
Unsloth框架+LoRA微调Qwen最新模型Qwen3-B-unsloth-bnb-4bit
推荐使用注册能免费赠送三十几个小时的A10,选择GPU环境,启动,即可打开。
·
一、云服务器准备:
推荐使用https://www.modelscope.cn/my/mynotebook
注册能免费赠送三十几个小时的A10,选择GPU环境,启动,即可打开
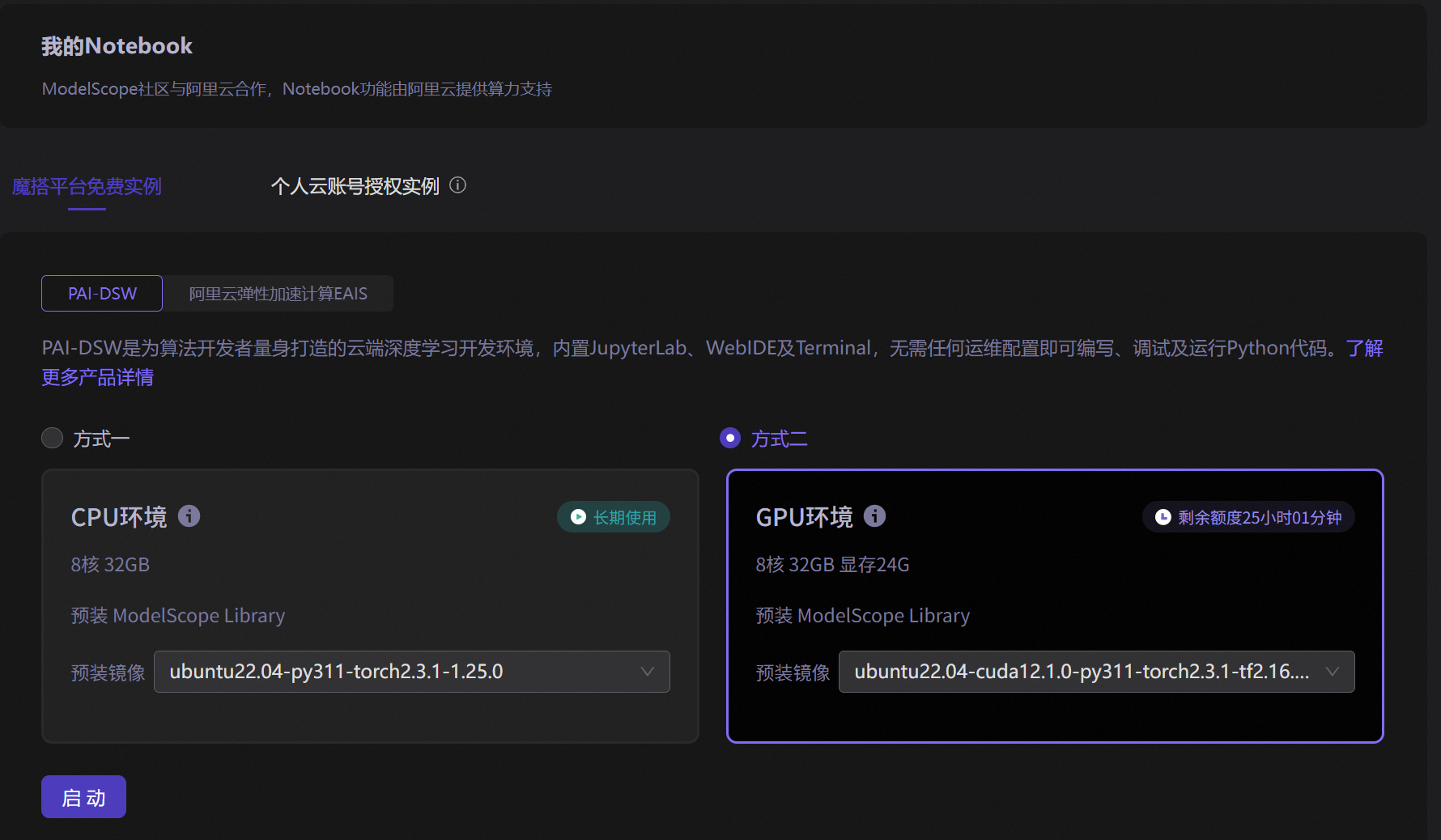
二、创建虚拟环境
进入后,可以先创建一个自己的虚拟环境
python3 -m venv venv激活环境
source venv/bin/activate三、相关库安装
安装torch:
pip install torch==2.4.1(基于python=3.1,cuda=12.1)配置unsloth框架
参考官网链接:https://github.com/unslothai/unsloth?tab=readme-ov-file
根据电脑配置进行选择

我直接用这个命令也是可以的:
pip install unsloth安装需要等待一会。注意,这个命令只能在linux中安装,最好是配置镜像源。如果是在魔塔社区上的服务器运行的话,网速会很快,五分钟左右可以装好。
装完之后,依次测试一下如下命令,确保所有依赖都安装了:
python -m torch.utils.collect_env
python -m xformers.info
python -m bitsandbytes安装好后,可以尝试:
import torch
import unsloth如果没用报错的话,说明安装成功!
modelscope安装:
pip install modelscope四、大模型下载
这里选用Qwen最新推出模型。通过莫塔社区下载模型文件,这里选用8b模型:
Qwen3-8B-unsloth-bnb-4bit · 模型库 --- Qwen3-8B-unsloth-bnb-4bit · 模型库
直接运行以下代码:
modelscope download --model unsloth/Qwen3-8B-unsloth-bnb-4bit在服务器上下载速度很快,也是五分钟左右。如果在自己电脑上的话,可能速度会较慢。
下载完成可以对比一下 和官网上的是否一致
五、数据集准备
我这里直接用了网上一个现成的数据集,大家下载下来后上传到服务器里就可以用了。数据集的制作方法后面会专题学习。
https://pan.baidu.com/s/162eeWiRclh5eZo6SEA44Vg?pwd=qtbn
六、微调
万事俱备,终于可以开始微调了!代码具体细节直接看注释。
Python
# 导入必要的库
from unsloth import FastLanguageModel # Unsloth提供的高效语言模型接口
import torch # PyTorch深度学习框架
# 设置模型参数
max_seq_length = 4096 # 模型支持的最大序列长度
dtype = None # 数据类型,None表示自动选择
load_in_4bit = True # 使用4位量化加载模型以节省显存
# 从预训练模型加载模型和分词器
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="/mnt/workspace/unsloth_env/Qwen/Qwen3-8B-unsloth-bnb-4bit", # 模型路径
max_seq_length=max_seq_length, # 最大序列长度
dtype=dtype, # 数据类型
load_in_4bit=load_in_4bit, # 4位量化加载
device_map="auto", # 自动分配设备(GPU/CPU)
)
# 打印模型和分词器信息
print(model)
print(tokenizer)
"""
#尝试对话
messages = [
{"role" : "user", "content" : "你好,好久不见!"}
]
text = tokenizer.apply_chat_template(
messages,
tokenize = False,
add_generation_prompt = True,
enable_thinking = False, # 设置不思考
)
print(text)
inputs = tokenizer(text, return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=max_seq_length,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response)
text = tokenizer.apply_chat_template(
messages,
tokenize = False,
add_generation_prompt = True,
enable_thinking = True, # 设置思考
)
inputs = tokenizer(text, return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=max_seq_length,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
"""
# 获取并打印GPU内存信息
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")
# 加载训练数据集
from datasets import load_from_disk
# 从磁盘加载预处理的训练数据
combined_dataset = load_from_disk("/mnt/workspace/unsloth_env/Qwen/cleaned_qwen3_dataset")
# 注入LoRA适配器(轻量级微调方法)
model = FastLanguageModel.get_peft_model(
model,
r=32, # LoRA的秩(rank),决定适配器复杂度
# 指定要微调的注意力层和前馈层
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_alpha=32, # LoRA的缩放系数(建议设置为r或2r)
lora_dropout=0, # 防止过拟合的dropout比率
bias="none", # 偏置项处理方式(none表示不训练偏置)
# 使用Unsloth优化的梯度检查点技术,可节省30%显存
use_gradient_checkpointing="unsloth",
random_state=3407, # 随机种子保证可复现性
use_rslora=False, # 是否使用稳定秩的LoRA变体
loftq_config=None, # LoftQ量化配置(未使用)
)
# 配置微调参数
from trl import SFTTrainer, SFTConfig
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=combined_dataset, # 训练数据集
eval_dataset=None, # 验证数据集(未设置)
args=SFTConfig(
dataset_text_field="text", # 数据集中的文本字段
per_device_train_batch_size=2, # 每个设备的批次大小
gradient_accumulation_steps=4, # 梯度累积步数(等效增大批次)
warmup_steps=5, # 学习率预热步数
max_steps=30, # 最大训练步数(替代epochs)
learning_rate=2e-4, # 初始学习率
logging_steps=1, # 每步记录日志
optim="adamw_8bit", # 8位优化器节省显存
weight_decay=0.01, # 权重衰减防止过拟合
lr_scheduler_type="linear", # 线性学习率调度
seed=3407, # 随机种子
report_to=None, # 不报告给任何平台
),
)
# 打印训练前的显存使用情况
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.")
# 开始模型微调
trainer_stats = trainer.train()
# 计算并打印显存使用情况
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory / max_memory * 100, 3)
lora_percentage = round(used_memory_for_lora / max_memory * 100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")
# 效果测试
messages = [
{"role" : "user", "content" : "Solve (x + 2)^2 = 0."}
]
text = tokenizer.apply_chat_template(
messages,
tokenize = False,
add_generation_prompt = True,
enable_thinking = False,
)
# 保存微调后的模型(合并为16位浮点数格式)
model.save_pretrained_merged(
save_directory="Qwen3-8B-finetuned-fp16", # 保存路径
tokenizer=tokenizer, # 同时保存分词器
save_method="merged_16bit", # 合并为16位格式便于后续使用
)效果图: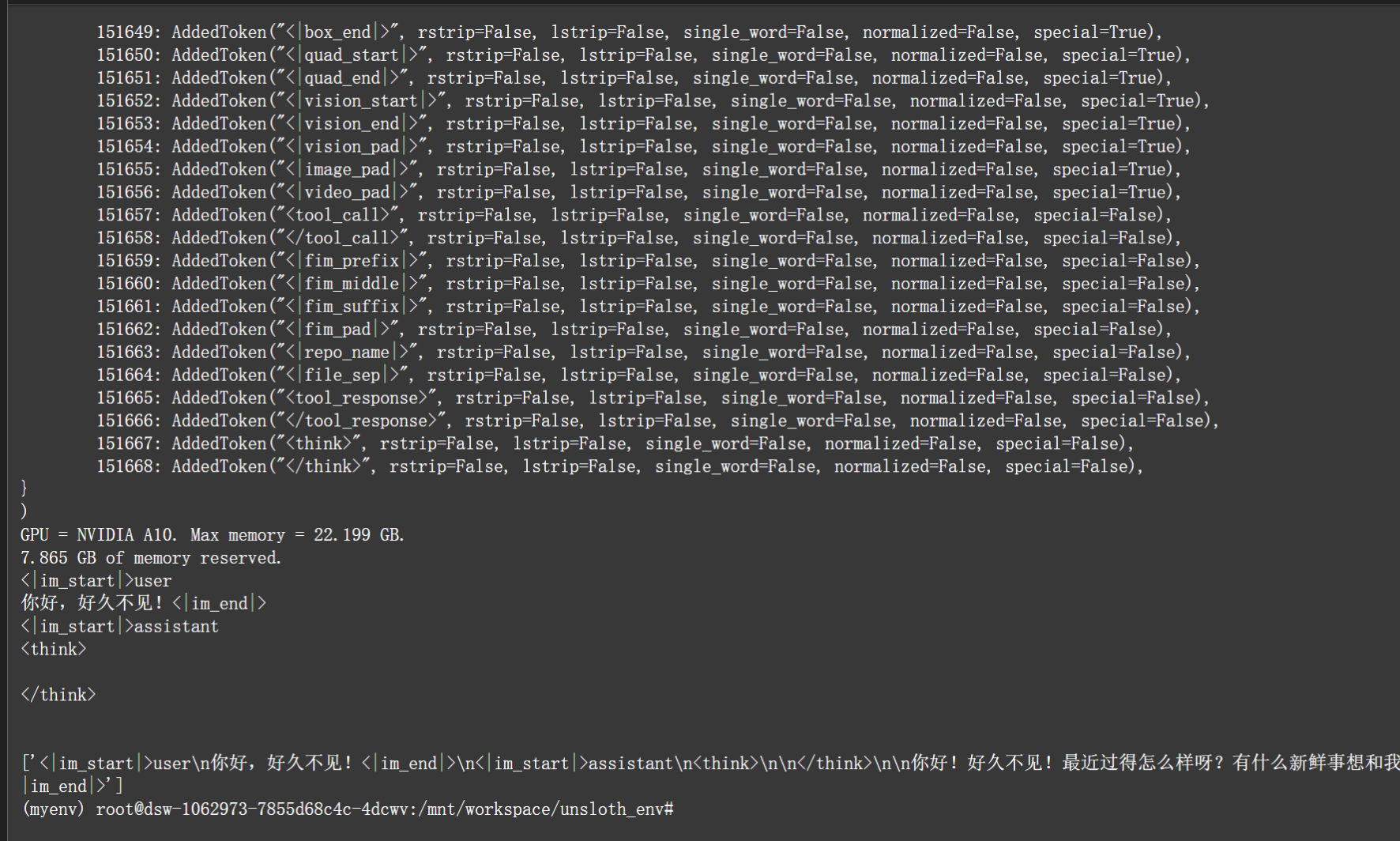
151652: AddedToken("<|vision_start|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151653: AddedToken("<|vision_end|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151654: AddedToken("<|vision_pad|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151655: AddedToken("<|image_pad|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151656: AddedToken("<|video_pad|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
151657: AddedToken("<tool_call>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151658: AddedToken("</tool_call>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151659: AddedToken("<|fim_prefix|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151660: AddedToken("<|fim_middle|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151661: AddedToken("<|fim_suffix|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151662: AddedToken("<|fim_pad|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151663: AddedToken("<|repo_name|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151664: AddedToken("<|file_sep|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151665: AddedToken("<tool_response>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151666: AddedToken("</tool_response>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151667: AddedToken("<think>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
151668: AddedToken("</think>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=False),
}
)
GPU = NVIDIA A10. Max memory = 22.199 GB.
7.865 GB of memory reserved.
Unsloth 2025.4.8 patched 36 layers with 36 QKV layers, 36 O layers and 36 MLP layers.
Detected kernel version 4.19.91, which is below the recommended minimum of 5.5.0; this can cause the process to hang. It is recommended to upgrade the kernel to the minimum version or higher.
GPU = NVIDIA A10. Max memory = 22.199 GB.
7.865 GB of memory reserved.
==((====))== Unsloth - 2x faster free finetuning | Num GPUs used = 1
\\ /| Num examples = 24,065 | Num Epochs = 1 | Total steps = 30
O^O/ \_/ \ Batch size per device = 2 | Gradient accumulation steps = 4
\ / Data Parallel GPUs = 1 | Total batch size (2 x 4 x 1) = 8
"-____-" Trainable parameters = 87,293,952/8,000,000,000 (1.09% trained)
0%| | 0/30 [00:00<?, ?it/s]Unsloth: Will smartly offload gradients to save VRAM!
{'loss': 0.5243, 'grad_norm': 0.1709010750055313, 'learning_rate': 0.0, 'epoch': 0.0}
{'loss': 0.6313, 'grad_norm': 0.18070438504219055, 'learning_rate': 4e-05, 'epoch': 0.0}
{'loss': 0.6917, 'grad_norm': 0.2633160948753357, 'learning_rate': 8e-05, 'epoch': 0.0}
{'loss': 0.6277, 'grad_norm': 0.22932463884353638, 'learning_rate': 0.00012, 'epoch': 0.0}
{'loss': 0.5566, 'grad_norm': 0.22025035321712494, 'learning_rate': 0.00016, 'epoch': 0.0}
{'loss': 0.5038, 'grad_norm': 0.2894326150417328, 'learning_rate': 0.0002, 'epoch': 0.0}
{'loss': 0.497, 'grad_norm': 0.16209828853607178, 'learning_rate': 0.000192, 'epoch': 0.0}
{'loss': 0.4613, 'grad_norm': 0.11242818832397461, 'learning_rate': 0.00018400000000000003, 'epoch': 0.0}
{'loss': 0.4056, 'grad_norm': 0.06437942385673523, 'learning_rate': 0.00017600000000000002, 'epoch': 0.0}
{'loss': 0.5185, 'grad_norm': 0.10055717825889587, 'learning_rate': 0.000168, 'epoch': 0.0}
{'loss': 0.4111, 'grad_norm': 0.1213046982884407, 'learning_rate': 0.00016, 'epoch': 0.0}
{'loss': 0.4616, 'grad_norm': 0.1085151880979538, 'learning_rate': 0.000152, 'epoch': 0.0}
{'loss': 0.5397, 'grad_norm': 0.11820624023675919, 'learning_rate': 0.000144, 'epoch': 0.0}
{'loss': 0.435, 'grad_norm': 0.10208404809236526, 'learning_rate': 0.00013600000000000003, 'epoch': 0.0}
{'loss': 0.4151, 'grad_norm': 0.08620519191026688, 'learning_rate': 0.00012800000000000002, 'epoch': 0.0}
{'loss': 0.4628, 'grad_norm': 0.09688656032085419, 'learning_rate': 0.00012, 'epoch': 0.01}
{'loss': 0.3921, 'grad_norm': 0.06548664718866348, 'learning_rate': 0.00011200000000000001, 'epoch': 0.01}
{'loss': 0.4749, 'grad_norm': 0.06672561913728714, 'learning_rate': 0.00010400000000000001, 'epoch': 0.01}
{'loss': 0.3859, 'grad_norm': 0.061673250049352646, 'learning_rate': 9.6e-05, 'epoch': 0.01}
{'loss': 0.4225, 'grad_norm': 0.054180387407541275, 'learning_rate': 8.800000000000001e-05, 'epoch': 0.01}
{'loss': 0.4114, 'grad_norm': 0.051119450479745865, 'learning_rate': 8e-05, 'epoch': 0.01}
{'loss': 0.472, 'grad_norm': 0.05558755621314049, 'learning_rate': 7.2e-05, 'epoch': 0.01}
{'loss': 0.4502, 'grad_norm': 0.053756918758153915, 'learning_rate': 6.400000000000001e-05, 'epoch': 0.01}
{'loss': 0.4471, 'grad_norm': 0.050144098699092865, 'learning_rate': 5.6000000000000006e-05, 'epoch': 0.01}
{'loss': 0.413, 'grad_norm': 0.05417421832680702, 'learning_rate': 4.8e-05, 'epoch': 0.01}
{'loss': 0.4903, 'grad_norm': 0.04735643416643143, 'learning_rate': 4e-05, 'epoch': 0.01}
{'loss': 0.3312, 'grad_norm': 0.05248301103711128, 'learning_rate': 3.2000000000000005e-05, 'epoch': 0.01}
{'loss': 0.4171, 'grad_norm': 0.05325600132346153, 'learning_rate': 2.4e-05, 'epoch': 0.01}
{'loss': 0.3431, 'grad_norm': 0.047759443521499634, 'learning_rate': 1.6000000000000003e-05, 'epoch': 0.01}
{'loss': 0.4022, 'grad_norm': 0.052073266357183456, 'learning_rate': 8.000000000000001e-06, 'epoch': 0.01}
{'train_runtime': 831.7713, 'train_samples_per_second': 0.289, 'train_steps_per_second': 0.036, 'train_loss': 0.4665292869011561, 'epoch': 0.01}
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [13:51<00:00, 27.73s/it]
831.7713 seconds used for training.
13.86 minutes used for training.
Peak reserved memory = 11.084 GB.
Peak reserved memory for training = 3.219 GB.
Peak reserved memory % of max memory = 49.93 %.
Peak reserved memory for training % of max memory = 14.501 %.
PeftModelForCausalLM(
(base_model): LoraModel(
(model): Qwen3ForCausalLM(
(model): Qwen3Model(
(embed_tokens): Embedding(151936, 4096, padding_idx=151654)
(layers): ModuleList(
(0-2): 3 x Qwen3DecoderLayer(
(self_attn): Qwen3Attention(
(q_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(k_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(v_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(o_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(q_norm): Qwen3RMSNorm((128,), eps=1e-06)
(k_norm): Qwen3RMSNorm((128,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): Qwen3MLP(
(gate_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(up_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(down_proj): lora.Linear(
(base_layer): Linear(in_features=12288, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=12288, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(act_fn): SiLU()
)
(input_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
(post_attention_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
)
(3): Qwen3DecoderLayer(
(self_attn): Qwen3Attention(
(q_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(k_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(v_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(o_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(q_norm): Qwen3RMSNorm((128,), eps=1e-06)
(k_norm): Qwen3RMSNorm((128,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): Qwen3MLP(
(gate_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(up_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(down_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=12288, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=12288, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(act_fn): SiLU()
)
(input_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
(post_attention_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
)
(4): Qwen3DecoderLayer(
(self_attn): Qwen3Attention(
(q_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(k_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(v_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(o_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(q_norm): Qwen3RMSNorm((128,), eps=1e-06)
(k_norm): Qwen3RMSNorm((128,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): Qwen3MLP(
(gate_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(up_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(down_proj): lora.Linear(
(base_layer): Linear(in_features=12288, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=12288, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(act_fn): SiLU()
)
(input_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
(post_attention_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
)
(5): Qwen3DecoderLayer(
(self_attn): Qwen3Attention(
(q_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(k_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(v_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(o_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(q_norm): Qwen3RMSNorm((128,), eps=1e-06)
(k_norm): Qwen3RMSNorm((128,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): Qwen3MLP(
(gate_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(up_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(down_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=12288, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=12288, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(act_fn): SiLU()
)
(input_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
(post_attention_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
)
(6): Qwen3DecoderLayer(
(self_attn): Qwen3Attention(
(q_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(k_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(v_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(o_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(q_norm): Qwen3RMSNorm((128,), eps=1e-06)
(k_norm): Qwen3RMSNorm((128,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): Qwen3MLP(
(gate_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(up_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(down_proj): lora.Linear(
(base_layer): Linear(in_features=12288, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=12288, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(act_fn): SiLU()
)
(input_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
(post_attention_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
)
(7-33): 27 x Qwen3DecoderLayer(
(self_attn): Qwen3Attention(
(q_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(k_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(v_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(o_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(q_norm): Qwen3RMSNorm((128,), eps=1e-06)
(k_norm): Qwen3RMSNorm((128,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): Qwen3MLP(
(gate_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(up_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(down_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=12288, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=12288, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(act_fn): SiLU()
)
(input_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
(post_attention_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
)
(34): Qwen3DecoderLayer(
(self_attn): Qwen3Attention(
(q_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(k_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(v_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(o_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(q_norm): Qwen3RMSNorm((128,), eps=1e-06)
(k_norm): Qwen3RMSNorm((128,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): Qwen3MLP(
(gate_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(up_proj): lora.Linear(
(base_layer): Linear(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(down_proj): lora.Linear(
(base_layer): Linear(in_features=12288, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=12288, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(act_fn): SiLU()
)
(input_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
(post_attention_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
)
(35): Qwen3DecoderLayer(
(self_attn): Qwen3Attention(
(q_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(k_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(v_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=1024, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=1024, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(o_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(q_norm): Qwen3RMSNorm((128,), eps=1e-06)
(k_norm): Qwen3RMSNorm((128,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): Qwen3MLP(
(gate_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(up_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=4096, out_features=12288, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(down_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=12288, out_features=4096, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=12288, out_features=32, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=32, out_features=4096, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(act_fn): SiLU()
)
(input_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
(post_attention_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)
)
)
(norm): Qwen3RMSNorm((4096,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=4096, out_features=151936, bias=False)
)
)
)
To solve the equation \((x + 2)^2 = 0\), we can follow these steps:
1. Recognize that the equation \((x + 2)^2 = 0\) is a perfect square trinomial, which means the left side is a square of a binomial.
2. The square of a binomial is zero only when the binomial itself is zero. Therefore, we can set the binomial equal to zero:
\[
x + 2 = 0
\]
3. Solve for \(x\) by isolating it on one side of the equation:
\[
x = -2
\]
Thus, the solution to the equation \((x + 2)^2 = 0\) is \(\boxed{-2}\).<|im_end|>更多推荐



 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)