
DeepMind | 合成数据+RL,SWiRL让大模型拥有超强“工具脑”!
总结1: SwiRL + Tool use > Base Model + Tool use >> Base Model。引入工具后还是效果提升非常大,说明Base Model已经具备不错的Tool调用的能力了。SwiRL可以改进Tool 调用的能力。总结2: 不需要其他标注资源,利用现有的Model就可以合成数据进行RL训练提升Model的Tool Use能力。
大家好,我是HxShine
今天分享一篇来自斯坦福大学和 Google DeepMind 的文章,标题为:《Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use》(利用合成数据生成和多阶段强化学习进行推理和工具使用)。
本文提出了一种名为 SWiRL (Step-Wise Reinforcement Learning) 的方法,旨在优化 LLMs 在复杂多步推理和工具使用任务中的表现。该方法分为两个主要阶段:
2. 合成数据生成:通过迭代式生成多阶段(Multi-step)的推理和工具使用数据,并从中学习。
2. 多目标强化学习:提出一种针对多阶段优化的强化学习方法。提示模型的Tool调用以及推理能力能力。
与Search-R1等方法不同,其通过合成推理的Tracing数据,并基于该数据来进行RL学习,可以极大提升在复杂多步推理和工具使用任务中的表现。可以给后续DeepResearch的端到端的RL训练提供一个参考。
一、概述
- Title: Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use
- URL: https://arxiv.org/abs/2504.04736
- Authors: Anna Goldie, Azalia Mirhoseini, Hao Zhou, Irene Cai, Christopher D. Manning
1 Motivation
- 现有的 LLMs 在处理需要多步骤推理和工具使用的复杂查询时(如多跳问答、数学问题求解、编程等)表现不佳。
- 传统的强化学习方法(如 RLHF、RLAIF)主要关注单一步骤优化,而多步骤任务中,中间步骤的错误可能导致最终结果的错误,因此需要对整个行动链条的准确性进行优化。
- 需要开发一种能够处理多步骤动作序列(例如,确定何时停止搜索以及何时综合信息)并有效从错误中恢复的优化技术。
2 Methods
SWiRL 方法旨在提升 LLM 在多步推理和工具使用任务中的表现,避免了对人工标注和GroundTruth的依赖,其核心在于合成数据生成和基于模型判定的分步强化学习。
优点总结:不需要Golden label,不需要人类标注,基于model-based judgment和data生成,过滤,来做RL的训练。
详细方法和步骤:
Stage 1: 多步合成数据生成与筛选 (Multi-Step Data Collection)
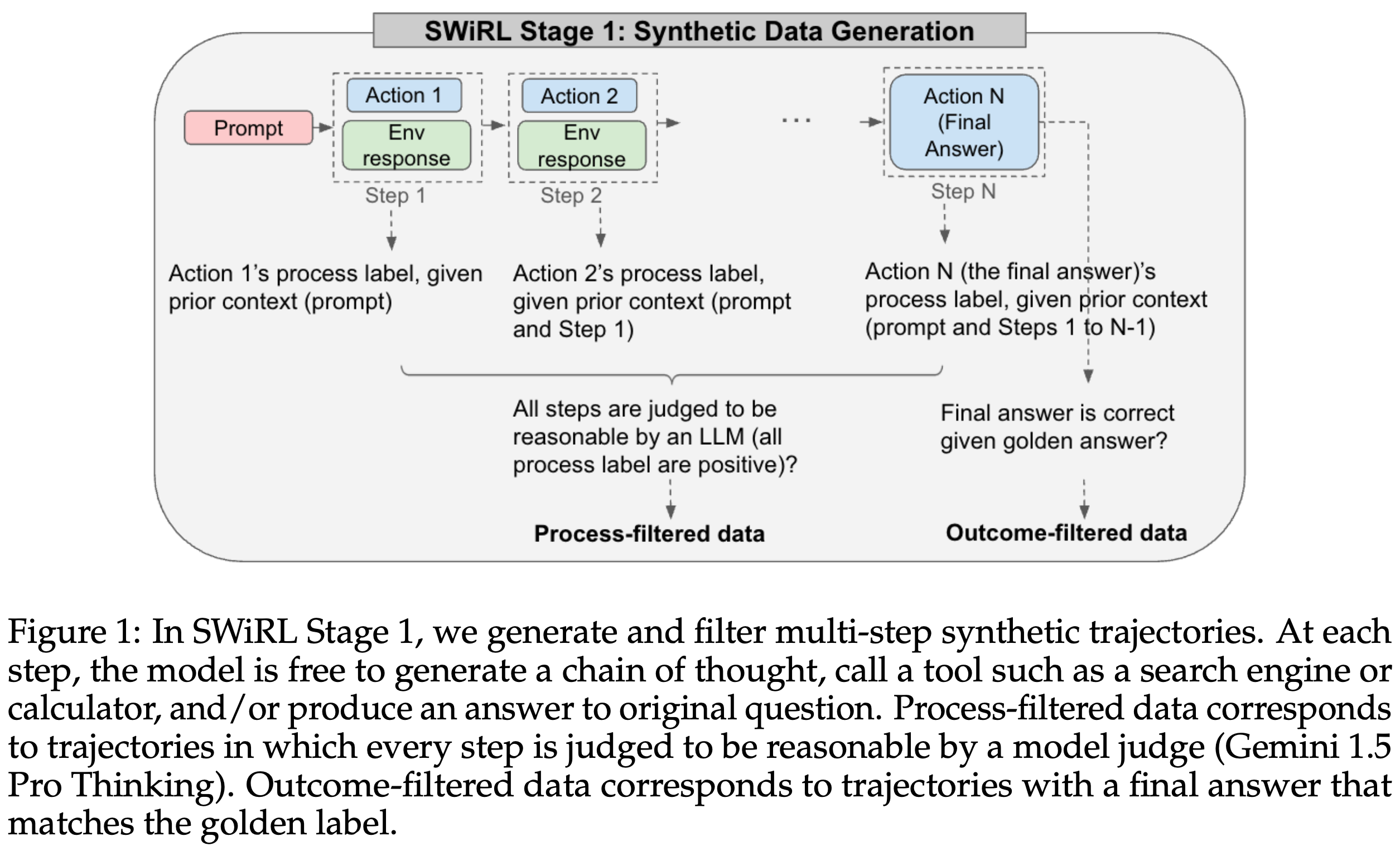
- 数据生成:
- 使用开源 LLM (Gemma 2) 并接入外部工具(如搜索引擎或计算器)。
- 迭代式地提示模型生成多步轨迹(trajectories)。在每一步中,模型可以生成思维链(chain of thought),选择调用工具或直接给出最终答案。
- 如果模型调用工具,则查询会被自动提取并在环境中执行,结果会作为下一步的上下文提供给模型。
- 轨迹在模型生成最终答案(通过特殊标记表示)时结束。
- 轨迹转换: 将包含 k 个动作的轨迹转换为 k 个子轨迹,每个子轨迹包含从开始到该动作的所有上下文。
- 数据筛选策略:探索四种筛选策略对模型性能的影响:
- No filtering (无筛选):不进行任何筛选。
- Process filtering (过程筛选):保留每一步都被模型(Gemini 1.5 Pro Thinking)判断为合理的轨迹。判断标准是当前动作 a_i 在给定上下文 s_i 下的合理性,不使用GroundTruth。
- Outcome filtering (结果筛选):仅选择最终答案 a_K 与GroundTruth的轨迹。
- Process and outcome filtering (过程与结果联合筛选):同时满足过程合理性及最终答案正确的轨迹。
- 数据集构建规模:
- 收集了 50,000 条合成轨迹(基于 10,000 个 HotPotQA 训练集问题,每个问题 5 条轨迹)。
- 收集了 37,500 条合成轨迹(基于 7,500 个 GSM8K 训练集问题)。
- 为防止轨迹过长,将 HotPotQA 的最大步骤数设置为 5,GSM8K 设置为 10。
Stage 2: 分步强化学习优化 (Step-Wise Reinforcement Learning Methodology)

-
优化目标:
- 目标函数是期望的逐步奖励总和:
J(θ) = E[R(a|s)],其中R(a|s)是根据生成式奖励模型(Gemini 1.5 Pro)评估当前动作 a 在上下文 s 下的质量。不使用GroundTruth label来做Reward。 - 该方法通过细粒度的、按步骤的微调,使模型能够学习局部决策(预测下一步)和全局轨迹优化(生成最终响应),并获得即时反馈。
- 目标函数是期望的逐步奖励总和:
-
推理阶段评估 (Step-Wise Inference-time Evaluation):
- 在推理时,模型会迭代地被提示,选择调用工具或生成最终答案。
- 如果模型生成工具调用(如
<search_query>或<math_exp>标签),则解析查询并在环境中执行,结果会注入到模型上下文中。 - 该过程持续直到模型生成答案(通过
<answer>标签表示)或达到最大查询次数限制(问答数据集 5 次,数学推理数据集 10 次)。

Q1: 他的reward是怎么来的,如何计算?
答:作者直接采用Gemini 1.5 Pro(直接LLM as judge,这个效果好吗?)作为reward model。其主要做法是:
- 每一步生成之后,用reward model来判定本步动作(如某条搜索查询或推理步骤),在当前上下文里是否“reasonable(合理)”。
- reward model的判定形式是:对于每一个action,reward model只基于该action和前面的全部上下文(包括之前的步骤和环境给出的反馈),判断这一步的推理或操作是否靠谱,然后输出评分(相当于是“好/坏”标签,见原文 process filtering prompt)。
- 这种reward不是基于最终答案(outcome),而是基于每一个过程动作的合理性(process-based)。

优点:
- 生成数据快、成本低,不用人工逐步标注,只要评判prompt设计合理即可。
- 它能更细粒度地对每个步骤给反馈,而不是等整个问题解完后才评判,避免“只会背答案”的问题,提高多步推理能力。
- 这样能充分利用现有强大LLM的理解和判断力,不需要再训练一个reward模型。
Q2:如何理解强化学习的目标函数?
J(θ)=Es∼T, a∼πθ(s)[R(a∣s)] J(\theta) = \mathbb{E}_{s\sim T,\; a\sim\pi_\theta(s)} [R(a|s)] J(θ)=Es∼T,a∼πθ(s)[R(a∣s)]
1. 各个符号的含义:
- J(θ)J(\theta)J(θ):是整体的优化目标函数,也叫“期望总奖励”。目标是让模型学会让J(θ)J(\theta)J(θ)值最大化,也就是每一步都能获得尽可能高的奖励。
- θ\thetaθ:代表基础语言模型的参数,训练过程就是不断调整θ\thetaθ。
- s∼Ts \sim Ts∼T:sss表示在合成的数据轨迹中出现的所有“状态”,TTT是全部这些状态的集合。每条多步轨迹中,每到达一个新的上下文/已知信息组成的时刻就是一个sss。
- a∼πθ(s)a \sim \pi_\theta(s)a∼πθ(s):πθ\pi_\thetaπθ是当前参数下的模型策略,意思是在状态sss下,模型会生成一个动作aaa(比如输出一步链式推理,或发起一次工具调用)。
- R(a∣s)R(a|s)R(a∣s):奖励函数。在当前上下文sss下生成action aaa后,由Gemini 1.5 Pro这样的奖励模型打分,衡量aaa在当前sss下的“合理性”“高质量”程度。
2. 整体的优化思想: 在所有的数据状态sss下,从模型当前策略πθ\pi_\thetaπθ生成的动作aaa,经奖励模型R(a∣s)R(a|s)R(a∣s)打分后,整体的平均分数要尽量高。强化学习的目标就是最大化这个J(θ)J(\theta)J(θ),即让模型输出每一步都受到奖励模型认可、在多步推理链条上“逐步走好”。模型每走一步、每输出一句话/工具调用,都会根据之前的全部上下文被奖励模型打分;整个训练的目标就是反复采样这样的“状态-下一步行为”,期望行为在奖励模型评价体系下,平均得分越高越好。
3 Conclusion
- 多步推理与工具使用的显著提升: SWiRL 在复杂多跳问答和数学推理任务中,平均性能优于基线模型达 15%。
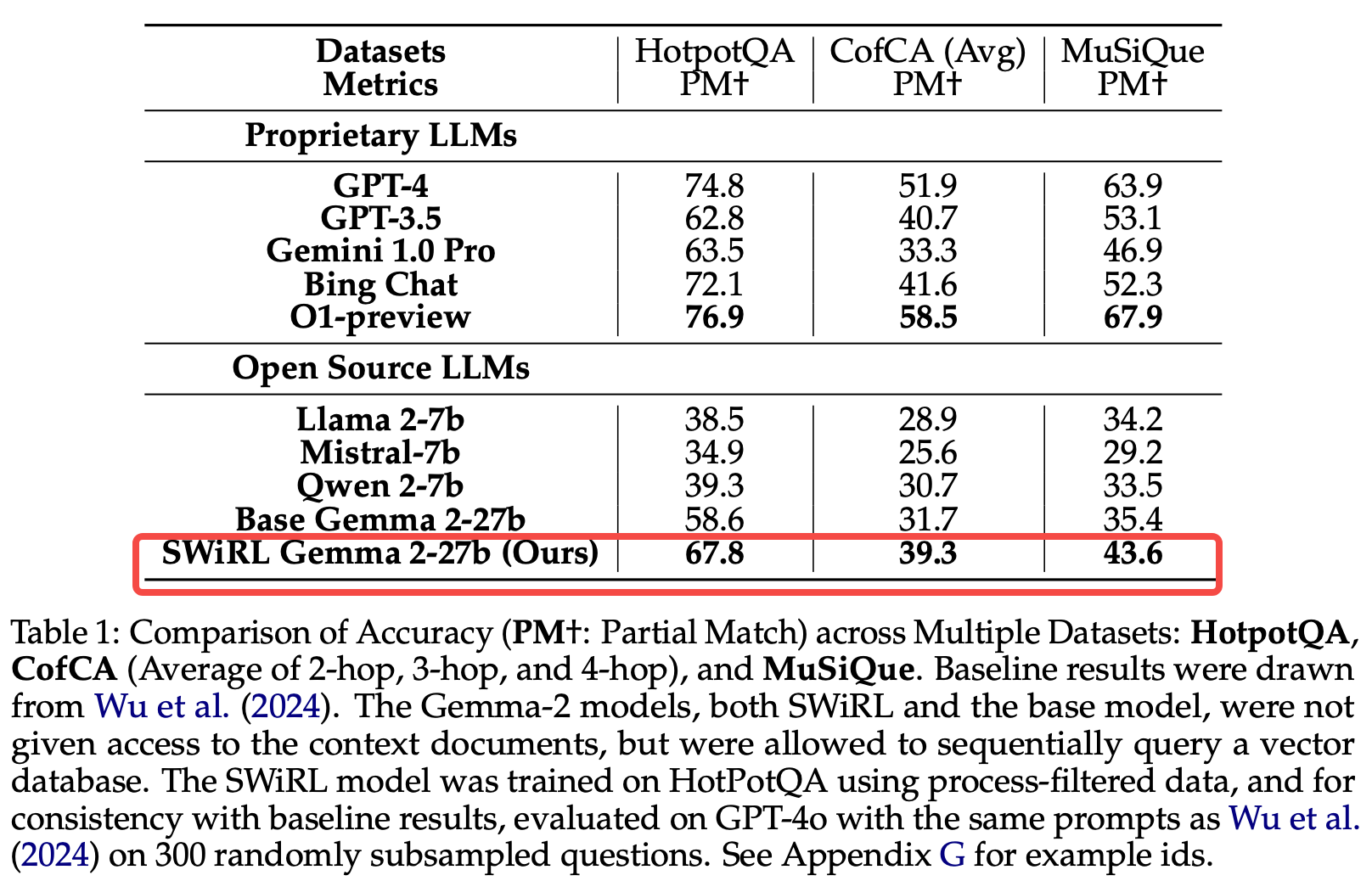
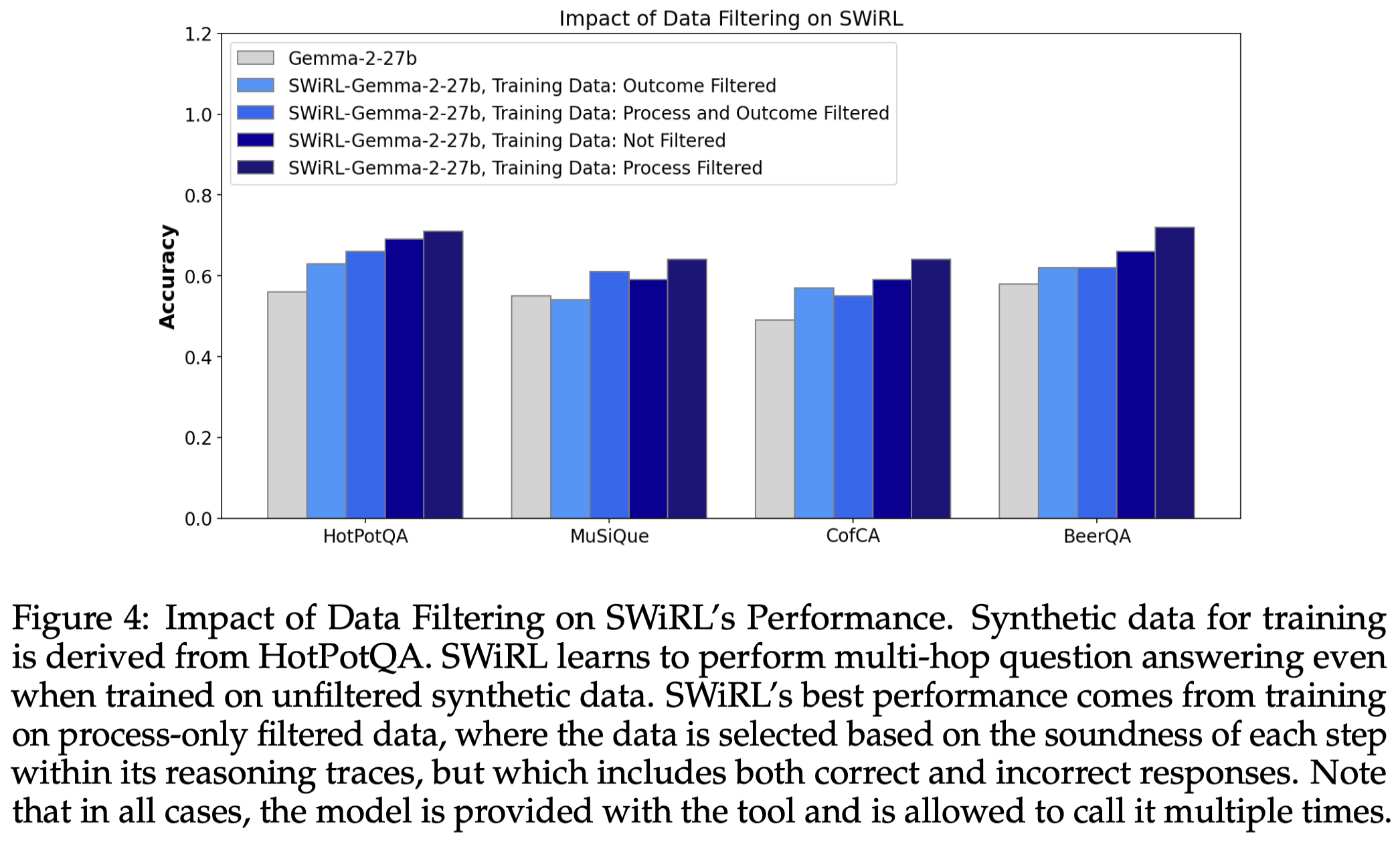
- 数据筛选策略的有效性: 该方法即使在未筛选的数据上也能有效学习,但在“仅过程筛选”的数据上表现最佳,这表明模型可以从包含不正确最终答案的轨迹中学习,甚至受益于正确和不正确最终答案的混合数据。
- Process filtering (过程筛选):指的是保留每一步都被模型(Gemini 1.5 Pro Thinking)判断为合理的轨迹。判断标准是当前动作 a_i 在给定上下文 s_i 下的合理性,不使用GroundTruth。
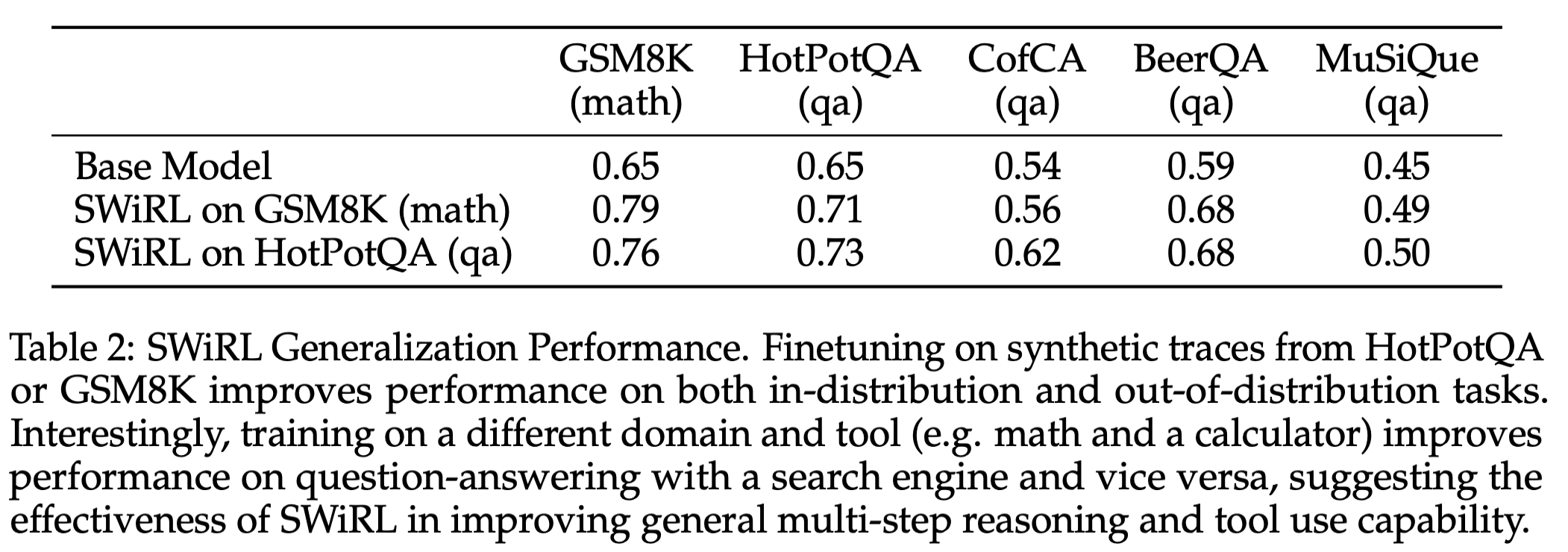
- 强大的跨任务泛化能力: SWiRL 展现了强大的泛化能力,例如,在多跳问答(HotPotQA)上训练,能将数学推理(GSM8K)性能提升 16.9%,反之亦然,说明其提升了通用的多步推理和工具使用能力。
4 Limitation
- 模型规模限制: 尽管 SWiRL 对较小的模型(如 Gemma-2-2b 和 9b)在领域内数据集上有益,但它们未能展现与大型模型(Gemma-2-27b)相同的跨任务泛化能力。这表明 SWiRL 的有效性可能受模型规模限制,对于小模型,其泛化能力不如大模型。
5 Future Work
- 探索更大模型规模和更多任务: 对更大模型和更多复杂任务进行 SWiRL 的评估,以确认其泛化能力。
- 优化奖励模型和数据生成: 进一步研究如何改进奖励模型的设计,以及如何更有效地生成高质量的合成数据,以进一步提升性能。
- 在线与离线 RL 的结合: 探索结合在线和离线强化学习方法,以弥补离线方法在实时交互和适应性方面的不足。
二、详细内容
1 SFT 与 SWiRL 性能比较
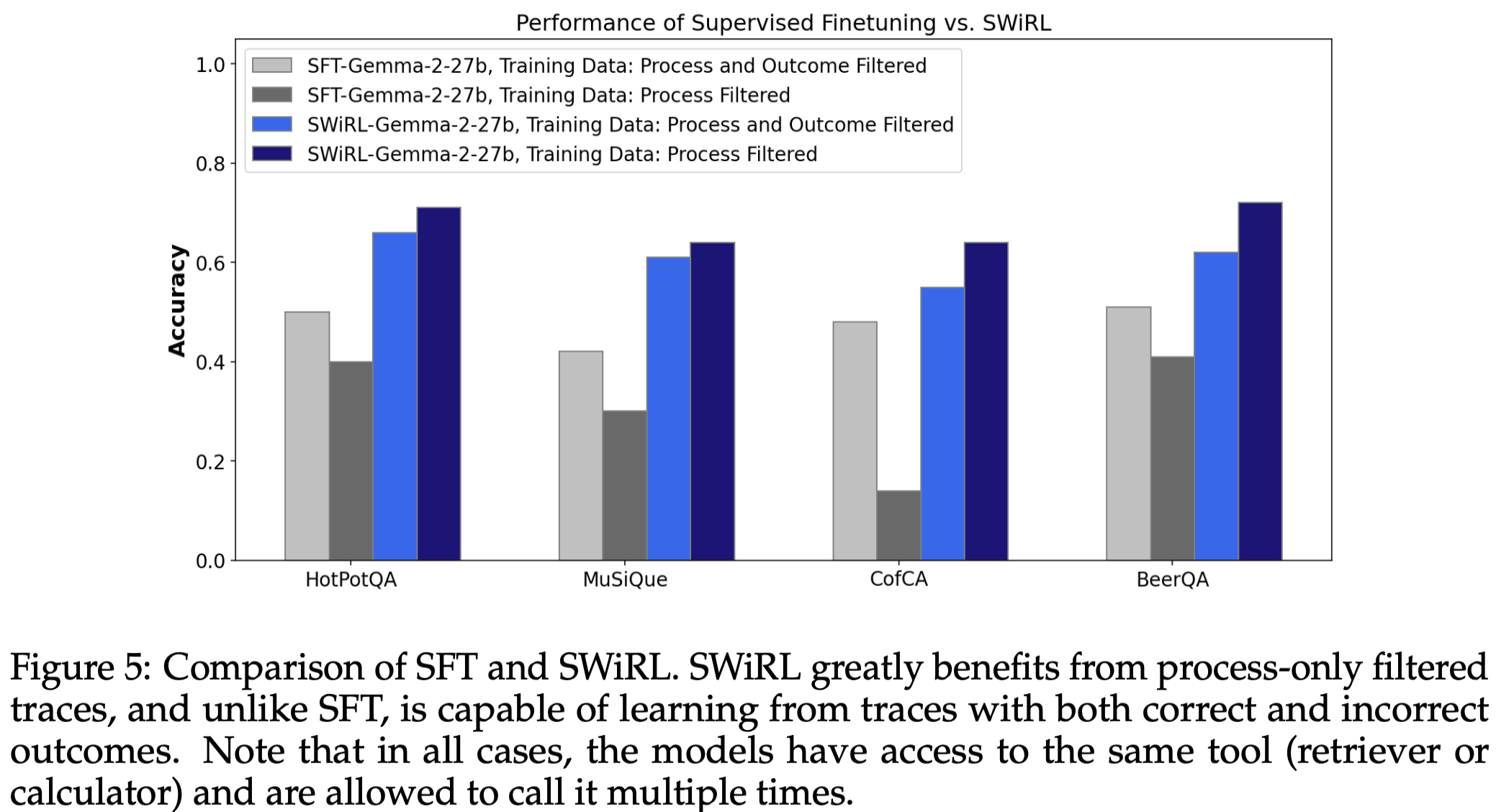
- SWiRL 优于 SFT:SWiRL 在“仅过程筛选”的轨迹中表现出显著优势,并且能够从同时包含正确和不正确结果的轨迹中学习,而 SFT 则不能。
2 SWiRL 在有无多步工具使用时的性能表现
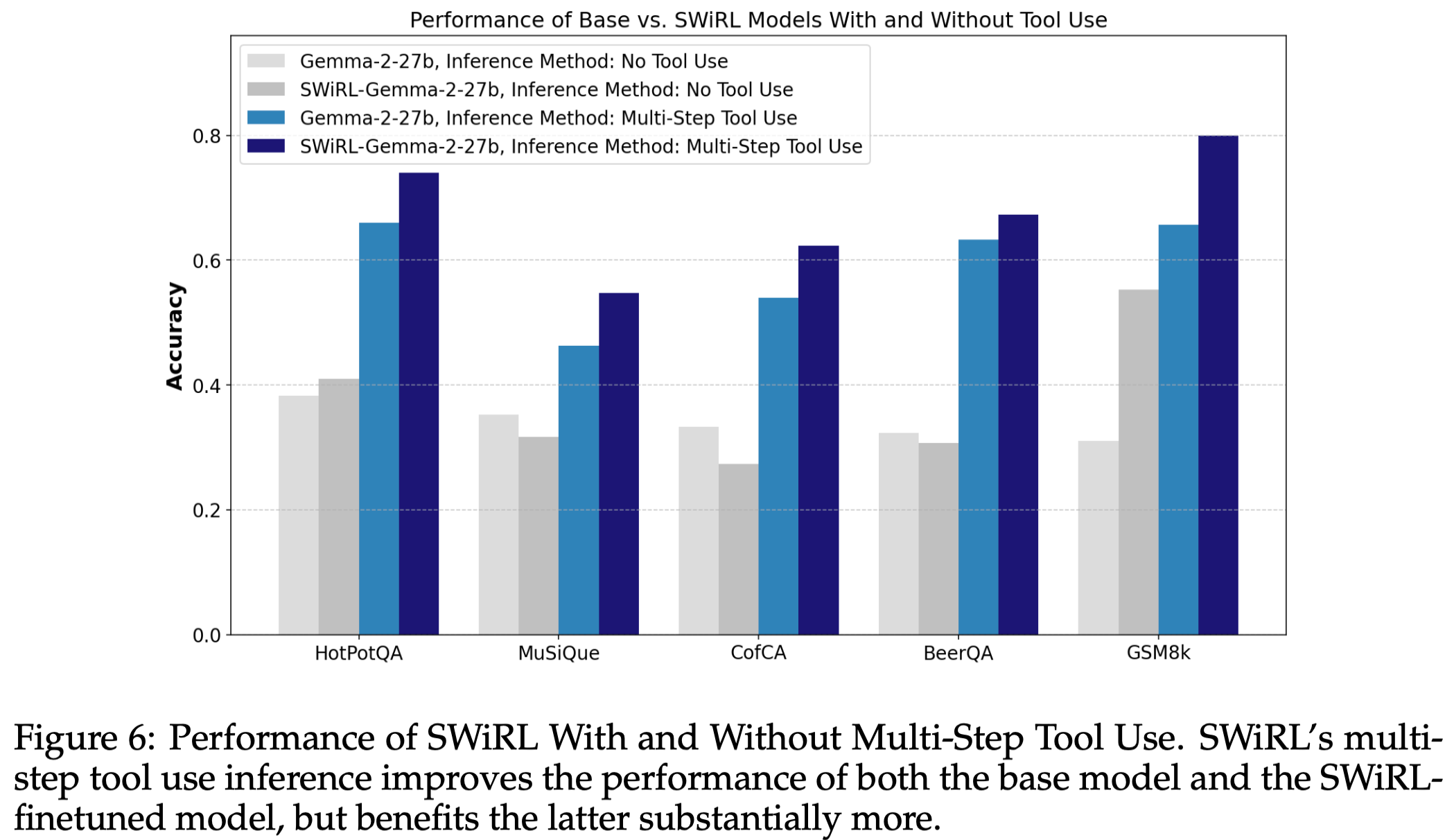
- 总结1:SWiRL 的多步工具使用推理既提升了基线模型和 SWiRL 微调模型的性能,但在后者身上提升更为显著。
- 总结2:即使没有工具访问,SWiRL 模型也展现出显著改进,这表明 SWiRL 训练提高了模型将复杂问题分解为多个可管理子任务的能力。
3 性能与合成数据集大小的关系
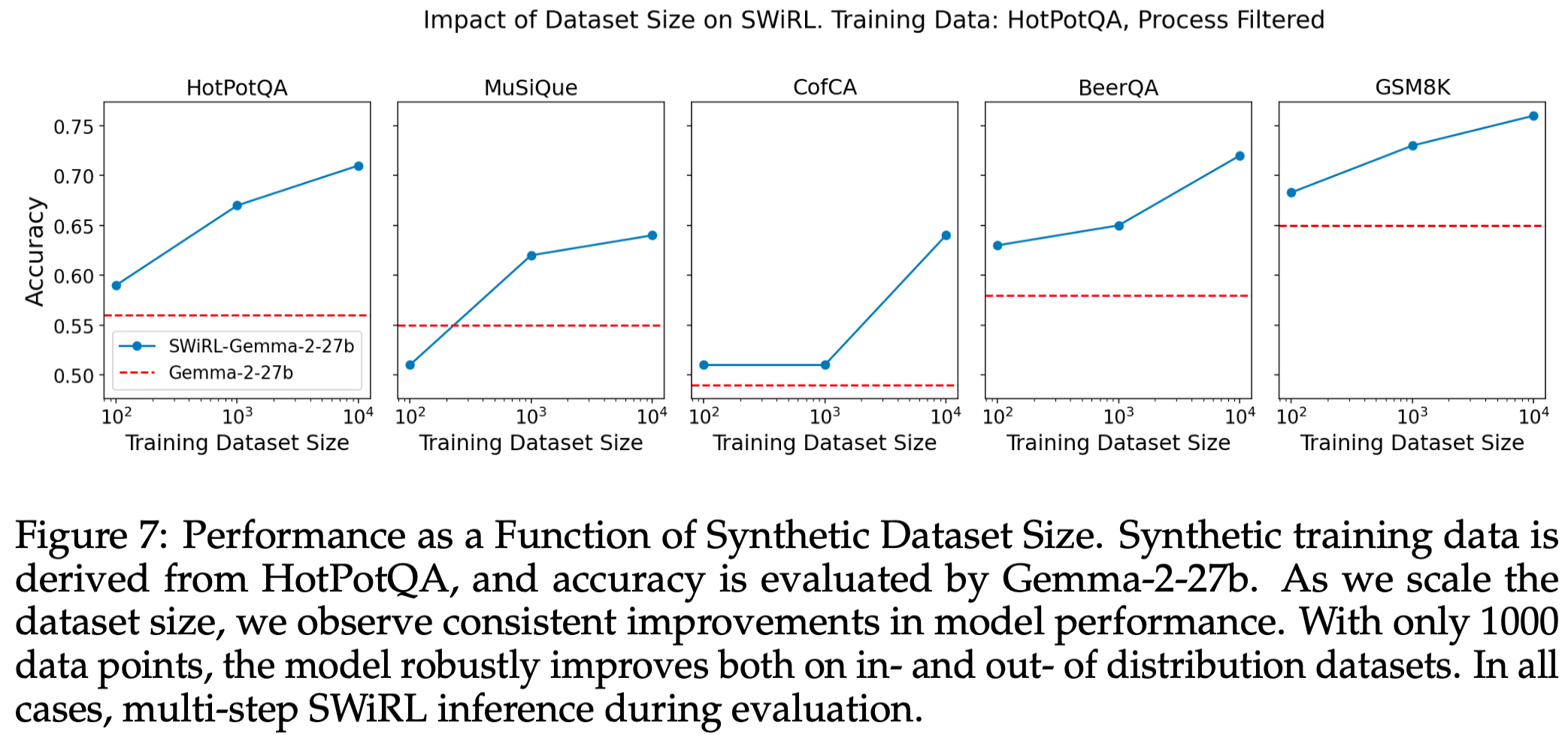
- **总结:**即使仅有 1000 个数据点,模型也能在域内和域外数据集上实现显著改进。
4 SWiRL、基线模型与 Gemini 1.5 Pro 的性能比较
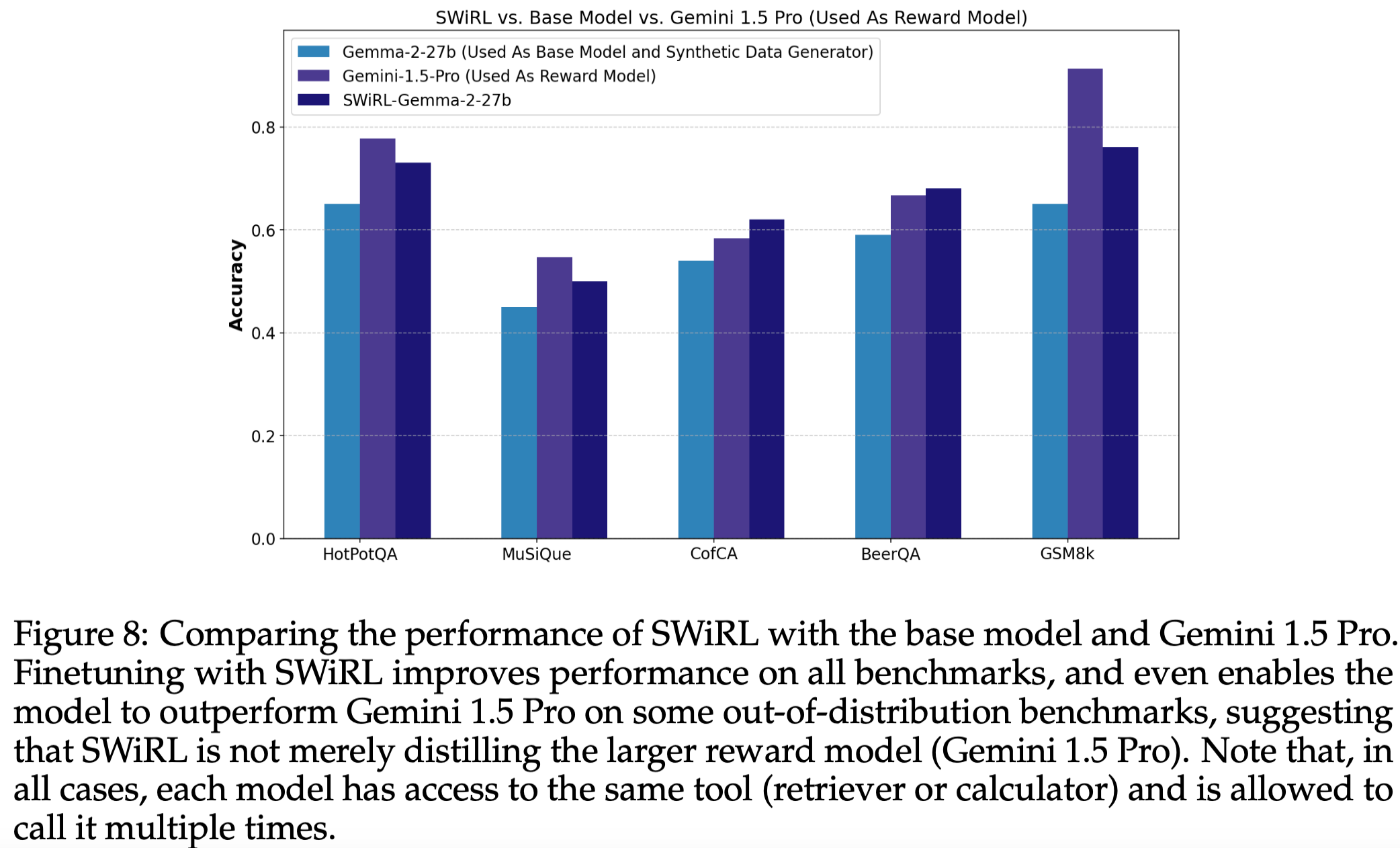
- 总结1:SWiRL 显著优于所有基线模型,甚至在某些域外基准(如 CofCA 和 BeerQA)上超越了 Gemini 1.5 Pro。
- 总结2: SWiRL 不仅仅是简单地蒸馏了一个更强的奖励模型。
11 Table 3: SWiRL 对过程正确性平均值的影响

- 过程正确性提升:经过 SWiRL 优化后,模型在域内(HotPotQA)和域外(GSM8K)任务上,每个步骤的平均正确性均有所提高。
- 下游性能源于推理提升:这表明最终更高的准确性归因于改进的多步推理。
三、总结
总结1: SwiRL + Tool use > Base Model + Tool use >> Base Model。 引入工具后还是效果提升非常大,说明Base Model已经具备不错的Tool调用的能力了。SwiRL可以改进Tool 调用的能力。
总结2: 不需要其他标注资源,利用现有的Model就可以合成数据进行RL训练提升Model的Tool Use能力。 通过“过程筛选”策略,从包含合理推理轨迹(即使最终答案不正确)的数据中学习,避免了对昂贵人工标注和GroundTruth的依赖,极大地提高了数据获取的效率和成本效益。
总结3: SwiRL训练后泛化能力也不错。 说明Tool Use的能力是可以迁移的。例如在 HotPotQA 训练能将 GSM8K 性能提高 16.9%。
关注公众号NLP PaperWeekly,获取更多学习资料
更多推荐



 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)