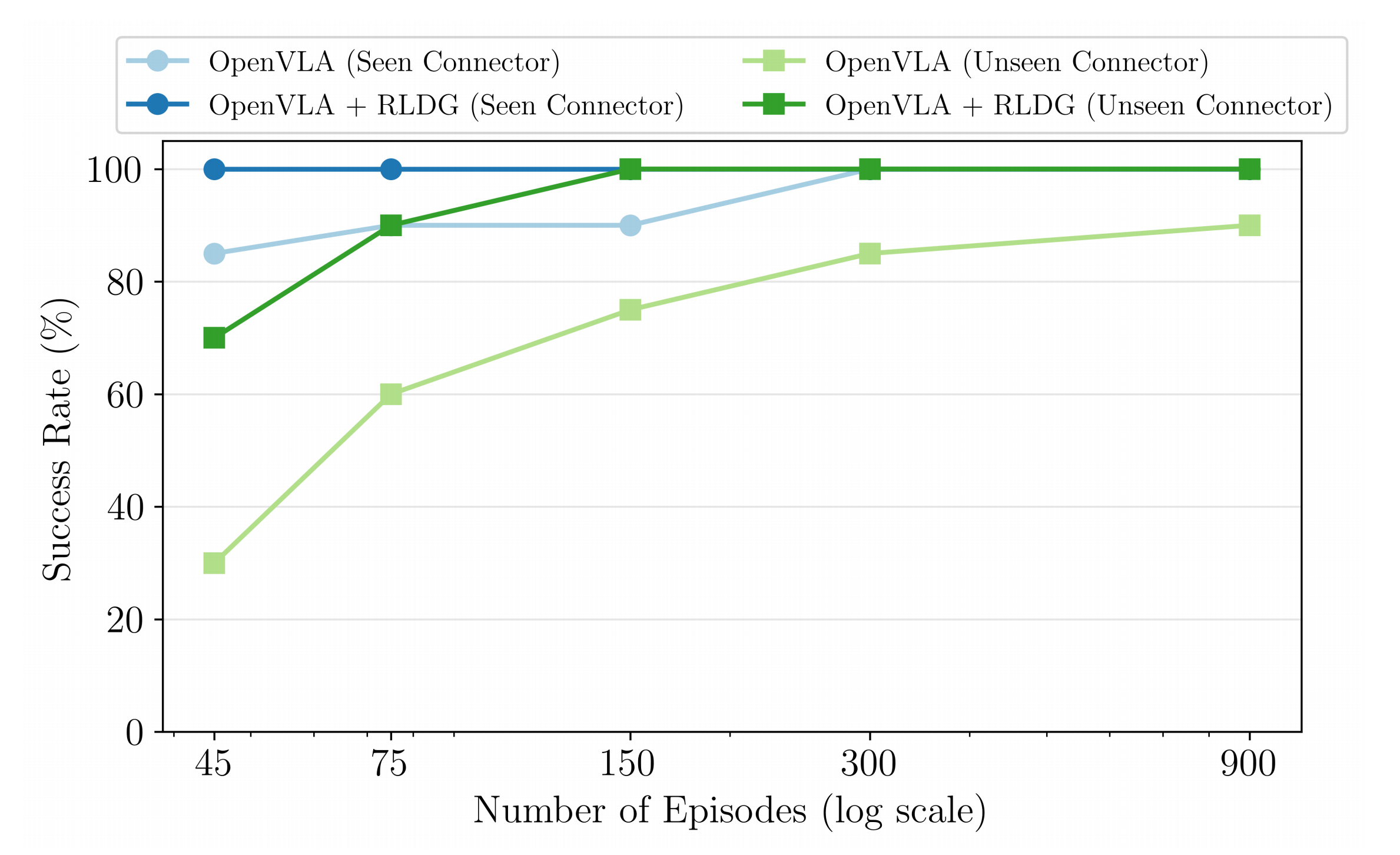
此外,使用150个RL回合在VGA、USB-A和以太网连接器上训练的策略,在未知Type-C连接器插入任务上也达到了100%的成功率,而基于OpenVLA的训练在即使进行了900次演示,人类演示的成功率也停滞在90%
这些结果强烈表明,利用RLDG微调通用策略在样本效率上更高,并且在分布内任务和未见任务上都能获得比人类演示更优的性能 - 周期时间
如图6所示,使用RL数据训练的通用策略在各项任务中的周期时间始终快于通过人工演示训练的策略,尽管差距并不显著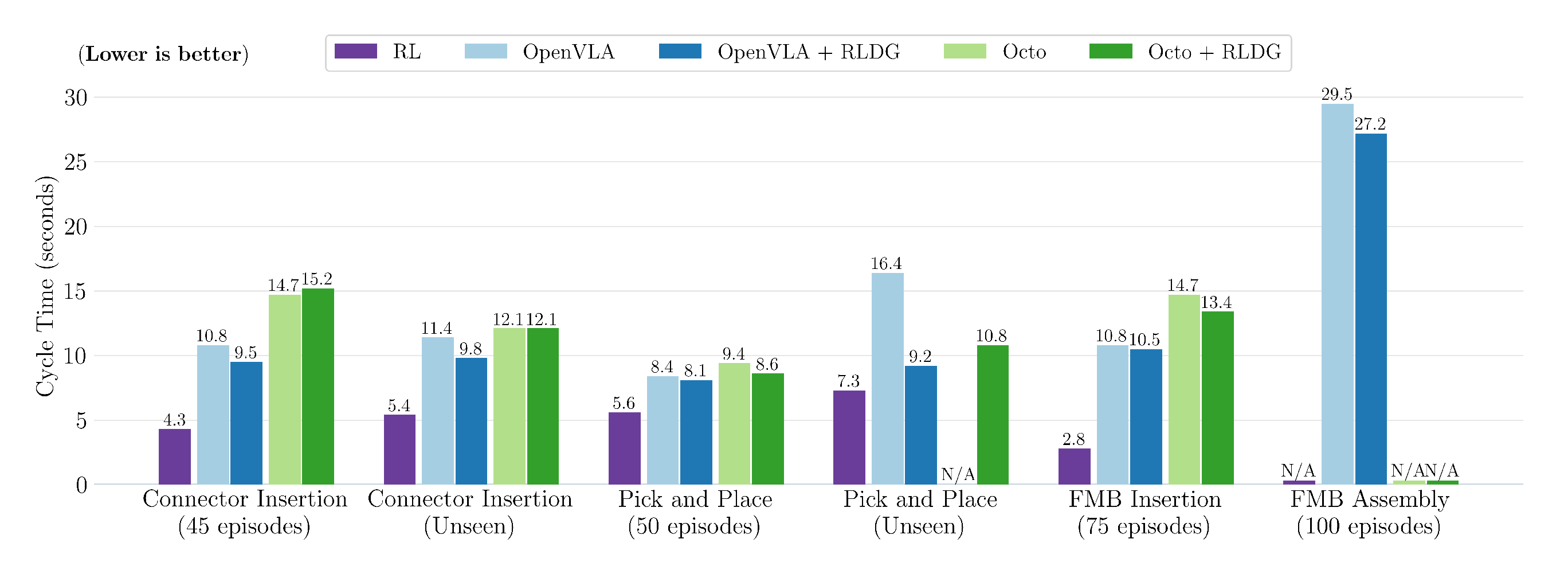
对于OpenVLA,RLDG将每项任务的周期时间缩短了0.3到2.3秒,而Octo整体上几乎没有提升。这一改进可归因于其固有的速度优势——通过时间折扣实现RL训练中的优化,随后通过收集比人类专家更快解决任务的轨迹,将其蒸馏到通用策略中
然而,所有通用策略在解决任务时仍然远比原始RL策略慢。对于OpenVLA,作者主要将这一不足归因于RL策略的10Hz控制频率与OpenVLA的4Hz之间的差距,这改变了系统动力学并降低了机械臂的最大速度
作者认为,如果推理速度能够提升到与RL策略相同的频率,OpenVLA的速度将有显著提升。对于Octo,微调后的策略无法完全拟合微调数据集,导致整体成功率较低且循环时间更长
1.3.3 RLDG 的泛化能力与原始强化学习策略的对比
为了解决本节开头提出的问题2,作者将采用RLDG训练的通用体的泛化性能与用于生成数据的原始强化学习策略进行了对比
如图4所示,强化学习策略在训练场景下的成功率为20/20,但在Pick and Place任务的未见场景下迅速下降至1/20
- 相比之下,采用RLDG的OpenVLA和Octo在同一任务上分别达到了10/20和4/20的成功率
- 此外,OpenVLA和Octo的多任务能力使其能够在Connector Insertion任务中对多种连接器数据进行微调,在评估4种未见(Unseen)连接器时,分别取得了73/80和50/80的成绩,而在单一连接器上训练的RL策略,在三个任务中的最高成功率也仅取得了49/80
1.4 分析与总结
如上已经证明,使用强化学习数据对通用策略进行微调,其性能优于仅用人工数据训练。然而,目前尚不清楚这些优势究竟源自何处
本节将分为两部分分析这些优势的来源
- 第一部分重点研究强化学习数据中动作和状态分布各自带来的益处
- 第二部分则聚焦于剖析微调策略在各个具体任务中的失败模式
1.4.1 RL 数据更优是因为更好的动作分布还是状态分布?
为了解答这个问题,作者采用 FMB 插入任务,并创建了一个“混合”数据集:在该数据集中,作者保留人类数据的状态,但将动作替换为 RL 策略采样得到的动作
- 通过比较“混合”数据集、纯 RL 数据以及纯人类演示数据在微调过程中的表现,可以分别观察动作和状态分布在提升性能中的作用
如图7所示
将人类状态与 RL 动作混合后,微调成功率优于完全使用人类数据(在25/50/75条轨迹微调时提升超过50%),但仍不及完全使用 RL 数据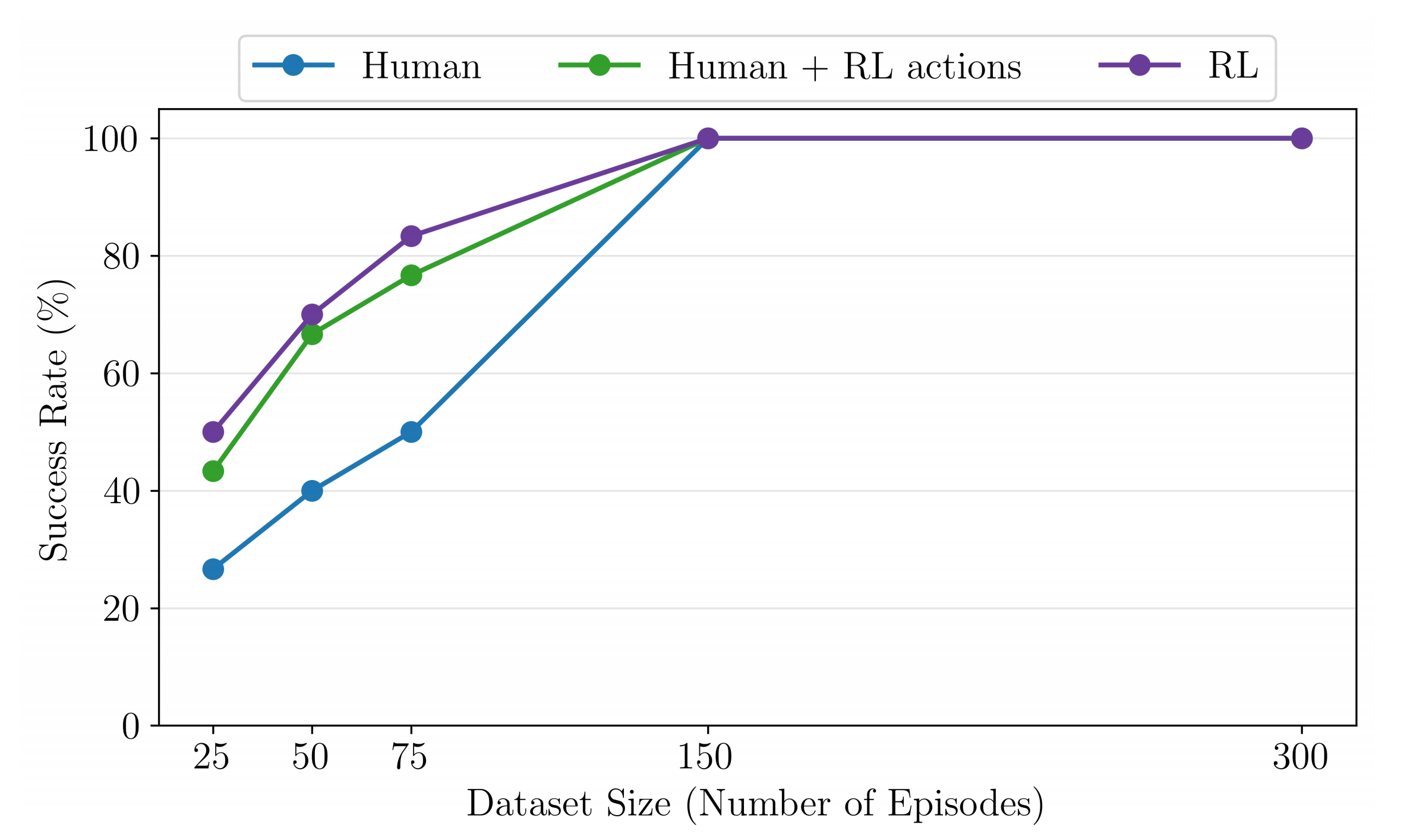
这表明,虽然 RL 的动作和状态分布都对微调性能提升有贡献,但动作质量是改进性能的主要因素 - 图8展示了人类动作与RL动作的对比
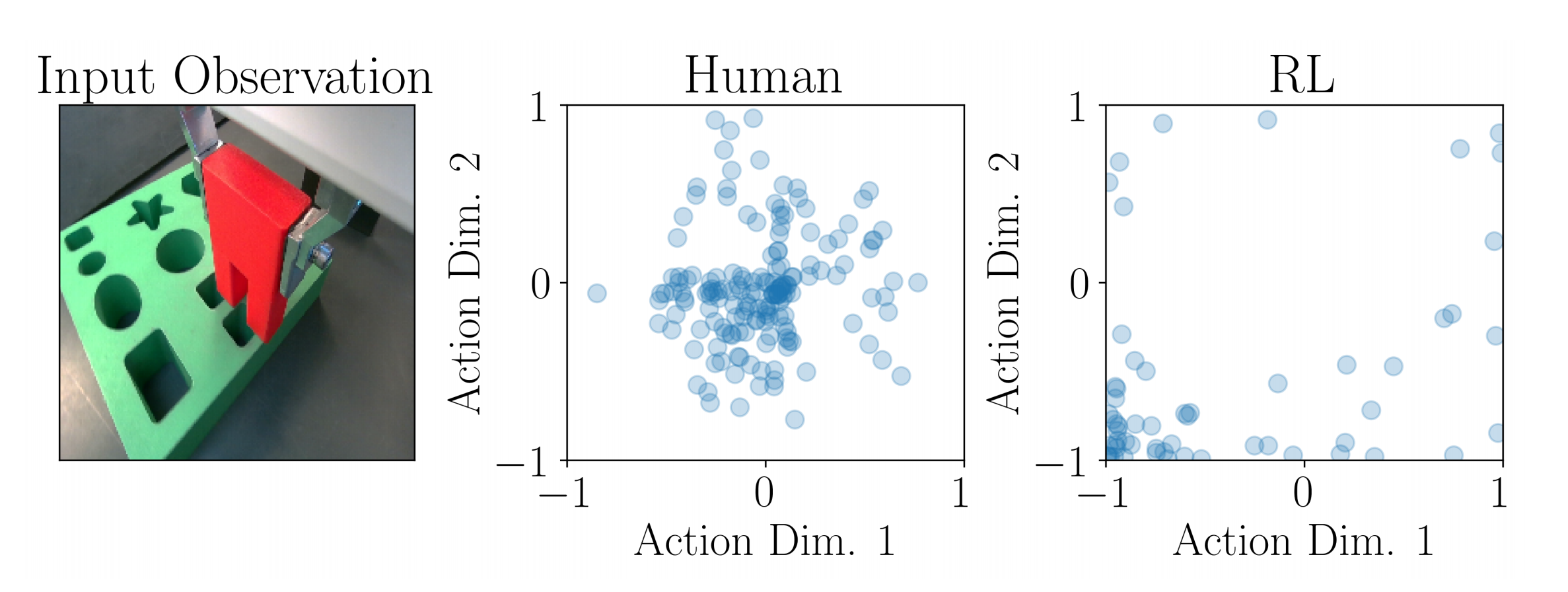
可以看到,RL动作分布在正确方向(左下方)上分配了更多的概率密度,该方向能够将末端执行器朝插入点移动,而人类动作分布则主要集中在中间,只有轻微偏向正确方向
这表明,RL动作比人类动作更加最优,从而导致了在图7中观察到的微调阶段更高的样本效率
1.4.2 定性分析
为了进一步理解为什么RL生成的数据能够带来更好的性能,作者还对各项任务中的失败模式进行了分析。作者观察到,使用RL生成数据训练的策略在精确、接触丰富的任务中,能够持续帮助克服对齐问题,并减少抓取过程中夹爪过早闭合的现象
- 连接器和FMB插入
在这两项任务中,强化学习(RL)数据消除了对象接触电路板但未能正确对齐所导致的“卡住”状态。人工示范策略通常会持续保持接触压力,但缺乏必要的探索性动作
此外,RL数据还优化了接近轨迹,有效防止了过早下降,从而避免了连接器卡在插槽边缘的问题 - 抓取与放置
强化学习(RL)数据提升了抓取的可靠性,减少了仅通过人类演示训练的策略中出现的夹爪过早闭合现象。然而,也观察到一种有趣的强化学习特有的失败模式:物体有时会被过早释放,从而弹出碗外
这很可能是由于强化学习在优化速度时,物体一旦越过碗沿就立即释放,但蒸馏后的策略缺乏精确的时机把控 - FMB组装
虽然两种OpenVLA策略在抓取和搬运阶段表现相似,因为它们都是基于相同的人类数据进行训练的,但在插入阶段出现了性能差距,RL数据更好地解决了对齐问题,这与插入任务中的表现类似
Octo的失败主要是由于持续的抓取错误,表现为手指位于物体前方,这很可能是由于缺乏良好的深度感知能力所致
1.5 训练流程与局限性
1.5.1 训练流程
对于FMB插入、连接器插入和取放任务
- 作者首先使用SpaceMouse遥操作设备收集正负样本,以训练一个二分类成功判别器,作为强化学习的奖励函数
- 然后,用20条示范初始化强化学习缓冲区,并在完整任务上训练1至3小时,直到策略达到100%的成功率
- 接下来,利用收敛的强化学习策略进行部署,收集用于通用策略微调的数据,并筛除所有失败的轨迹(如有)
且还收集了所有成功的人类专家演示,用于与强化学习生成的数据进行对比
对于FMB单物体装配任务
- 插入RL训练,抓取IL
作者采用与FMB插入任务相同的奖励函数,并且仅在插入阶段训练强化学习
通过将物体预先抓取好,机械臂起始于距离板面15厘米的位置,并在一个5厘米×5厘米的随机区域内开始
且在训练和数据收集过程中定期调整抓取姿态,以增强对抓取变化的鲁棒性 - 插入 抓取均手机人类演示数据
同时,作者在插入阶段收集相同数量的人类演示数据以进行性能对比
随后,作者分别为抓取阶段收集人类演示数据,起始时机器人位于插入物体上方,结束时机械臂已抓取物体并移动到板面上方的插入随机区域内
作者将上面这两个阶段的数据结合用于微调。且对在OXE数据集上预训练的OpenVLA权重进行了微调,采用了LoRA方法,在模型的每个线性层上应用了秩为32的LoRA,从而在不显著牺牲性能的情况下降低了计算开销
作者使用默认的微调配置,批量大小为2,梯度累积步数为3,在一块Nvidia RTX 4090GPU上进行训练,收敛时间为3到5小时
- 对于Octo,从预训练的Octo-Base模型出发,使用主图像分词器对腕部摄像头图像进行分词,并移除了次级分词器。同时,由于作者未使用图像目标,因此对其进行了遮蔽
- 作者采用了全参数微调,使用默认的超参数和批量大小64,直到收敛,整个过程在单块Nvidia RTX 4090 GPU上耗时3-5小时
1.5.2 局限性
在本研究中,作者提出了RLDG,这是一种简单的方法,通过对由强化学习(RL)策略生成的高质量数据进行微调,从而优化通用策略
- 作者证明了,使用RLDG微调的通用策略在一系列现实世界具有挑战性的精密操作任务中,始终优于仅通过人类专家演示训练的策略
且他们的方法可应用于需要大量训练数据或通过人类演示训练策略已达到性能瓶颈的现实世界机器人操作任务 - 其次,他们的研究也为实现通用策略的自主改进提供了更具可扩展性和可操作性的途径
首先,他们的方法假设能够获取用于微调任务的奖励函数,但当任务奖励难以明确时,这可能会带来一定困难
未来的研究方向包括:自主生成带有奖励函数的微调任务(例如,利用预训练的视觉语言模型VLMs),以避免手动指定任务 - 此外,他们的RL策略不仅优化任务完成的成功率,还兼顾完成任务的速度。然而,这样的目标并不一定能产生在蒸馏误差下依然鲁棒的策略。例如,在Pick and Place任务中,基于RL生成数据微调的策略通常会在物体靠近目标位置后立即尝试放置,但有时会过早丢下物体——说白了,RL 并非适合所有任务
尽管如此,作者证明了专业的RL策略可以作为机器人基础模型训练数据的有效生成器,并希望能激发该领域的进一步研究
更多推荐

 29
29 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)