
【论文阅读—专家特化微调】ESFT 对Deepseek MOE框架下面的专家特化微调
MOE框架
在了解什么是ESFT专家特化微调之前我们需要了解什么是MOE框架,这是deepseek提出的一套架构,核心思想是用多个专家(expert)替代传统的全连接层(Feed-Forward Networks, FFNs)。有实验表明相同任务的数据激活的专家是集中的,不同任务的数据激活的专家差异很大,所以MOE只对任务亲和度高的专家进行调优冻结其他专家,“专人干专事”。
每个MOE层有多个专家组成,每个专家本质上是一个FFN,MOE通过路由机制讲输入token分配给最相关的专家
原来的FFN网络:output = down_proj(up_proj(x))
MOE的FFN网络:output = down_proj(act_fn(gate_proj(x)) * up_proj(x))
其实也就是对专家输出的特征进行加权求和,acf_fn是一个激活函数,gate_proj是专家权重向量,不选择该专家的话权重为0。
所以从公式上不太能看得出来,这里其实有一个比较重要的点就是参数规模的问题。可能会有一个疑问:“如果MOE层每个专家相当于一个FFN,那岂不是有多个FFN,如果说至少激活一个专家的话,最后计算的代价也应该是大于等于原始FFN啊?”。
但实际上,MOE中的专家FFN规模要比原来的FFN小,如下图所示,MOE中的专家FFN的规模其实要比原来的小很多,只是数量上很多所以在激活一定数量的专家FFN的情况下是有可能达成更小代价的目标的。
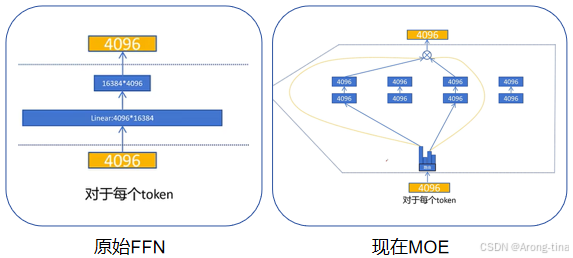
ESFT专家特化微调
- 数据采样:从训练数据中随机采样一个子集,用于专家选择。
- 专家相关性评分:提出两种评分方法,基于专家的平均门控分数(ESFT-Gate)和基于专家被选择的token比例(ESFT-Token)。
- 专家选择与微调:根据相关性评分选择每个MoE层中最相关的专家进行微调,其他专家和模块保持冻结。
ESFT方法是针对MOE框架的微调方法,所以主要结构包括两个方面:MOE替代ffn、细粒度专家选择方式。
MOE专家加权求和
这是文章里面的公式:
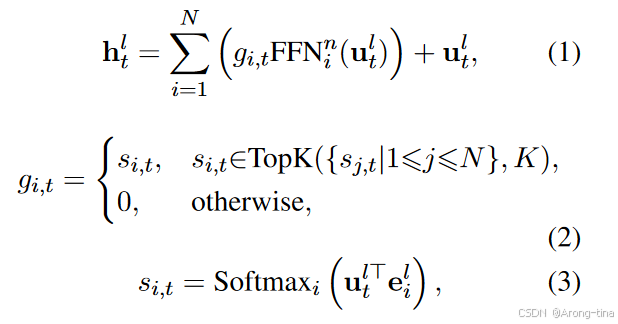
:第 l 层中第 t 个 token 的输出隐藏状态。
:第 i 个专家的 FFN。
:第 i 个专家对第 t 个 token 的门控值(gate value),表示该专家对 token 的贡献程度。
:第 l 层中第 t 个 token 的输入隐藏状态。
N:专家总数。
总的来说就是专家的特征过softmax之后进行选择,只保留选择的专家的特征权重,其余权重为0,对所有专家的特征进行加权求和。
ESFT专家特化微调
所以可以看到在MOE框架里面对于专家的选择至关重要,如果对专家的选择不当就会出现有些专家学习的任务过于复杂,而有些专家又几乎没学习到什么知识却占用了显存容量,导致专家负载不均衡。
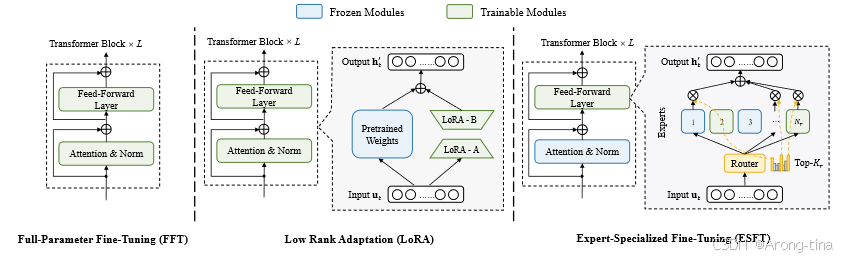
所以ESFT的特化微调模块设计了挑选专家的平均门控分数,虽然都是topk专家挑选策略,但是在什么样的标准下面达到topk对专家挑选任务来说至关重要
平均门控分数
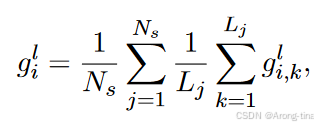
第一种很容易理解,直接看这个专家在其所有样本和token上的平均门控值,用这个数值来反应专家对于任务的亲和度。
token选择比例
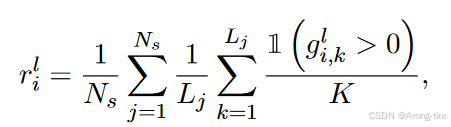
1( >0):指示函数,当专家i对token k的们控制大于0时为1,否则为0.
K:每个token被分配的专家数量
这个可以通过一个例子来理解,假设我们有一个MOE模型,其中:每层有N=4个专家,每个token被分配给K=2个专家,采样了Ns=2个样本,每个样本的长度为Lj=3(也就是每个样本有3个token)。
- 样本1:
- Token 1:被分配给专家1和专家2
- Token 2:被分配给专家2和专家3
- Token 3:被分配给专家1和专家3
- 样本2:
- Token 1:被分配给专家1和专家2
- Token 2:被分配给专家2和专家3
- Token 3:被分配给专家1和专家3
对于每个专家,我们计算其token被选择的比例,针对专家1总共在两个样本,每个样本3个token中被选择了4次,得到token选择比例:,同理专家2和专家3的token选择比例也是2/3,专家4的选择比例是0。
在这个例子中,专家1、2、3在任务中被token选择的频率相同,专家4则明显低于其余专家,专家的token选择比例呈现出明显差异,通过这些差异来反映专家在人物中的重要性,从而进行topk的选择。
重要实验
最后这一部分,说明论文中的重要实验,主要从两个角度对本文提出的方法进行评估:(1)在效果已经很好的模型上面提升模型性能(2)将已有语言模型适应到一个不熟悉的专门任务。也就是一个通用模型上面的性能,一个是微调上面的性能。
微调效率

这一部分主要是在计算代价上面的优势比较明显,在效果比LoRA微调方法好能够和FFT comparable的同时计算消耗比FFT少很多,这一点其实很重要,说明在推理的时候即使花费少量的代价也能达到相当的模型性能。
通用性能
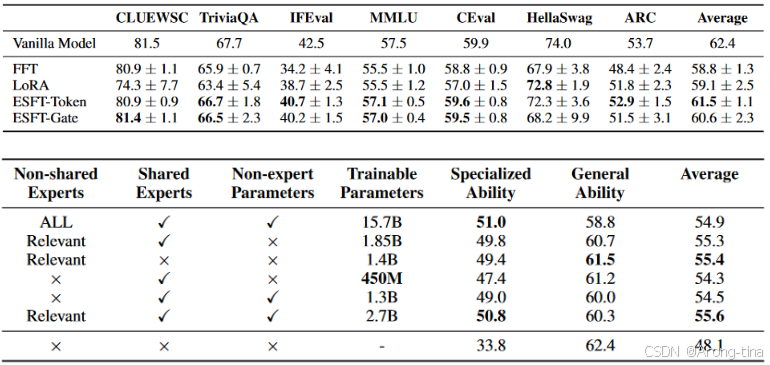
两个表格说明两件事,第一个表格说明在众多通用任务上面专家特化微调思路效果有所提升,第二个表格说明了随着模型参数的增加,模型在通用任务上面的能力会有相应的提升,但是在专家领域的能力会有所下降。并且一旦超过某个参数规模之后,继续增加参数规模将不会继续对模型产生性能增益效果。
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)