
ICLR 2025 | Sergey Levine团队 WSRL 横空出世:RL微调告别离离线数据,学习速度&性能双突破!
WSRL。这是他和Paul Zhou、Andy Peng等人共同完成的研究:在强化学习(RL)领域,现有范式常通过离线RL预训练后结合在线数据微调,但主流方法需持续用离线数据,存在效率低、成本高的问题。方法,证明微调离线RL初始化模型时无需保留离线数据。该方法先明确保留离线数据主要为避免在线微调初期因分布不匹配引发的价值函数骤降与“灾难性遗忘”,随后引入预热阶段,用预训练策略采集少量在线轨迹初始化
1. 【前言】
π联合创始人、UC Berkeley 副教授、强化学习大牛 Sergey Levine 在7月份发布了一项新成果:WSRL。这是他和Paul Zhou、Andy Peng等人共同完成的研究:
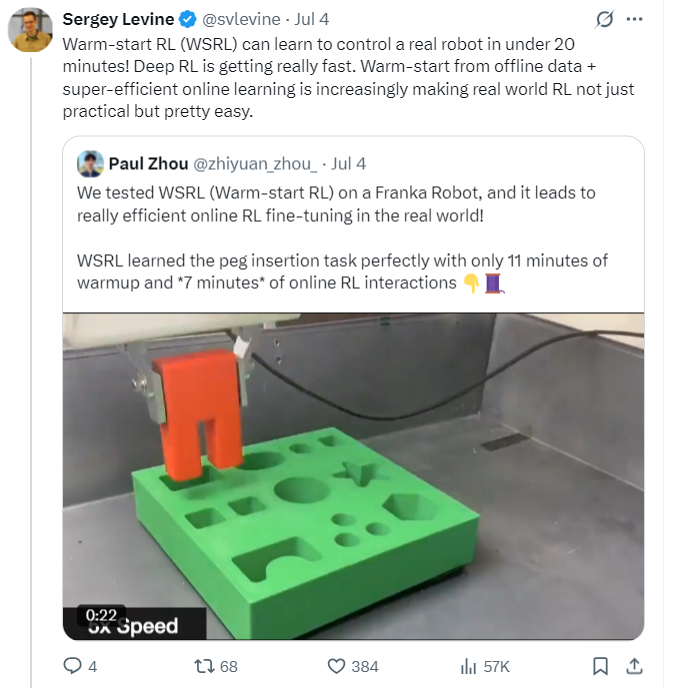
在强化学习(RL)领域,现有范式常通过离线RL预训练后结合在线数据微调,但主流方法需持续用离线数据,存在效率低、成本高的问题。Warm - start RL(WSRL) 方法,证明微调离线RL初始化模型时无需保留离线数据。该方法先明确保留离线数据主要为避免在线微调初期因分布不匹配引发的价值函数骤降与“灾难性遗忘”,随后引入预热阶段,用预训练策略采集少量在线轨迹初始化回放缓冲区,桥接分布差异并校准离线Q函数。实验表明,WSRL无需离线数据,仍比现有算法实现更快速的学习与更优渐近性能,在真实机器人插销任务中18分钟即达成完美效果。
今天,让我们一起来看一下这篇论文研究
2. 【论文基本信息】

论文标题:Efficient Online Reinforcement Learning Fine-Tuning Need Not Retain Offline Data
作者:Zhiyuan Zhou*, Andy Peng*, Qiyang Li, Sergey Levine, Aviral Kumar(*表示同等贡献)
作者机构:1. University of California, Berkeley (UC Berkeley);2. Carnegie Mellon University
论文来源: ICLR 2025
论文链接:https://arxiv.org/abs/2412.07762v3
项目链接:代码仓库链接为 https://github.com/zhouzypaul/wsrl;机器人实验代码仓库链接为 https://github.com/zhouzypaul/wsrl-robot
3.【背景及相关工作】
3.1 研究背景
- RL主流范式:遵循“离线RL预训练+在线RL微调”,但现有微调需持续用离线数据,否则易因离线-在线数据分布偏移,导致Q值发散、预训练知识遗忘(“螺旋式下降”)。
- 核心问题:离线数据虽能初期稳定训练,却因规模大导致训练低效,且长期使用损害渐近性能;现有方法无法在无离线数据时高效微调。
- 研究目标:构建无需保留离线数据,仍能避免遗忘、高效在线微调的RL方法。
3.2 相关工作
- 离线到在线RL:如CQL、IQL、CalQL,均依赖离线数据保留,无数据时失效;JSRL用预训练策略却丢弃价值函数,未充分利用预训练成果。
- RL微调瓶颈:已有研究发现离线数据可缓解分布偏移,但未分析无数据时的“螺旋式下降”;本研究补充“校准Q值(如CalQL)仍无法避免遗忘”的关键结论。
- 无预训练的在线RL:直接用“离线+在线数据”从头学,部分场景优于“预训练+微调”,凸显现有流程缺陷;本研究通过优化微调环节,证明预训练价值。
- 无数据保留的RL微调:持续/终身RL、元RL聚焦多任务/环境,与本研究“单环境单任务”不同;单任务On-policy RL(如PPO)样本效率低,解决遗忘策略与本研究(Off-policy)差异大。
4.【创新解法:WSRL 算法】
4.1 问题建模:无离线数据的RL微调
- 场景:无限时域MDP M = { S , A , P , r , γ , ρ } M=\{S, A, P, r, \gamma, \rho\} M={S,A,P,r,γ,ρ}, S / A S/A S/A 为状态/动作空间, P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a) 为转移函数, r r r 为奖励, γ \gamma γ 为折扣因子, ρ \rho ρ 为初始状态分布。
- 目标:仅用离线预训练的策略 π ψ p r e ( a ∣ s ) \pi_{\psi}^{pre}(a|s) πψpre(a∣s) 和Q函数 Q θ p r e ( s , a ) Q_{\theta}^{pre}(s,a) Qθpre(s,a)(无 D o f f D_{off} Doff),最大化折扣回报:
η ( π ) = E s t + 1 ∼ P , a t ∼ π , s 0 ∼ ρ ∑ t = 0 ∞ γ t r ( s t , a t ) \eta(\pi)=\mathbb{E}_{s_{t+1}\sim P,a_t\sim\pi,s_0\sim\rho}\sum_{t=0}^{\infty}\gamma^t r(s_t,a_t) η(π)=Est+1∼P,at∼π,s0∼ρ∑t=0∞γtr(st,at)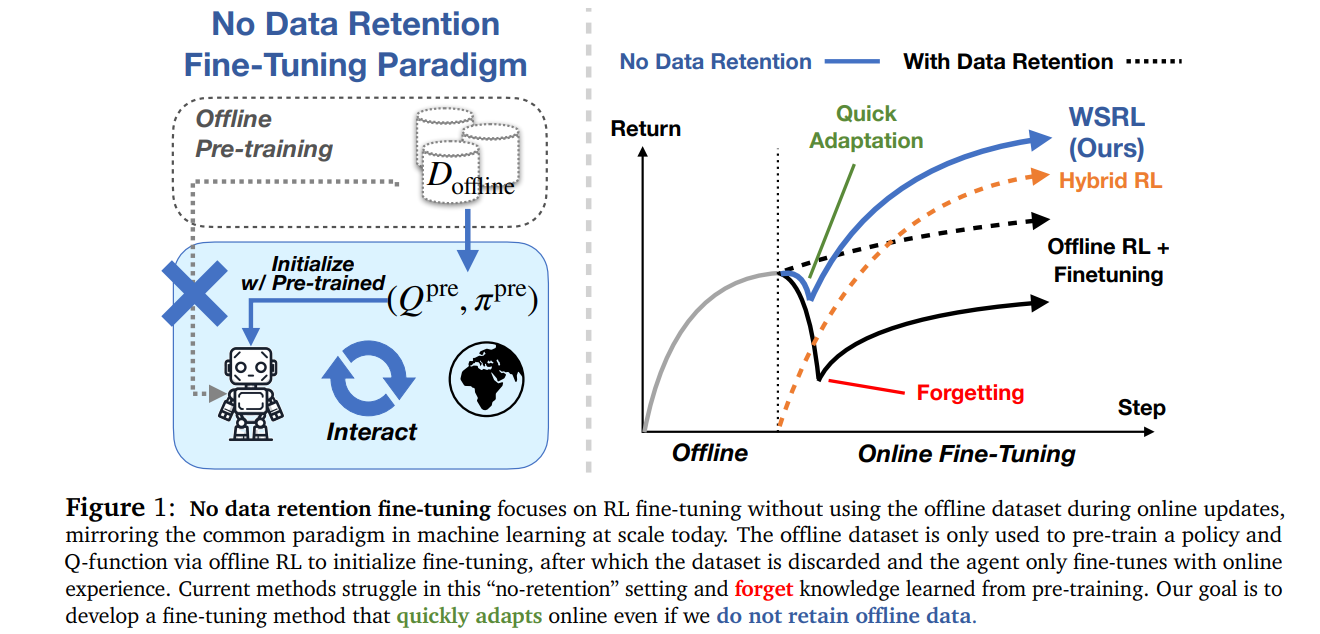
4.2 关键问题分析
4.2.1 离线数据的必要性
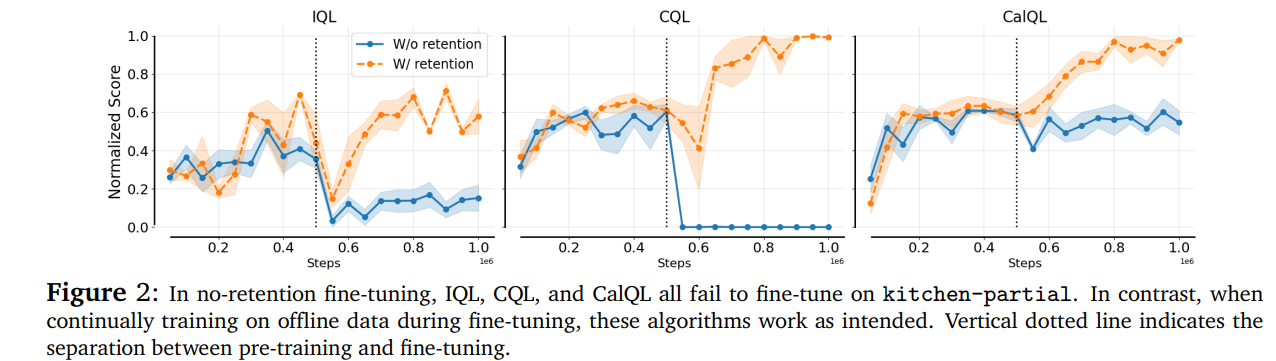
无离线数据时,“离线-在线分布偏移”导致Q值发散:离线分布下Q值/TD误差飙升,引发“非学习”(性能骤降)或“遗忘”(预训练失效);保守型算法(如CQL)的悲观TD目标还会造成Q值“螺旋式下降”。
4.2.2 离线数据的缺陷
持续用离线数据混训(如CalQL)会拖累长期性能,速度远慢于从scratch的在线RL(如RLPD)。
4.3 WSRL算法设计
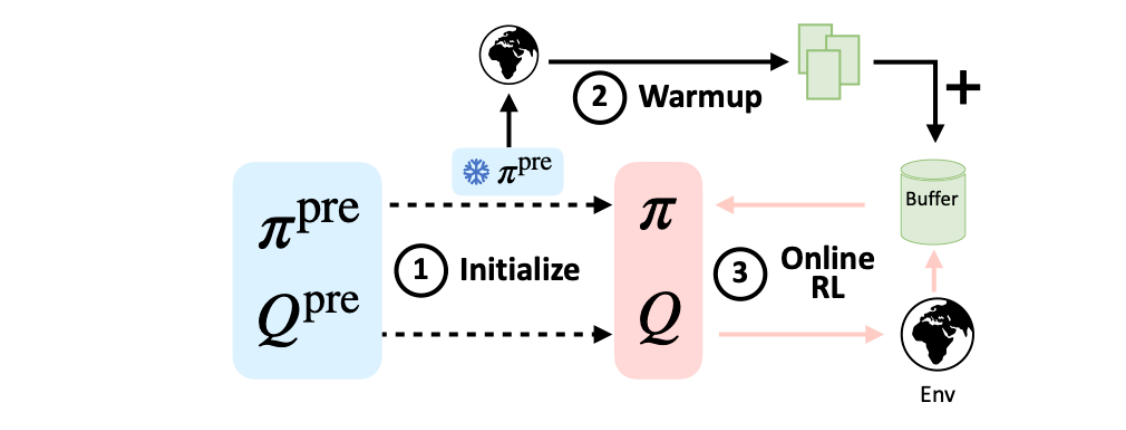
4.3.1 核心思路
用“热身阶段桥接分布偏移”+“纯在线RL更新”,结合高更新数据比(UTD),实现无 D o f f D_{off} Doff 的高效微调。
4.3.2 三阶段流程
- 初始化:用任意离线RL(如CQL)预训练得到 π ψ p r e \pi_{\psi}^{pre} πψpre 和 Q θ p r e Q_{\theta}^{pre} Qθpre,直接初始化在线网络。
- 热身(K=5000步):冻结 π ψ p r e \pi_{\psi}^{pre} πψpre 收集少量轨迹,存入回放缓冲区以缓解分布偏移。
- 在线更新:用无约束SAC更新,高UTD=4(1批数据对应4次Q更新+1次策略更新);用10Q网络集成(采样2个取min)+层归一化稳定训练。
4.3.3 核心公式
- Q函数更新:最小化TD损失
L ( θ ) = E ( s , a , s ′ , r ) ∼ R [ ( Q θ ( s , a ) − ( r + γ min i Q θ i ′ ( s ′ , a ′ ) ) ) 2 ] \mathcal{L}(\theta)=\mathbb{E}_{(s,a,s',r)\sim\mathcal{R}}\left[\left(Q_{\theta}(s,a)-\left(r+\gamma\min_i Q_{\theta_i'}(s',a')\right)\right)^2\right] L(θ)=E(s,a,s′,r)∼R[(Qθ(s,a)−(r+γminiQθi′(s′,a′)))2] - 策略更新:最大化Q值与熵的联合目标
∇ ψ E s ∼ R , a ∼ π ψ [ Q θ ( s , a ) + α H ( π ψ ( ⋅ ∣ s ) ) ] \nabla_{\psi}\mathbb{E}_{s\sim\mathcal{R},a\sim\pi_{\psi}}\left[Q_{\theta}(s,a)+\alpha\mathcal{H}(\pi_{\psi}(\cdot|s))\right] ∇ψEs∼R,a∼πψ[Qθ(s,a)+αH(πψ(⋅∣s))]
5.【核心问题分析】
5.1 为何传统方法离不开离线数据?
离线数据与在线交互数据存在“分布偏移”:若微调只用地道在线数据,模型对离线数据的拟合度会急剧下降——即便在线数据的TD误差(衡量预测精度)变化不大,离线分布下的TD误差却会显著飙升,直接导致训练失控。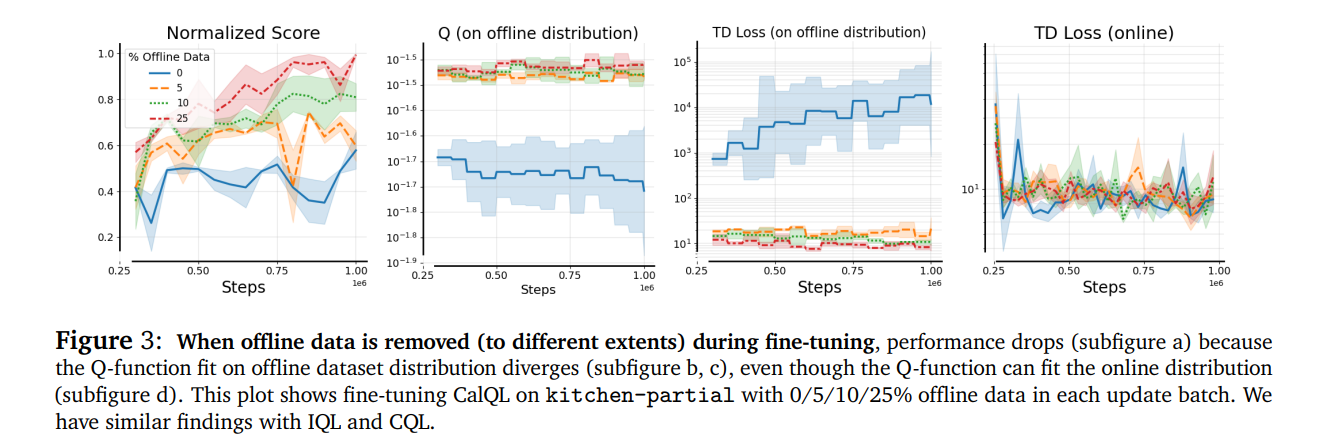
5.2 致命的“Q值螺旋式下降”
不保留离线数据时,不仅离线分布的Q值会发散,在线分布的Q值也会在微调初期“过度低估”。根源在于:Q值校准过程中,TD目标(更新依据)过于悲观,形成“低估→更新偏差→更严重低估”的恶性循环,最终让模型彻底遗忘预训练知识。
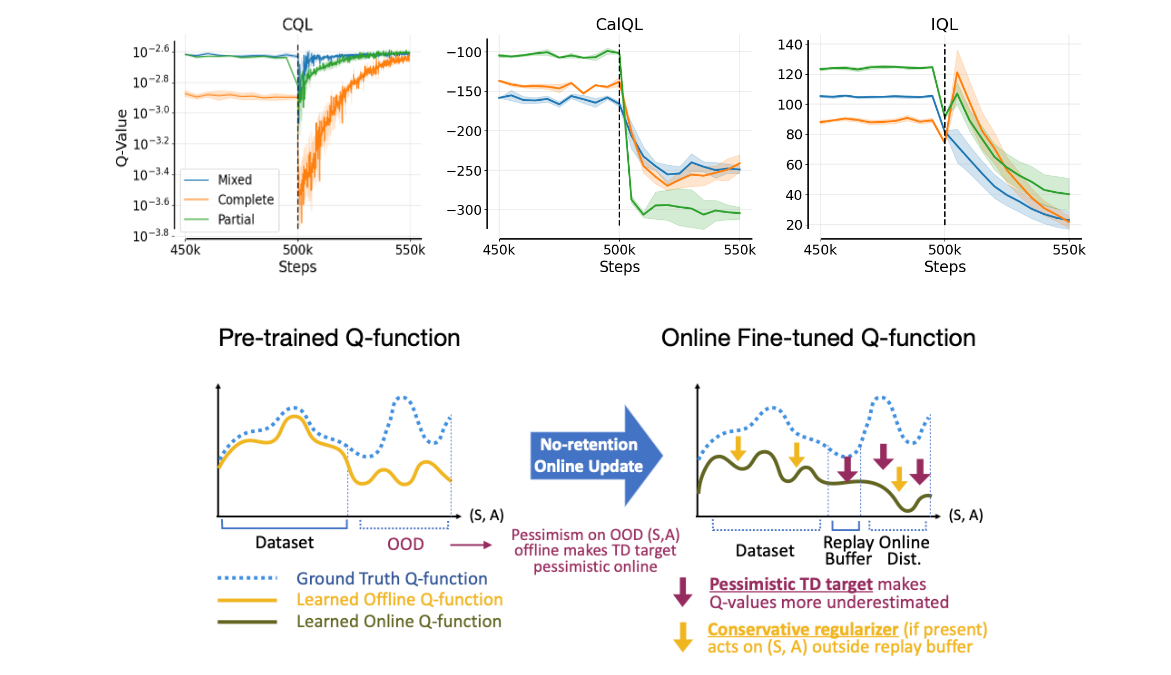
5.3 保留离线数据的悖论
虽然离线数据能稳住微调初期的训练,但用悲观型离线RL算法持续更新,会严重拖累长期性能与效率——研究发现,依赖离线数据的CalQL等方法,比“从 scratch 的在线RL(如RLPD)”慢得多,相当于“为了起步稳,牺牲了全程速度”。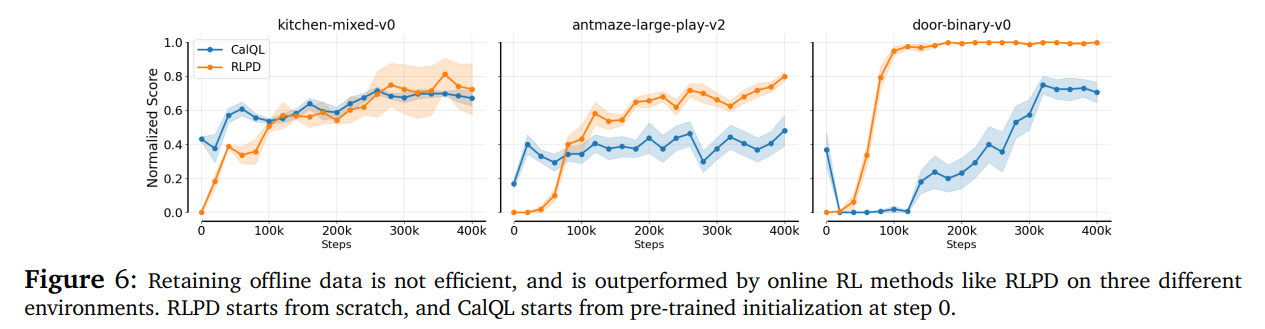
6.【实验结果:碾压式优势】
6.1 无离线数据场景:断层领先
在“不保留离线数据”的微调任务中,WSRL轻松化解传统算法的“初期性能暴跌”问题,效率和最终性能远超IQL、CQL、CalQL等方法——后者要么直接失效,要么难以恢复状态,而WSRL能稳定复用预训练优势。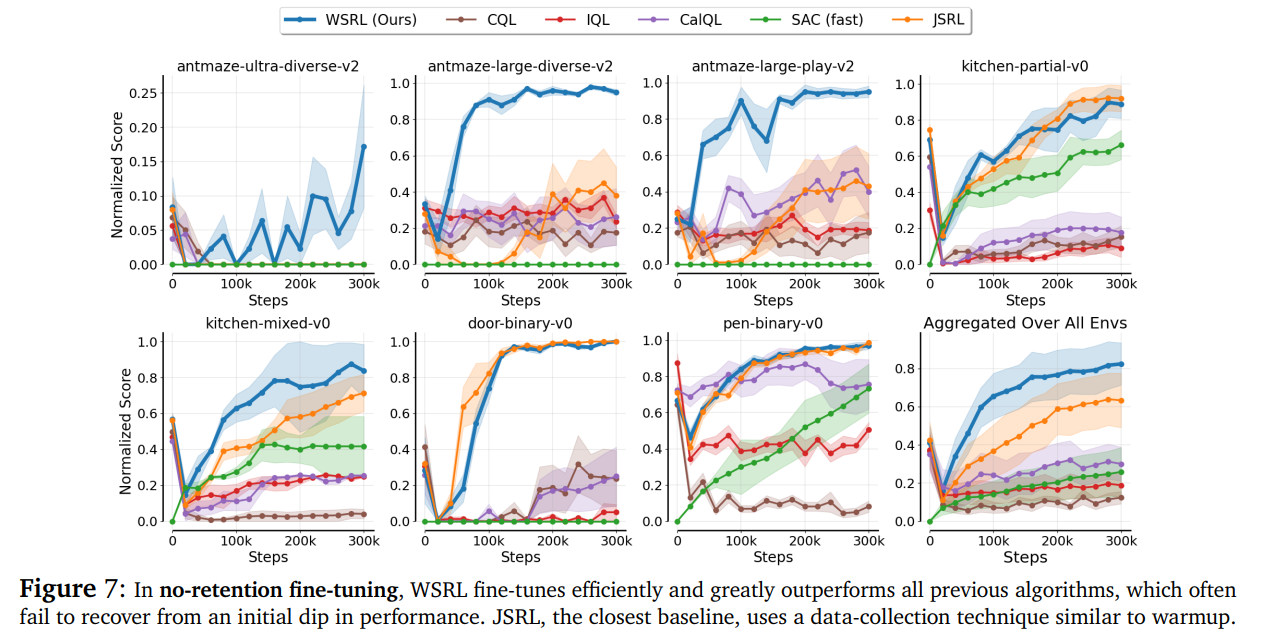
6.2 对标保留离线数据的方法:毫不逊色
即便与“手握离线数据、信息更充足”的传统方法比,WSRL在不依赖离线数据的情况下,要么微调速度更快,要么性能持平——彻底打破了“无离线数据就做不好微调”的固有认知。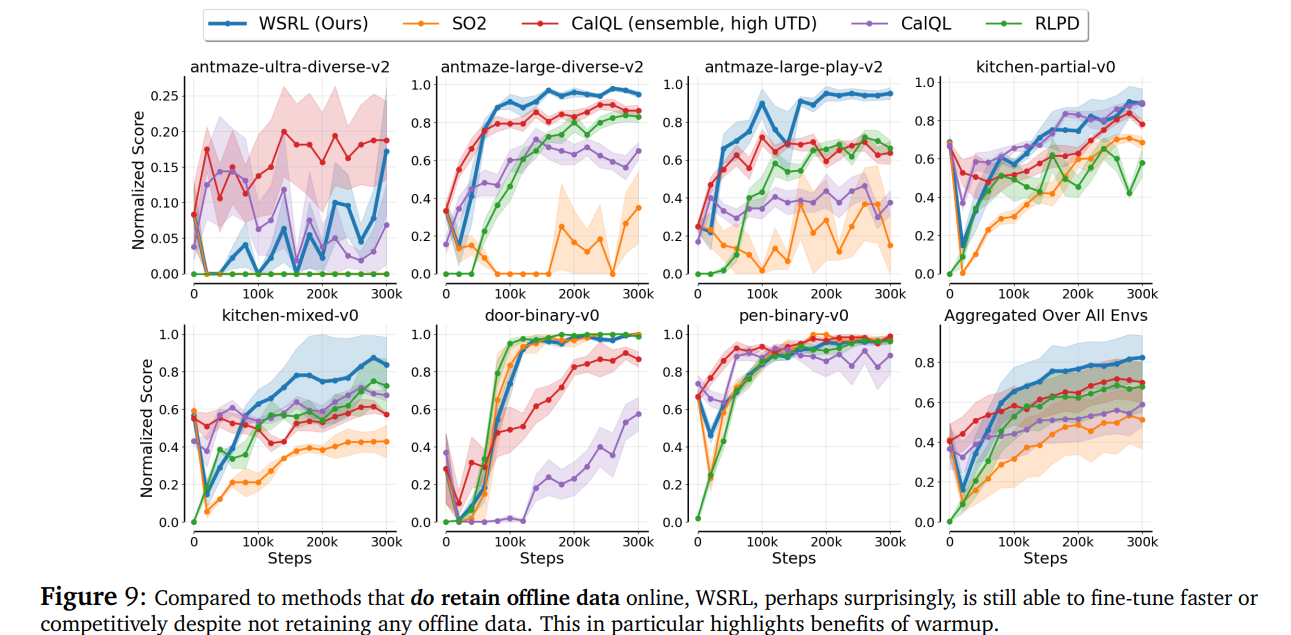
6.3 关键组件验证
消融实验证明:热身阶段、纯在线RL更新、预训练初始化,三者缺一不可——少了任何一步,WSRL的性能都会大幅下滑,印证了设计逻辑的严谨性。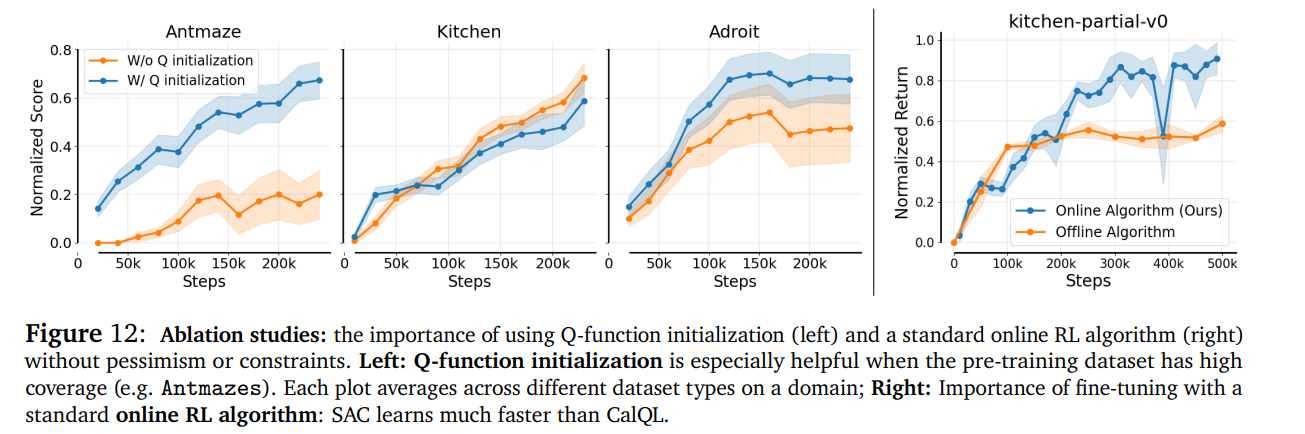
7.【研究价值】
- 成本革命:无需存储和处理大规模离线数据,极大降低RL规模化应用的算力与存储成本。
- 效率突破:既解决了“无离线数据的遗忘问题”,又规避了“保留离线数据的性能拖累”,让RL“预训练+微调”真正落地实用。
- 范式启发:为RL与LLM等领域的“无数据保留微调”提供了新思路,证明“复用预训练成果”不必依赖原始数据。
8.【快速上手指南】
8.1 环境搭建
8.1.1 基础环境安装
- 首先创建并激活名为
wsrl的conda环境,指定Python版本为3.10:conda create -n wsrl python=3.10 -y conda activate wsrl - 安装项目依赖包:
pip install -r requirements.txt
8.1.2 JAX安装
执行以下命令安装适配CUDA 11的JAX(版本0.4.20):
pip install --upgrade "jax[cuda11_pip]==0.4.20" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
8.1.3 D4RL环境安装
需安装项目作者fork的D4RL仓库(已集成antmaze-ultra环境,并修复厨房环境奖励与离线数据集的一致性问题):
git clone git@github.com:zhouzypaul/D4RL.git
cd D4RL
pip install -e .
8.1.4 Mujoco安装与环境变量配置
- 手动下载Mujoco(参考官方指引),并解压至
~/.mujoco/目录; - 配置环境变量以加载Mujoco库:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HOME/.mujoco/mujoco210/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/nvidia
8.1.5 Adroit环境安装与数据集准备
- 克隆并安装Adroit相关环境库:
git clone --recursive https://github.com/nakamotoo/mj_envs.git cd mj_envs git submodule update --remote pip install -e . - 从官方链接下载Adroit数据集,解压至
~/adroit_data/目录;若需自定义数据集路径,可通过环境变量指定:export DATA_DIR_PREFIX=/path/to/your/data
8.2 模型运行
8.2.1 核心运行脚本与配置文件
- 项目主运行脚本为
finetune.py; - 不同环境(如Antmaze、Adroit等)的训练脚本(用于运行WSRL、IQL、CQL、CalQL、RLPD等算法)存放于
experiments/scripts/<ENV>目录; - 共享智能体配置文件位于
experiments/configs/*,环境专属配置文件分别在experiments/configs/train_config.py与各bash脚本中。
8.2.2 预训练操作
根据目标环境选择对应脚本执行预训练,示例如下:
- Antmaze环境(CalQL预训练,启用Q网络集成):
bash experiments/scripts/antmaze/launch_calql_finetune.sh --use_redq --env antmaze-large-diverse-v2 - Adroit环境(CalQL预训练,启用Q网络集成):
bash experiments/scripts/adroit/launch_calql_finetune.sh --use_redq --env door-binary-v0 - Kitchen环境(CalQL预训练,启用Q网络集成):
bash experiments/scripts/kitchen/launch_calql_finetune.sh --use_redq --env kitchen-mixed-v0 - Mujoco运动环境(CQL预训练,因MC回报估算难度较高):
bash experiments/scripts/locomotion/launch_cql_finetune.sh --use_redq --env halfcheetah-medium-replay-v0
8.2.3 微调操作
基于预训练 checkpoint 运行WSRL微调,示例如下:
- Antmaze环境:
bash experiments/scripts/antmaze/launch_wsrl_finetune.sh --env antmaze-large-diverse-v2 --resume_path /path/to/checkpoint - Adroit环境:
bash experiments/scripts/adroit/launch_wsrl_finetune.sh --env door-binary-v0 --resume_path /path/to/checkpoint - Kitchen环境:
bash experiments/scripts/kitchen/launch_wsrl_finetune.sh --env kitchen-mixed-v0 --resume_path /path/to/checkpoint - Mujoco运动环境:
bash experiments/scripts/locomotion/launch_wsrl_finetune.sh --env halfcheetah-medium-replay-v0 --resume_path /path/to/checkpoint
8.2.4 离线数据保留设置
项目默认遵循论文设定,微调过程中不保留离线数据;若需开启离线数据保留,可通过--offline_data_ratio <数值>或--online_sampling_method append参数配置,具体细节可参考finetune.py脚本说明。
对于做机器人控制、自动驾驶等需RL落地的研究者/工程师来说,WSRL可能是近期最值得尝试的微调方案——代码已开源(见前文项目链接),快用它拯救你的RL训练效率吧!!
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)