
一.Yolov8量化感知训练微调(QAT)第二篇: 单batch和多batch导出onnx和engine模型 (Tensorrt推理)
一.最最最重要的官方ultralytics量化速度信息二.设置onnx模型导出的输出头数量和输出头维度三. 设置单batch和多batch的onnx模型导出四. onnx导出为tensorrt的engine模型五. 验证tensorrt的engine模型六. 额外知识点
一. 最最最重要的官方ultralytics信息
下面是官方ultralytics上的TensorRT的FP32, FP16, INT8在GPU显卡上推理的时间对比:
官方ultralytics的TensorRT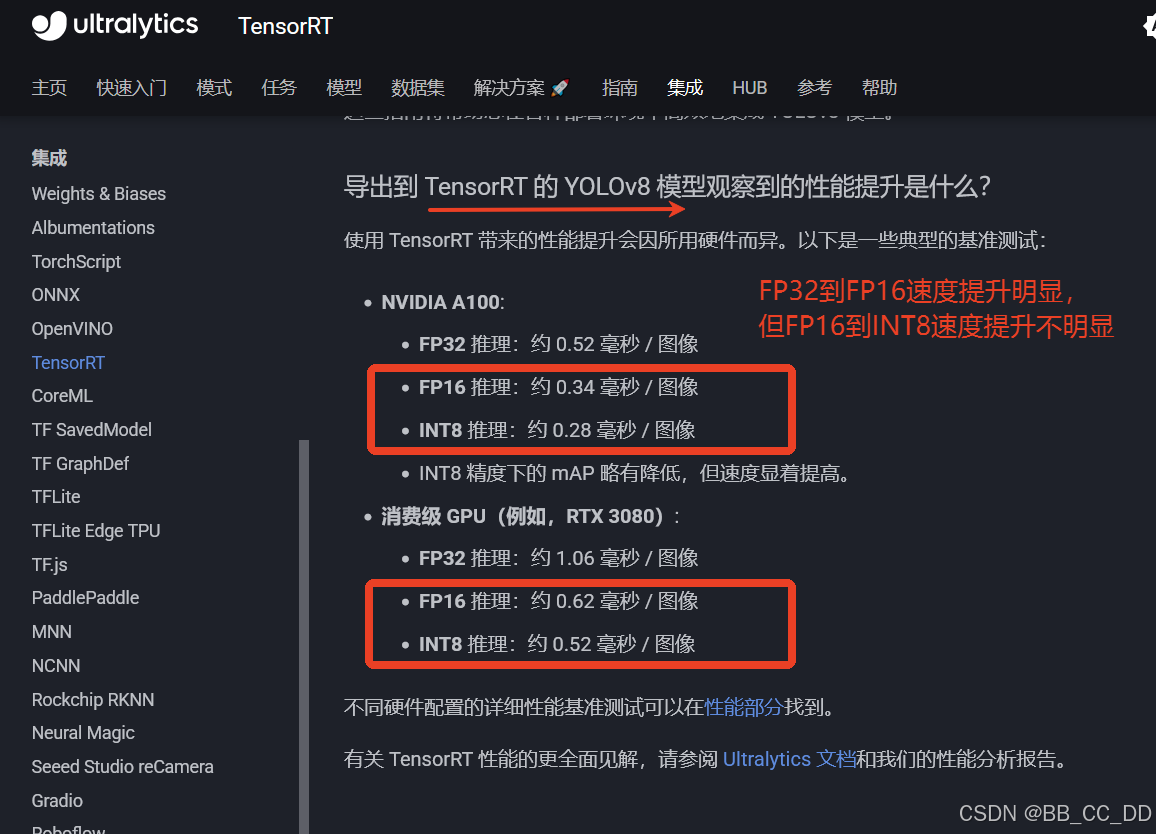
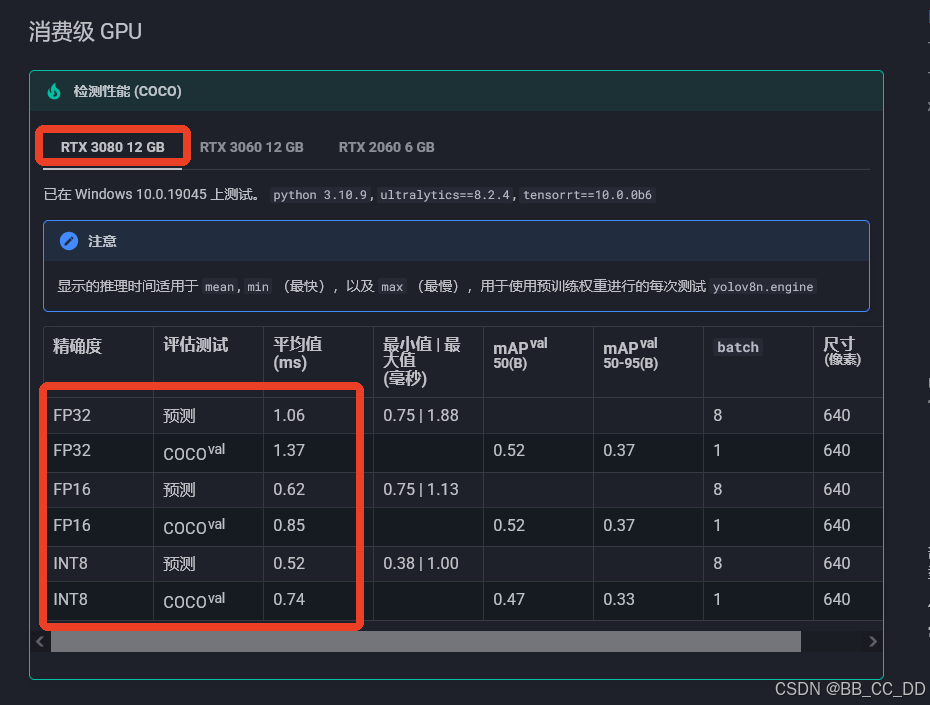
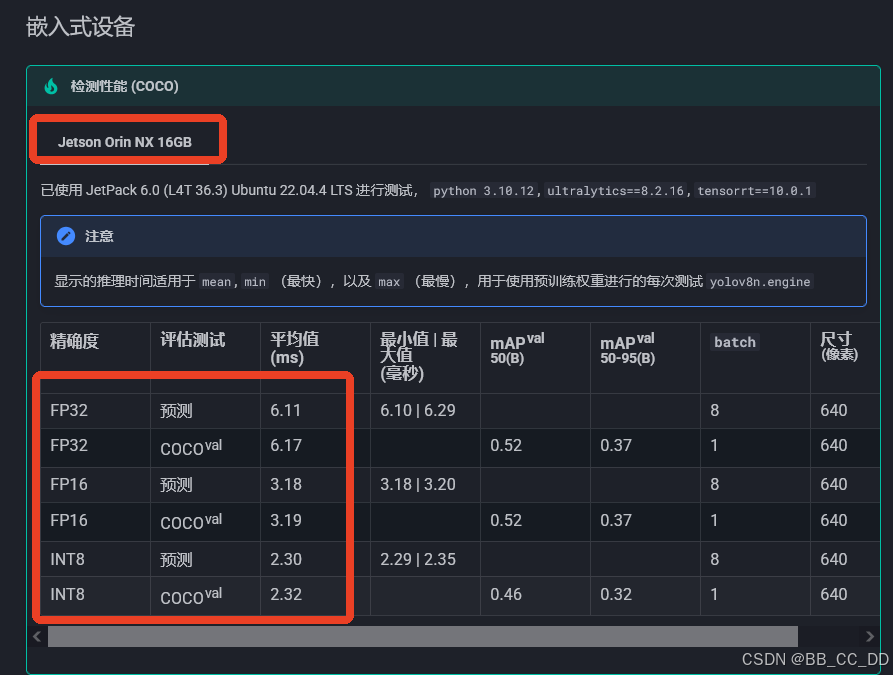
可以看出, 对于Yolov8而言, FP32--->FP16速度提升明显, 约能提升50%的速度, 但FP16--->INT8速度提升不明显, 约10%-25%, 不同设备提升速度不一样.
二.设置onnx模型导出的输出头数量和输出头维度
下面先以单batch推理为例(dynamic=False), 单batch推理能正常导出onnx模型, 那么多batch (dynamic=True) 也能正常导出onnx模型.
1. 设置onnx模型的输出头节点的数量
按照yolo官方的onnx导出, 是一个输出头, 如下图所示, 我们尽量不改变官方的输出头结构, 也设置一个输出头.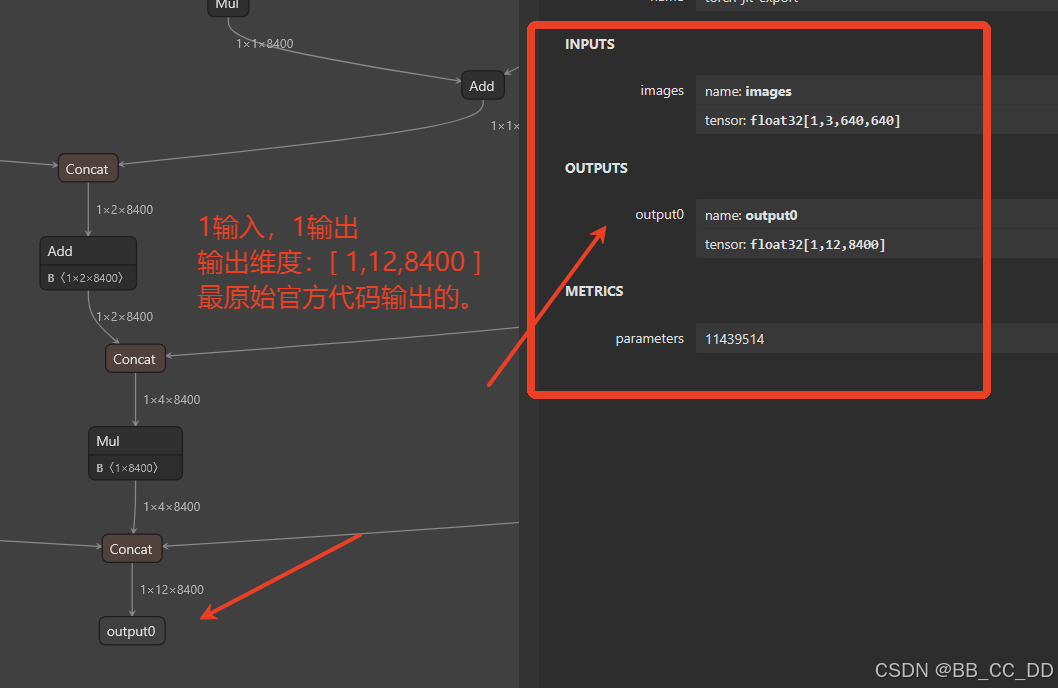
1.1 在多头输出的情况下, 如何修改为一个头输出.
下面代码所示, 附带上需要导出量化节点的quant_export_onnx()函数, 如果不要量化节点, 去掉quant_nn.TensorQuantizer.use_fb_fake_quant的代码, 或者全都赋值为False即可, 这是要被调用的单独接口.
def quant_export_onnx(model, input, file, *args, **kwargs):
quant_nn.TensorQuantizer.use_fb_fake_quant = True
model.eval()
with torch.no_grad():
torch.onnx.export(model, input, file, *args, **kwargs)
quant_nn.TensorQuantizer.use_fb_fake_quant = False
下面是整个onnx模型导出的函数接口:
1> 下面的dynamic = False是表示单batch推理的onnx模型导出设置, 若dynamic = True则是多batch推理的onnx模型导出设置;
2> 用到simplify参数对onnx模型进行简化, 加快onnx模型推理(simplify参数可以在ultralytics/cfg/default.yaml中设置, 也可以在进行传参或在代码中直接设置):
# 源代码 export onnx
def export_onnx(model : OBBModel, save_file, size=(640,640), dynamic_batch=False, noanchor=False, prefix=colorstr('ONNX:')):
"""YOLOv8 ONNX export."""
"""
model: DetectionModel class
"""
requirements = ['onnx>=1.12.0']
check_requirements(requirements)
output_names = ['output']
dynamic = False
if dynamic:
dynamic['output0'] = {0: 'batch', 2: 'anchors'}
device = next(model.parameters()).device
imgsz = check_imgsz(size, stride=model.stride, min_dim=2) # cfg.imgsz
# im = torch.zeros(1, 1, *imgsz).to(device) # 1 ch cfg.batch
im = torch.zeros(1, 3, *imgsz).to(device) # 1 ch cfg.batch
quant_export_onnx(model.cpu() if dynamic else model, # dynamic=True only compatible with cpu
im.cpu() if dynamic else im,
save_file,
verbose=False,
opset_version=13,
do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False
input_names=['images'],
output_names=output_names,
dynamic_axes=dynamic or None
)
# Simplify
model_onnx = onnx.load(save_file) # load onnx model
if cfg.simplify:
try:
LOGGER.info(f'{prefix} simplifying with onnxsim {onnxsim.__version__}...')
# subprocess.run(f'onnxsim "{f}" "{f}"', shell=True)
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, 'Simplified ONNX model could not be validated'
except Exception as e:
LOGGER.info(f'{prefix} simplifier failure: {e}')
onnx.save(model_onnx, save_file)
1.1.1 修改代码, 删除不需要的输出头:
需要对上面的export_onnx()函数新增删除输出节点的代码:
##### 修改代码: 设置输入节点和输出节点 ################
output_names = ['output0'] # 设置输出节点名(可以设置任何名字)
dynamic = dynamic_batch # dynamic_batch为False是单batch, True多batch
if dynamic:
dynamic = {'images': {0: 'batch'}} # shape(1,3,640,640) # 设置输入维度
dynamic[output_names[0]] ={0: 'batch'} # shape(1,3,640,640) # 设置输出维度
# Simplify
model_onnx = onnx.load(save_file) # load onnx model
####### 新增代码: 删除不需要的输出节点 ################
# 删除不需要的输出节点
for output in model_onnx.graph.output[1:]:
model_onnx.graph.output.remove(output)
########################
上面的代码是保留第一个输出节点, 删除第二个及以后的节点. 如果有其他输出节点要删除, 需要根据输出的onnx和netron进行查看, 然后删除想要删除的输出节点.
netron --host 192.168.xx.xx --port xxxx qat.onnx
修改后的完整代码:
def export_onnx(model : OBBModel, save_file, size=(640,640), dynamic_batch=False, noanchor=False, prefix=colorstr('ONNX:')):
"""YOLOv8 ONNX export."""
"""
model: DetectionModel class
"""
requirements = ['onnx>=1.12.0']
check_requirements(requirements)
output_names = ['output0'] # 设置输出节点名(可以设置任何名字)
dynamic = dynamic_batch # dynamic_batch为False是单batch, True多batch
if dynamic:
dynamic = {'images': {0: 'batch'}} # shape(1,3,640,640) # 设置输入维度
dynamic[output_names[0]] ={0: 'batch'} # shape(1,3,640,640) # 设置输出维度
device = next(model.parameters()).device
imgsz = check_imgsz(size, stride=model.stride, min_dim=2) # cfg.imgsz
# im = torch.zeros(1, 1, *imgsz).to(device) # 1 ch cfg.batch
im = torch.zeros(1, 3, *imgsz).to(device) # 1 ch cfg.batch
quantize.export_onnx(model.cpu() if dynamic else model, # dynamic=True only compatible with cpu
im.cpu() if dynamic else im,
save_file,
verbose=False,
opset_version=13,
do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False
input_names=['images'],
output_names=output_names,
dynamic_axes=dynamic or None
)
# Simplify
model_onnx = onnx.load(save_file) # load onnx model
# Delete unnecessary outputs输出节点
for output in model_onnx.graph.output[1:]:
model_onnx.graph.output.remove(output)
if cfg.simplify:
try:
LOGGER.info(f'{prefix} simplifying with onnxsim {onnxsim.__version__}...')
# subprocess.run(f'onnxsim "{f}" "{f}"', shell=True)
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, 'Simplified ONNX model could not be validated'
except Exception as e:
LOGGER.info(f'{prefix} simplifier failure: {e}')
onnx.save(model_onnx, save_file)
# 打印模型的输出形状以验证
for output in model_onnx.graph.output:
print(f"Output name: {output.name}, shape: {[dim.dim_value for dim in output.type.tensor_type.shape.dim]}")
2. 根据自己tensorrt代码, 设置onnx模型输出头的维度
下面以(640, 640)图像尺寸大小为例:
我们的代码的输出维度是(1,8400,12), 所以要把yolo官方输出的维度(1, 12, 8400)修改为(1,8400,12), 如下图所示, 就是我们想要的输出维度(1,8400,12).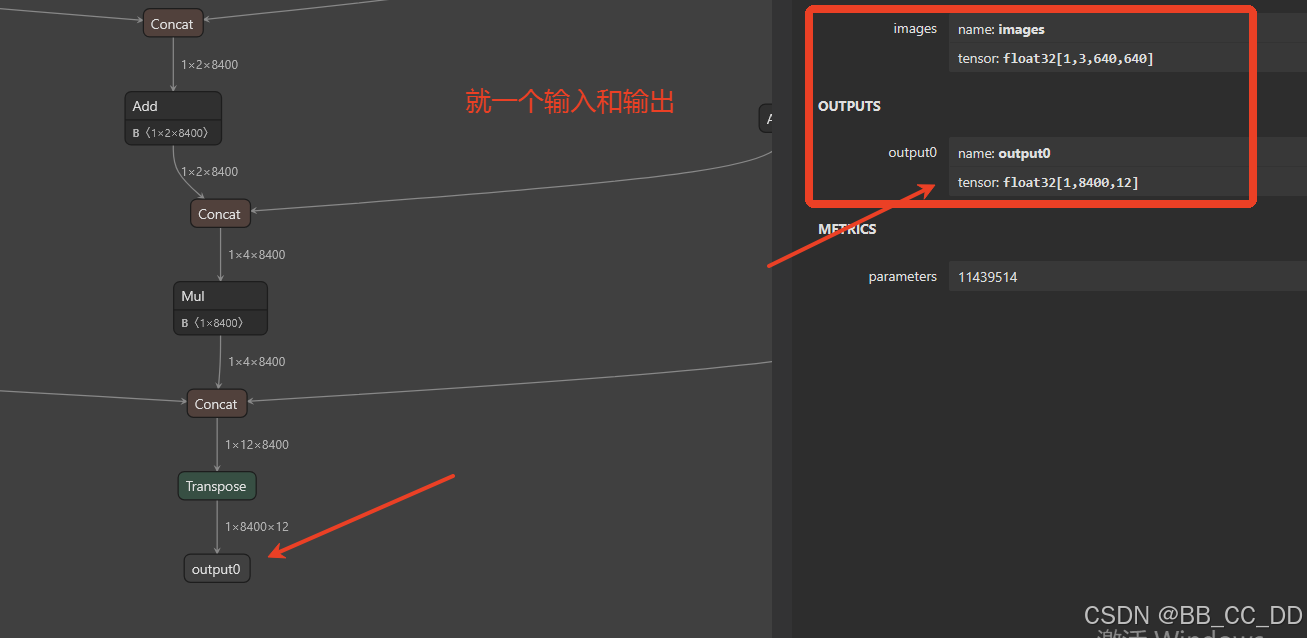 按照上面的步骤, 已经修改了onnx模型输出头的数量, 这里需要修改输出头的维度, 将最后两个维度进行互换.
按照上面的步骤, 已经修改了onnx模型输出头的数量, 这里需要修改输出头的维度, 将最后两个维度进行互换.
2.1 添加transpose节点, 互换最后两个维度
# Simplify
model_onnx = onnx.load(save_file) # load onnx model
#删除不需要的输出节点
for output in model_onnx.graph.output[1:]:
model_onnx.graph.output.remove(output)
if cfg.simplify:
try:
LOGGER.info(f'{prefix} simplifying with onnxsim {onnxsim.__version__}...')
# subprocess.run(f'onnxsim "{f}" "{f}"', shell=True)
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, 'Simplified ONNX model could not be validated'
except Exception as e:
LOGGER.info(f'{prefix} simplifier failure: {e}')
######### 新增transpose节点, 互换最后两个维度 ###############
# 获取 output0 节点
output_node = model_onnx.graph.output[0]
shape = output_node.type.tensor_type.shape.dim
# 获取最后两个维度的大小
last_dim_1 = shape[-1].dim_value
last_dim_2 = shape[-2].dim_value
# 交换最后两个维度
shape[-1].dim_value = last_dim_2
shape[-2].dim_value = last_dim_1
# 创建 Transpose 节点来交换最后两个维度
transpose_node = helper.make_node(
'Transpose', # 节点类型, 把output0名修改为Transpose
inputs=[output_node.name], # 输入是 output0
outputs=['transpose_output'], # 输出是一个新的张量
perm=[0, 2, 1] # perm 为交换最后两个维度的顺序,[0, 2, 1]表示交换维度1和2
)
# 将 Transpose 节点和新的输出节点添加到计算图中
model_onnx.graph.node.append(transpose_node)
model_onnx.graph.output[0].name = 'transpose_output' # 最后一个输出节点名
#################################################
onnx.save(model_onnx, save_file)
三. 设置单batch和多batch的onnx模型导出.
1. 另一种单batch推理的onnx模型导出(修改yolo官方代码)
上面一.设置onnx模型导出的输出头数量和输出头维度的内容就是以单batch推理(dynamic=False)导出onnx模型, 下面介绍另一种的单batch推理导出onnx模型.
1.1 修改修改yolo官方代码, 在concat的时候用transpose直接修改最后两个维度
可以参考下面这篇文章, 能正常转多batch推理的onnx和engine模型:
yolov8/yolov11 obb的pt转onnx再转engine, 并支持onnx和engine模型多batch推理
2. 多batch推理onnx模型导出, 观察图形结构,分析onnx模型转出是否正确
2.1 修改dynamic=True
2.2 导出onnx模型, 查看图形结构
首先先看一下yolo官方导出的多batch的onnx模型的结构, 可以看到右边输入INPUTS的images的维度和输出的OUTPUTS的output0的维度.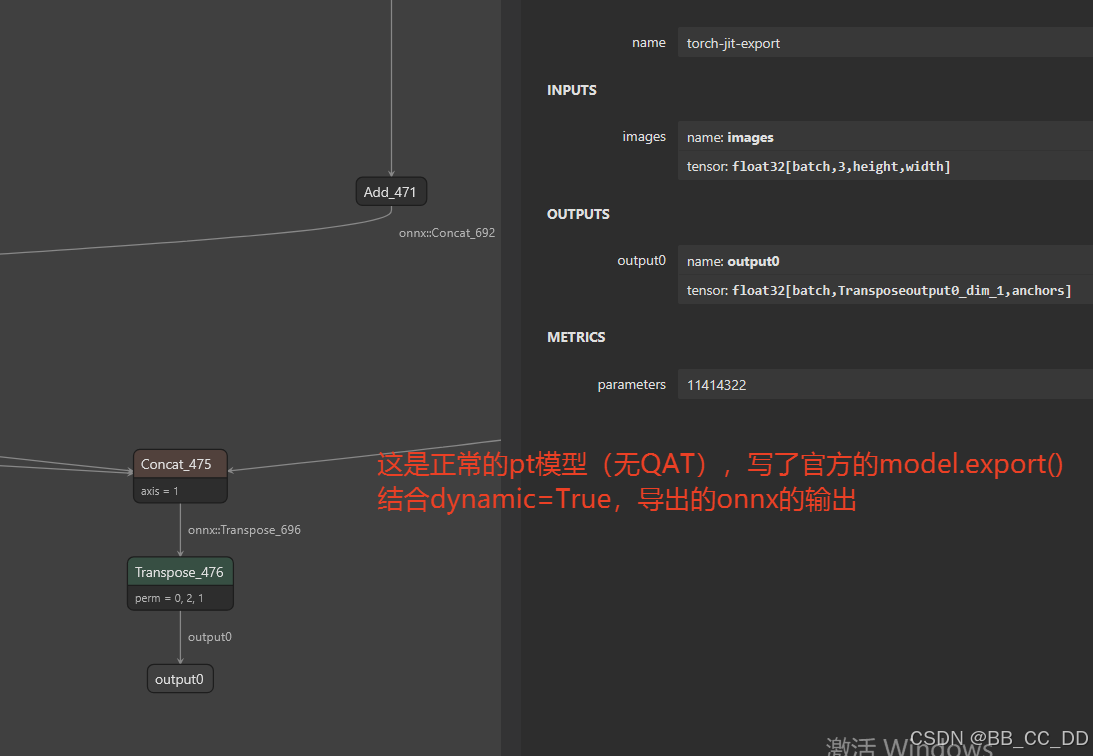 我们自己把QAT微调训练的pt转为onnx之后的图形结构:
我们自己把QAT微调训练的pt转为onnx之后的图形结构:
# pt转onnx的指令
python qat-yolov8-obb.py \
--weight qat.pt \
--export \
--save qat.onnx \
--size 640 640 \
--dynamic
看到右边输入INPUTS的images的维度和输出的OUTPUTS的output0的维度, 输入和官方的输入是一样的维度, 输出的维度有点不一样, 经过测试, 只要输出的维度的第一个维度是batch, 那么模型就能在tensorrt部署代码上正确运行.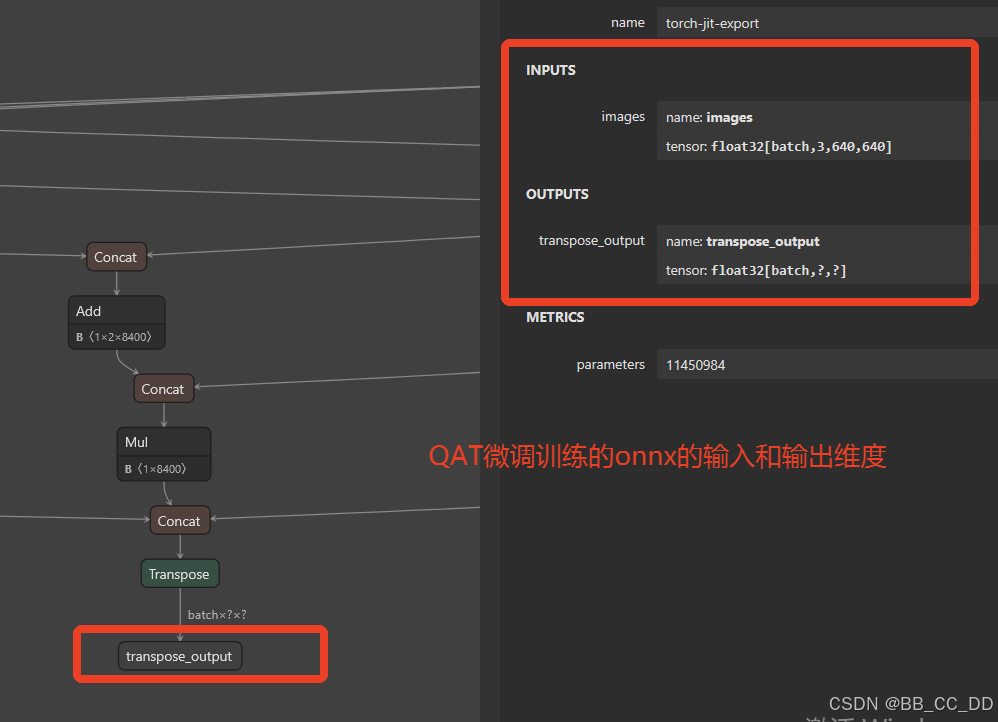
四. onnx导出为tensorrt模型
1. 多batch推理的onnx导出为多batch推理tensorrt模型:
多batch推理参数:
设定转换参数:
–minShapes=images:1x3x640x640 --optShapes=images:2x3x640x640 --maxShapes=images:4x3x640x640
备注: 640的尺寸可以自己修改
int8或fp16量化模型转换:
设定转换参数:
–int8 --fp16
由于我的pt模型是QAT量化感知训练后得到的, 所以里面已经有量化节点, 所以可以直接用int8进行量化转换:
sudo /usr/src/tensorrt/bin/trtexec\
--onnx=qat_multi_batch.onnx \
--saveEngine=qat_multi_batch.engine \
--workspace=1024 \
--int8 \
--verbose \ # 打印转换模型的信息, 方便查找转换模型的问题
--minShapes=images:1x3x640x640 \
--optShapes=images:2x3x640x640 \
--maxShapes=images:4x3x640x640
当同时指定--int8和--fp16这两个参数时,TensorRT会:
- 优先尝试INT8精度 - 对支持INT8的层使用8位整数计算
- 智能回退到FP16 - 对不支持INT8的层使用16位浮点计算
这样精度能更高一些, 但会增加耗时. 我测试了纯int8 和int8和fp16混合和纯fp16的运行时间:
纯int8: 耗时约21ms-22ms
int8和fp16混合: 耗时约24-25ms
纯fp16: 耗时约26-27ms
五. 验证tensorrt的engine模型
如果你没有可以运行engine模型的代码, 但想验证转换的engine是否可以正常运行, 可以执行以下指令:
/usr/src/tensorrt/bin/trtexec \
--loadEngine=qat_multi_batch.engine \
--shapes=images:2x3640x640 \
--warmUp=100 \
--duration=10 \
--iterations=100
如果能打印以下信息, 说明转换的engine模型能正常执行:
[09/27/2025-08:56:13] [I] === Performance summary ===
[09/27/2025-08:56:13] [I] Throughput: 10.6639 qps
[09/27/2025-08:56:13] [I] Latency: min = 96.6201 ms, max = 99.0234 ms, mean = 98.2436 ms, median = 98.2065 ms, percentile(90%) = 98.5088 ms, percentile(95%) = 98.6611 ms, percentile(99%) = 99.0234 ms
[09/27/2025-08:56:13] [I] Enqueue Time: min = 2.59717 ms, max = 4.70996 ms, mean = 3.39695 ms, median = 3.31909 ms, percentile(90%) = 4.04102 ms, percentile(95%) = 4.18054 ms, percentile(99%) = 4.70996 ms
[09/27/2025-08:56:13] [I] H2D Latency: min = 2.28308 ms, max = 3.44141 ms, mean = 2.93126 ms, median = 2.9043 ms, percentile(90%) = 3.02051 ms, percentile(95%) = 3.19214 ms, percentile(99%) = 3.44141 ms
[09/27/2025-08:56:13] [I] GPU Compute Time: min = 92.7559 ms, max = 94.1494 ms, mean = 93.3496 ms, median = 93.334 ms, percentile(90%) = 93.4775 ms, percentile(95%) = 93.5308 ms, percentile(99%) = 94.1494 ms
[09/27/2025-08:56:13] [I] D2H Latency: min = 0.959961 ms, max = 2.19287 ms, mean = 1.96276 ms, median = 1.96448 ms, percentile(90%) = 2.00366 ms, percentile(95%) = 2.03613 ms, percentile(99%) = 2.19287 ms
[09/27/2025-08:56:13] [I] Total Host Walltime: 9.37747 s
[09/27/2025-08:56:13] [I] Total GPU Compute Time: 9.33496 s
[09/27/2025-08:56:13] [I] Explanations of the performance metrics are printed in the verbose logs.
[09/27/2025-08:56:13] [I]
&&&& PASSED TensorRT.trtexec [TensorRT v8502] # /usr/src/tensorrt/bin/trtexec --loadEngine=qat_multi_batch.engine --shapes=images:2x3x1024x1024 --warmUp=100 --duration=10 --iterations=100
六. 额外知识点
1.额外知识点1:
如果是用QAT微调得到的量化模型, 那么转为int8量化模型之后, 在tensorrt环境中运行, 不需要再做后处理数据校准, 但如果是PTQ得到的量化模型, 那么是要做后处理数据校准的.
2.额外知识点2:
1024*1024图像分辨率:
output维度[1, 21504, 98]:
1 → batch size
98 → [x, y, w, h] + [objectness] + [93 类别概率]
21504 → 128×128 + 64×64 + 32×32 三个特征层的总预测点数
640*640图像分辨率:
output维度[1, 8400, 98]:
1 → batch size
98 → [x, y, w, h] + [objectness] + [93 类别概率]
8400 → 80×80 + 40×40 + 20×20 三个特征层的总预测点数
3.额外知识点3:
parser.add_argument中, 使用type=bool会出现一个常见的错误:
parser.add_argument('--dynamic', type=bool, default=False, help="dynamic batch for export onnx ...")
在argparse中:
所有非空字符串都会被解析为True
只有空字符串才会被解析为False
所以使用–dynamic False时:
"False"是一个非空字符串
即bool(“False”) 返回 True因此args.dynamic仍然是True
修改下面的方式, 避免上面出现的问题:
parser.add_argument('--dynamic', action='store_true', help="enable dynamic batch for export onnx")
使用方式改为:
启用dynamic:–dynamic
禁用dynamic:不添加–dynamic参数
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)