
Qwen25-7B模型微调实战:2小时完成从入门到应用,大模型入门到精通,收藏这篇就足够了!
本文提供了一个整体流程框架。通过反复实验可以发现,大模型微调并不神秘,而是一个有章可循的工程流程。

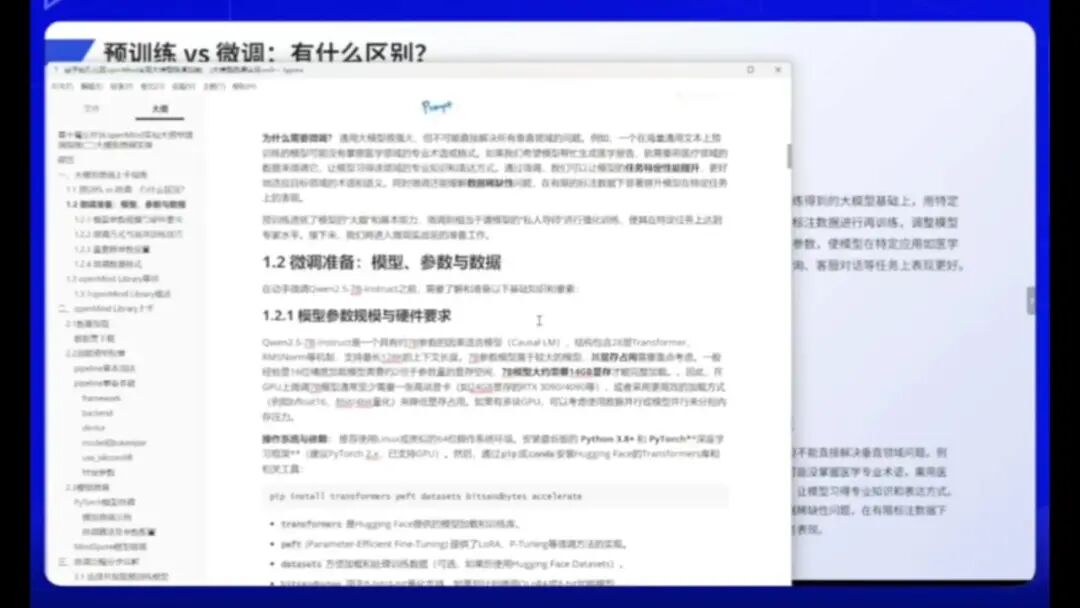
预训练是指在大量无标注文本数据上训练一个通用的大型语言模型,如GPT、LLaMA等,它不针对特定任务进行优化,是基础模型。
微调则是在预训练模型基础上,使用特定任务和领域的标注数据集进行训练,使其能应用于特定场景,这些场景通常较为垂直,偏向业务和领域,这是微调的独特之处。


微调旨在解决特定领域的问题,这与通用模型的概念有所不同。那么,为什么需要进行微调呢?
预训练模型就好比高中毕业生,虽然可以胜任不同领域的工作,但其专业能力显然不如特定领域的大学生。例如,若让高中生与计算机专业的大学生一同从事编程工作,结果显而易见。经过微调的大模型更适用于特定领域。
以通用大模型如DeepSeq、TrackGPT或COR为例,无论其性能多么强大,仍无法解决垂直领域的问题。例如,在中医药咨询诊断方面,未经医疗领域训练的模型显然无法提供专业回答,因为它缺乏相关领域的专业数据和训练。因此,微调的必要性显而易见。
接下来,我们将探讨微调阶段的具体准备工作。首先,需要明确选择哪个大模型进行微调。
其实选模型的话,

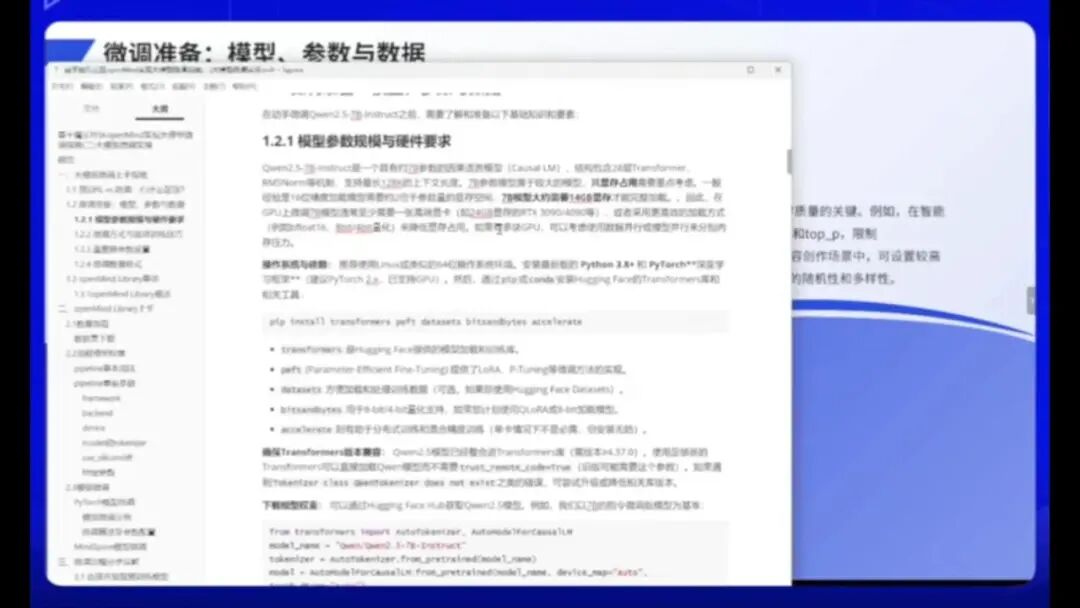
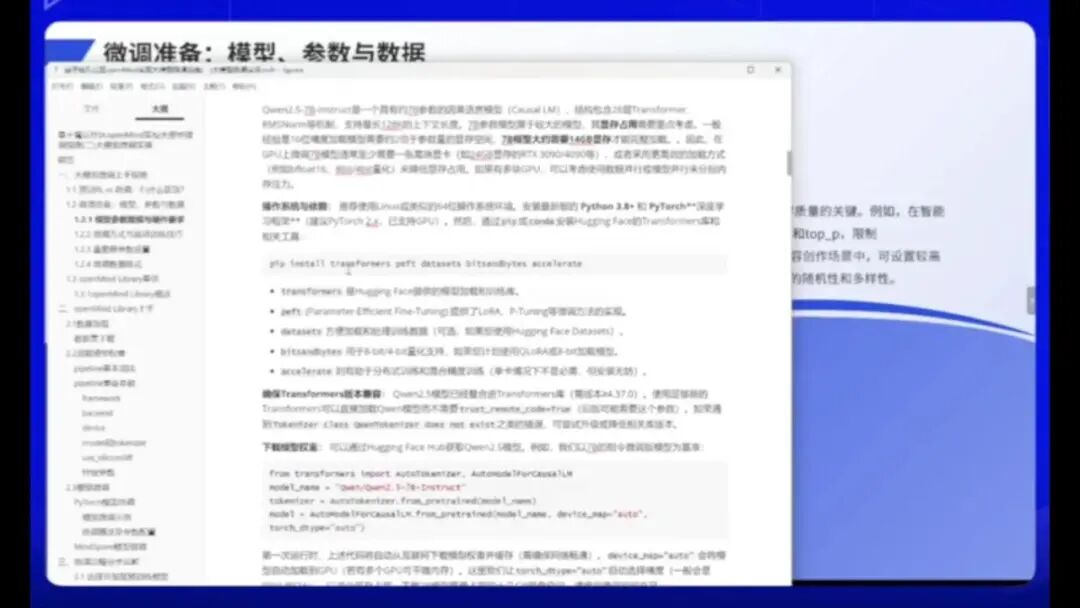
在选择模型时需要慎重考虑。例如,尽管DeepSeek等大型模型性能强大,但参数规模过大将显著增加显存消耗。多数实际应用场景,包括部分竞赛,更适合使用Qwen25-7B-Instruct或1.5B这类中小型参数模型。这些模型更适用于日常业务和个人使用场景。
我们当前的微调手册基于Qwen25-7B-Instruct模型,这是一个英语语言模型,采用28层Transformer架构,最大支持128K上下文长度。其显存需求较低,仅需单张RTX3090或RTX4090显卡(24GB显存)即可完成训练。
微调过程中需重点关注三个核心要素:
1.超参数设置:包括学习率、Temperature等参数。这些参数直接影响模型输出质量,需根据具体任务进行调整。
2.微调方法选择:除全参数微调外,还可采用LoRA、QLoRA等高效微调方法。这些方法能显著降低计算资源需求。
3.实际调优:通过摩尔平台进行实践操作,验证不同参数组合的效果。
这些是微调过程中最关键的要素,当然还包括其他需要掌握的内容,均已列在课程资料中。
由于我们使用的是摩洛社区的NPU显卡,考虑到部分同学认为NPU不太适用或更倾向于使用GPU,教师已在操作手册中为同学们整理了相关指导。若有同学需要使用GPU,
也有不同的策略,这里使用GPU进行训练,按照操作手册下载。
这个Transformer数据集来自第三方库,需确保其与您的CUDA环境兼容。
然后你可以使用自己的GPU训练模型,从而摆脱环境限制。这为同学们提供了第二种选择。

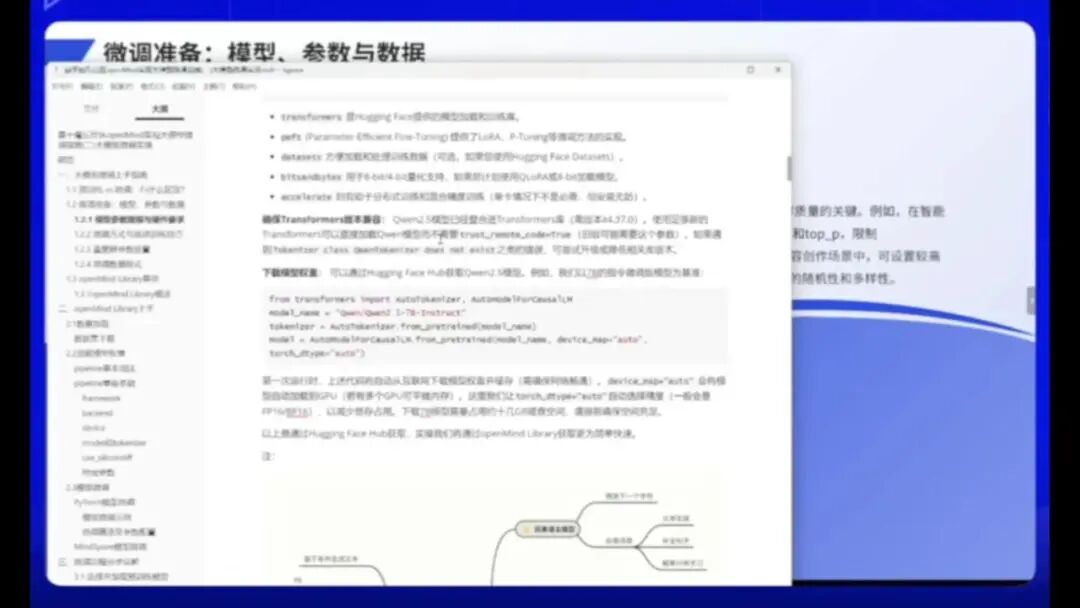
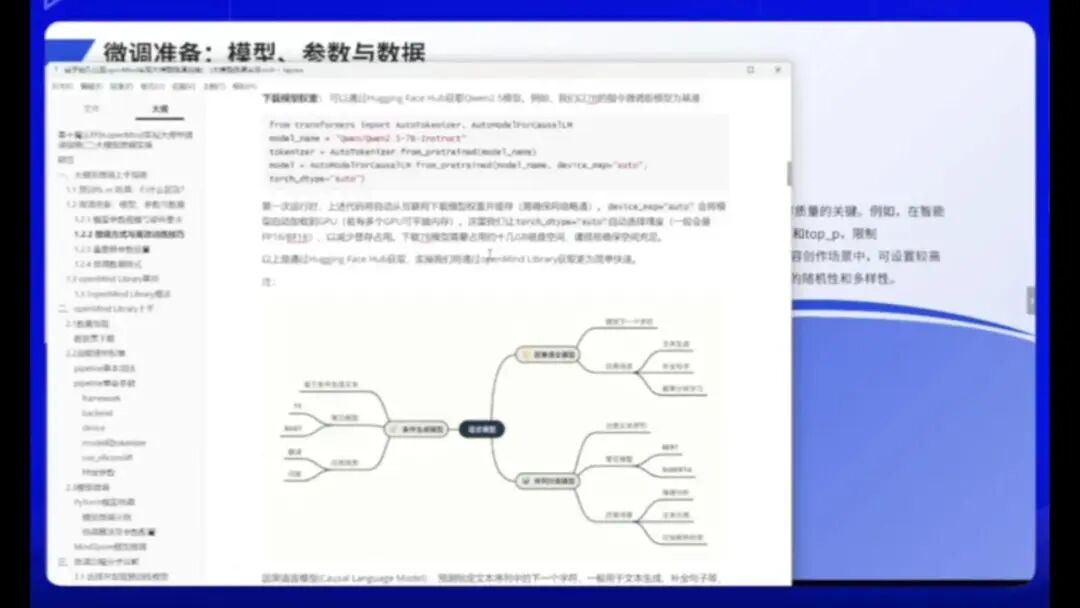
值得注意的是,老师之前提到的Qwen2.5-7B是一个因果语言模型。大家可能会问,DeepSeek、Noval Alchemy或ChatGPT这些大语言模型之间有何区别。实际上,语言模型主要分为三类:条件生成模型、序列分类模型和因果语言模型。由于本节课侧重实操环节,理论部分不做过多展开,相关名词解释均已收录在实操手册中。建议同学们通过手册深入了解不同语言模型的特性及其适用场景,因为不同环境下各模型的适应性也存在差异。
在掌握参数方法后,我们还需要关注模型的高效训练方式。这里简要回顾上节课的重点内容,因为这些方法在当前微调实践中具有重要价值。例如LoRA、QLoRA和Prefix-Tuning等通用方法需要反复研习。为帮助同学们加深理解,老师重新梳理了LoRA的工作原理,并建议结合课件中的示意图进行深入学习。相信通过理论知识与实践操作的结合,同学们能够更清晰地掌握这些微调方法,实现高效的大模型微调效果。

在选择微调方式时,需要根据实际场景和业务需求进行权衡。不一定要使用LoRA或QLoRA,也可以直接进行参数微调。每种微调方法都有其优缺点,建议根据可用资源和具体业务场景,实事求是地选择最适合的微调方式。


其中最重要的一个超参数设置,我之所以单独详细讲解这一部分,是因为其重要性。

由于许多大模型在后续训练中逐渐演变为计算模型,若已有他人完成了模型的训练工作,我们通常可以直接使用其微调后的模型架构。然而,参数设置仍需自行决定,这一点至关重要,尤其是超参数的调整。
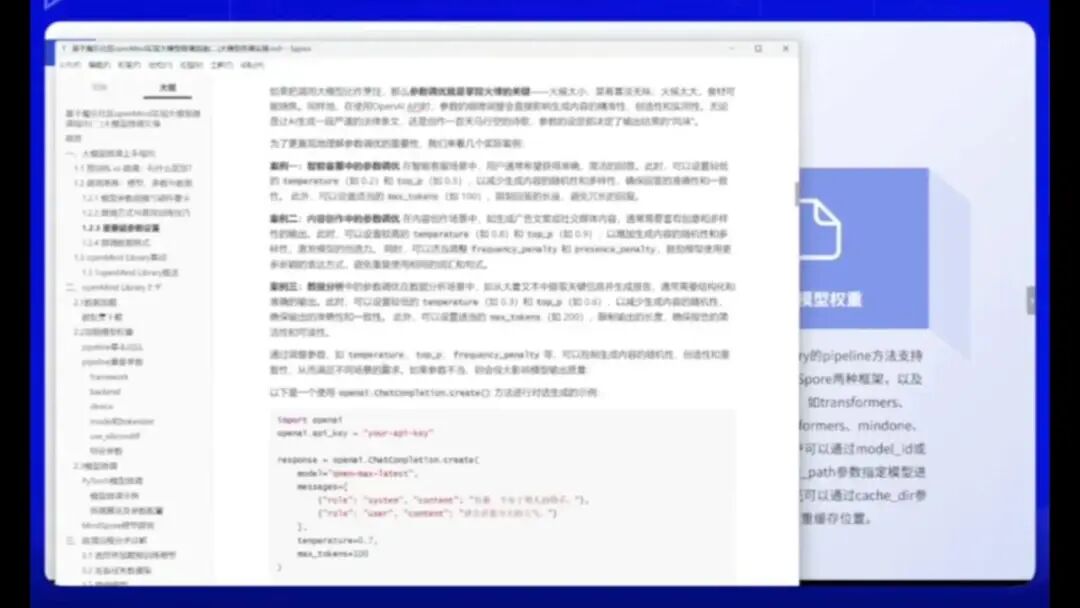
我们可以将大模型比作烹饪过程,参数调优就如同掌控火候的关键——火候不足则菜品寡淡,火候过猛则食材焦糊。在大模型中,参数调整同样如此,最典型的例子便是温度参数(Temperature)。同学们是否使用过AI智能体的温度参数?当温度值设置过高(超过1)时,模型的思维会变得天马行空,创作理念新颖独特;反之,若将温度值设为0.1或0.01,模型则会严格遵守提示词(Prompt)的设定,恪守输入输出原则,避免过度联想和创新。
让我们通过几个实际应用场景来说明参数调优的重要性:
1.智能客服场景:在进行智能客服调优时,我们通常不希望客服给出天马行空的回答,用户更期待获得准确简洁的回应。因此,在智能客服引擎的大模型配置中,需要设定较低的温度值(Temperature)和TopP参数(限定前五个最优回答),以降低内容的随机性和多样性,确保回答的准确性和一致性。
2.内容创作场景:当需要撰写小红书分享文档或其他平台的文案时,建议调高温度值,这样生成的诗歌或文章会更加生动有趣,避免内容过于枯燥。
3.数据分析场景:这个场景需要采取折中策略。过高的温度值可能导致模型编造数据,产生AI幻觉;而过低的设置又会限制模型的联想能力,使分析不够全面。因此,需要选择适中的温度值,并根据实际情况不断调整。
无论是调整Temperature、TopP还是Frequency Penalty等参数,这些设置都能以多种方式控制大模型输出的随机性、创造性和准确性,使同一个大模型能够适应不同场景下的多样化需求,从而影响其输出质量。

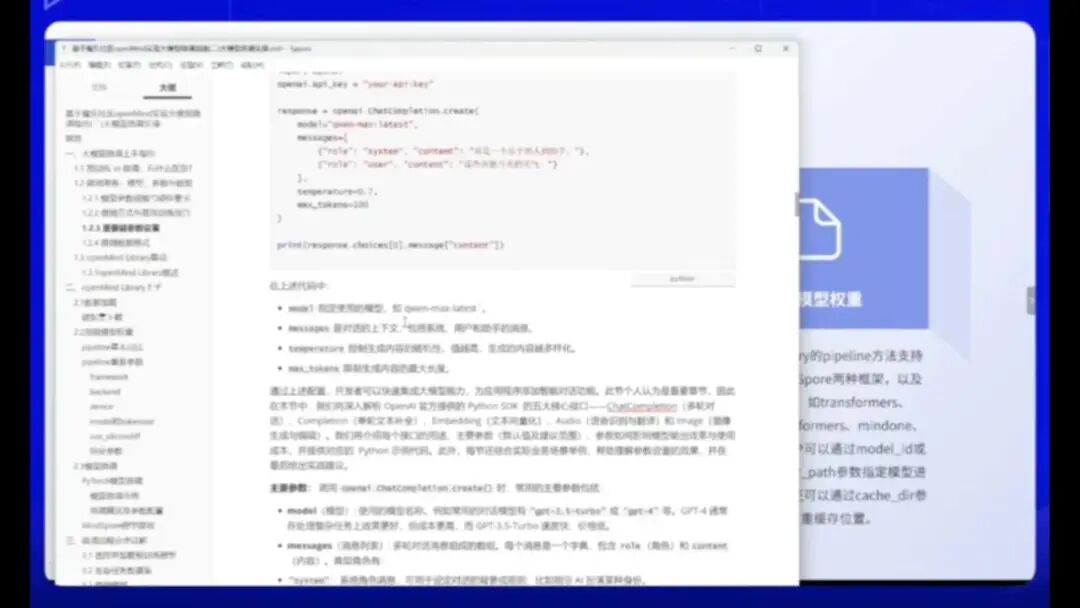
然后,我的Markdown文档中还提供了一些实际的temperature应用场景示例。大家不要因为看到代码就觉得难以学习,其实它相当友好。

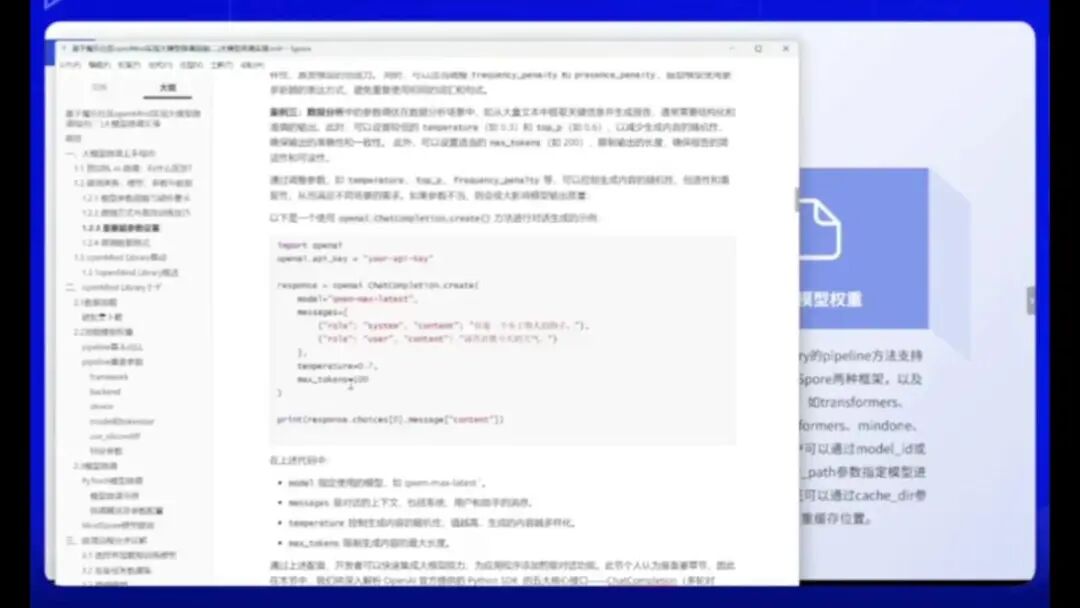
比如这是一个标准的OpenAI参考格式。TLMAX系统使用了TLMAX作为其Prompt的定义,这是一个智能助手的功能。用户可以简单地查询天气等信息。
以下是其超参数的设置:
- Temperature为0.7
- Max Token也有相应配置
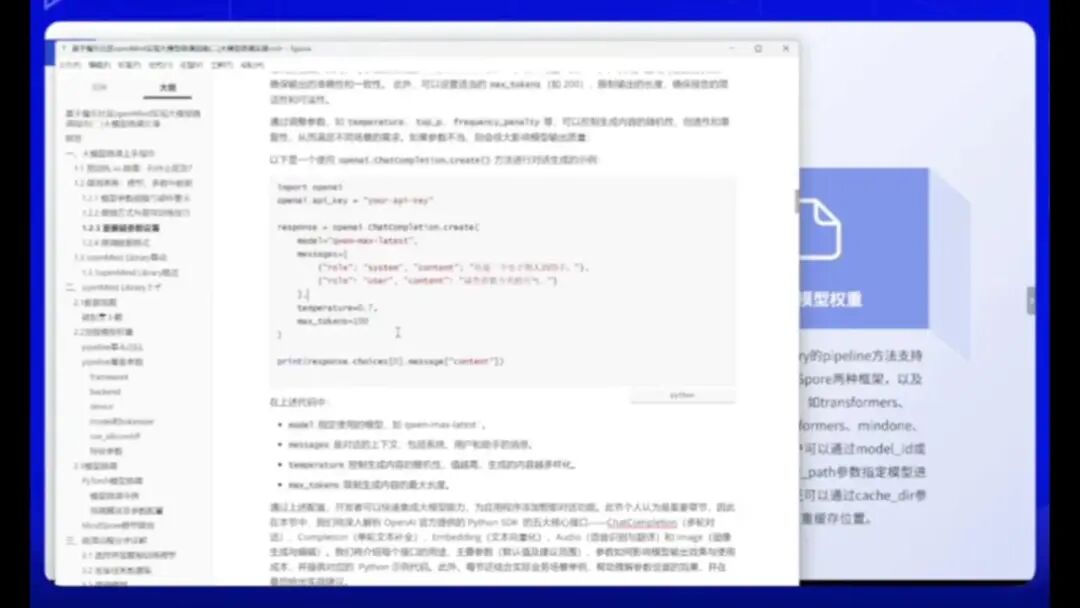
该功能限制Token数量在100以内,超出部分将被截断,这是其测试机制的一部分。
我这边的手册内容非常详细,涵盖了众多接口的相关信息。
包括Python SDK,即OpenAI官方提供的开发工具包,涵盖了日常开发所需的各类参数。OpenAI的SDK基于特定框架设计,目前仅支持ChatGPT模型调用。
值得注意的是,当前众多平台如阿里百链和豆包等,均已兼容OpenAI的SDK标准。这体现了大模型参数的统一性——OpenAI制定的参数规范已被行业广泛采纳,后续厂商均遵循该标准进行大模型参数设定。
因此,所有参数的含义及数据结构均保持高度一致,具有通用性。
比如选择这个model_id,它代表一个模型,可以是GPT-3.5-Turbo、GPT-4或其他模型。每个模型都有一个对应的Message。
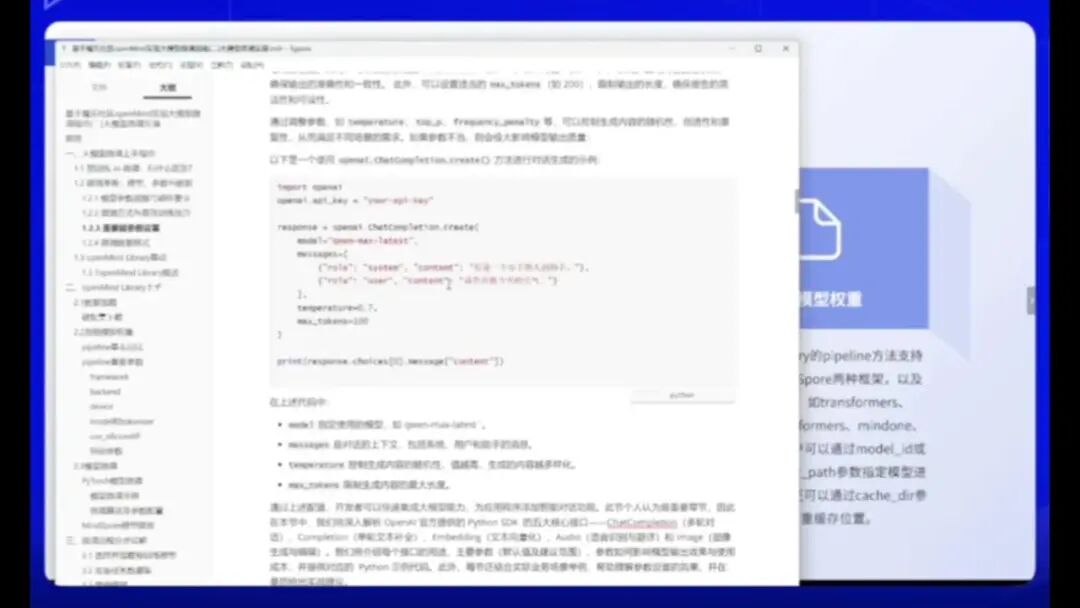
例如,这是一个Message的格式,具体结构如下。可以将其理解为建筑队的格式。
在此,我提供了详细的解说过程。由于这是实际操作环节,就不进行过多讲解。建议各位仔细阅读这一部分内容,因为某些参数确实至关重要。
例如,Temperature参数控制文本生成的随机性,而TopP参数则属于核采样技术,用于调控模型预测下一个词时的累积概率范围。当TopP值小于1时,其采样范围会变得较为宽泛。
具体而言,若设置为0.1,生成的文本会更加符合常理;反之,若调高该值,则可能出现不常用的罕见词汇。

参数 N 表示一次返回的结果数量,可以设置为1、2或3。例如,在使用TentGPT时,系统可能返回两个结果供用户选择。
在诗歌创作或广告词生成等场景中,生成多个结果进行对比并选择最优方案是一种常见用法。此外,还有一个参数 Strafer 可供设置。
这是一个流式输出场景。
当我们调用第三方API时,可能会遇到响应时间问题。如果输出内容过长且未启用流式输出,系统可能会因超时而无法返回数据。
启用流式输出后,数据会实时返回,从而避免超时问题。这在开发过程中尤为重要。此外,还可以通过设置停止标志来控制生成过程,该参数支持字符串或字符串列表形式。
如果出现该标志,系统将自动停止生成内容。我们可以通过判断敏感词来实现这一功能。
目前使用的大模型涉及许多敏感词汇,只需将这些词汇列入停止列表(Stop List),当模型检测到这些词时,便会停止生成。
相信使用过的用户都遇到过这种情况:输入某些敏感词后,模型不会给出回答,这正是利用了停止列表的特性。
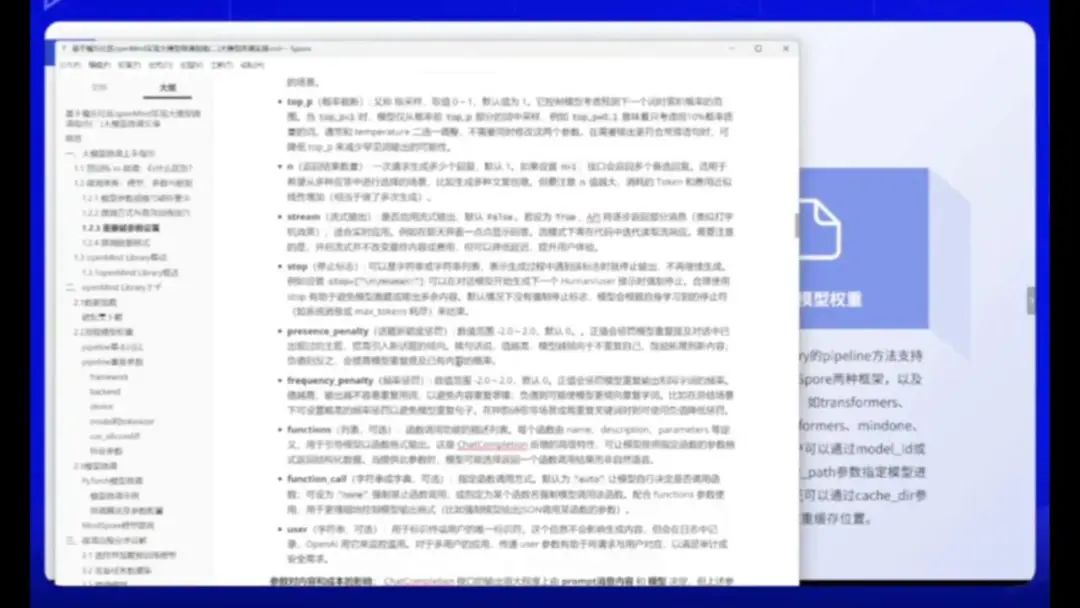
这些是较新加入的参数。例如话题新颖度惩罚,其作用是避免大模型在对话中重复提及上一轮的内容,从而鼓励拓展新话题。
该参数值越高,模型越倾向于避免自我重复,转而探索新内容;若设为负值,则会增加模型重复已有内容的概率。如需调整模型表现,可尝试将该参数调低。
此外,还有频率惩罚等参数,此处不再赘述,感兴趣的读者可自行研究。

需要仔细查阅操作手册,例如关于命名一致性、输入场路径等内容。
模型的性能可通过超参数进行调控,或通过调整模型内部参数指标来实现。
这些内容我已向同学们说明。在实际应用时,必须对这两个概念有清晰的认识。
不同模型的框架及Chat Completion接口的基本用法如下。超参数设置方面,如Temperature或N值等参数需根据实际情况调整。
接下来,我们将探讨微调后的效果以及用户体验。在讨论完微调的超参数设置后,另一个关键问题是微调数据的具体形式。
许多同学对微调数据缺乏深入了解,仅有一个模糊的概念。微调数据是以对话形式传输,还是采用特定格式,如书籍、PDF等?微调数据集的具体格式究竟是什么?

在此,我将通过案例说明数据格式的多样性。无论是JSON、CSV列表还是CL对称关系,均可作为权重数据或微调数据集的格式。
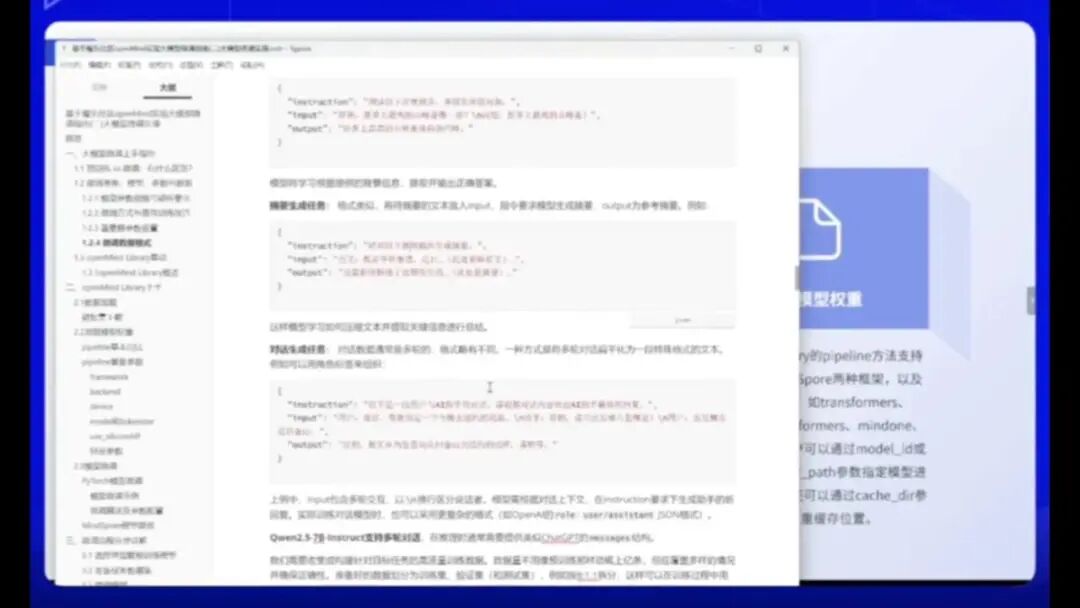
以文本分类为例,若需训练情感分析模型,可如下设置:
- 指令部分定义任务(如“判断下列句子情感倾向”)
- input提供上下文(如“这家餐厅菜品丰富”作为content)
- output标注预期结果(如“正面”)
单条数据即构成数据集的基本单元,可通过批量生成形成完整数据集。
数据集构建主要有两种方式:
- 利用专业大模型生成
- 人工标注
当前最常用的框架是DeepSeq的帧流模型,其原始版本为670CB。通过将对话数据集输入DeepSeq 671B模型生成回答,再将这些问答对构建为训练集,最终训练出通一千万2.5的帧流72版本。
简言之,该流程采用迭代优化策略:先用基础模型生成数据,再用生成数据训练增强模型。问答(QA)领域同样适用此方法论。
该数据集要求阅读下一段背景信息进行构建,部分内容涉及摘要生成。
要提取关键信息并构建数据集,可以参考老师提供的模型权重和相关参数。
该论文主要探讨对话生成领域。部分比赛涉及对话生成任务,或要求参与者模拟合成数据,以生成可用于训练和标注的AI数据。
该论文基于特定规则构建了专用数据集。如有相关需求,可参考本文提供的数据集格式。

在GitHub或开源社区中,数据集通常按类别分类,并以不同格式呈现,便于用户查找和使用。
接下来,我们来看通义千问7B模型支持的多轮对话格式。该格式采用message结构,通过上下文的message结构可以实现多样化的训练微调,确保上下文一致的训练过程。
针对主流大模型微调,我们整理了16个不同领域的数据集。考虑到部分学员希望构建个性化数据集,我们提供了多种领域的参考方案: - 既有垂直领域的深度数据集,如青龙数据集、翻译数据集、文本匹配数据集; - 也有特色应用场景的数据集,如科普类大模型、古典诗歌生成模型、真假新闻检测模型,以及诈骗电话识别模型等; - 此外,还包括小学教育答题生成逻辑、风水占卜和中国古代文化等特色数据集。
这些数据集均可下载,学员可结合微调方法尝试打造专属大模型。所有16个数据集均可在开源社区获取。
现在进入重点内容:平台操作指南。第一章已介绍大模型基本概念、微调方法、数据格式、超参数设置和微调流程。接下来将详细讲解Modelers平台的操作方法,包括如何利用该平台进行微调。
操作流程如下: 1. 首先,在首页创建体验空间(这是第一节课教授的内容)。
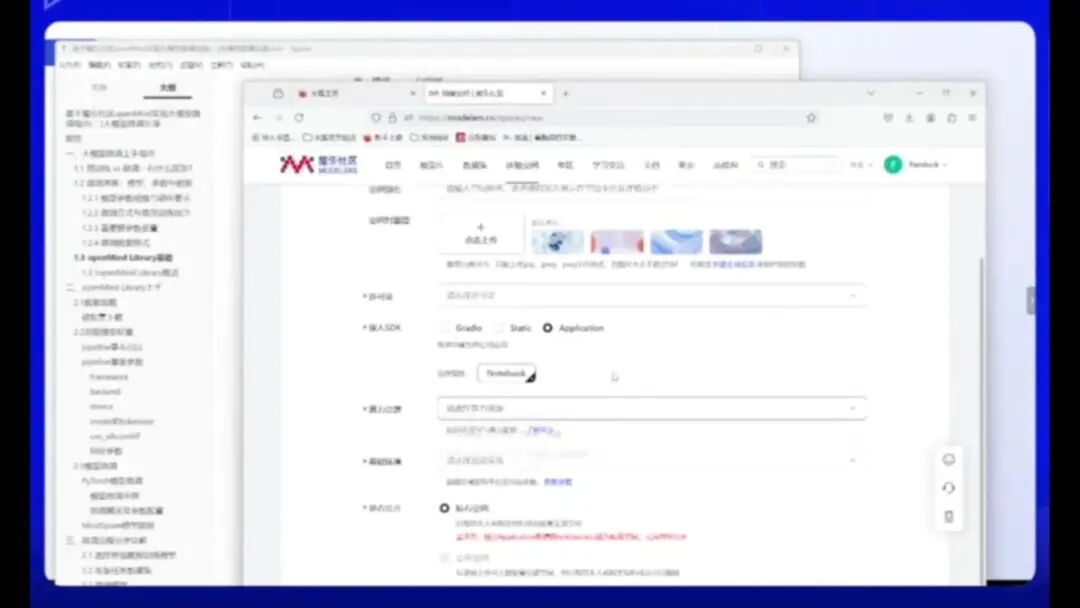
选择 Application 后,在资源选项中有一个 NPO 选项。我们的 OpenMind 是基于深藤框架开发的,专门针对 NPO 进行微调。由于我已创建了一个实例,无法再次创建。
请注意选择 NPO 选项,然后配置基础环境。

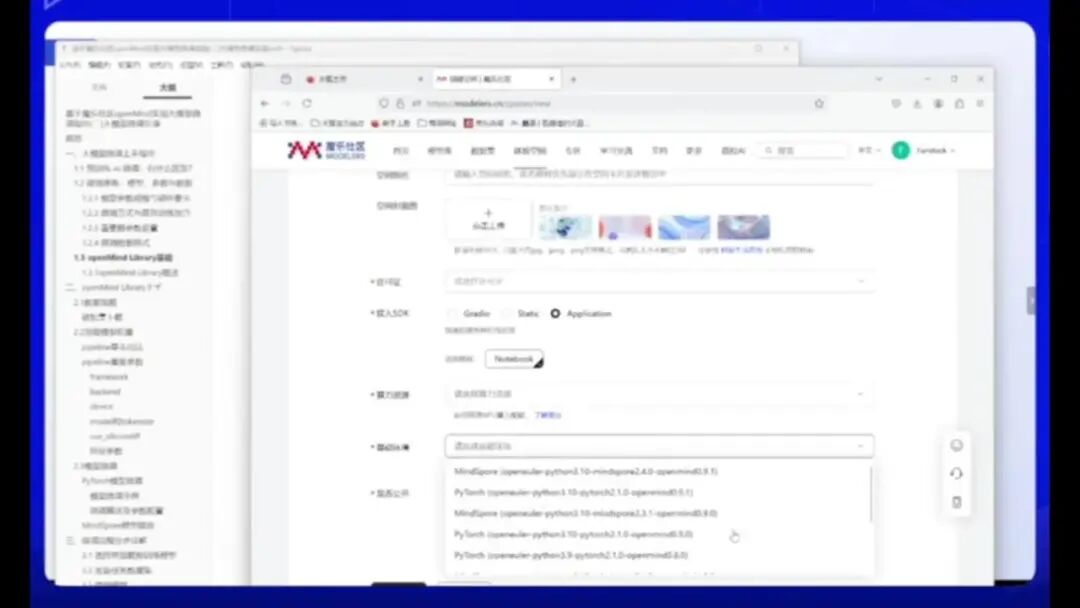
基础环境配置需特别注意,官方默认版本为0.91。请根据最新文档指引操作,点击OpenMind的lab模块。

此处显示版本为 0.1。根据最新文档要求,我们需要选择 0.1 版本对应的环节。请注意,该环节需要使用 PyTorch 框架。
创建相应工作空间的操作在此不再演示,因已预先完成。


接下来介绍参数的调用方法。考虑到部分用户希望在本地电脑而非云环境中使用OperMind的lab功能,可以通过PyTorch进行安装。相关安装指令已明确列出,操作较为简单,只需输入相应命令即可完成下载。
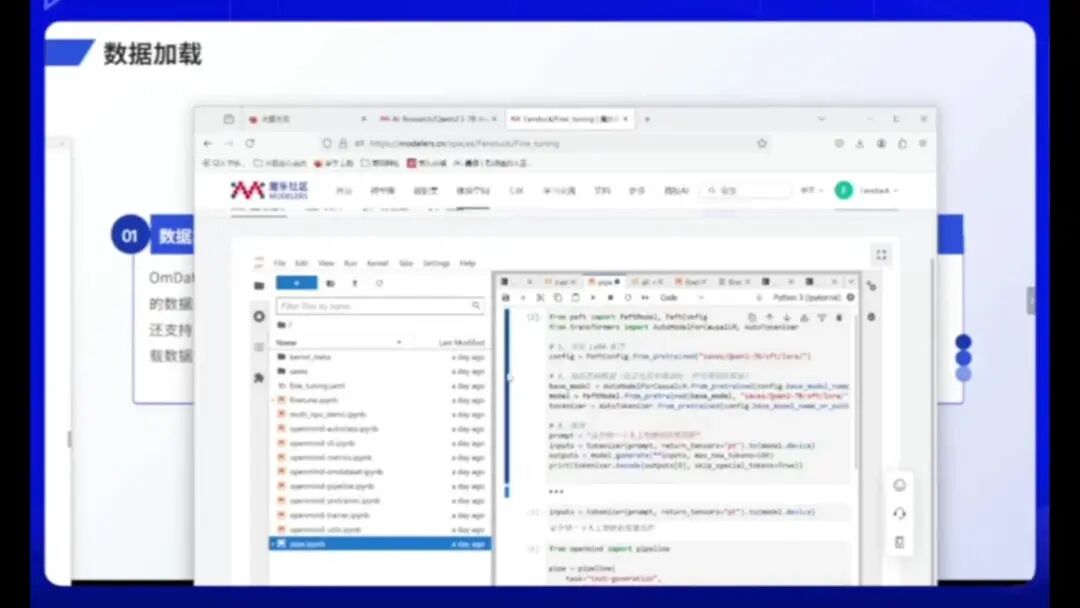
关于OperMind lab的功能,主要包括:首先,该工具支持加载数据集,例如前文提到的lab数据集均可下载使用。

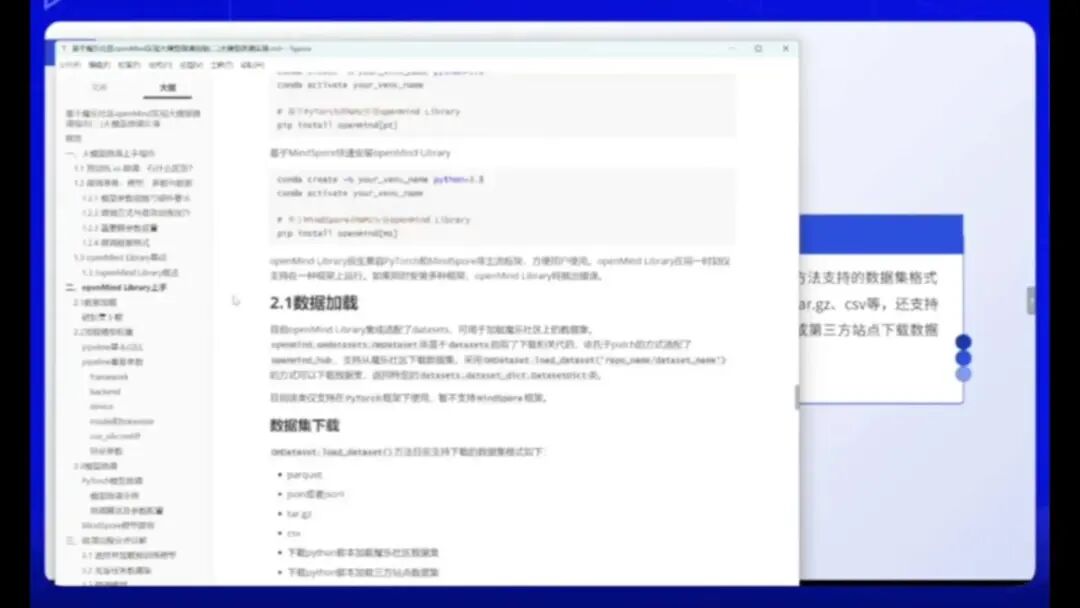
通过OpenMind的OM数据集,可以下载并使用。以下是我个人应用程序的展示。
该微调指南目前处于应用阶段。创建完成后,系统将跳转至该界面。

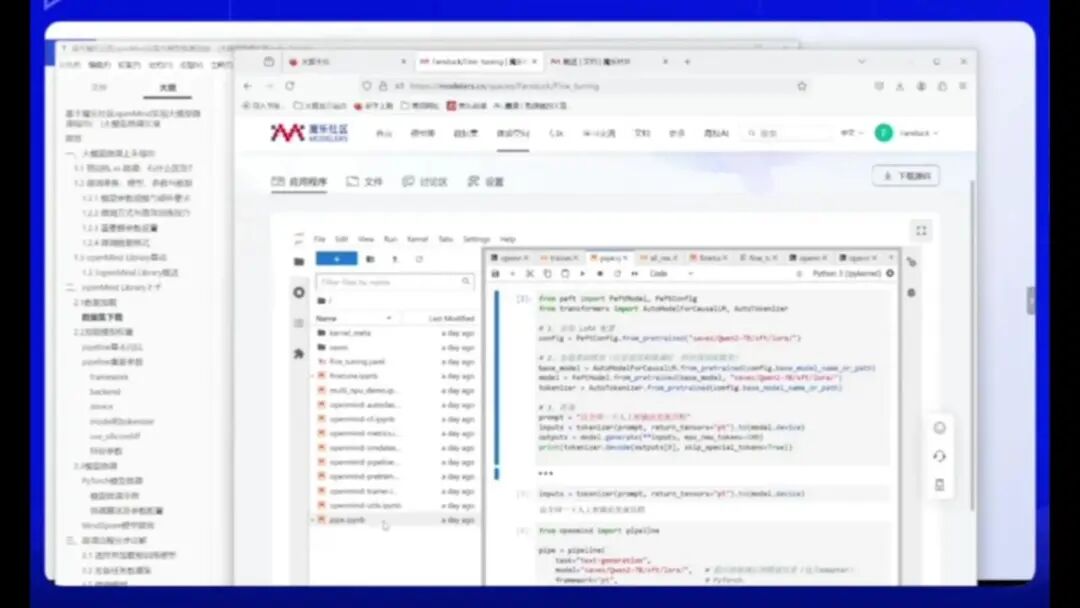
接下来我将为大家介绍一个已经完成测试的微调训练。如需下载,可通过以下代码实现,该代码能够下载对应的数据集。需要注意的是,数据集的链接已包含在模型库中,可直接获取。
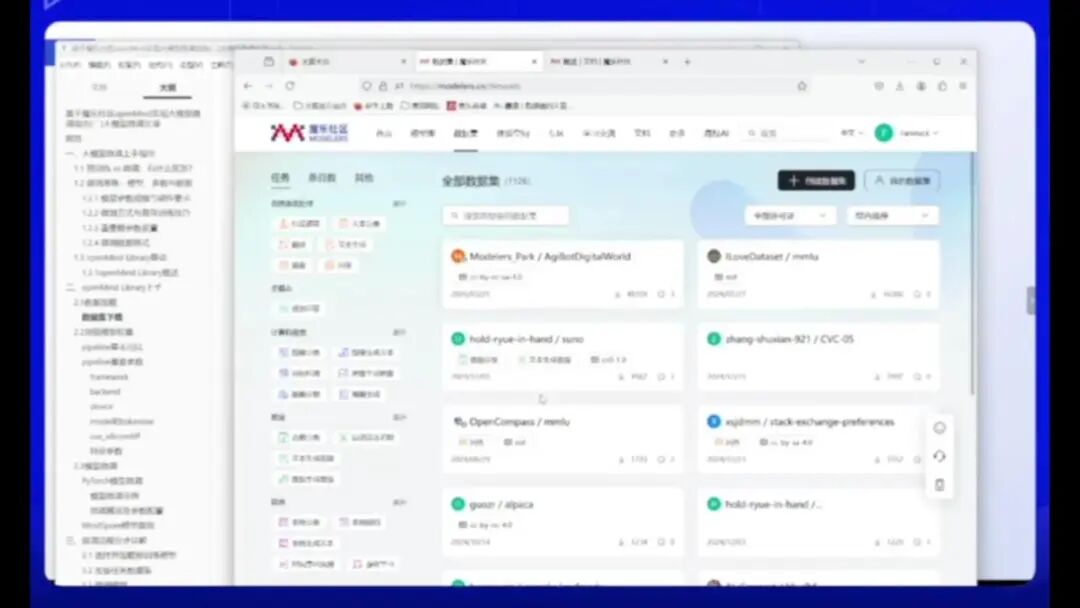
要下载数据,必须确保数据存在,否则无法下载。平台也提供了第三方下载渠道,如JSON、数据压缩包或CSV格式的文件。这些资源均可获取。若需下载Hugging Face或GitHub上的数据集,需通过相应接口实现,这涉及编程知识。建议具备一定编程基础的用户尝试,具体方法详见实验操作手册。
下载数据集仅是第一步。若需创建自定义微调数据集,则需进行数据处理。数据处理在大模型训练中至关重要,优质模型的训练或微调依赖于高质量且标注完善的数据集。因此,数据处理方法需详尽严谨。目前提供的数据集均已预处理,无需单独执行此步骤。但需注意,数据处理过程复杂且工作量较大,是模型训练中的重要环节。

我们获取训练数据集后,需要下载待微调的模型。OpenMind的加载方式与HuggingFace或LAMA使用大模型的方法类似:只需输入目标大模型的索引,系统便会自动下载相应权重。
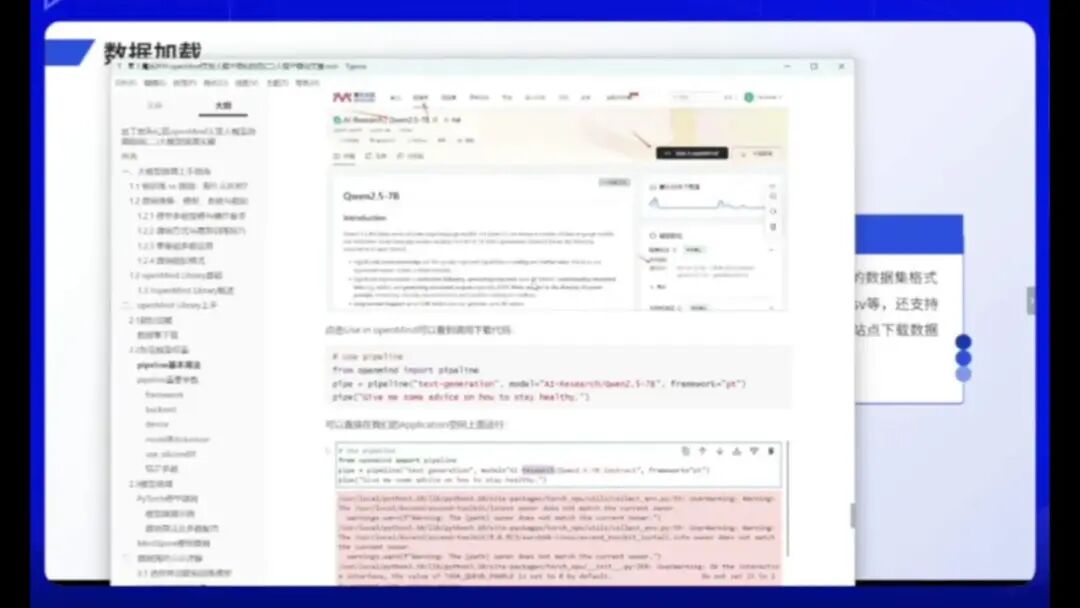
我已进行演示操作,大家需打开大模型空间并访问模型库,例如选择Qwen模型。
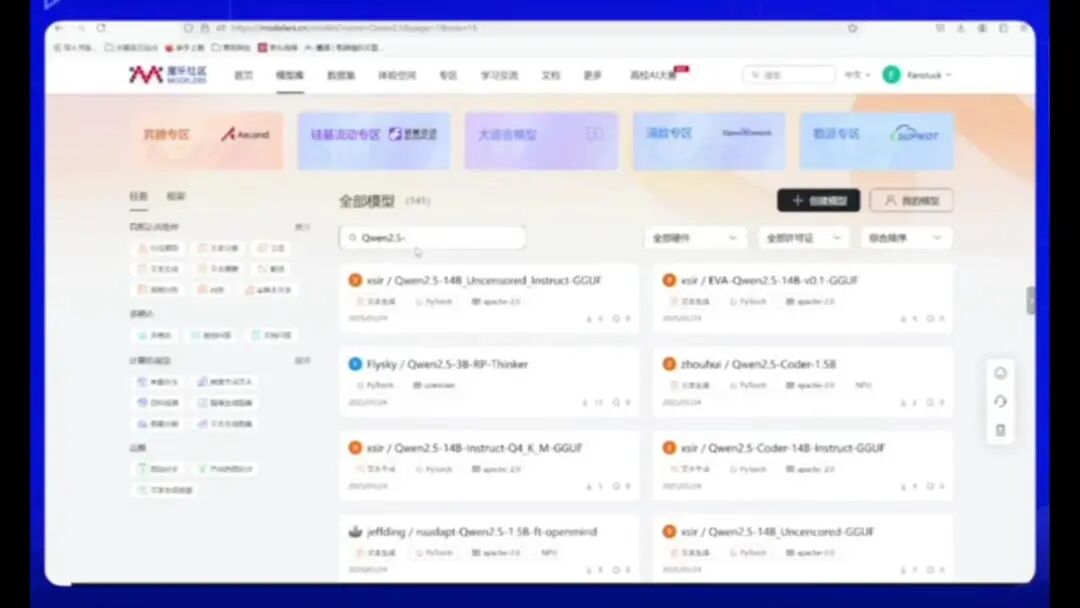
2.5GB,点击搜索后即可下载AI Research文件。点击打开该文件即可。
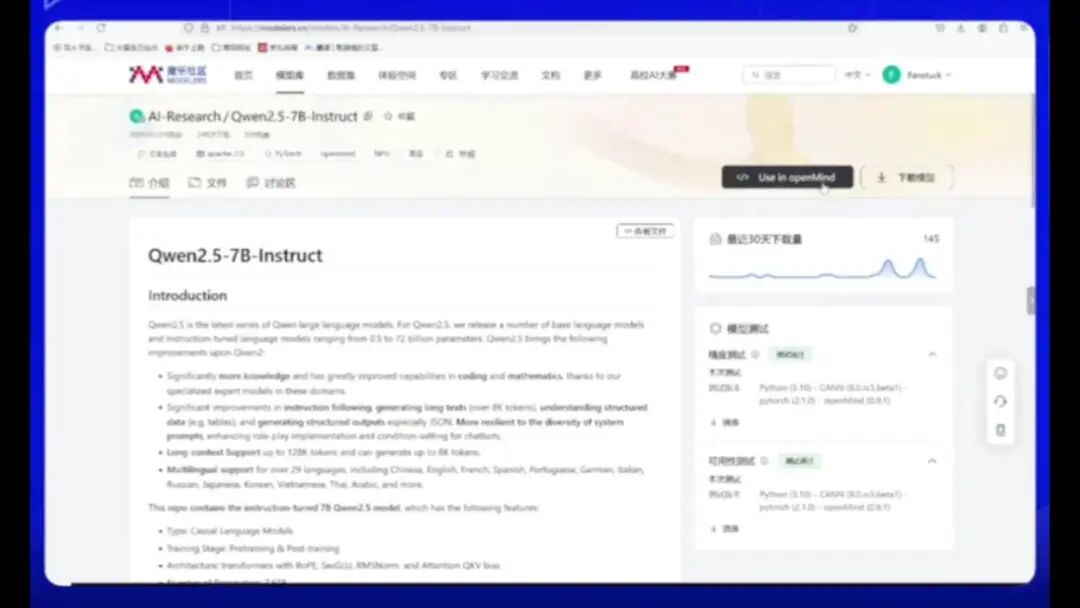
它有一个U4E OpenMind,点击此处即可。

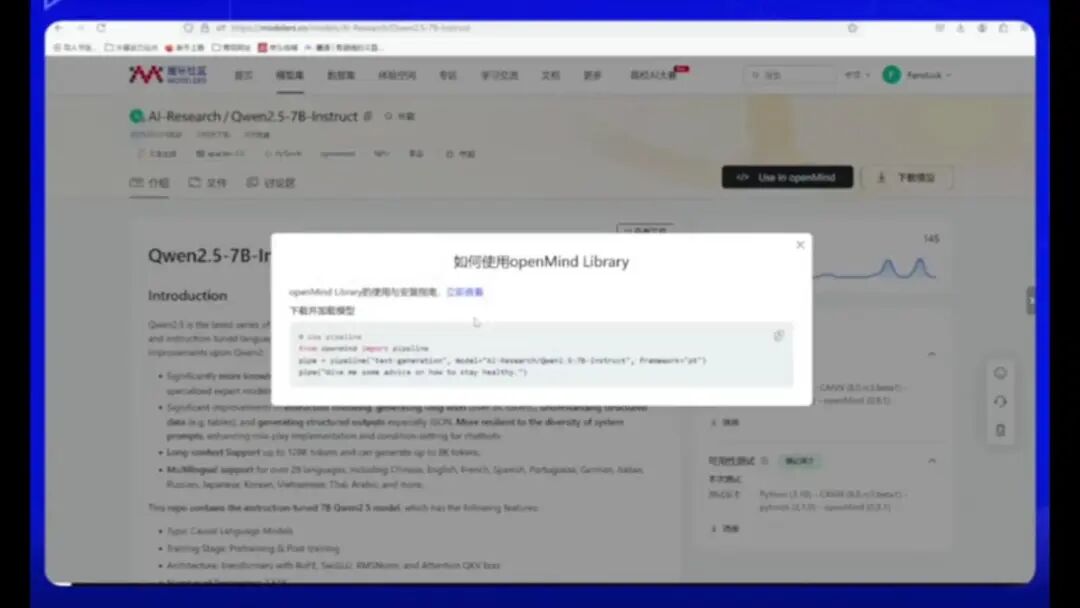
它可以直接运行推理,连接后即可使用,十分便捷。
我还是建议大家到我们的各类空间自行尝试,我这边已经完成了相关操作。
已成功调试,采用7B通信相关模型,并已获得相应结果。请介绍其智能逆向工程能力,该功能已实现并可正常调试。首次下载时需注意相关配置。


加载7B模型所需时间较长。

大约需要8到9个句子,因此运行所选代码时可能会比较卡顿。

由于下载模型的过程可能较为耗时,特别是在使用某些性能较低的云主机时,建议选择下载1.5B或0.5B的较小模型。若仅需快速验证效果,0.5B或1.5B的模型即可满足需求。

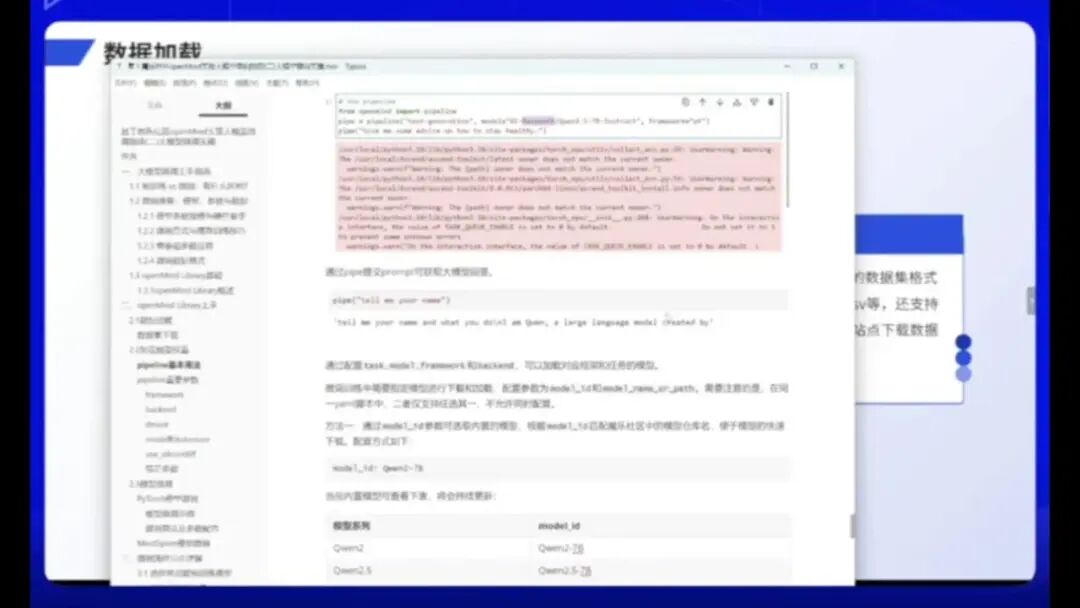
无需强制使用7B模型,用户即可获得部分回答。通过配置Text Mode Framework Backend,可以加载相应框架的任务。此外,我们还可以基于内置模型下载不同版本。如需微调其他模型,可通过Mod ID、Mod name或Path进行索引,这些方法均已提供详细说明。
言归正传,在完成大模型下载和加载后,还需配置Piper的关键参数。那么Piper有哪些重要参数呢?

实际应用中,我们下载的大模型通常包含大量参数。例如,模型可能具有1.5B参数,或经过Int4量化处理。
在Piper推理过程中也存在不同参数设置,需要特别注意。以框架选择为例,主要支持MS(MindSpore)和PT(PyTorch)两种架构。若使用华为的ModelArts平台,则需选用MS架构。
具体框架信息可在模型文档中查看,文档会明确标注是MS(Media Support)还是其他支持架构。

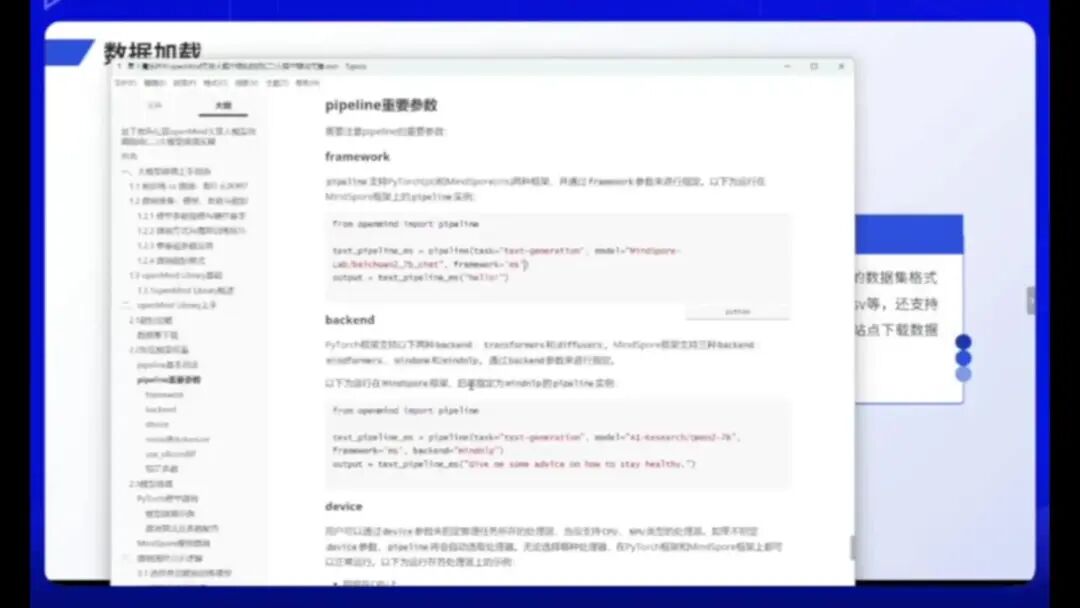
此外,Backend方面,PyTorch支持两种Transformer架构。在Media Support方面,它包含Media Formers、Media DOM和Media LLP等多种格式,需要大家了解。
关于微调,并非每个参数都需要完全掌握,过程并不复杂。使用OpenMind Library进行微调十分简便,只需编写一个YAML配置文件即可。OpenMind内置了大量预训练模型和参数供用户选择,包括大模型微调所需的各项参数设置。
在设备选择方面,大模型推理需要指定运行设备。可选择CPU或NPU等不同硬件平台。若要在NPU上训练,需指定为NPU的0号卡;若使用CPU,则需指定为CPU设备。这些设置均通过Device参数完成。
关于模型(Modal)部分……
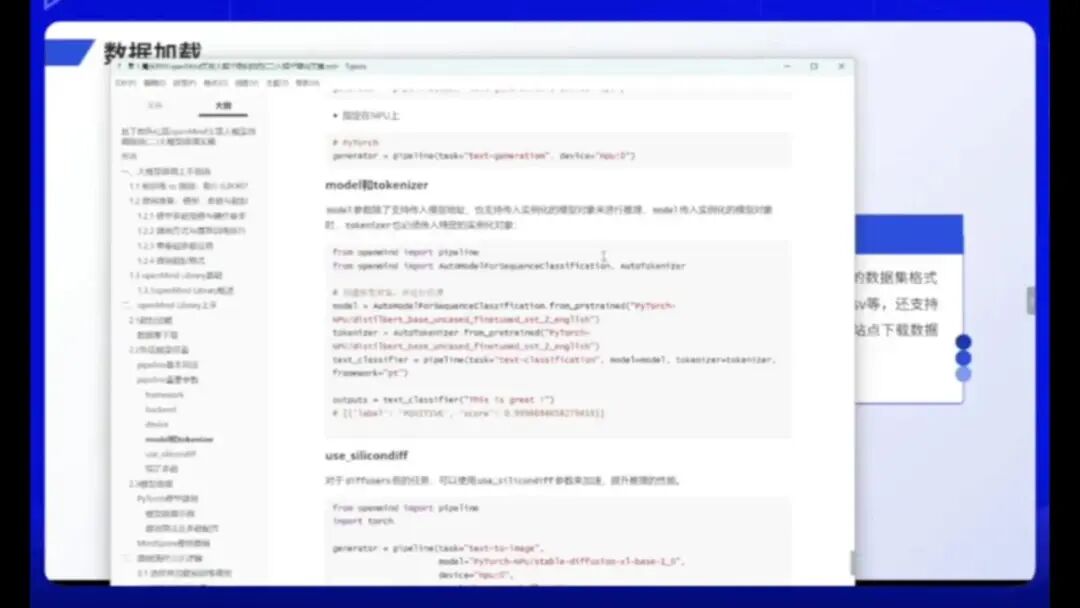
Token部分涉及众多参数,此处已详细列出。若逐一讲解,将占用大量实操时间,因此不再深入展开。建议感兴趣的同学查阅相关文档和手册,以便更好地理解代码、文字说明及配图。
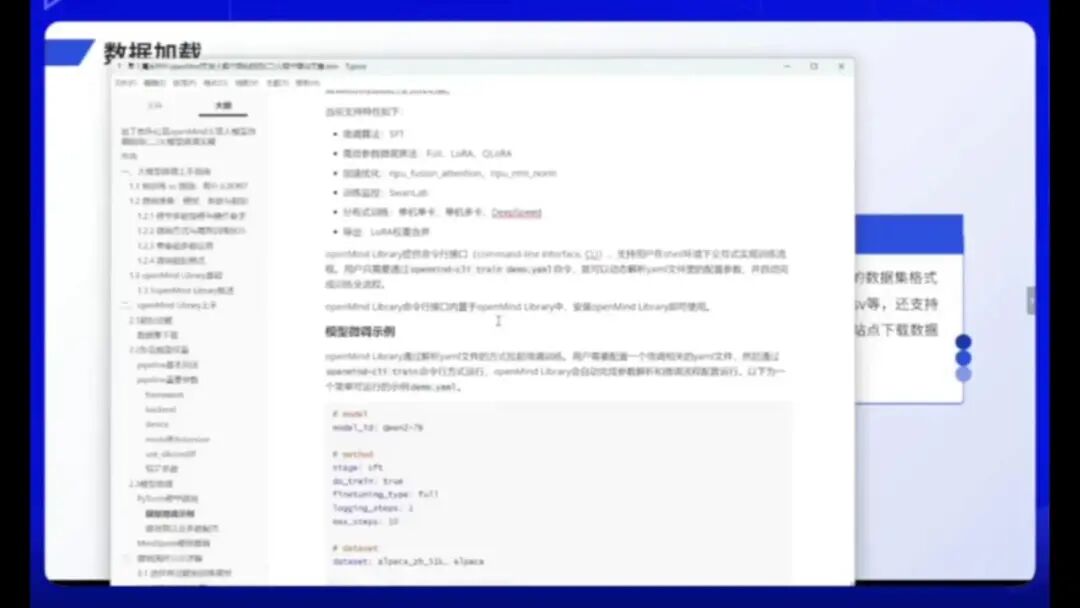
接下来,我们将使用PyTorch进行微调。这是一个简单的微调实例。首先,PyTorch微调具有特定特性,需选择合适的微调算法。目前主流算法为SFT,多数框架仅支持该算法。此外,还有高效参数微调算法,如FOR、ROR或QROR,以及二者的结合方案。
优化加速方面,可采用NPU算子或NPU的Fashion Attention技术。监控环节可配置每步的评价指标和参数指标,这些配置均可在Open Library文档中找到。
有一份详细的微调手册可供参考。通过简单的Demo示例即可快速上手运行。虽然Demo仅展示基本功能,但无需担心参数配置问题。在第三章的微调分布详解中,会逐一说明每个参数的含义及YAML文件的配置方法。手册中提供了多个实际案例供参考。
首先进行微调算法参数设置,选择Target。目前OpenMind仅支持SFT(全参数微调),因此选择SFT模式。需要配置是否进行全参数微调。

在选择全参或部分参数微调时,我们通常采用LoRA微调方法。在Fantasy标签页中选择LoRA后,需要配置相关参数。关于LoRA算法的框架和运行原理,已在第一节课中详细介绍。通过调整更细粒度的参数,可以实现更深层次的模型微调。本次演示将采用默认配置。
另一种方法是QLoRA,适用于分布式集群环境。该方法在显存利用方面更具优势,但对硬件条件有特定要求。相关配置参数已预先设置完成。
需要强调的是,这些参数设置在实际工程应用中至关重要。每个参数的调整都可能影响模型性能,若在特定业务场景中出现问题,可能导致严重的经济损失或业务故障。因此建议在基础阶段就完成参数优化。
接下来,我们将以通义千问2.57B(East Dragon)模型为例,结合OpenMind Library动态生态框架,逐步演示模型微调的具体实现过程。


首先进行微调的加载。熟悉我的同学都知道,我更侧重于实操与实践。PPT仅用于快速展示,帮助我们在大脑中构建知识体系,作为后续操作的引导。
根据指引,我们可以下载不同的模型。首先需要打开工作空间,然后新建一个YAML文档。根据提示配置YAML文件,第一步是选择模型。

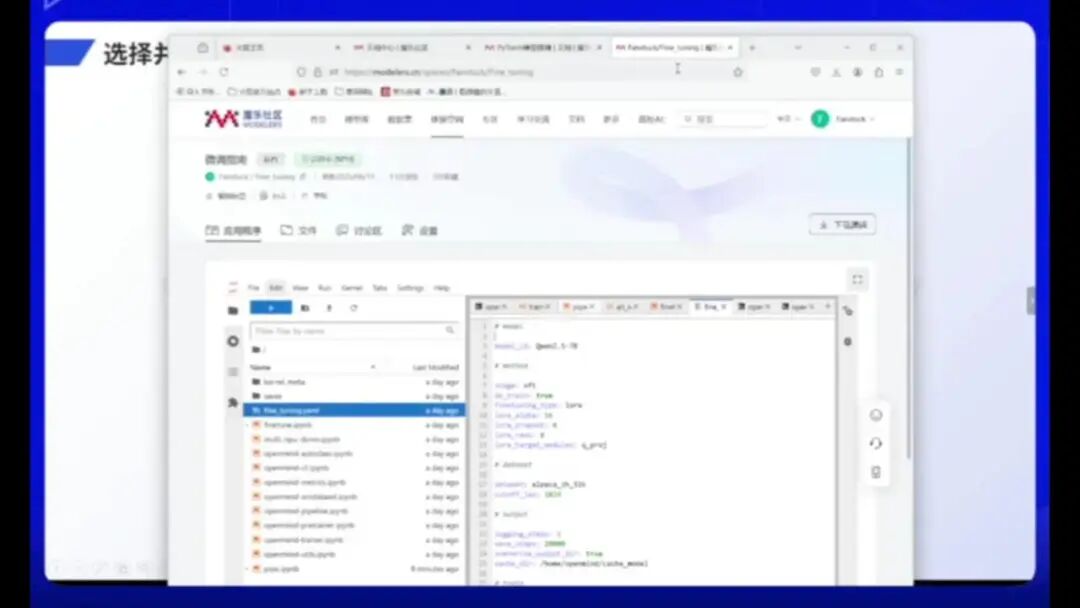
那么我们选择这个1500亿参数的模型。
然后其次我们要根据,
根据已有的数据集选择,
我选择的是APEX的51条弹幕形数据集,该数据集基于斯坦福大学发布的Alpaka英文指令数据集(52k条),可用于中英文指令微调。
在支持中文大语言模型LLM的研究中,具体采用JSON格式。我将提供详细的指令格式,需要加载至LUGE数据集。
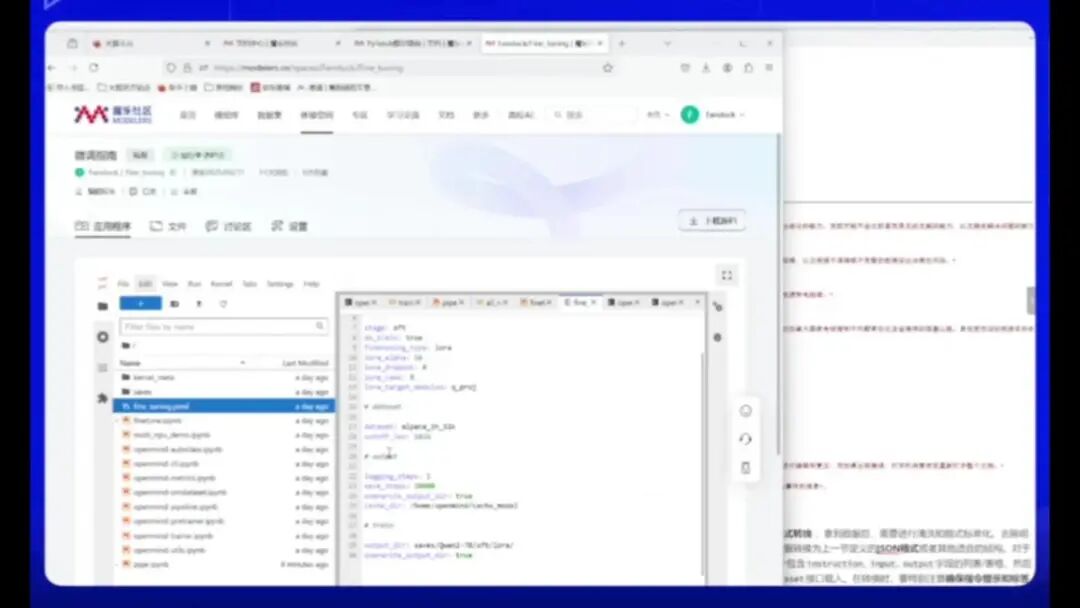
选择DataSeed,即AIPAC JHCK,其长度为1024。

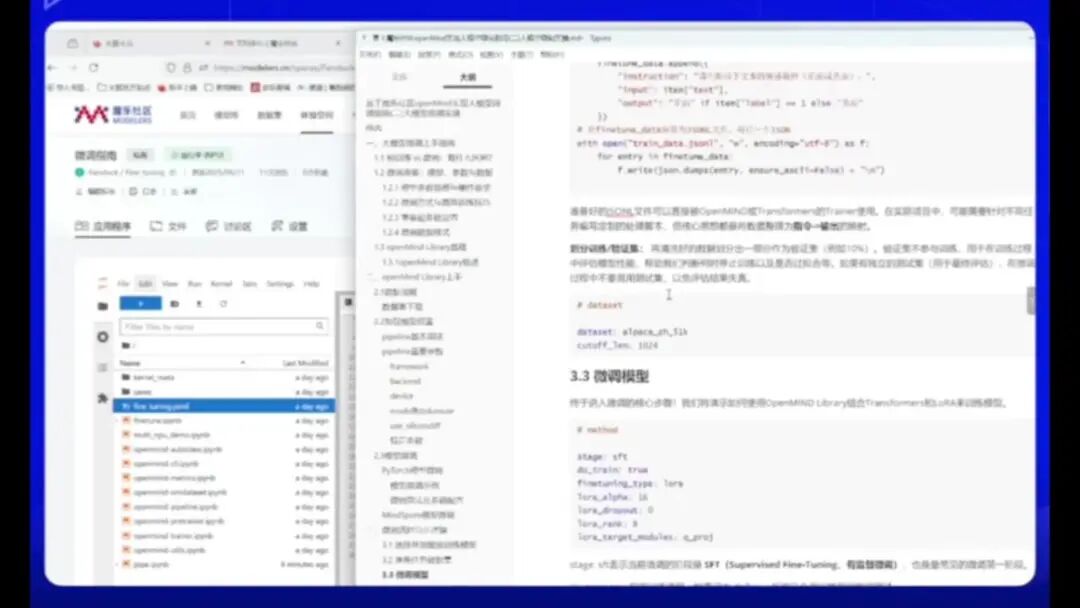
首先选择划分数据集,相关操作步骤已在文档中详细说明。本文档内容比官方文档更为详尽,建议按照所述步骤进行操作,后续理解会更加清晰。
部分代码无法运行可能是由于参数未及时更新至最新SDK版本所致,该问题将在后续更新中修复。目前无需急于运行这些代码,可先完成整体流程。
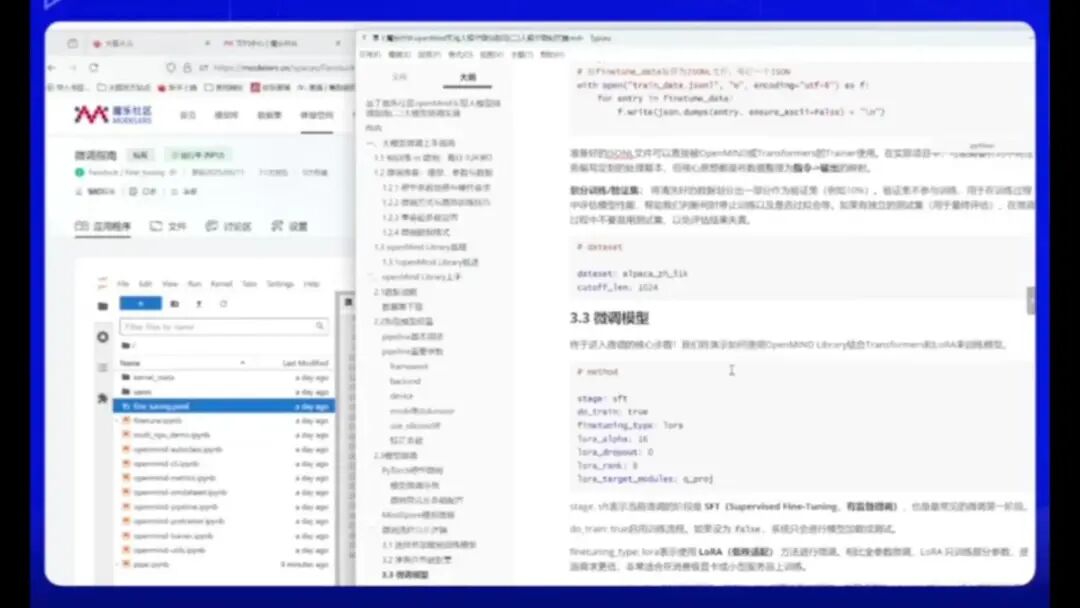
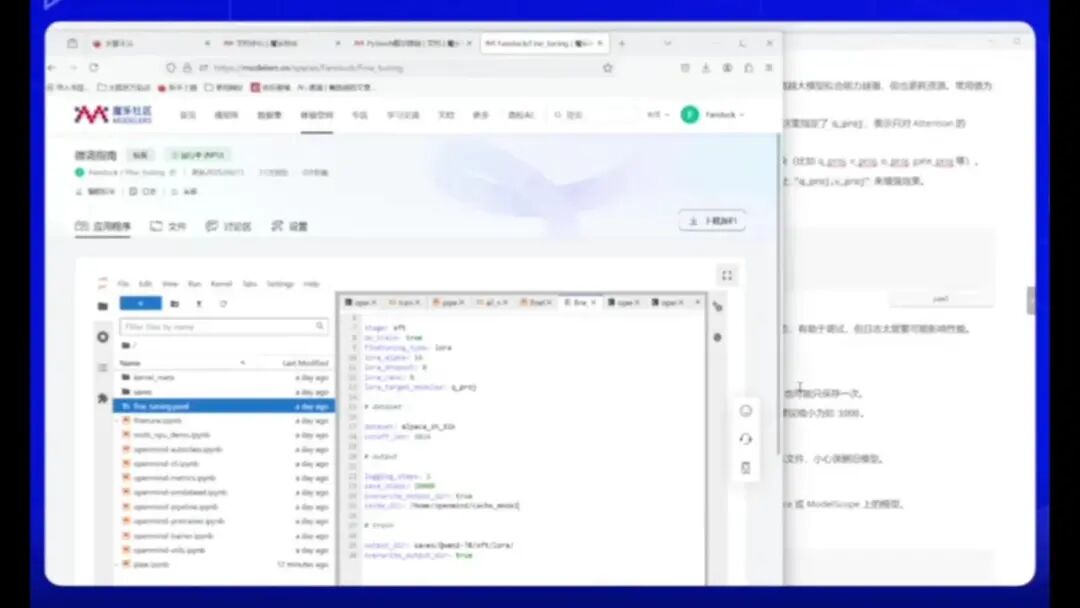
接下来我们将进入核心步骤,需要按照微调格式来训练LoRA模型。首先,我已明确列出每个参数的定义,并选择了SFT方法。

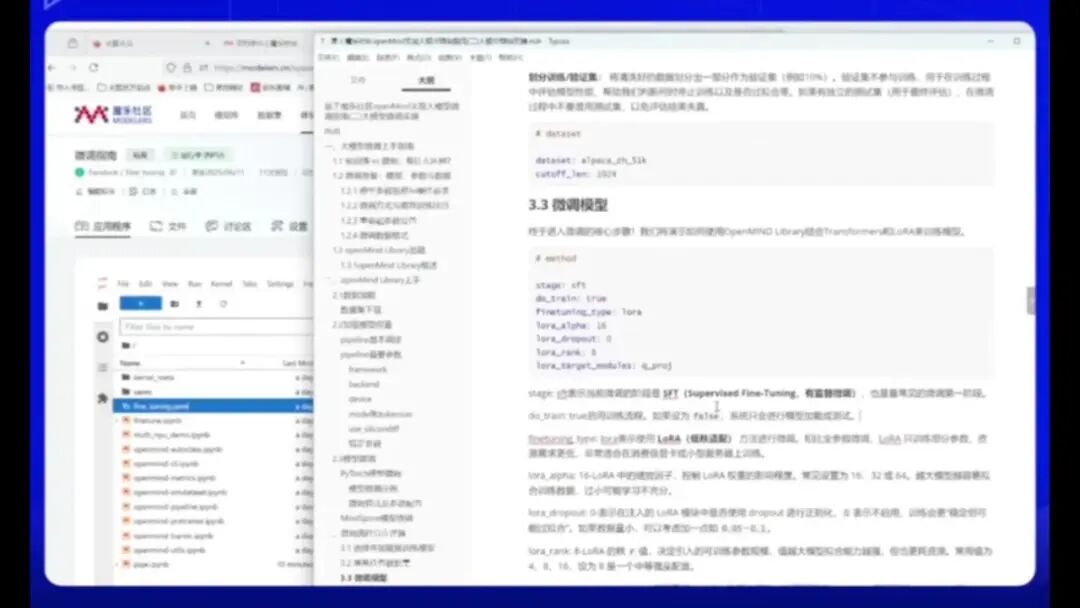
这是一个分阶段微调的过程,属于常见的微调第一阶段。其中包含多种配置选项:
1.训练流程设置
oDon’t Train:仅加载模型,不进行测试。
oFerden 和 Temper 类型:选择 LoRA 方法进行微调。
oLoRA 参数已详细列出,请根据说明进行配置。
2.模型输出与日志
o需指定微调后模型的输出路径。
o日志配置示例:
§Stem:每训练 10 步打印一次日志。若设为 1,则每一步都会记录权重和损失函数,但会影响性能。实际训练建议设置为 10 或 50。
o保存频率(Stemper):可根据数据集大小调整。例如,数据集较多时可设为 1000 或 5000,较少时保存一次即可。需结合数据量和 Batch Size 进行优化。
3.输出目录
o若目录已存在,则会覆盖原有文件。
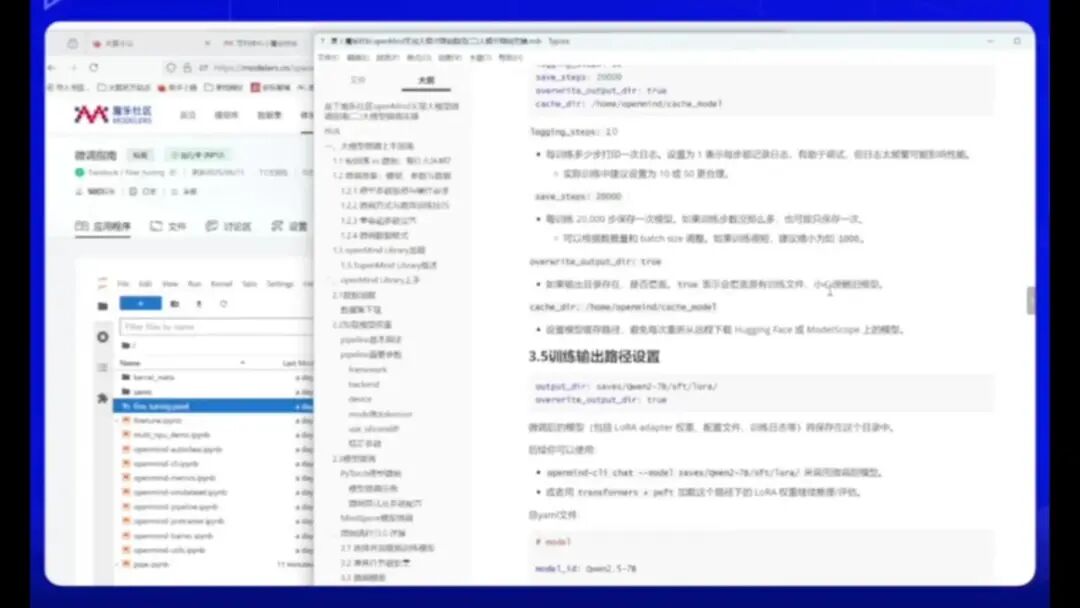
若未进行覆盖操作,系统将默认新增一个目录,而不会删除原有模型。
需注意的是初始缓存目录的设置。由于上方已加载模型,若指定了缓存目录,可避免每次从远程重新下载通义千问7B模型。模型文件将存储于该目录下。
同学们可参照我的操作,将文件放入YUM目录中。
之后,设置输出路径时,我直接将其保存在Server目录下。由于中断训练涉及多个参数设置,因此我采用了中断训练方式。
由于我使用的模型参数较高,且硬件配置有限,因此不在此进行训练演示。大家只需记住,使用指定参数进行训练后,模型将开始微调。
我总共花费了两小时完成微调过程。线下操作时,大家可以直接使用该流程。线上因训练时长较长,暂不展示。输入指令后,模型将启动微调。若使用0.5B或1.5B参数模型,则无需耗费如此长时间。
微调完成后,系统会生成一个server目录,点击即可进入。
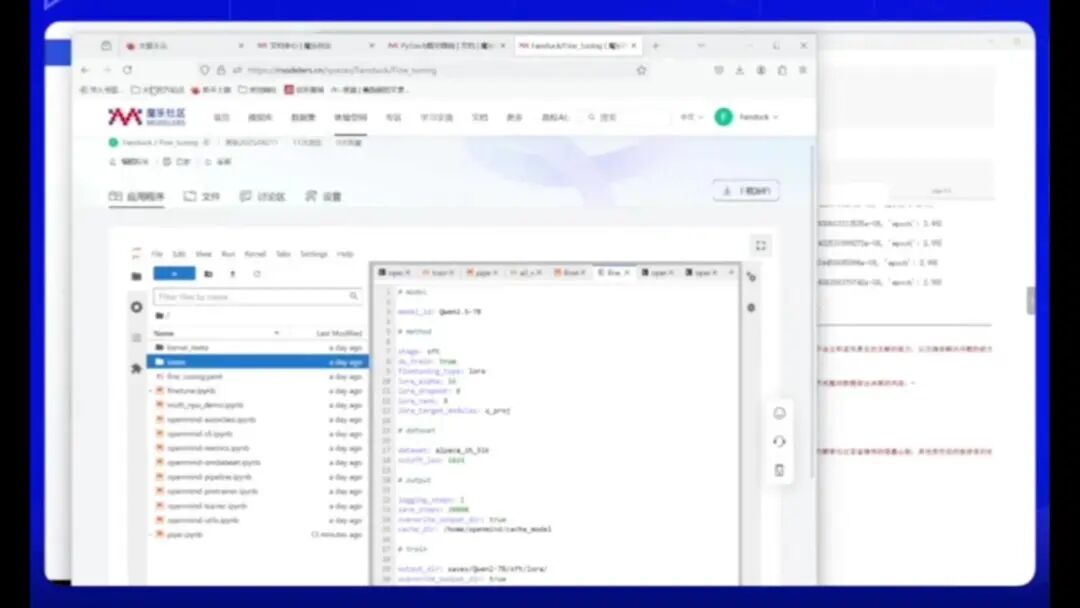
当前操作似乎存在延迟,系统已生成微调文件。以下是微调过程中产生的文件及其对应文件名。
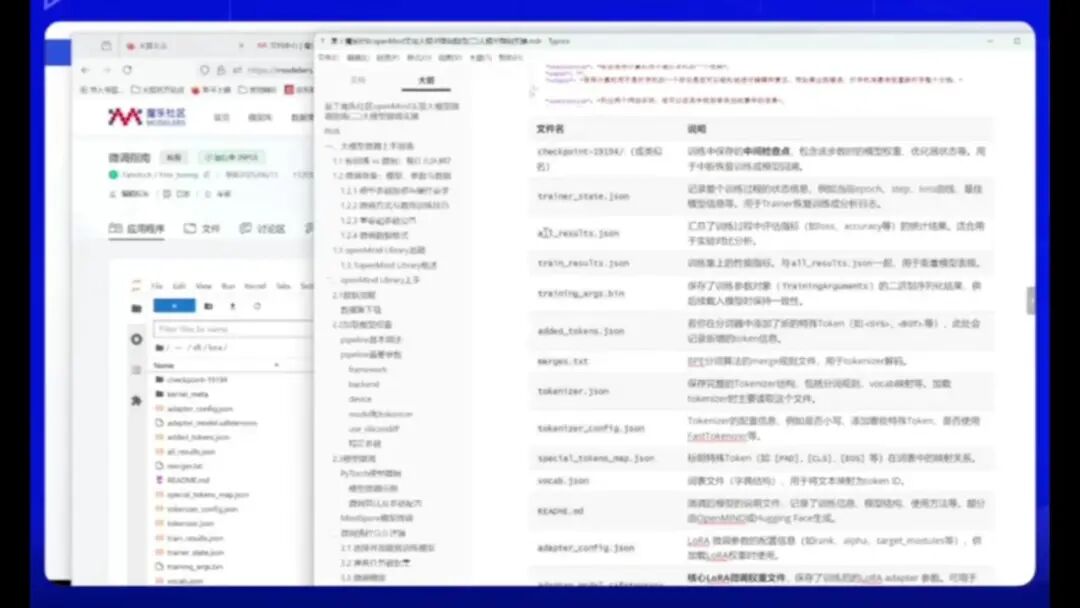
这里详细记录了整个过程。例如,检查点(checkpoint-19194)用于在训练过程中保存中间状态,包含模型权重等相关信息。
优化器状态可以进行回溯,记录整个通信过程或汇总模型评估的损失函数值,用于实验分析比对。结果保存在这里,包括损失函数值、训练用时(当前为2小时)以及训练准确性等指标。所有信息均按照文件进行了详细说明,点击即可查看。
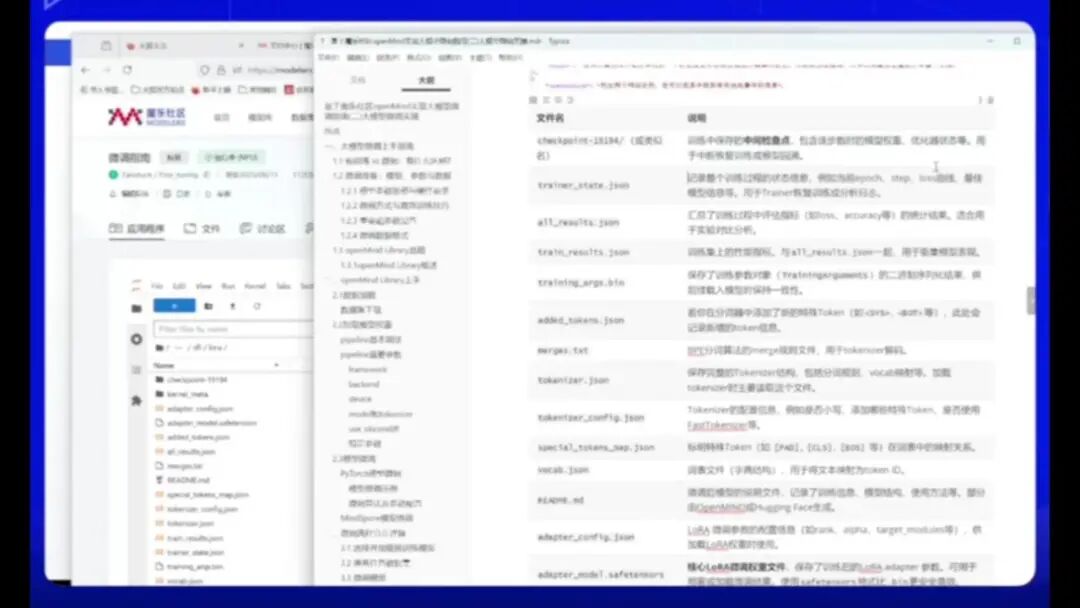
merges.txt文件是BPE分词算法的规则文件,适用于Tokenizer的解码过程。训练生成的模型权重保存在adapter_model.safetensors文件中,这是训练后的模型权重文件,需要特别注意。

核心LoRA微调的权重文件保存了训练后的参数,用于部署和进一步微调。成功完成微调后,将生成包含所有相关文件的微调结果。
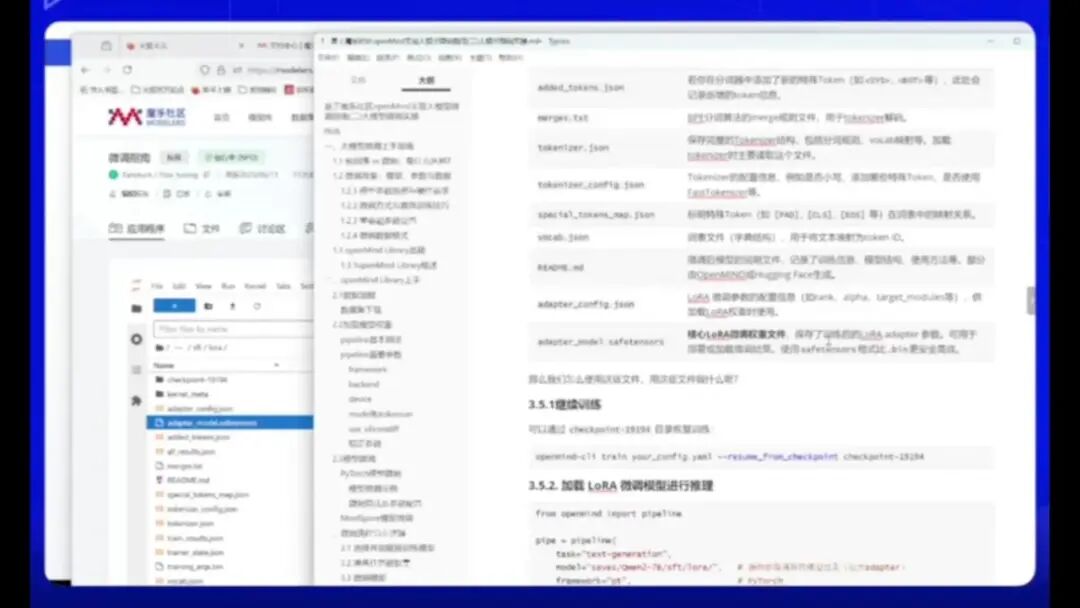
虽然微调过程至此结束,但我们需要了解如何利用这些文件。例如,探讨文件的具体应用场景和使用流程。

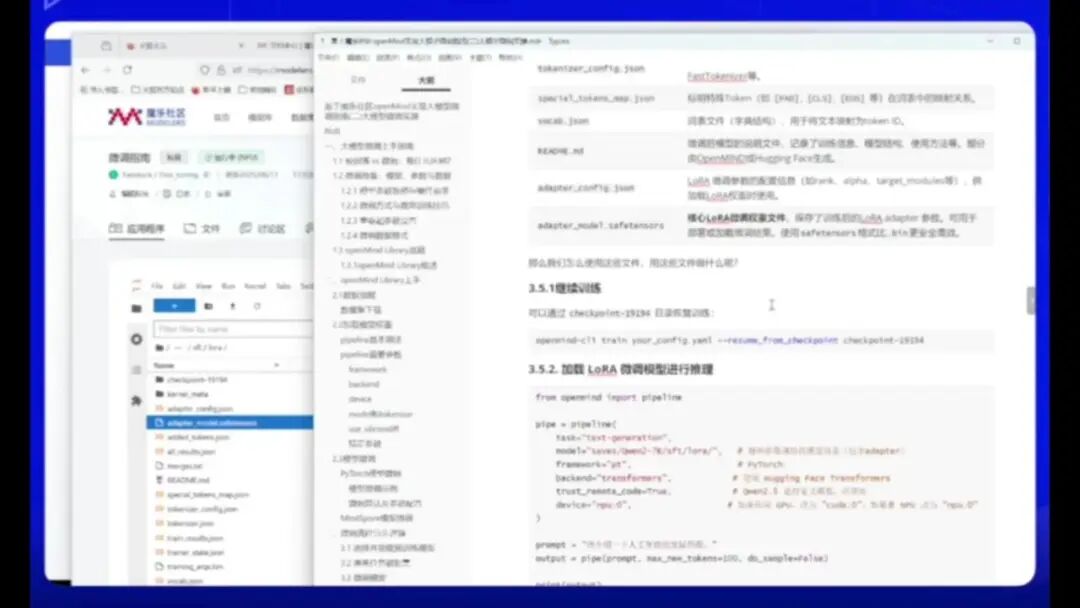
checkpoint目录用于恢复训练。若要加载模型,可使用以下代码进行推理:
使用pecker加载模型,模型保存在指定目录下,该目录指向微调目录。需注意模型格式为.pt,并使用npu显卡及transformer backend。
由于采用PyTorch框架,需选择ms模式,此时backend不再支持transformer,需切换至medialint。完成设置后即可加载训练好的模型。
如图所示,模型已成功运行并输出结果。在超参数设置中,max_token数限制为100,达到该值时会自动截断。当前界面显示了完整的微调过程。
现在,你可以参与我们的微调过程。经过第一到第二期的学习,你已经掌握了大模型工业级微调的基本算法调整能力。当然,这并不意味着你已经完全熟练,仍需要反复观看课程解说,并详细阅读文档中的参数说明,才能全面掌握模型微调技术。

有一个详细的认知过程。在完成模型微调后,必须进行效果测试。我们不会将每次微调后的模型直接投入生产环境使用。实际上,我们需要从批量训练的多个模型中选择最优版本。为此,我们需要评估模型效果。以下是常用的评估指标:

如果之前学习过经济学或深度学习,常见的评价指标在两者中是通用的,例如命中率、查准率、覆盖率等。
对于文本任务,则涉及RTE和LC的收音性,如UC。问答任务的指标则计算其命中率。

它的准确匹配率,有的用于摘要和翻译任务。

在评估模型性能时,覆盖面和召回率是关键指标。对话系统尤其具有挑战性,通常需要与业务部门的同事进行讨论和协商。通过直接使用业务场景进行评估,能够获得更准确、更符合实际业务需求的评价结果。
我们将完整呈现大模型微调的核心概念,包括大模型的基本原理、微调算法以及整个微调流程。这些内容将为各位提供全面的理解框架。

这些指标需要深入研究与细致分析。大模型的微调并非仅通过简单指令或少量样本即可完成,而是需要进行严谨的评估。这与工程项目类似,工程师必须对工程有充分的把握和严谨的态度,以确保其能够承担相应的工作任务和功能效果。
因此,必须反复查阅相关文档和参数,并仔细理解训练微调后的输出文档,才能成功微调出符合需求的模型。按照以下步骤,我们即可完成从模型选择到最终应用的整个过程。


从数据下载、参数配置、训练、微调、监控收敛到模型评估的全流程,对于初学者而言,每一步都需要耐心和反复实验。遇到问题时,应多分析错误信息以降低任务难度。例如,可以不采用通用的大模型如7B参数模型,而选择1.5P参数模型或自建小型数据集来简化任务。
本文提供了一个整体流程框架。通过反复实验可以发现,大模型微调并不神秘,而是一个有章可循的工程流程。建议大家尝试不同任务和数据组合,开展开拓性微调实验,在实践中积累经验,掌握各类问题的解决方法。
最终目标是能够驾驭大模型完成各种有趣的应用。祝愿大家在大模型应用领域取得丰硕成果。由于PPDR仅作引导,讲解到此结束,感谢各位的观看。

想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)