
一文搞懂大模型的预训练、微调和蒸馏,大模型入门到精通,收藏这篇就足够了!
初学者常对大模型的预训练(Pre-training)、微调(Fine-tuning)和蒸馏(Distillation)感到困惑,三者虽均属模型训练,但目标、数据和实现方式差异显著。
初学者常对大模型的预训练(Pre-training)、微调(Fine-tuning)和蒸馏(Distillation)感到困惑,三者虽均属模型训练,但目标、数据和实现方式差异显著。
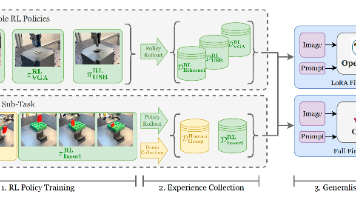
预训练使用海量无标注标注数据(如互联网文本、图像库)进行通识教育(大学基础课程);微调使用专业领域标注数据(如医疗影像、法律文书、代码库)进行专业培训(入职后的岗位技能培训);蒸馏使用教师模型的输出(如概率分布、推理链)进行经验传承(老员工带新人)。
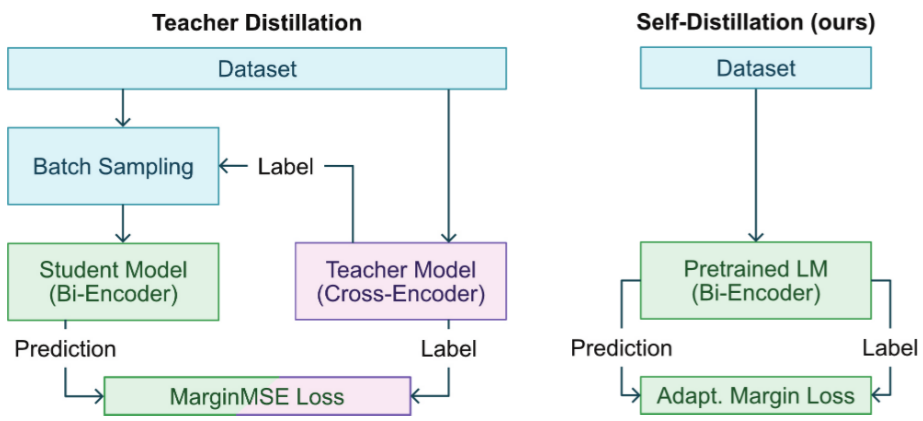
预训练(Pre-training)
预训练(Pre-training):大学通识教育
让模型“学会思考”,具备通用能力。
(1)目标:让模型具备通用能力,理解语言、图像等底层规律。
(2)数据:海量无标注/弱标注数据(如互联网文本、图像库)。
(3)效果:模型具备基础能力,但缺乏针对特定任务的精细技能(类似“通过面试但未上岗”)。
预训练通过海量无标注数据(如互联网文本)让大语言模型(LLM)接受大学通识教育(如数学、物理、英语)。就像大学生先学基础学科,为未来专业方向打基础。
预训练(Pre-training)就是暴力美学,通过堆算力,实现Scaling Low。不过这条路目前有点停滞,因为大模型能学习的互联网高质量数据接近用尽,传统依赖大规模预训练和模型扩张的发展路径正面临瓶颈。
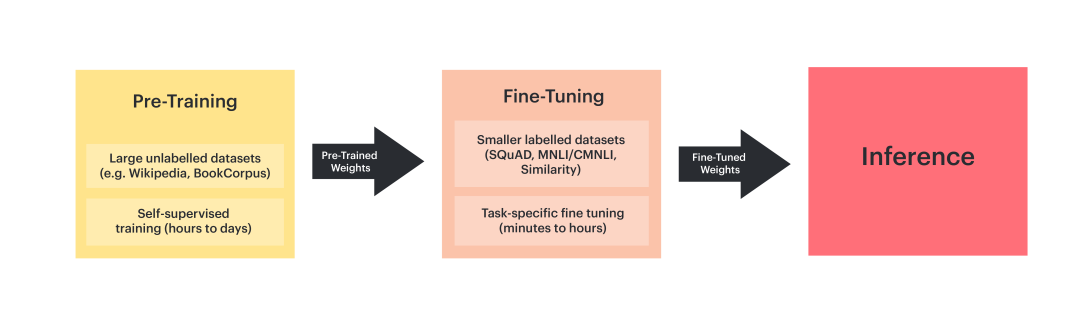
微调(Fine-tuning)
微调(Fine-tuning):专业培训(入职后的岗位技能培训)
让模型“学会干活”,针对特定任务优化。
(1)目标:让模型在特定任务上表现优异。
(2)数据:专业领域标注数据(如医疗影像、法律文书、代码库)。
(3)效果:模型在特定任务上达到高精度(类似“上岗干活”)。
大语言模型在预训练模型基础上通过大量标注数据进行微调(调整模型最后几层参数),从而学习垂直领域的专项技能。就像医生入职后学习专科知识(如心内科、骨科),针对具体岗位提升技能。
微调(Fine-tuning)是目前将通用大模型训练为垂直大模型比较有效的方式。Adapter微调在预训练模型中插入轻量级模块(如Adapter层),仅训练这些模块,减少参数更新量;而LoRA微调则通过低秩矩阵分解,降低微调时的参数更新量,提升效率。
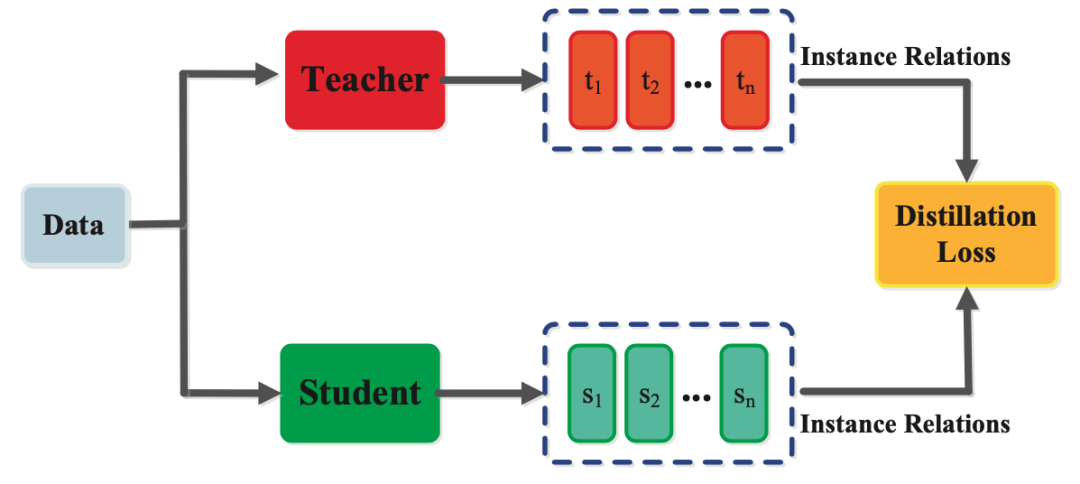
蒸馏(Knowledge Distillation)
蒸馏(Knowledge Distillation):经验传承(老员工带新人)
让模型“学会传承”,将大模型的经验迁移到小模型。
(1)目标:将大模型(教师)的知识迁移到小模型(学生)。
(2)数据:教师模型的输出(如概率分布、推理链)。
(3)效果:学生模型在保持轻量化的同时,学习到教师的经验(类似“新人快速上手”)。
小模型通过蒸馏学习到大模型(教师)的“软标签”(如概率分布)或推理过程。就像老员工将经验传授给新人,而非直接学习书本知识。
大模型虽性能卓越,但部署成本高(如推理延迟、内存占用)。蒸馏通过将大模型(教师模型)的“隐性知识”迁移到小模型(学生模型),实现轻量化部署,同时保留核心能力。这样可以解决AI在资源受限、隐私敏感、领域垂直等场景中的应用。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础第二不要求准备高配置的电脑第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的
核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)