
ollama 部署自己微调过的.safetensors模型
Ollama现已支持直接导入safetensors格式模型,无需转换为GGUF格式。用户需创建Modelfile文件配置导出参数,包括模板设置、系统参数及运行参数(如停止标记、上下文长度等)。使用时通过命令行执行"ollama create"命令加载模型,常见错误包括:Modelfile含中文导致解析失败,以及显存不足引发的CUDA错误(可通过nvidia-smi检查显存占用)
·
ollama已经支持safetensors类型直接导入,不需要再转换成GGUF
Modelfile文件
需要一个Modelfile控制导出参数
Modelfile:
FROM .
TEMPLATE """<|begin▁of▁sentence|>{{ if .System }}{{ .System }}{{ end }}{{ range .Messages }}{{ if eq .Role "user" }}<|User|>{{ .Content }}<|Assistant|>{{ else if eq .Role "assistant" }}{{ .Content }}<|end▁of▁sentence|>{{ end }}{{ end }}"""
PARAMETER stop "<|end▁of▁sentence|>"
PARAMETER num_ctx 4096
Parameter是模型使用时的参数,可用参数如下,有默认值,如果有需求可以自行修改
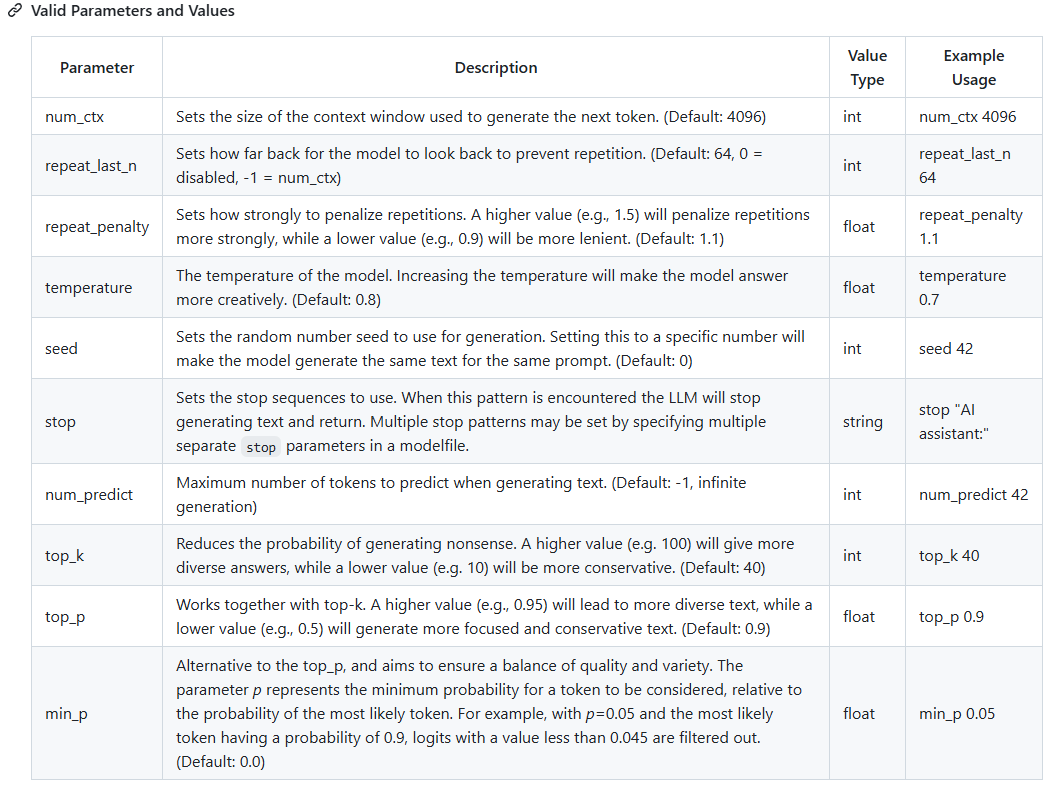
除了Parameter还有Template、system等参数可以参考:Modelfile 说明文档
ollama/docs/modelfile.md at main · ollama/ollama · GitHub
ollma导入模型
然后启动cmd操作ollama,输入:
cd 你的模型位置
ollama create 你的模型名称 -f Modelfile报错情况:
1、Modelfile文件中不要有中文,不然会报错Error: EOF
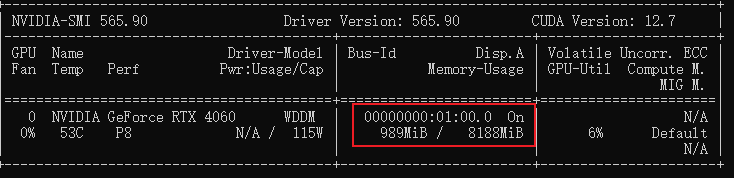
2、Error: llama runner process has terminated: error loading model: unable to allocate CUDA0 buffer。这是显存不够了
nvidia-smi查看显存使用情况
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)