
LoRA微调首选Q和V的奥秘
LoRA微调Transformer模型时,通常优先选择注意力机制中的Query和Value矩阵进行优化。这是因为Q矩阵直接影响注意力分配方向,V矩阵决定输出内容,二者对模型性能提升效果更显著。相比Key矩阵的中间媒介作用,微调Q和V能以较少参数量获得更好效果,且符合注意力机制工作原理。实际应用中会创建低秩矩阵并冻结原权重,仅训练新增参数。虽Q和V是主流选择,但根据任务需求也可调整组合策略。这种选择
LoRA微调主要是针对线性层的权重矩阵,例如注意力机制中的Q、K、V投影矩阵以及前馈网络(FFN)中的权重矩阵。那么对具有Transformer结构的模型进行LoRA微调的时候我们应该优先选择哪些权重矩阵进行微调呢?
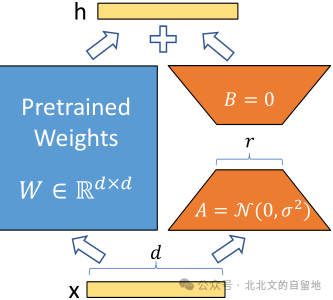
事实上在使用LoRA方法对大型语言模型进行微调时,最常见的做法是选择注意力机制中的Query(Q)和Value(V)矩阵进行微调,而不是Key(K)矩阵。
这种选择主要基于以下几个考虑因素:
为什么选择Q和V而非K?
1. 参数影响效率
Query(Q)和Value(V)矩阵在注意力机制中扮演着更直接的角色:
-
Query(Q)决定了模型"关注什么",直接影响注意力的分配方向
-
Value(V)决定了模型"获取什么信息",直接影响输出的内容表示
相比之下,Key(K)矩阵主要用于与Query进行相似度计算,在整个注意力机制中起到中间媒介的作用,对最终输出的直接影响相对较小。
2. 实验效果验证
大量实践表明,微调Q和V通常能够获得更好的性能提升。研究者通过对比实验发现,在有限的可训练参数预算下,将这些参数分配给Q和V矩阵能够获得更好的模型适应性和任务表现。
3. 计算资源优化
LoRA的核心思想是通过低秩分解来减少需要训练的参数量。在有限的计算资源下,选择对模型性能影响最大的矩阵进行微调是更为经济的做法。Q和V矩阵的微调通常能够以较小的参数量获得较大的性能提升。
4. 注意力机制的工作原理
从注意力机制的工作原理来看:
-
Query(Q)表示当前位置需要查询的信息
-
Key(K)用于与Query计算相似度,确定注意力权重
-
Value(V)是实际被加权聚合的信息
微调Q可以改变模型关注的方向,微调V可以改变模型获取的信息内容,这两者的组合能够有效地调整模型对特定任务的适应性。
LoRA微调的实施过程是怎样的?
在实际应用LoRA时,微调过程通常包括:
-
选择目标层:确定要应用LoRA的层,通常是Transformer架构中的注意力层中的Q和V矩阵
-
初始化低秩矩阵:为选定的Q和V矩阵创建低秩分解矩阵(A和B)
-
冻结原始预训练权重:保持原始模型参数不变
-
只训练新增的低秩矩阵:在训练过程中,只更新LoRA引入的参数
-
推理时合并参数:可以选择将LoRA参数与原始参数合并(可以是加权合并),不增加推理时的计算开销。
如果微调Q、V效果不好该怎么办?
虽然Q和V是最常见的选择,但根据具体任务和模型特点,有时也会采用其他组合:
-
有些研究者会选择Q和K的组合
-
在某些特定任务上,可能会只微调V矩阵
-
对于资源充足的情况,有时会同时微调Q、K、V三个矩阵
-
除了注意力层外,有时也会将LoRA应用于前馈网络层
总结
在PEFT的LoRA微调中,选择Query(Q)和Value(V)矩阵是最常见且经验证效果较好的做法。这主要是因为这两个矩阵对模型输出有更直接的影响,能够在有限的参数预算下实现更好的性能提升。然而,具体的选择还应根据任务特点、模型架构和可用资源进行调整,以达到最佳的微调效果。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)