
ms-swift框架微调qwen3-0.6b模型
使用alpaca格式的数据集,例如。swanlab实验可视化。
·
首先是安装相关的库:swanlab,swift,modelscope等。
下载模型:
from modelscope import snapshot_download
local_dir = "./my_qwen_model"
model_dir = snapshot_download('Qwen/Qwen3-0.6B',local_dir=local_dir)
将模型下载到本地./my_qwen_model目录内。
使用alpaca格式的数据集,例如huanhuan.json。
CUDA_VISIBLE_DEVICES=0
swift sft \
--model ./my_qwen_model \
--model_type qwen3 \
--dataset ./huanhuan.json \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 2 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-5 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 2 \
--eval_steps 200 \
--save_steps 200 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 4096 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--load_from_cache_file false \
--loss_scale ignore_empty_think \
--save_strategy steps \
--model_author glm \
--model_name qwen3_0.6b \
--report_to swanlab \
--swanlab_project swift-learn
各参数解释如下:
CUDA_VISIBLE_DEVICES=0
swift sft \
--model ./my_qwen_model \ # 指定基础模型的本地路径
--model_type qwen3 \ # 指定模型的类型,用于加载正确的模板和配置
--dataset ./huanhuan.json \ # 指定训练数据集的 JSON 文件路径
--train_type lora \ # 指定训练方法为 LoRA,一种参数高效微调技术
--torch_dtype bfloat16 \ # 指定模型训练时使用的数据类型,节省显存并加速计算
--num_train_epochs 2 \ # 指定训练的总轮数,模型将完整地看两遍数据
--per_device_train_batch_size 4 \ # 指定每个 GPU 上的训练批大小
--per_device_eval_batch_size 1 \ # 指定每个 GPU 上的评估批大小
--learning_rate 1e-5 \ # 指定优化器的学习率
--lora_rank 8 \ # 指定 LoRA 适配器的秩,控制其复杂度和参数量
--lora_alpha 32 \ # 指定 LoRA 的缩放因子,控制其对模型的影响强度
--target_modules all-linear \ # 指定将 LoRA 应用到所有线性层
--gradient_accumulation_steps 2 \ # 指定梯度累积步数,用于模拟更大的批大小
--eval_steps 200 \ # 指定每训练多少步进行一次评估
--save_steps 200 \ # 指定每训练多少步保存一次模型检查点
--save_total_limit 2 \ # 指定最多保留的检查点数量,以节省磁盘空间
--logging_steps 5 \ # 指定每训练多少步记录一次日志
--max_length 4096 \ # 指定输入序列的最大长度
--output_dir output \ # 指定输出目录,用于保存日志、模型等
--warmup_ratio 0.05 \ # 指定学习率预热的比例,用于稳定训练初期
--dataloader_num_workers 4 \ # 指定数据加载器的工作进程数,用于加速数据读取
--load_from_cache_file false \ # 设置为 false,每次都重新处理数据,便于调试
--loss_scale ignore_empty_think \ # 自定义的损失缩放策略
--save_strategy steps \ # 指定保存策略为按步数保存
--model_author glm \ # 设置模型作者的元信息
--model_name qwen3_0.6b \ # 设置模型名称的元信息
--report_to swanlab \ # 指定日志上报的可视化工具
--swanlab_project swift-learn # 指定在 SwanLab 中的项目名称
进行推理:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters ./output/v2-20251101-154047/checkpoint-934 \
--stream true \
--temperature 0 \
--max_new_tokens 2048
进行合并:
swift export \
--adapters ./output/v2-20251101-154047/checkpoint-934 \
--merge_lora true
```
进行合并后的推理:
```shell
swift infer \
--model_type qwen3 \
--model ./output/v2-20251101-154047/checkpoint-934-merged
swanlab实验可视化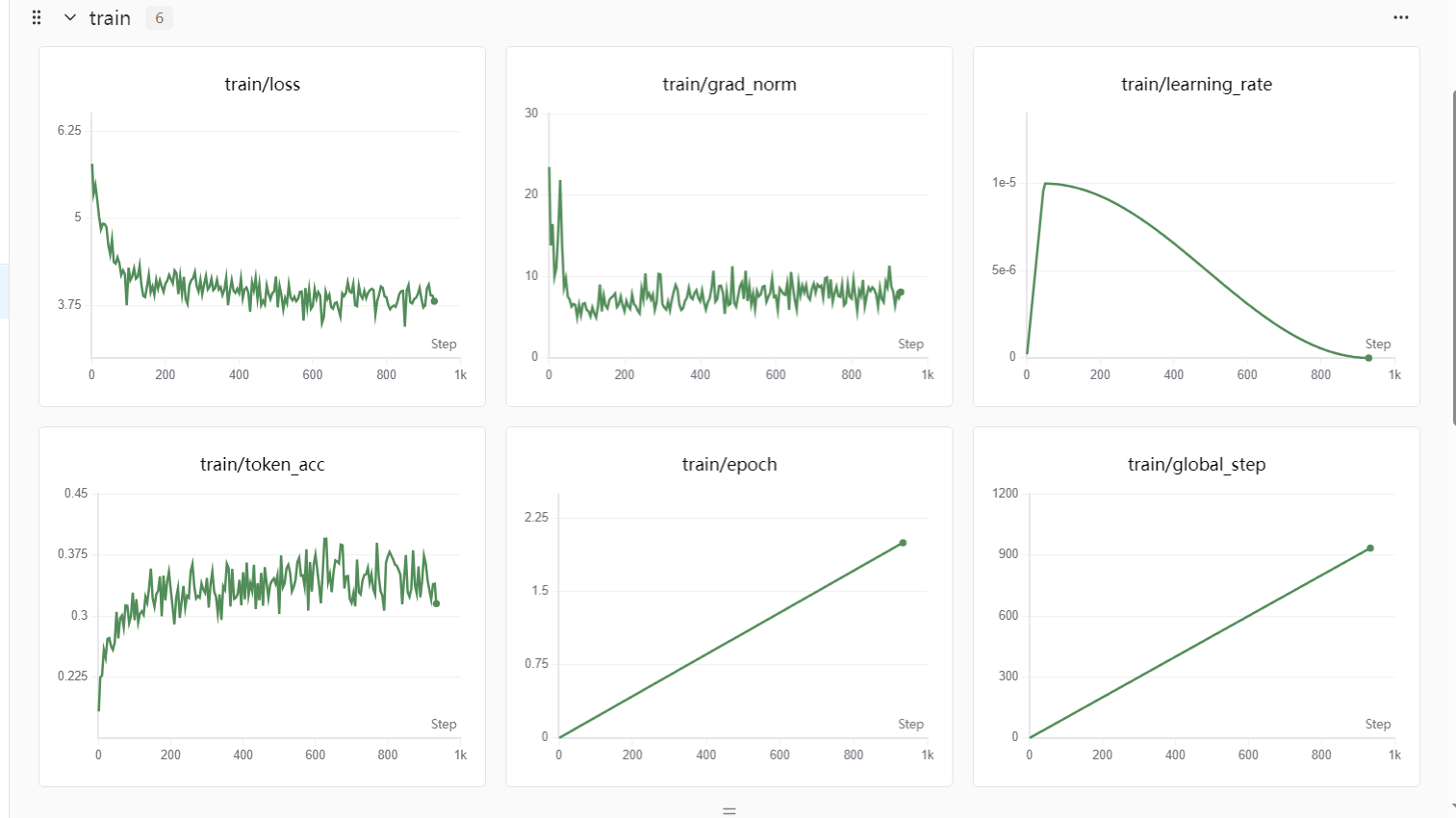
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)