
CLIP(Contrastive Language–Image Pretraining,对比语言 - 图像预训练)
通过线性投影层将两种模态的特征映射到同一高维空间,使得匹配的图文对向量距离更近。Decoder不需要图片和文字成对的资料,这个额外的Decoder的好处就在这里,这个docoder的训练:如果中间产物是小图,那只用把手上的图片找出来把他们变成小图然后进行训练。这个模型里面有一个Image Encoder和一个Text Encoder,这两个输入数据后分别产生一个向量,如果这个图片和文字相关的,那么
CLIP(Contrastive Language–Image Pretraining,对比语言 - 图像预训练)是 OpenAI 于 2021 年提出的多模态模型,通过对比学习将图像和文本映射到同一语义空间,实现跨模态理解与零样本迁移。基于 Transformer,将自然语言描述(如 “一只金毛犬在草地上奔跑”)转换为语义向量。通过线性投影层将两种模态的特征映射到同一高维空间,使得匹配的图文对向量距离更近。
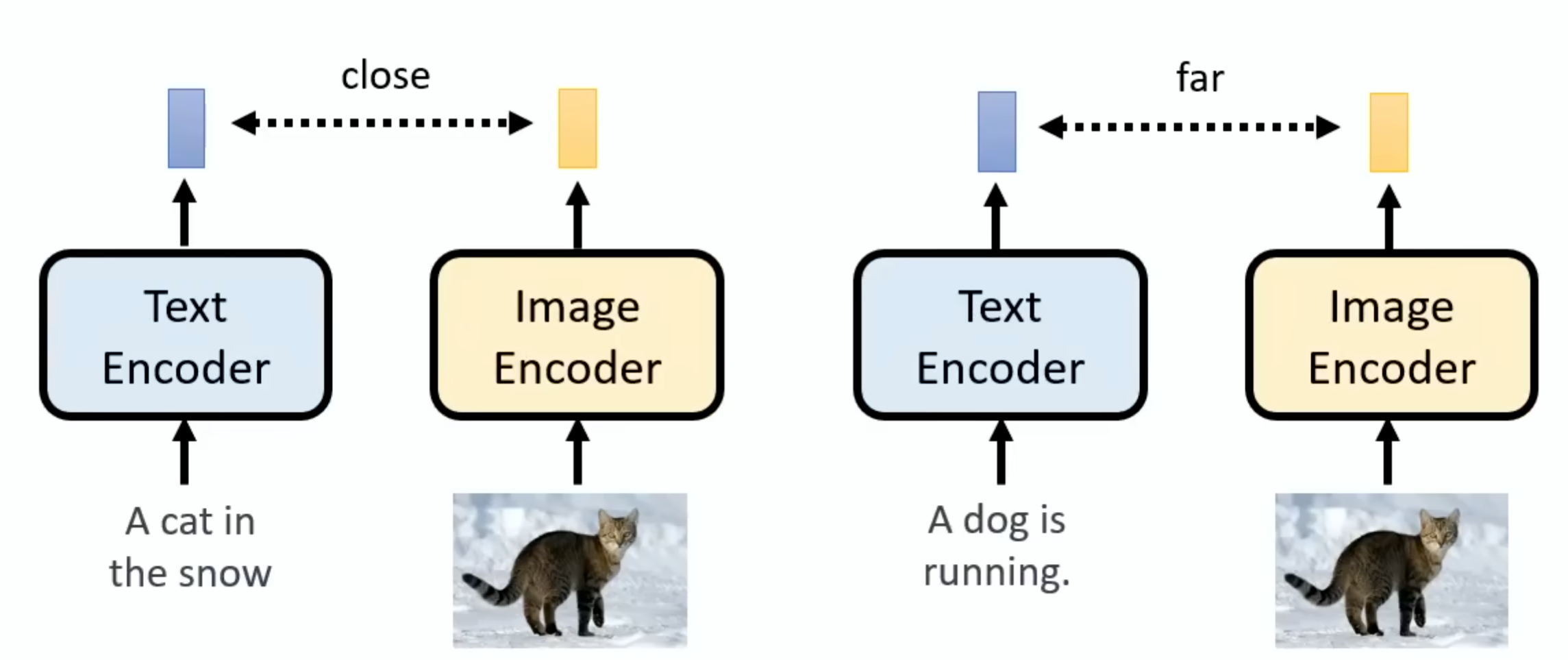
这个模型里面有一个Image Encoder和一个Text Encoder,这两个输入数据后分别产生一个向量,如果这个图片和文字相关的,那么这两个向量就越近越好,反之越远越好。
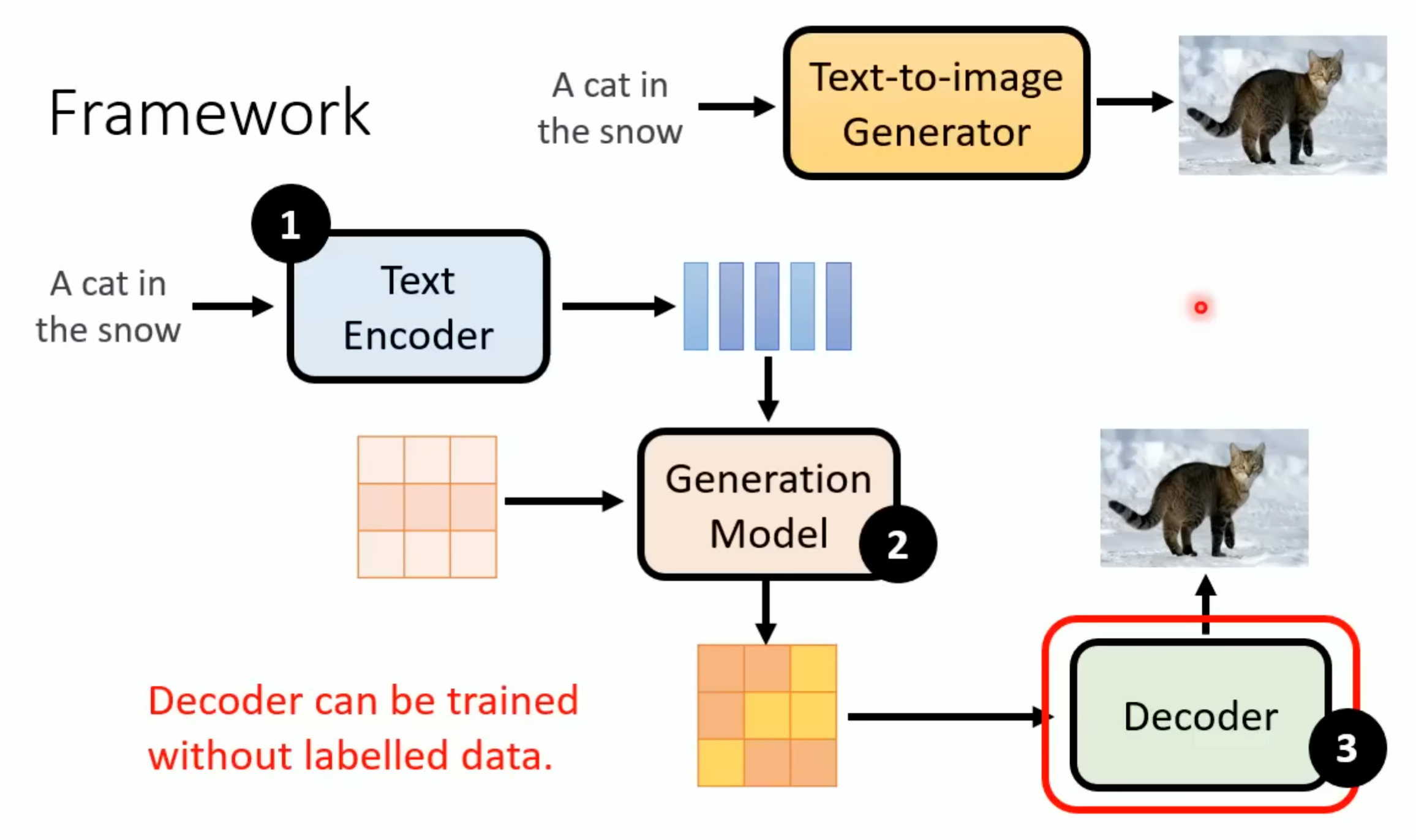
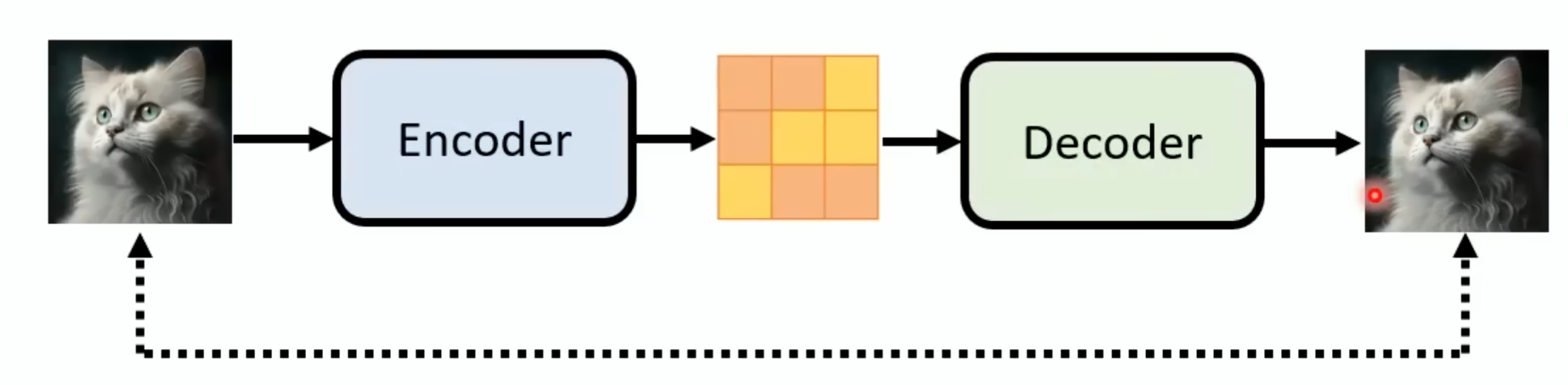
Decoder不需要图片和文字成对的资料,这个额外的Decoder的好处就在这里,这个docoder的训练:如果中间产物是小图,那只用把手上的图片找出来把他们变成小图然后进行训练。如果中间产物是Latent Representation,那就需要训练一个Auto-encoder,这里就是vae的decoder:
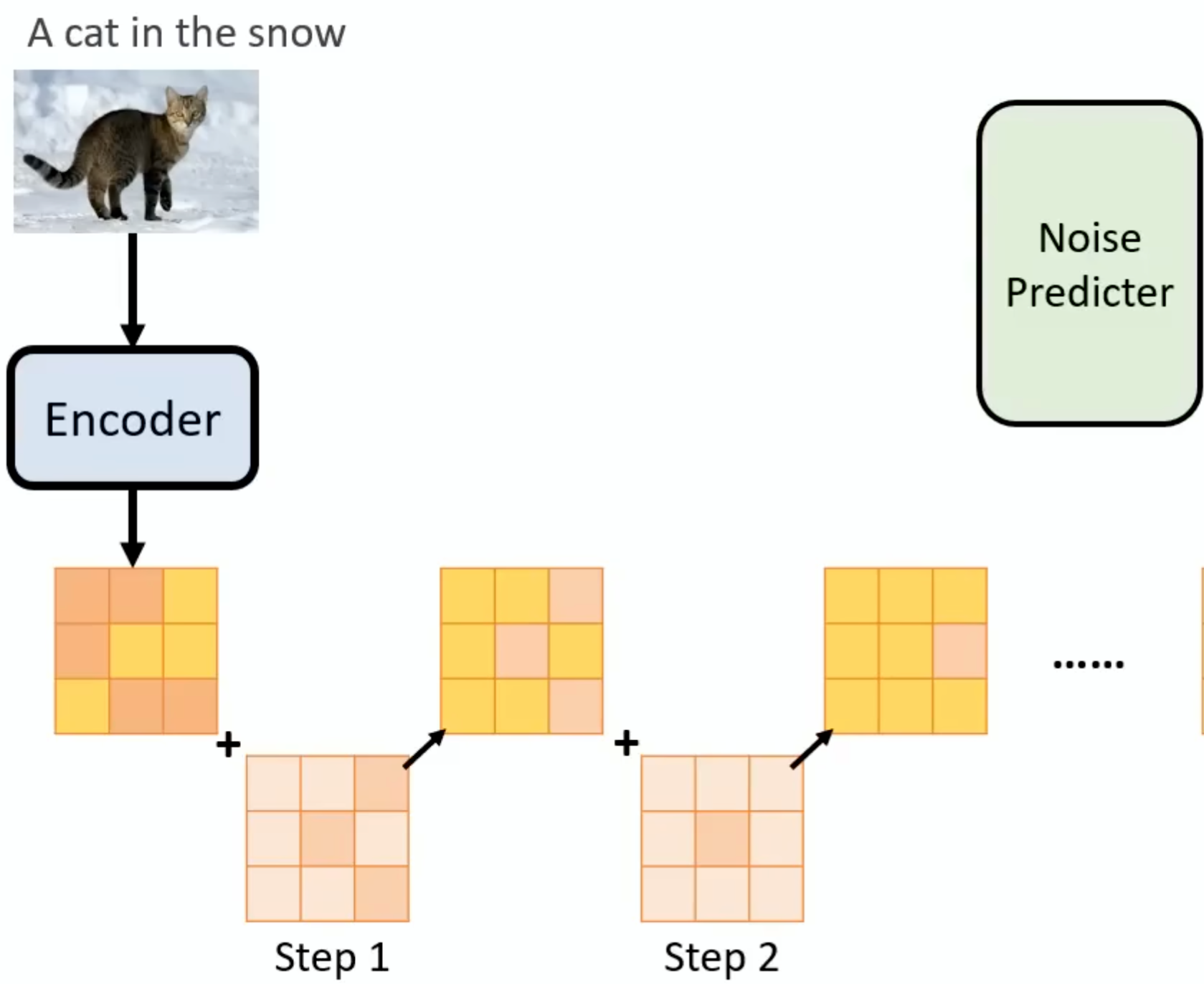
对于Generation Model部分,与之前不同,此时我们输入的东西已经不是图片了,这个noise需要加在中间产物上,先拿Encoder产生中间产物,然后把noise加载中间产物上,这个过程重复多次:
对于Noise Predicter的操作就和diffusion的差不多。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)