
预训练(Pre-training)与微调训练(Fine-tuning)区别
预训练与微调共同推动AI从“通用智能”走向“领域专家”。,使其精通特定任务。二者协同构建了现代AI的高效学习范式。理解二者差异,能更高效地设计训练流程——,这正是AI适应万千场景的核心密码。,赋予其广泛的知识基础;
·
 关于预训练(Pre-training)与微调训练(Fine-tuning)区别的详细解析,结合技术原理、应用场景及典型案例,帮助你系统理解两者的核心差异与协作价值:
关于预训练(Pre-training)与微调训练(Fine-tuning)区别的详细解析,结合技术原理、应用场景及典型案例,帮助你系统理解两者的核心差异与协作价值:
🧠 预训练 vs 微调训练:深度解析两大AI模型训练范式
预训练是模型的“通识教育”,赋予其广泛的知识基础;微调训练是“专业深造”,使其精通特定任务。二者协同构建了现代AI的高效学习范式。
🔍 一、本质定义与目标差异
| 维度 | 预训练(Pre-training) | 微调训练(Fine-tuning) |
|---|---|---|
| 核心目标 | 学习通用特征与语言规律 | 优化特定任务性能 |
| 训练数据 | 海量无标注数据(如网页、书籍) | 小规模标注数据(如分类标签) |
| 输出结果 | 基础模型(如BERT、GPT) | 任务适配模型(如法律问答机器人) |
- 预训练:通过自监督学习(如掩码语言建模、下一词预测),从万亿级Token中提炼语言结构、常识和跨文本关联,不依赖人工标注。
- 微调:基于预训练模型权重,用任务数据(如情感分析数据集)调整参数,使模型输出更精准、更专业。
⚙️ 二、技术流程与方法对比
1. 预训练:构建知识底座
- 训练方法:
- 自回归模型(如GPT):预测下一词,学习语言连贯性。
- 掩码模型(如BERT):遮盖部分词并预测原值,强化上下文理解。
- 数据规模:需TB级文本(如FineWeb数据集包含125T网页文本),覆盖多领域语言模式。
2. 微调训练:定制任务专家
-
关键步骤:
- 加载预训练权重(如InternLM或ChatGLM);
- 添加任务层(如分类头、序列标注模块);
- 选择性训练:
- 全参数微调:调整所有权重,适合数据充足场景;
- 参数高效微调(PEFT):仅训练少量参数(如LoRA低秩矩阵、Adapter适配器),节省90%算力。
-
典型挑战:
- 灾难性遗忘:过度微调可能丢失通用知识;
- 数据分布偏移:微调数据与预训练数据差异大时性能下降。
🚀 三、应用场景与典型案例
| 阶段 | 典型场景 | 案例说明 |
|---|---|---|
| 预训练 | 基础模型开发 | GPT-4:千亿参数模型,预训练于互联网文本,支持多语言生成。 |
| 微调 | 垂直领域任务 | 法律合同分析:基于BERT微调,识别条款风险(准确率提升12%)。 |
- 预训练价值:
- 解决数据稀缺问题(如小语种翻译);
- 提升模型泛化能力(跨任务迁移)。
- 微调价值:
- 快速适配:1周内构建医疗问答机器人;
- 降低成本:仅需1%预训练算力2,8。
🤝 四、协作关系:从通用到专用的技术链条
预训练与微调是递进而非对立:
- 预训练奠基:模型在大量数据中学习语言概率分布(如“苹果”可能指水果或公司);
- 微调聚焦:在特定数据中强化任务关联(如“苹果”在科技新闻中优先指公司)4,5。
工业级应用流程:
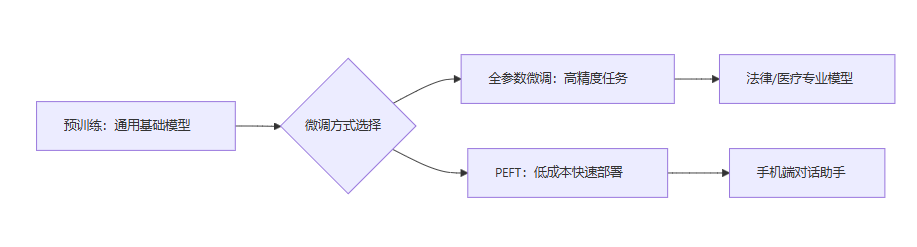
graph LR
A[预训练:通用基础模型] --> B{微调方式选择}
B --> C[全参数微调:高精度任务]
B --> D[PEFT:低成本快速部署]
C --> E[法律/医疗专业模型]
D --> F[手机端对话助手]📊 五、核心差异总结表
| 维度 | 预训练 | 微调训练 |
|---|---|---|
| 数据需求 | TB级无标注数据 | 百/千级标注样本 |
| 计算成本 | 千卡GPU集群训练数月 | 单卡GPU数小时~数天 |
| 输出能力 | 通用语言理解 | 任务专属优化 |
| 典型技术 | MLM、NSP、自回归 | LoRA、Adapter、Prompt Tuning |
| 适用阶段 | 模型开发初期 | 产品落地阶段 |
💎 结语:技术演进与未来方向
预训练与微调共同推动AI从“通用智能”走向“领域专家”。未来趋势包括:
理解二者差异,能更高效地设计训练流程——用预训练获取“知识广度”,用微调淬炼“技能深度”,这正是AI适应万千场景的核心密码
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)