
大模型学习笔记(四) 更好的LLM:微调、提示词工程与对齐
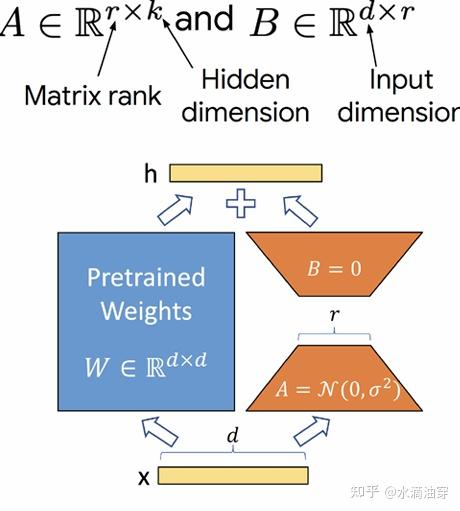
追本溯源的说,相较于finetuning,prompt-tuning是更符合人类学习知识、完成任务的习惯的,人类在完成任务的时候并不需要如此大规模的数据来支撑,我们可以通过比较简短的指示,类比、匹配不同的任务融会贯通的学习。一种可能的方法是让该矩阵遵循以下分解:Ml=BlAl其中B和A的规模如下图所示,这样的设计首先保证了M的维度仍然是d*k不变,但通过子维度r的添加,实现了对A和B的秩的限制,从
一、高效的大模型微调
1.1 微调技术(finetuning)的背景与高效微调(PEFT)
在上一篇笔记的末尾笔者简单讨论了语言模型的finetuning的背景。在此再做一个简单的回顾。语言模型的本质是根据已有的词汇预测下一个词,而使用者希望语言模型能够根据使用者给出的指令给出准确的回复,这中间天然存在一道间隙,也就是,模型只是在“补全句子”,而并非在“完成任务”。如何解决这两者之间的间隙,就需要对模型进行finetuning。
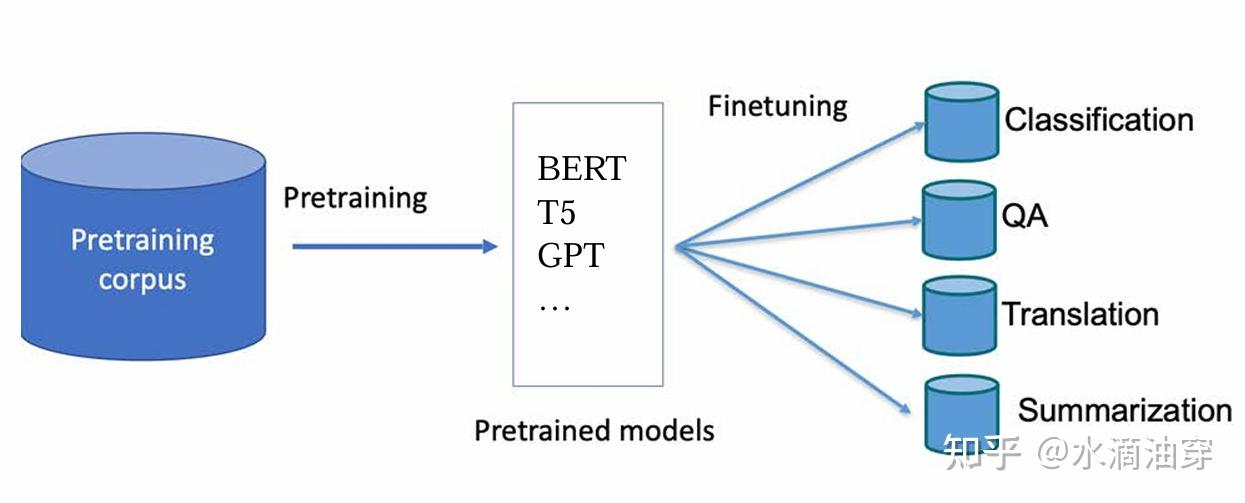
也就是说,finetuning是一种让“模型”适应“任务”的方式。所谓finetuning的本质,就是对模型的参数进行调整,其实质上是一个优化问题,也就是,根据任务的数据对模型参数执行优化,来完成模型参数的更新。
总的来说,依据参数调整的规模,可以分为whole-model finetuning和head finetuning,只对transformer的头进行微调势必会减少需要微调的参数量,但效果也可见的会较差。
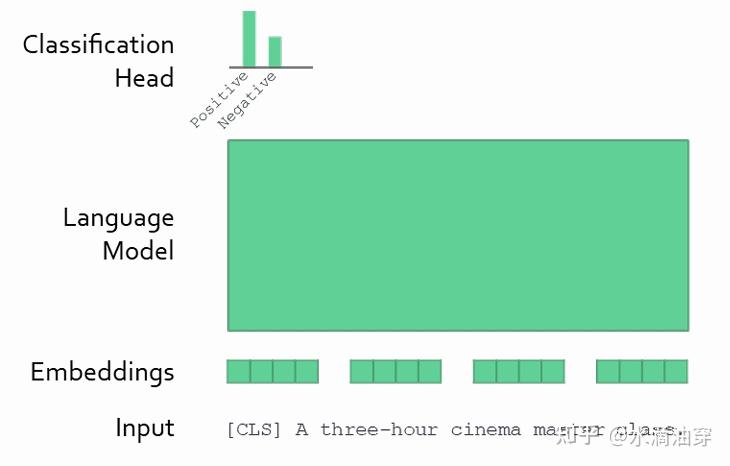
常见的微调方法是根据训练任务的要求训练一个全连接的神经网络,然后将其置于预训练好的大模型之后,通过神经网络的反向传播机制对大模型的参数进行调节。
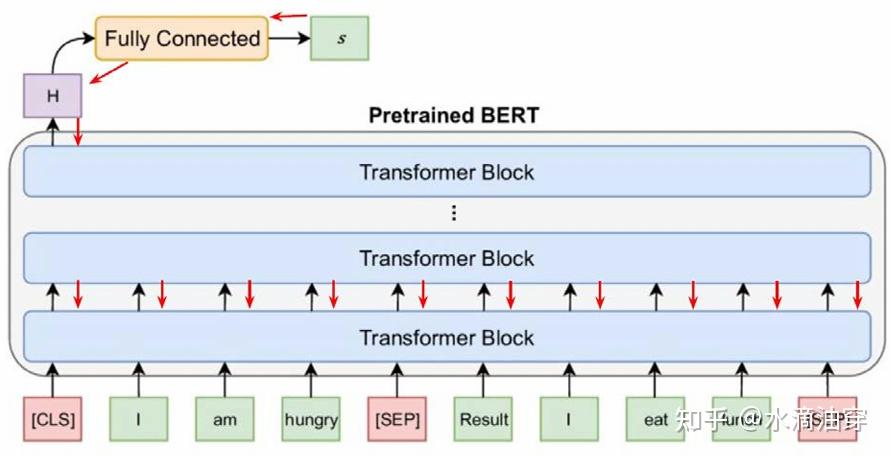
可以预见的是,每次对大模型进行微调都需要对所有的参数进行存储,而任务是复杂多变的,直接对全部参数进行微调注定会导致计算成本、训练成本的大幅度攀升。因而,普遍采用的是高效参数微调技术(PEFT),通过冻结预训练的大型模型的大多数参数,并且仅微调特定于下游任务的非常小的参数来提升微调的效率。因其在算力成本上巨大的优越性,这已经成为了一个广泛的研究方向。
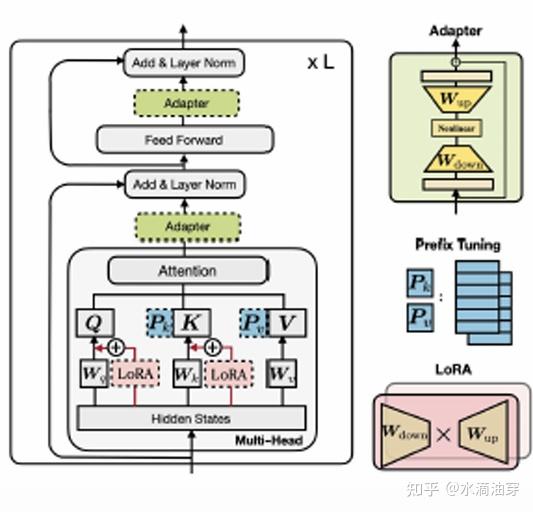
1.2 微调的三种逻辑
为了进一步细化“参数”这一个笼统的概念,我们首先考虑一个神经网络: fθ:x→y ,对这个映射关系进行分解,得到 fθ1⊙fθ2⋅⋅⋅⊙fθn ,每一个函数都有一个参数 θi (1≤i≤n) ,其中 ⊙ 是函数组合标志, θ 是集合{θ1,θ2,⋅⋅⋅,θn},假设我们有一个参数 μ ,这个参数和原来的参数有以下几种组合形式来作为修改:
fl(x)=fθl([x,μ])concatenationfl(x)=fθl⊙fμ(x)compositionf~l(x)=fθl⊕μ(x)interpolation通常,模块参数 μ 会更新,而 θl 是固定的。这三种组合形式分别用在encoder、decoder层基本结构的不同层。在input层中,通常可以对K和V进行参数更新,在input层中,通常可以对函数进行参数更新,同时,也可以对其他部分的参数进行更新。这三种参数更新分别对应上述三种组合形式。
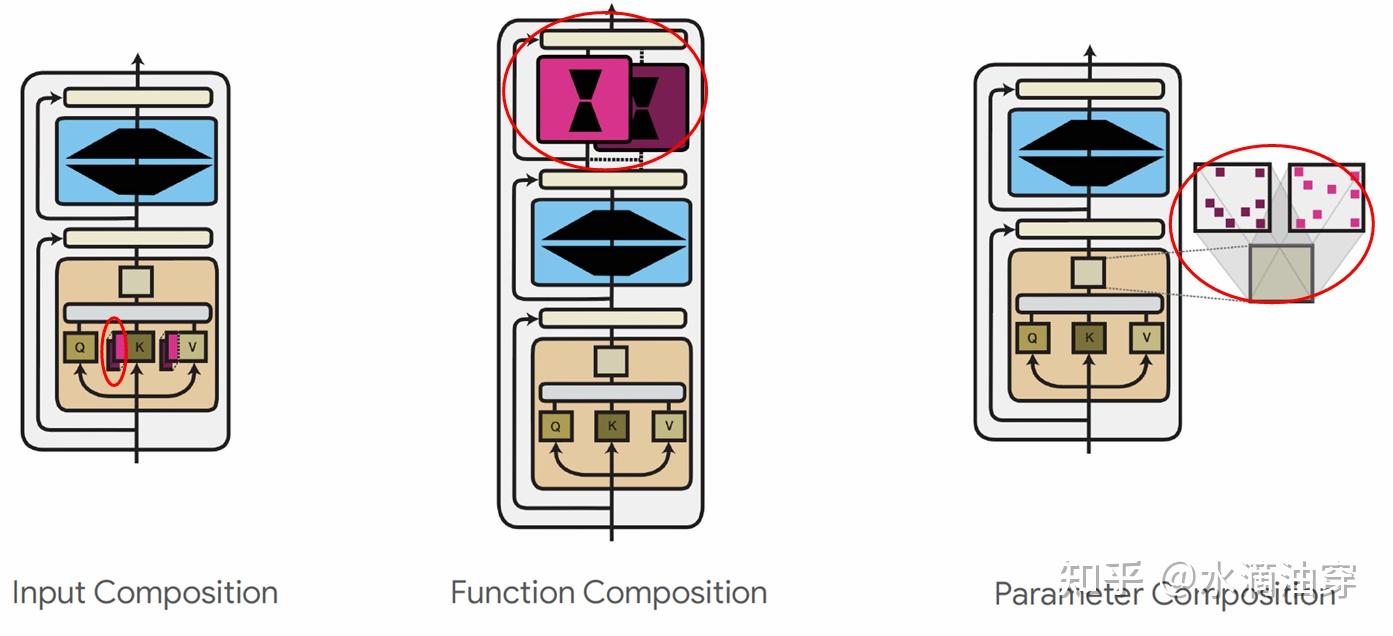
在input层,通过用一个可学习的参数向量与原有的参数向量相组合(concatenation),如下图中将prompt向量与预训练时的输入向量相组合:
在output层,通过对原有函数与可学习的特定任务所对应的特定函数相组合(composition),形成一个新的函数,这样可以使新的函数更加适应特定的任务,所以函数也常常被认为是“适配器”(adapter),对特定任务如何更好的设计合适的“适配器”函数显得特别重要,一般来说,transformer中的“适配器”函数分别包含向下的投影和向上的投影,从而能够保持前馈网络的连接,结构如下所示:
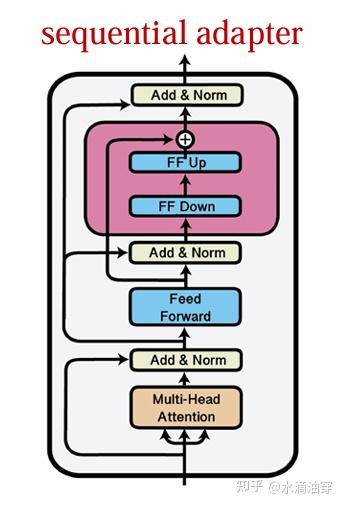
形式化地来说,假设FF Down可以表示为权重矩阵 WD∈Rk×d ,FF Up可以表示为权重矩阵 WU∈Rk×d ,一般的函数写成:fμ(x)=WDσ(WUx)除此之外,在对其它参数进行直接更新的过程中,大致有稀疏子网(Spares Subnetworks)、结构化合成(Structured Composition)和低秩合成(Low-RANK Composition)等方法。
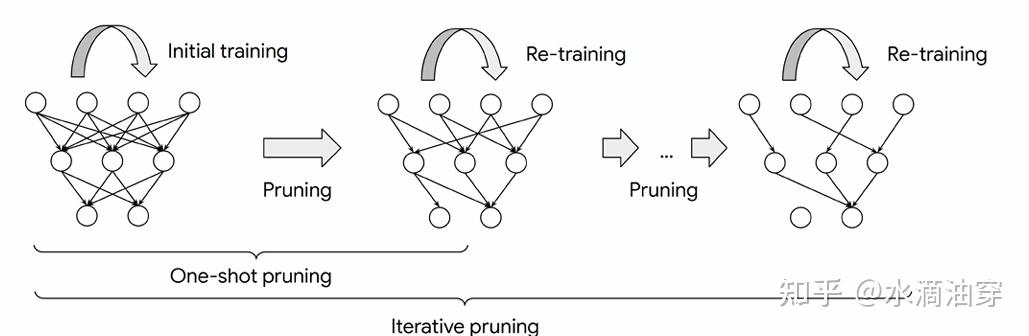
transformer中所应用的神经网络都是全连接的,这就导致其参数实际上是稀疏的,我们可以适当去除一些蕴含信息很少的连接,这种方法也就是pruning:通过一个0-1掩码矩阵M来决定层之间的连接是保留还是去除,由此产生一个子网,每个连接的权重大小是一个常见的pruning标准,如下所示:
我们也可以对网络中的每一个权重进行结构化处理,然后只更新属于预定义组G的权重:f~l(x)=fθl+μl(x),μl∈G这个预定义组G起到一个为权重赋予特征的效果,比如,可能的情况是每一个组都与一个层相对应,当我们需要调整特定层时只需要更新特定组的参数即可。
上述两种方法都是基于对参数“是否需要更新”这一事实进行筛选产生的,事实上,我们还可以从权重矩阵的秩本身出发,我们希望参数能处在尽量低维的空间之中。权重的更新形式与上面的方法类似:
f~l(x)=fθl+Ml(x)如果用以更新的权重矩阵是稠密的(rank高),它就会极大地占用运行时间和存储空间,因此,我们需要对 Ml 施以低秩限制来尽可能控制其规模。一种可能的方法是让该矩阵遵循以下分解:Ml=BlAl其中B和A的规模如下图所示,这样的设计首先保证了M的维度仍然是d*k不变,但通过子维度r的添加,实现了对A和B的秩的限制,从而控制M的秩在设计好的r之下,如下图右侧的两个梯形短边的长度r,就是通过r的设计实现的对M的秩的控制。
1.3 常见微调方法综述
在1.2节介绍的三种微调逻辑的方法,研究者设计了一系列的微调方法。
BitFit(Bias-terms finetuning)方法建立在结构合成方法的基础上,意图是只对模型的一小部分参数进行调整。这种方法只调整模型参数中的偏差和最终的线性层。具体来说,以有L层的bert为例,对于input的Q、K、V,我们保证原有的权重矩阵W不变,只通过调节细小的偏差b来实现对整体输入的更新。
Qm,l(x)=Wqm,lx+bqm,lKm,l(x)=Wkm,lx+bkm,l Vm,l(x)=Wvm,lx+bvm,l依据调整后的Q、K、V,我们可以计算得到h1l=attention(Q1,l,K1,l,V1,l,⋅⋅⋅,Qn,l,Kn,l,Vn,l)依照transformer的模型架构,在此之后就是dropout、norm和激活函数一系列操作,这里的每一个操作我们都放置一个偏差来供学习,以实现对各个层的参数更新:
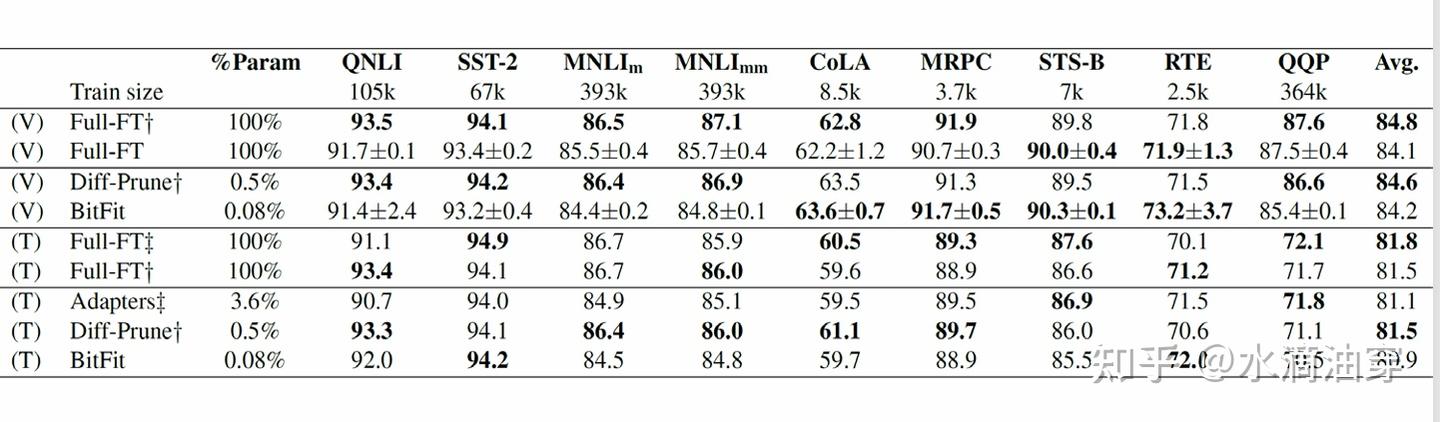
h2l=dropout(Wm1lh1l+bm1l)h3l=gLN1l⊙h2l+x−μσ+bLN1lh4l=GELU(Wm2lh3l+bm2l)h5l=dropout(Wm3lh4l+bm3l)outputl=gLN2l⊙h5l+h3l−μσ+bLN2l使用BERT-large模型和GLUE数据集进行测试,可以看到使用bitfit进行微调与全部进行微调的评分相近:
实质上,bitfit对偏差的微调所带来的改变即为下式。微调的结果与误差的维数成反比,与误差向量的调整前后的差的一阶范数成正比:
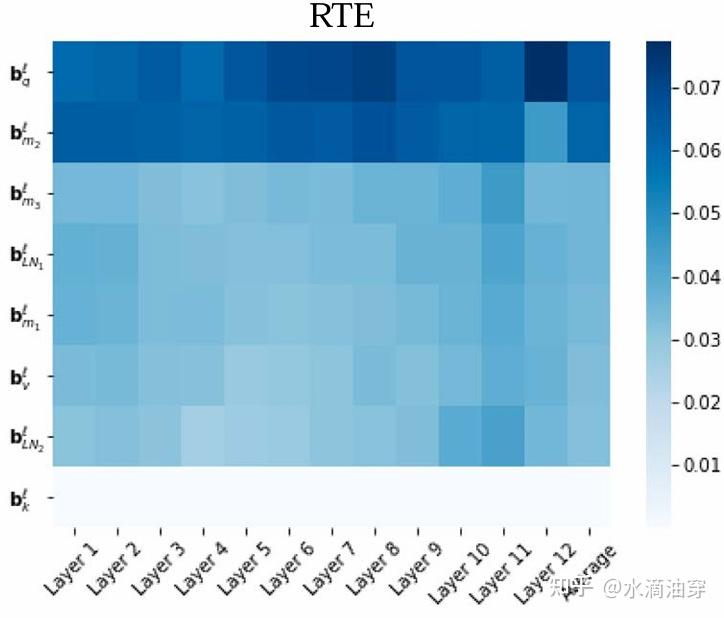
1dim(b)||b0−bF||1实验结果表明,在大多数NLP任务中,不同偏差改变的幅度是不一样的,一般来说, bq,bm2 的改变是最大的。下图是RTE任务中不同偏差改变幅度的一个例子:
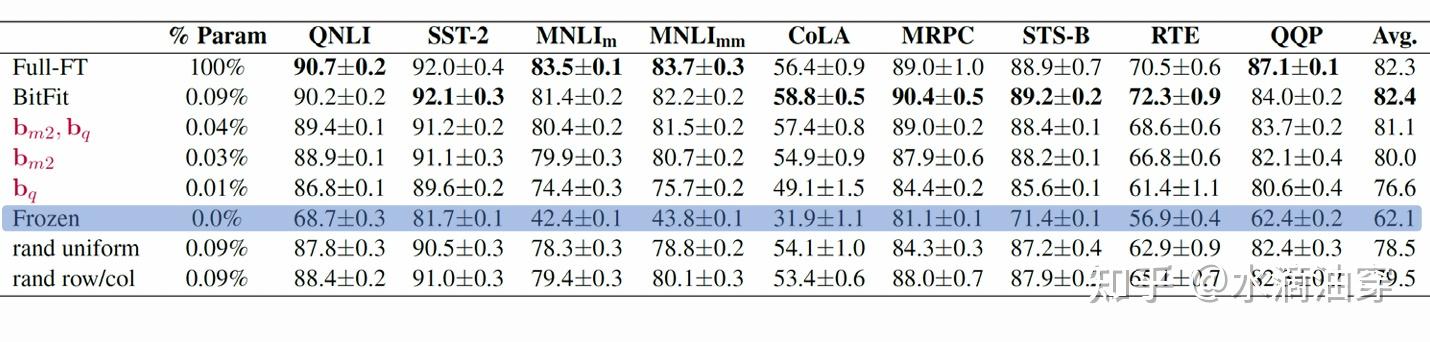
因而,只针对这些改变幅度大的参数进行微调,可能能够实现更高效的模型性能改进。下表提供了一个例证:
Bitfit方法的出发点是对普通参数微调中的structured composition方法的利用,它也同时为input composition提供了一种不同于contatention方法的新思路。除了对输入的微调,上一节介绍了设计adapter对输出进行微调的方法,adapter tuning就是建立在这一思路基础上的方法。它的核心思想就是在预训练模型的基础上在每一层后添加adapter module,这一思想的一大好处是它避免了对模型本身的改动,从而能保证每个新的下游任务进来时微调的基础模型都是最初预训练好的模型,避免了对原有参数的遗忘。
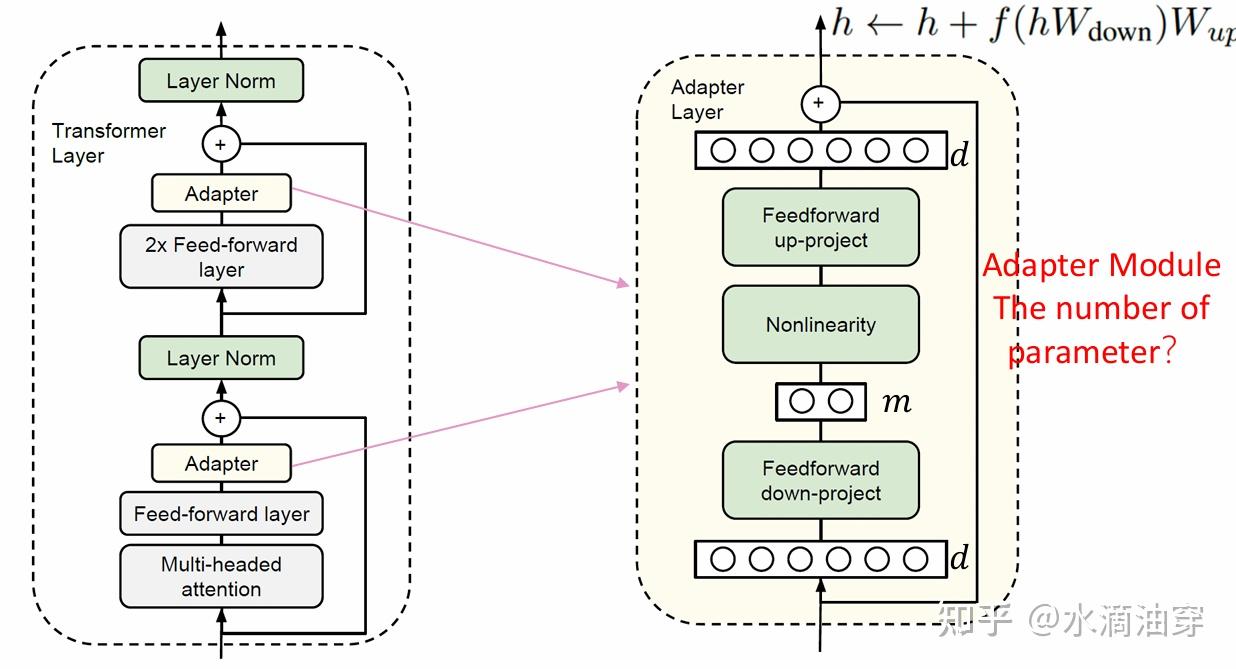
前文叙述过adapter一般所遵循的函数形式,此处的adapter层也遵照类似的形式,使得输出发生了上图右上角所示的变化。adapter层的参数数量(主要是m)是可以依据人为的想法进行调节的,选用m是8、64亦或是256都会导致模型不同的性能结果。

进一步地,adapter是在顶层之后再添加新的调节器,这与早期的对top layer进行微调的想法相似,但是实验结果表明adapter凭借较少数量的参数反而获得了较好的效果。
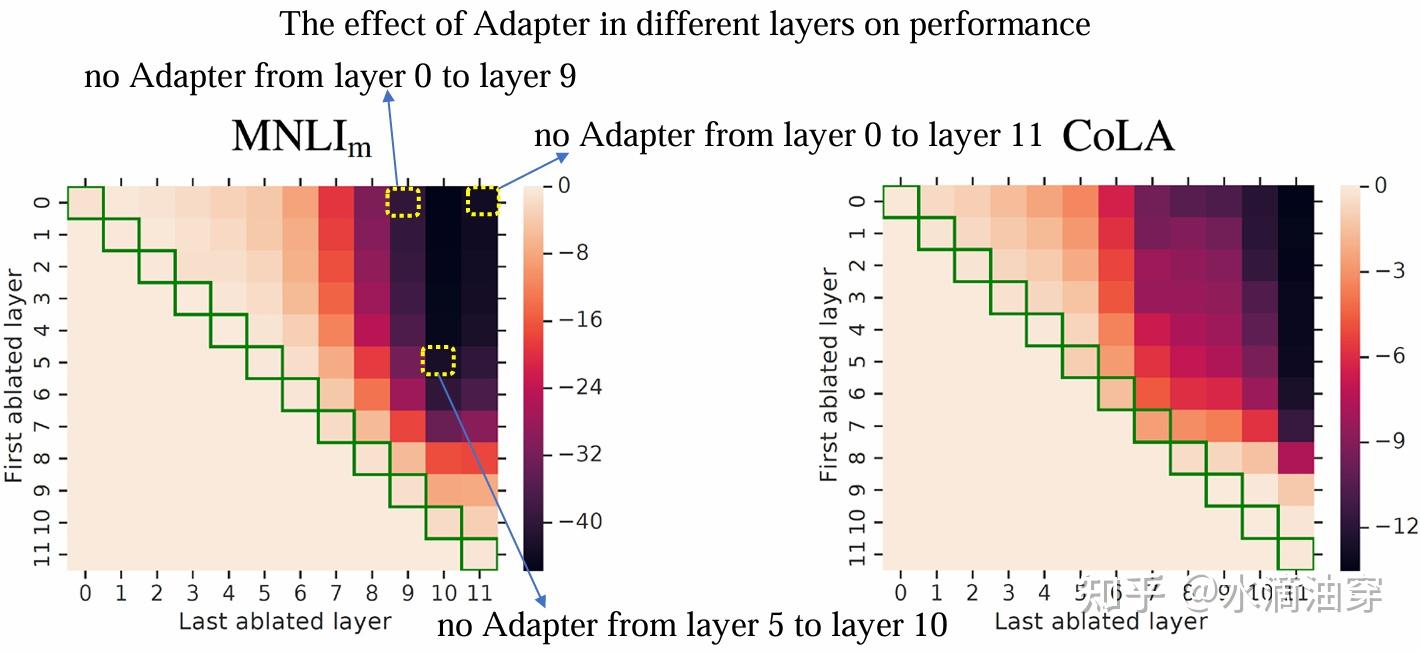
当然,进一步的研究表明对transformer不同层添加adapter之后所产生的效果可能不一定相同:
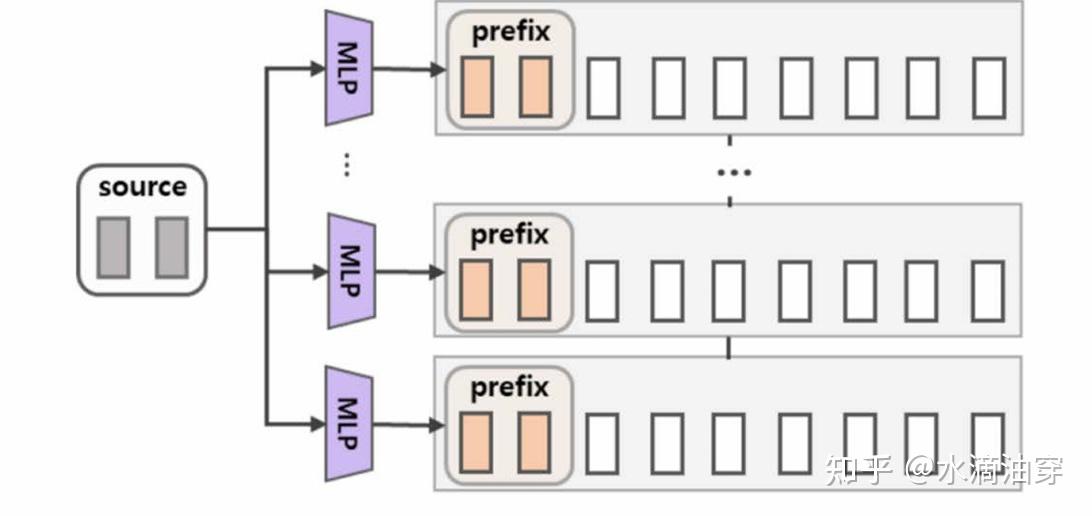
前面的方法都是从transformer的结构出发进行微调中。事实上,在前面介绍LLM时,我们提到了大语言模型的in-context learning能力,也提到了prompt对模型性能的影响。前缀微调(Prefix Tuning)就是一种通过设计前缀来实现微调的方法。Prefix Tuning将前缀作为提示词的一部分来进行微调,如下所示:
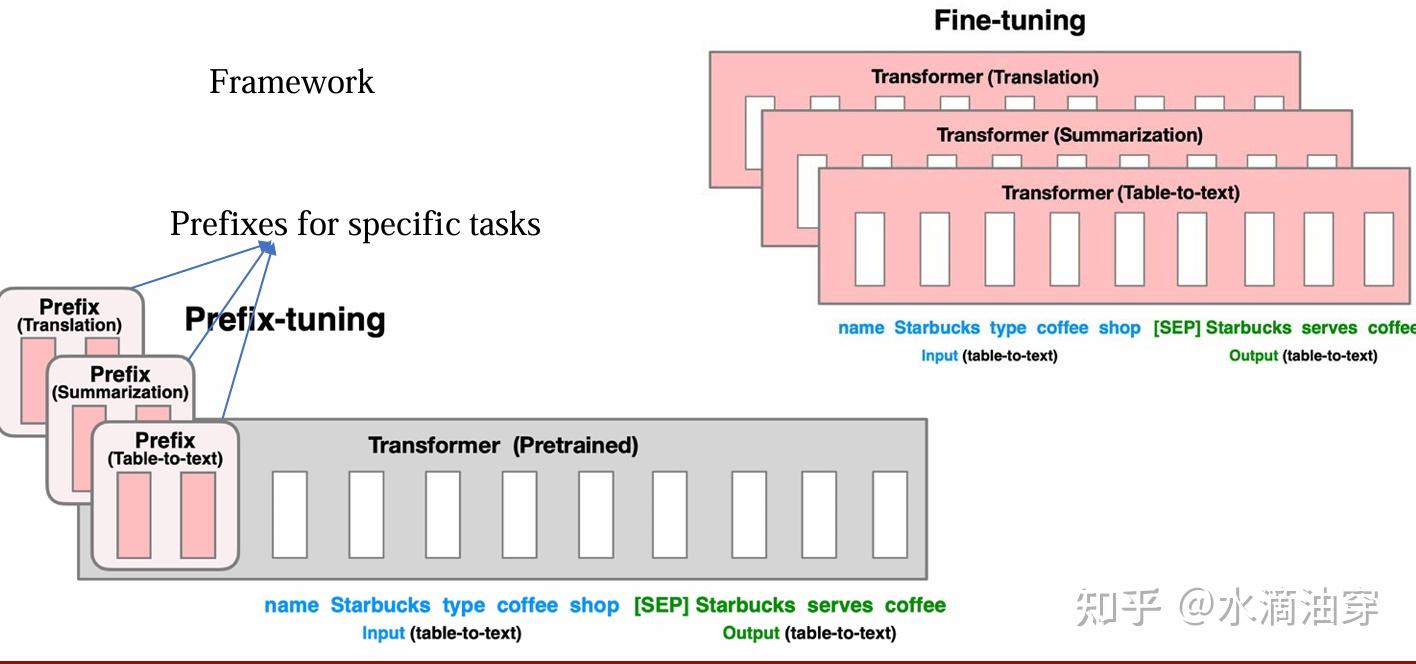
这个方法不同于T5对数据对的设计,这是一种广泛使用的微调方法,如对GPT生成式模型和基于encoder-decoder的BART模型,Prefix-tuning会采用不同的提示词微调方法:


这里的Activation的h是由下列函数决定的:
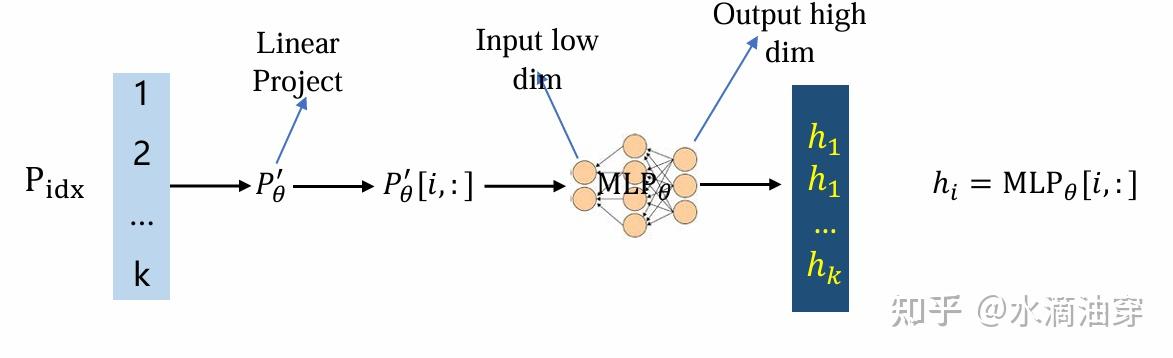
hi={Pθ[i,:], if i∈PidxLMϕ(zi,h<i), otherwise 然而,实验结果表明,在学习过程中混入前缀参数 pθ 的学习可能不利于模型的性能,一种可能的解决方案是将其调整为对MLP的学习,学习结束之后再删去这个MLP,如下所示:
研究者对prefix-tuning的一系列可能的情况都做了不同的研究,如对前缀的不同位置和不加前缀的情况进行了对比,证明了Prefix-tuning的效果:
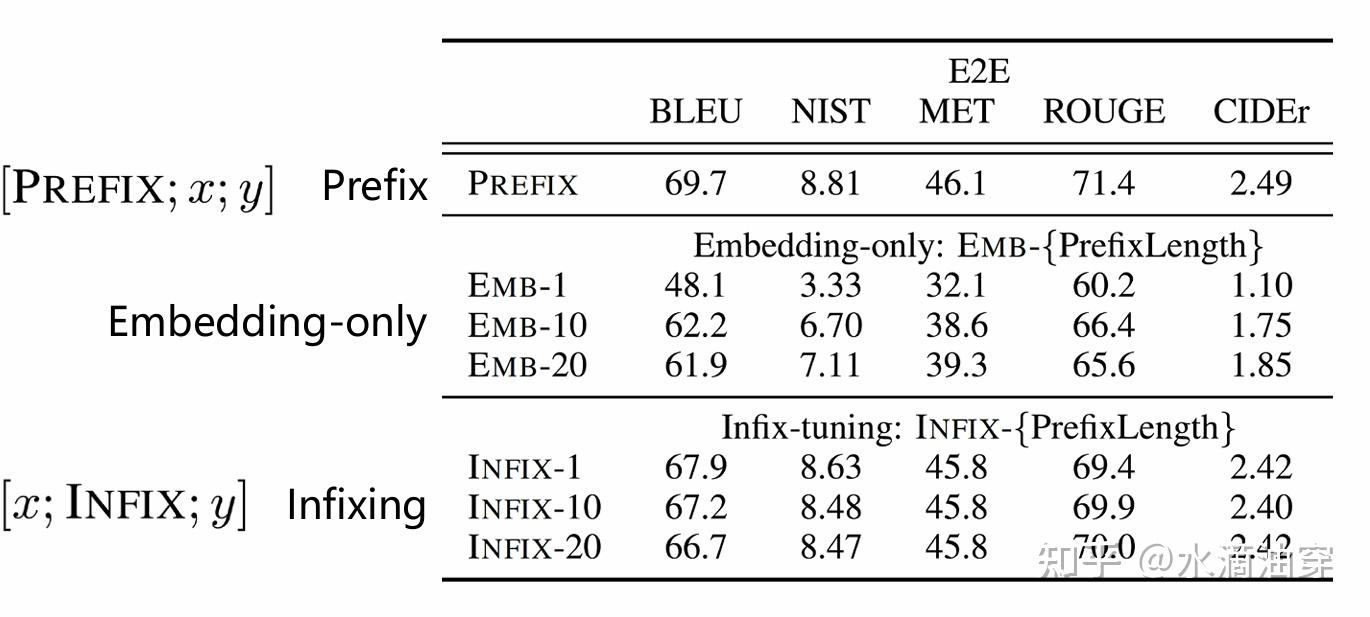
当然,perfix-tuning虽然效果可观,但由于格式的限定,导致其模型的泛用性存在一定的限制,一般来说只有明显的序列性文本数据可以用perfix-tuning。为了进一步简化对这些控制的操作,提高模型的泛用性,研究者进一步提出了prompt-tuning。简单来说,原本的perfix-tuning需要我们针对不同的 任务为输入的token前面加上不同的前缀,但出于效果的考虑,前缀和文本之间还进行了MLP的连接,而prompt-tuning则直接将这些简化为提示词。具体来说:
Xe∈Rn×e 是输入数据的嵌入矩阵,其中 n是标记的数量,e是嵌入空间的维度;
Pe∈Rp×e 是提示词的嵌入矩阵,其中 p是标记的数量,e是嵌入空间的维度;
[Xe;Pe] 即为输入的形式,当对模型进行微调的时候,冻住 θ ,只需要对 Pe 的参数进行学习即可;
我们所需要做的就是根据 maxPePr(Y|[P;x];θ,Pe) 学习满足这一要求的 Pe .
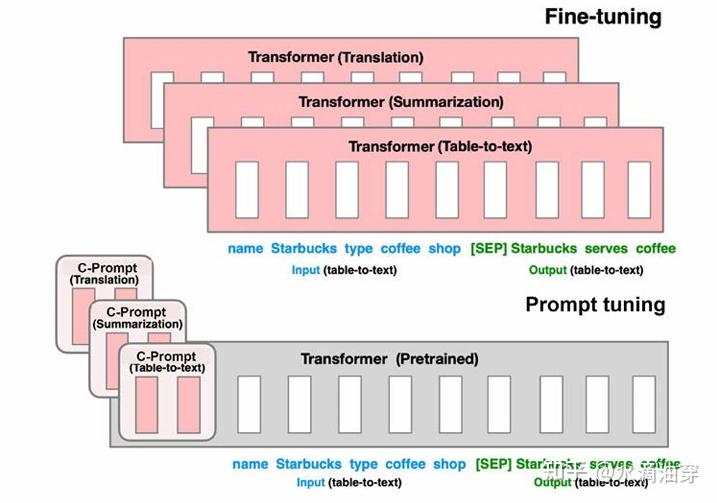
下面的图直观展示了prompt-tuning和直接进行finetuning在参数量上的区别:
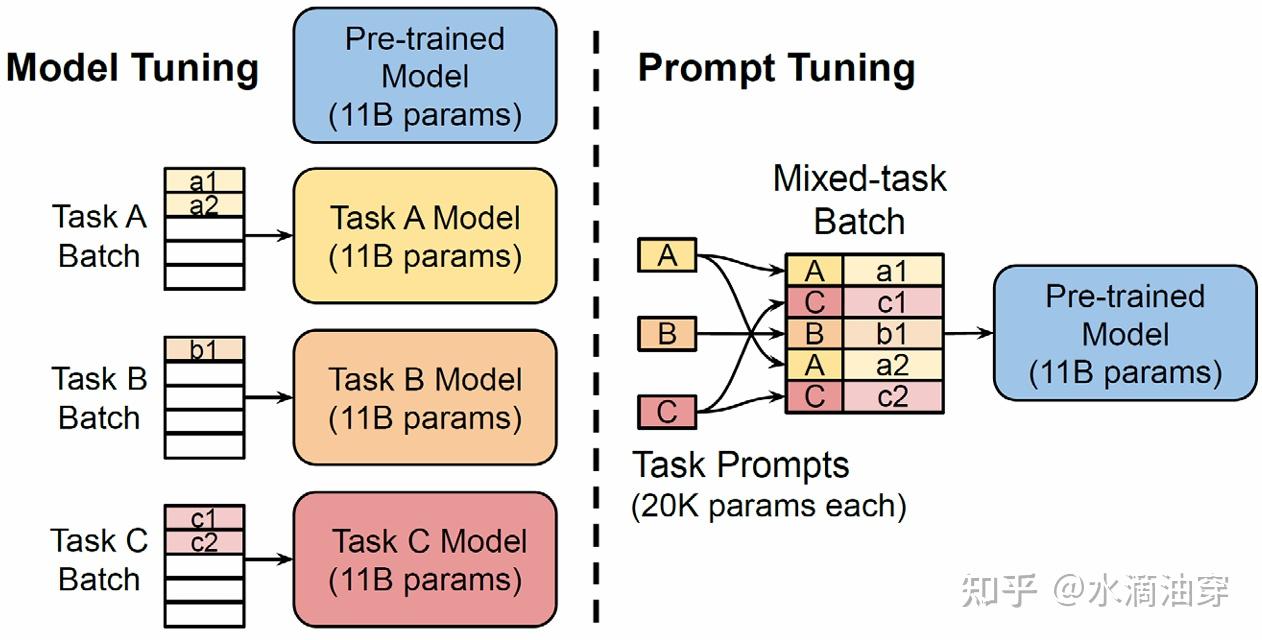
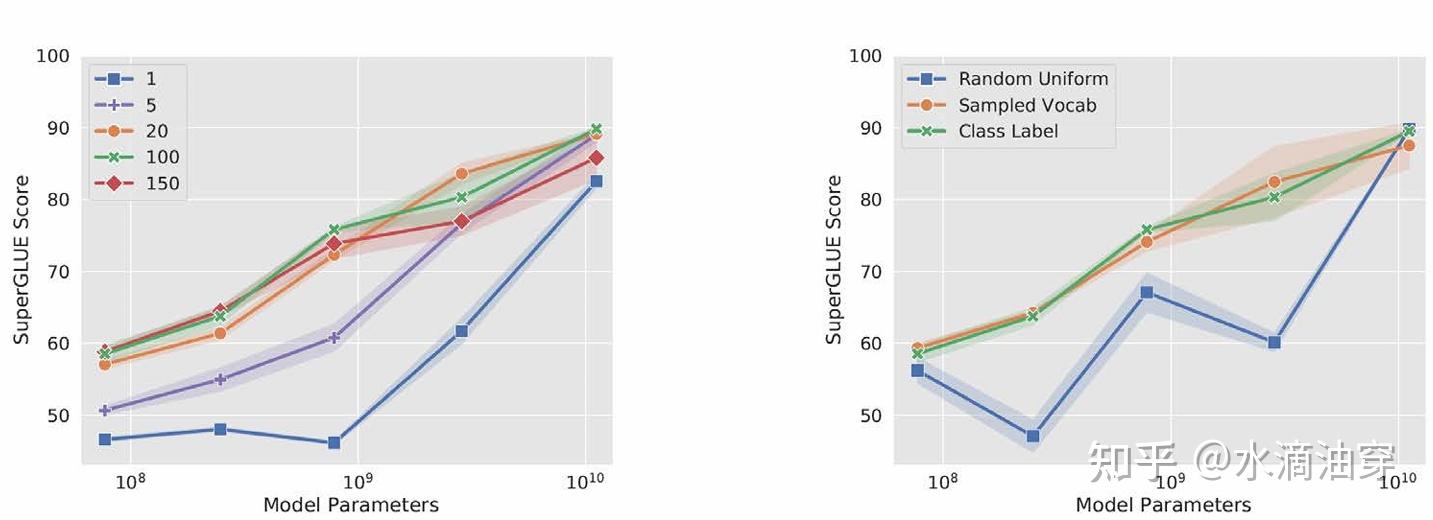
研究者使用T5和SuperGLUE数据集进行了一系列实验,证明了当参数量达到一定程度时prompt-tuning和直接微调能达到相似的效果。研究者还考虑了prompt长度和种类对微调效果的影响,结果如下两图所示:
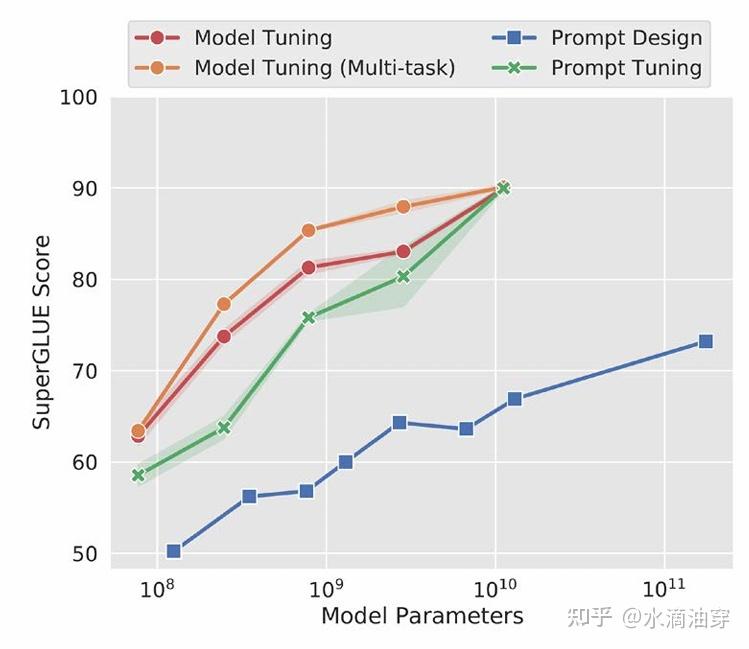
事实上,随着提示词工程的发展,它的效用已经逐渐超过了微调本身。追本溯源的说,相较于finetuning,prompt-tuning是更符合人类学习知识、完成任务的习惯的,人类在完成任务的时候并不需要如此大规模的数据来支撑,我们可以通过比较简短的指示,类比、匹配不同的任务融会贯通的学习。但这本身不是大模型设计的初衷,以情感分析为例,假设我们有一个已经经过预训练的模型,我们希望他对“I saw a three-hour tedious film”进行情感分析,模型本身倾向于续写这段文本,它可能会生成“today”“but”这种词汇,但绝不会在微调之前生成P或者N。

但不妨换个思路,我们应该如何让模型在不经过微调的情况下自己做出判断呢,一种解决方案是把输入改写成“I saw a three-hour tedious film, it was”,然后如下图定义概率,那么比较两种概率是不是自然就可以完成情感分析的任务了呢?

事实上,前面提过的prefix-tuning就是一种特殊的提示词,但前缀毕竟是一种相对死板的方式,因而prompt是直接从embedding的input视角出发的一种解决方案,相较于直接对参数进行微调,是一种更自然的思路。
我们已经指出了prompt的普遍形式: [Xe;Pe] ,在实际操作过程中,prompt有不同的具体形式。
一种方式是对原有的文本进行添加,这种方式主要包括三个步骤,首先,确认输入 x ,然后,确定一个有两部分空格的template,一个空格[X]用来放置输入,一个空格[Z]用来放置输出,然后将 x 填入[X]中形成prompt,以下是一个例子,其中"[X] Overall,it was a [Z] movie"就是针对input设计的:

对[Z]中内容的预测遵循这样的式子,这里的search函数可以是一个最大化概率的argmax,也可以根据已有的概率分布随机生成的结果。我们为了让输出符合我们的期望,可以为输出设定一个词汇表,让模型从中挑选输出。z∗=searchP(x,z∗;θmodel)

即便如此,很多时候输出不完全是我们想要的形式,我们需要对输出进行筛选,一些筛选的方式包括直接对[Z]进行检索和截取,或者依据[Z]的输出内容创建对应的映射。

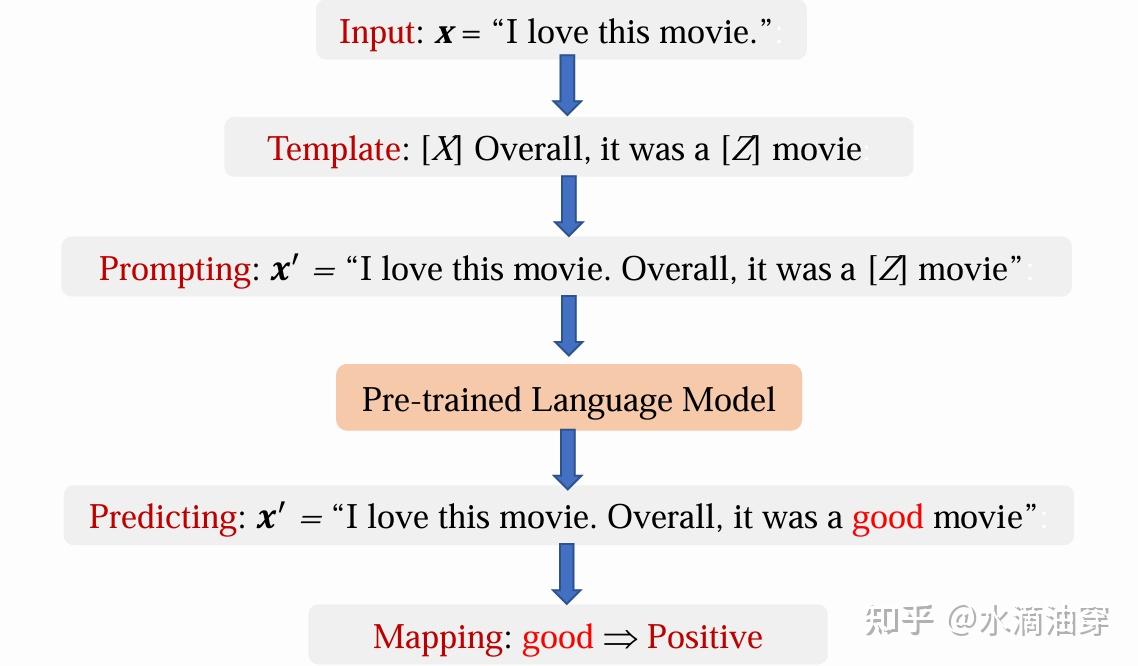
最后,一个完整的使用prompt方法进行微调的流程就如下图所示:
下面列举了一些常见的NLP任务的可能的template形式。一般来说,按照template的语序和编排不同,我们可以把prompt分为perfix prompting和cloze prompting
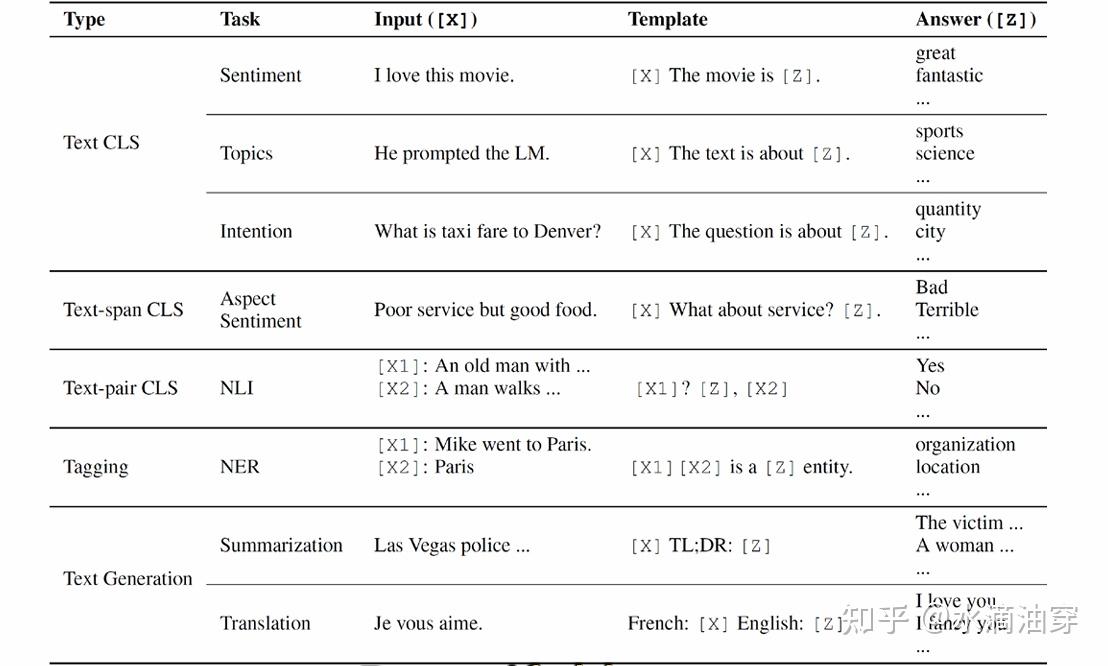
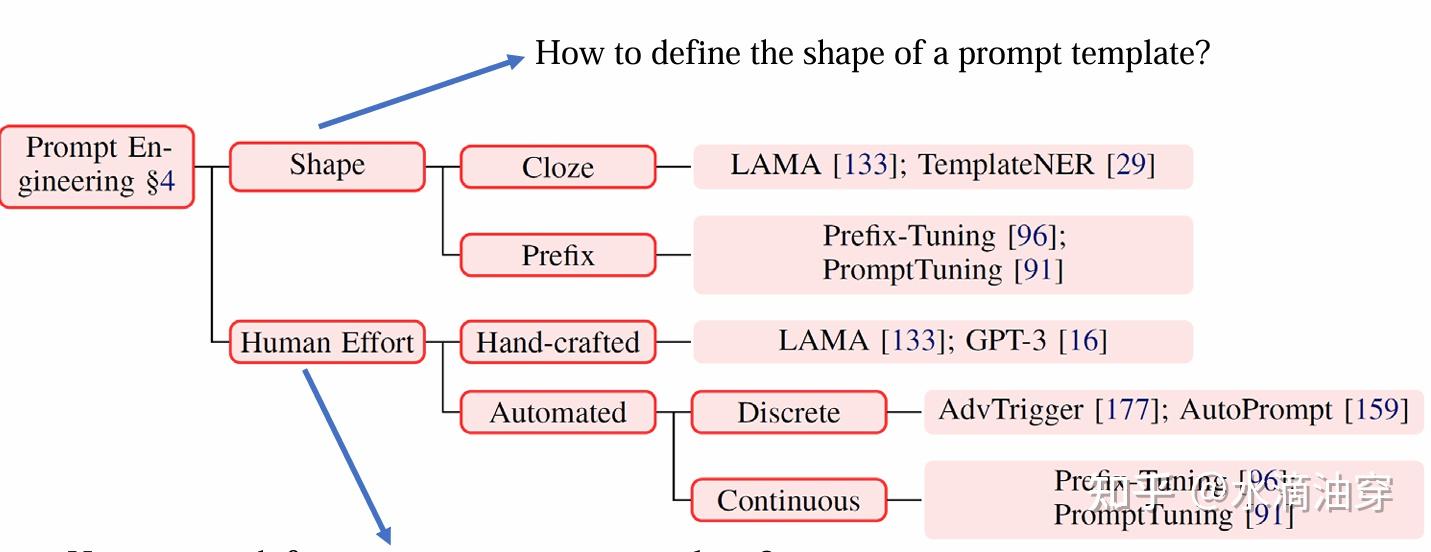
根据前文所述的prompt的产生过程,不难意识到一个prompt的产生需要先确定形状(cloze or perfix),再确定template的内容。一般来说,如果是人工设定形状和生成提示词的选择的话,针对不同的任务类型,模型的选用和提示词的编排也会有所不同,如果是从左到右按照语序生成的NLP任务,可以考虑perfix prompting,并使用GPT这种生成式模型;如果是要对一部分进行补全的NLP任务,可以考虑close prompting,并使用BERT这种填空式模型;如果是句子对的话,根据encoder-decoder是否需要分享参数,可以分别考虑T5和UniLM。当然,在确定内容的时候也可以使用一些已经预训练好,专门用来生成prompt的大模型,整体的逻辑框架如下所示:
下面介绍几种提示词工程的方法:
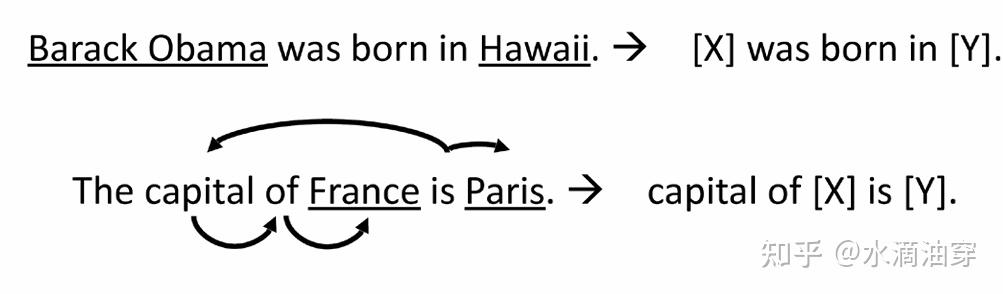
prompt mining是一种根据给定的一系列X和Y,自动从中提取template的方法。首先从一个大型语料库中提取一系列X和Y的语句对,并找到语句对之间的依赖词,一个可能的template句式就是[X]+依赖词+[Z],如下所示:
prompt paraphrasing是一种根据人工编写的seed prompt,让模型依照seed prompt的行驶,参照不同的输入转述为不同的prompt,然后再选择其中准确率最高的一种,如下所示的翻译句式的几种prompt的例子:

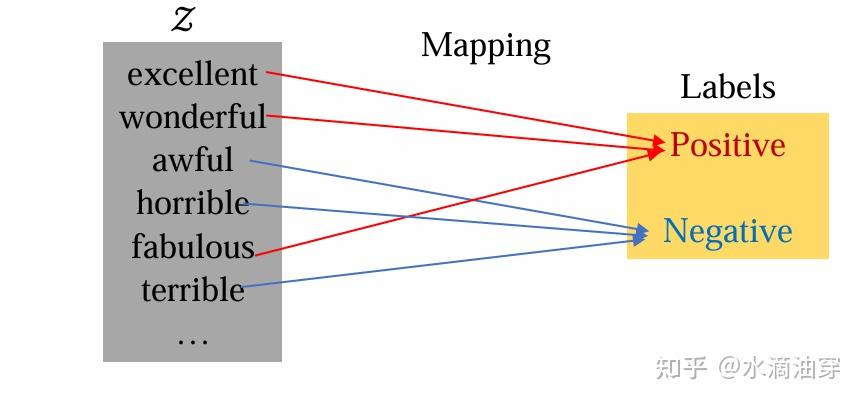
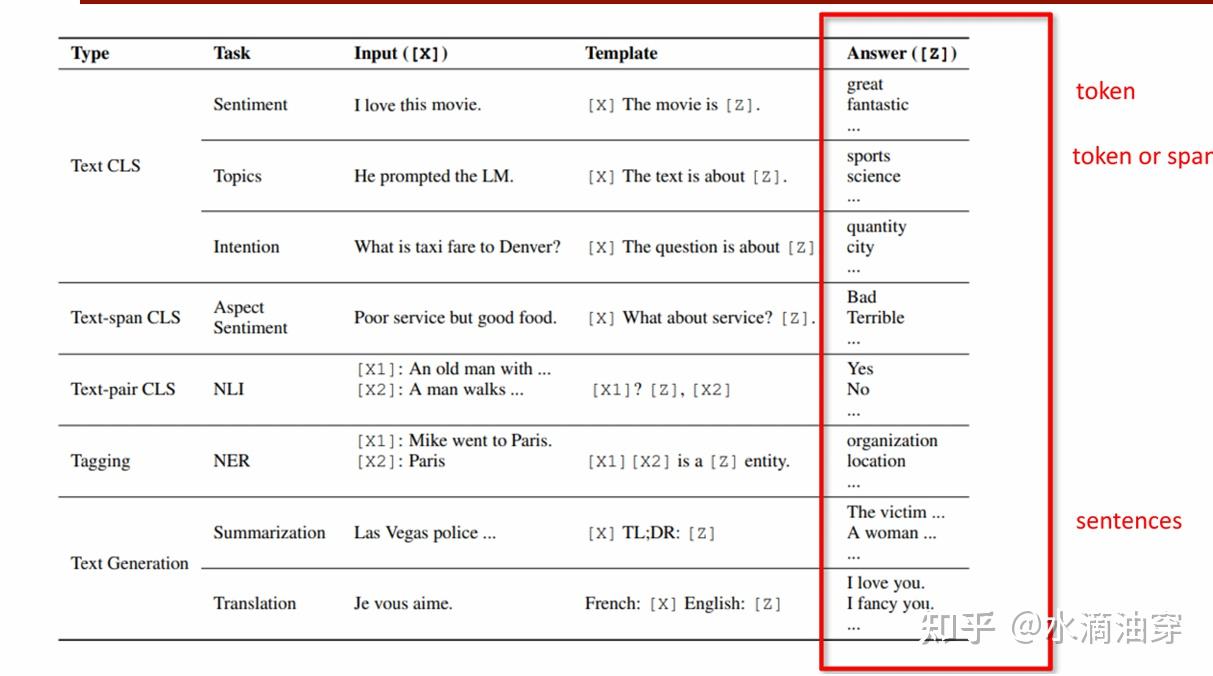
除了template的生成,Answer Enginnering是一种对输出的答案进行处理来使得其符合我们所需要求的方法,前面曾对构建映射、答案修剪等筛选方法进行简单介绍。
构建映射是一种比较常见的方法,如下图所示,根据task的不同,[Z]所限定的输出形式也是不一样的。
这里需要考虑的一个问题就是如何构建合适的答案集,除了人工进行标注之外,我们也可以使用一些自动答案搜索 的方法,如answer paraphrasing就是从初始答案空间开始,然后使用paraphrase来扩展此答案空间。除此之外Prune-then-Search是一种生成几个合理答案的初始修剪答案空间,再使用算法进一步搜索此修剪的空间以选择最终的答案集的方法。
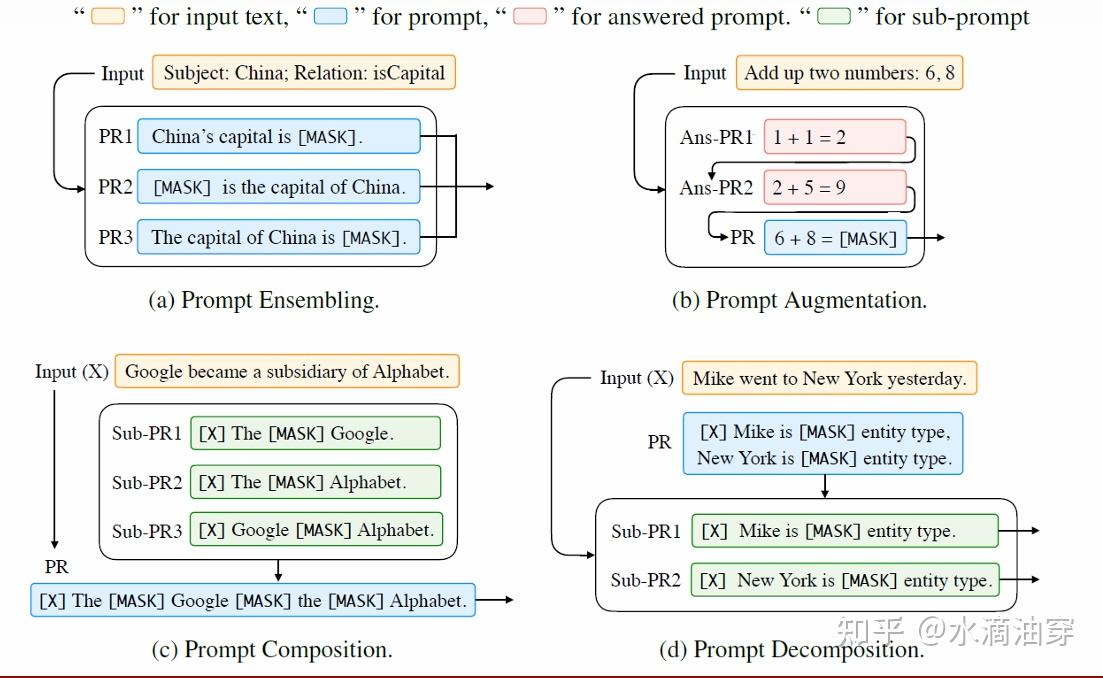
最后,除了单一的提示词作为微调的工具,Multi-prompt Learning也是一个可能的研究方向,下图示意了许多种将不同prompt相组合的方式,包括集成(ensembling)、增强(augmentation)、合成(composition)和分解(decomposition)等方法。
实质上,prompt相较于原本的finetuning,所采用的方法的区别主要在于,prompt通过在文本上设计一系列引导和规范性的语句,来激活模型的推理能力,为什么prompt能够获得成功?回想起上一篇笔记中在介绍GPT-3时所提到的in-context learning,我们不难发现,prompt和in-context learning关系密切,in-context learning会提供更加丰富的上下文信息,通过few-shot learning来激活模型的推理能力,而在few-shot learning中我们所提供的例子本质上就是一种更加丰富形象的prompt。
总的来说,基于模型的in-context learning能力,一个prompt应当包含以下部分: instruction,即希望模型执行的特定任务的描述;context,即可以引导模型做出更好响应的外部信息或其他的上下文,input和output。我们在撰写prompt的时候,一方面要尽量详尽、细致,另一方面也要尽量直接、高效,尽量避免不精确的表述,同时也尽量避免说否定词“不/not”,因为token切割时可能会造成歧义。
下面介绍一些撰写prompt的技巧:
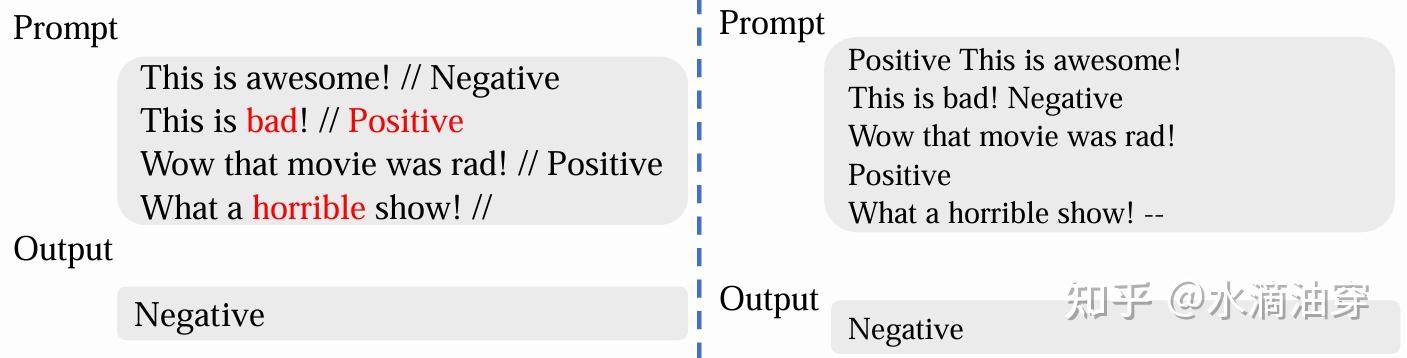
(1)few-shot prompting:通过几个例子来引导模型更好理解任务的需求。在这其中,如何处理label和input的位置对模型的结果有很大的影响,并且我们应该尽量保证几个例子和任务要求格式的一致性,另外,针对label的选择,可以考虑从真实分布中选择,对模型的性能会有帮助。下面第二个图演示了格式一致和不一致的情况,下面第三个图说明了label选择的随机与否对模型性能的影响。

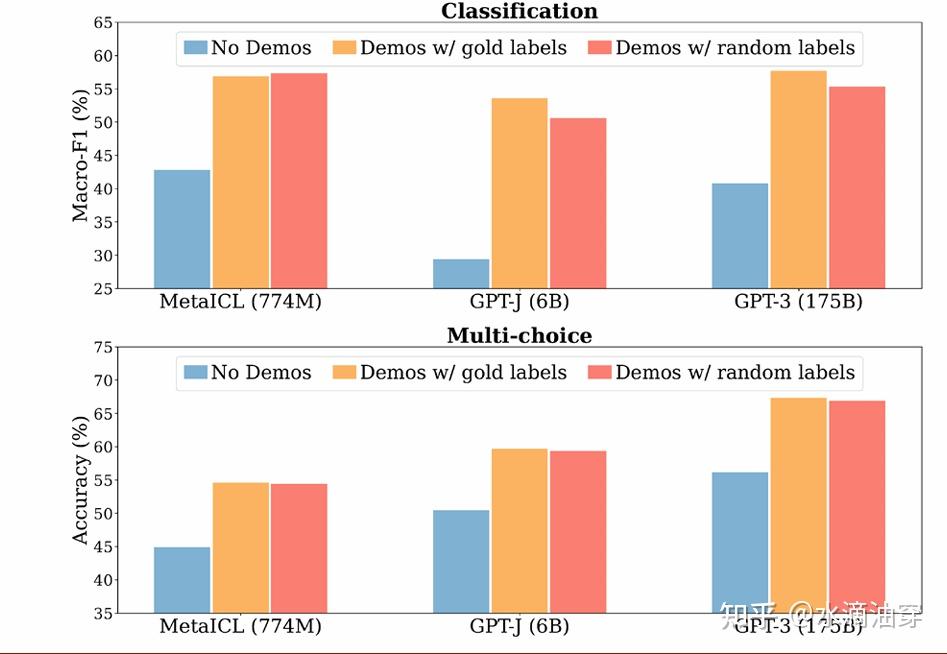
从第三张图我们可以看到,好像label只需要格式上“存在”,至于其具体内容好像对模型的性能没有太大影响,研究者试着调整了label的准确率,证实了这一点:

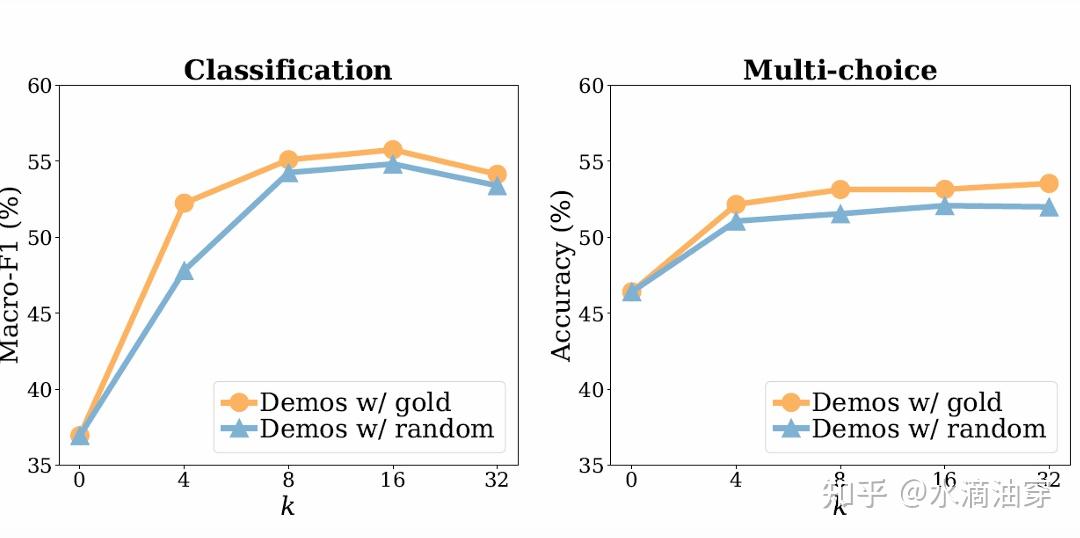
shot的数量随任务的不同有不同的变化规律,一般来说达到一定数量后shot的数量继续增加对模型性能的提升意义不大:
需要指出的是,研究表明few-shot learning在对模型的推理能力的提升方面主要是“照猫画虎”能力的提升,一旦模型在面临比较复杂的推理任务时,few-shot learning就没有那么有用:


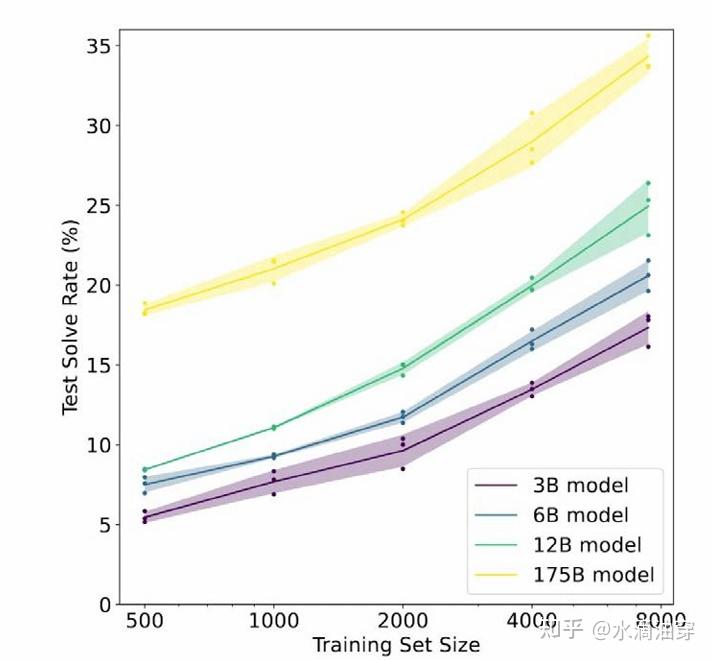
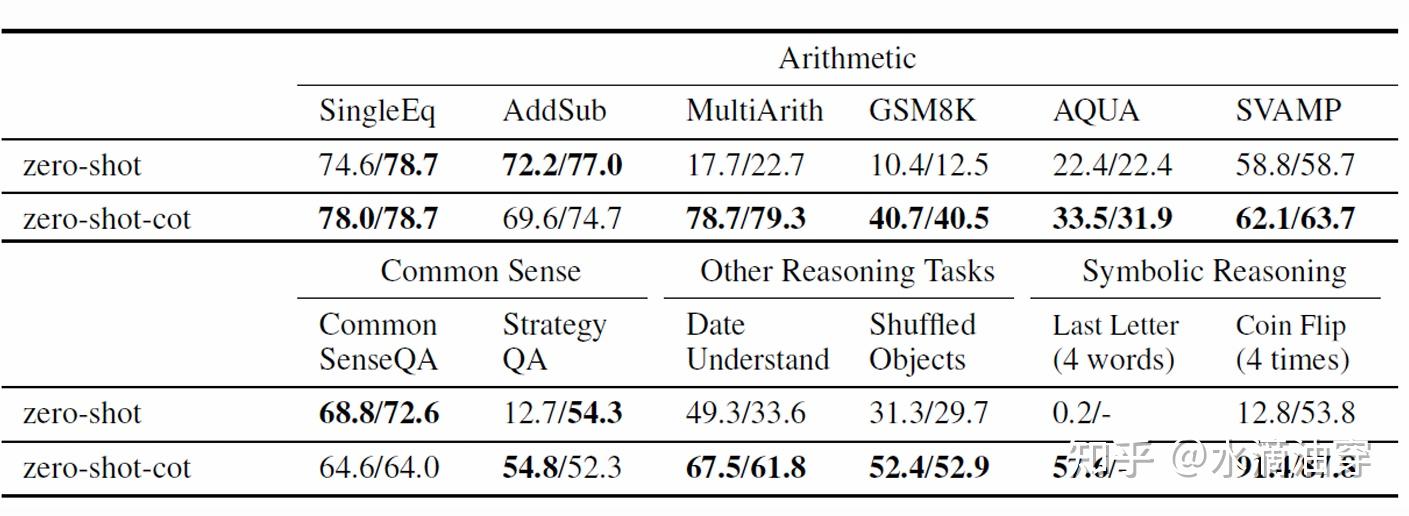
正如我们所熟知的,推理能力的提升一直是大模型的一个挑战,下图展示了即使是175B的大模型在推理上的准确率也很低,研究表明需要微调100次才能达到80%的准确率:
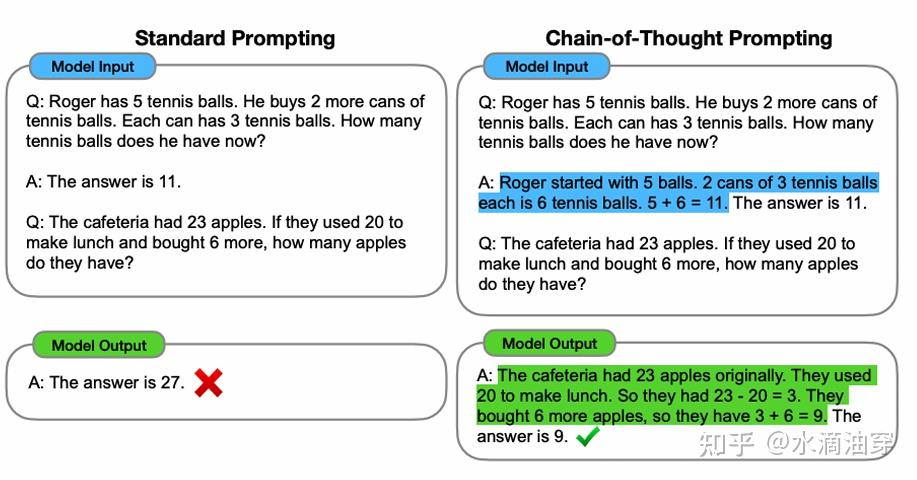
一个可能的解决方法是CoT(Chain of Thought),CoT实际上也是对人思考问题的方式的一种模拟,比如我们在解一道数学题的时候,很难看到题干就直接得出答案,我们都会得出一系列“中间结果”。也就是说,传统的范式是<input,output>,CoT则将这种范式调整为<input,intermediate result,output>。在实际过程中,我们可以在few-shot prompt的时候给每一个范例添加一些思考性的调整,这样可以将一个复杂的问题(对大模型来说)分解成一系列简单的中间问题,如下图所示:
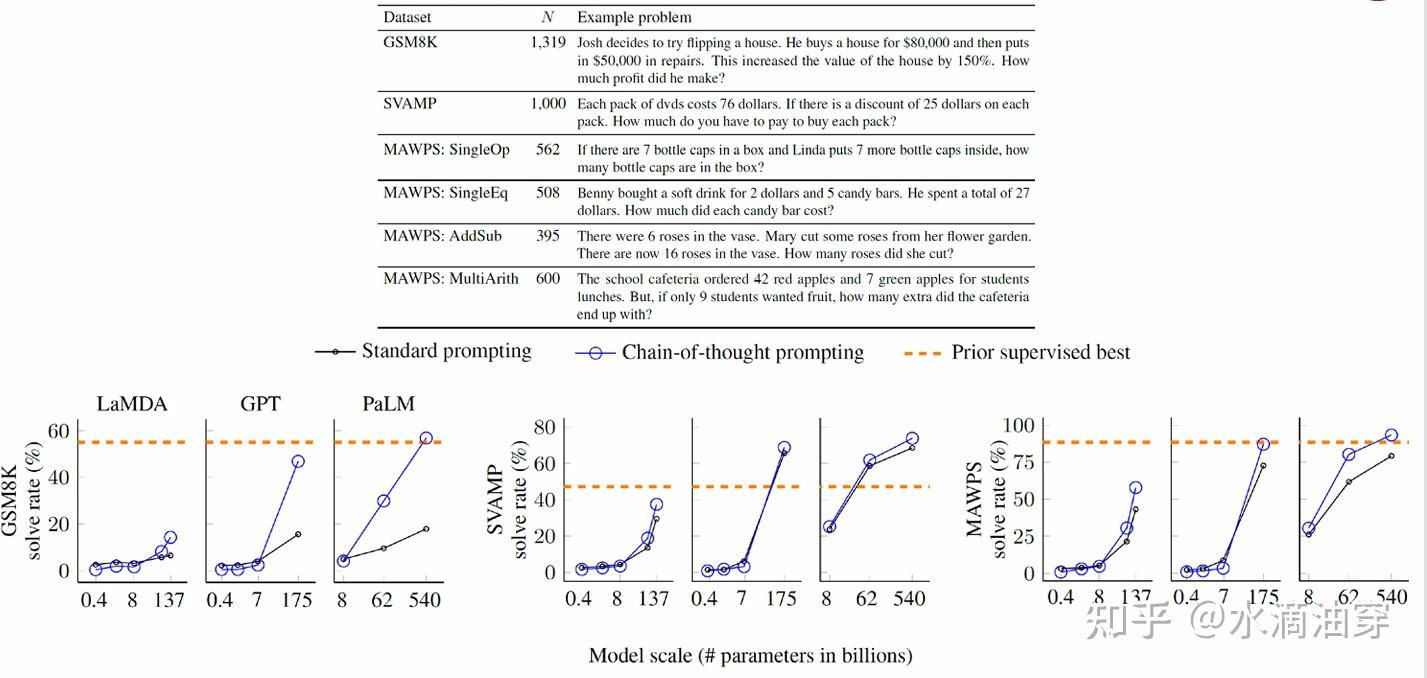
下面是一些使用CoT的实验结果,可以得到在某些问题上CoT甚至达到了监督学习的水平:
事实上,就算是不使用few-shot learning转而使用zero-shot learning,也就是添加一些类似于“Let’s think step by step”之类的prompt同样可以得到较好的效果:

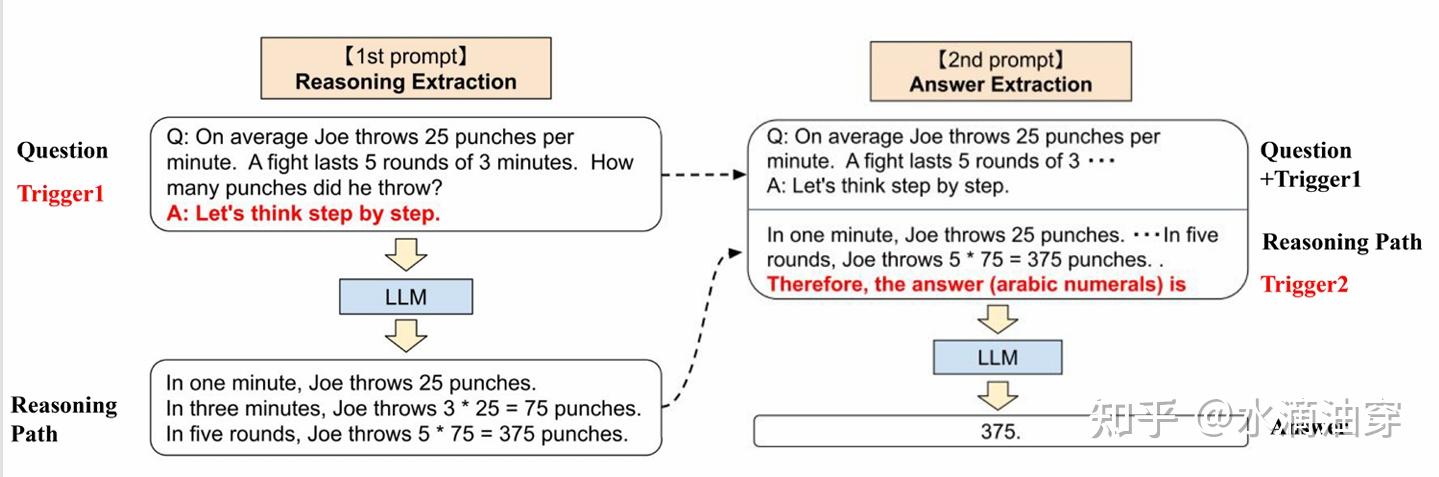
下面提供了一个zero-shot-CoT的训练范式,分别使用了两次prompt,在第二次引导了LLM给出问题的答案,这样就构成了一个完整的解题思路:
在一些问题上,zero-shot-CoT的表现要超过没有CoT的部分,这一点在模型的参数量变高时尤为明显:
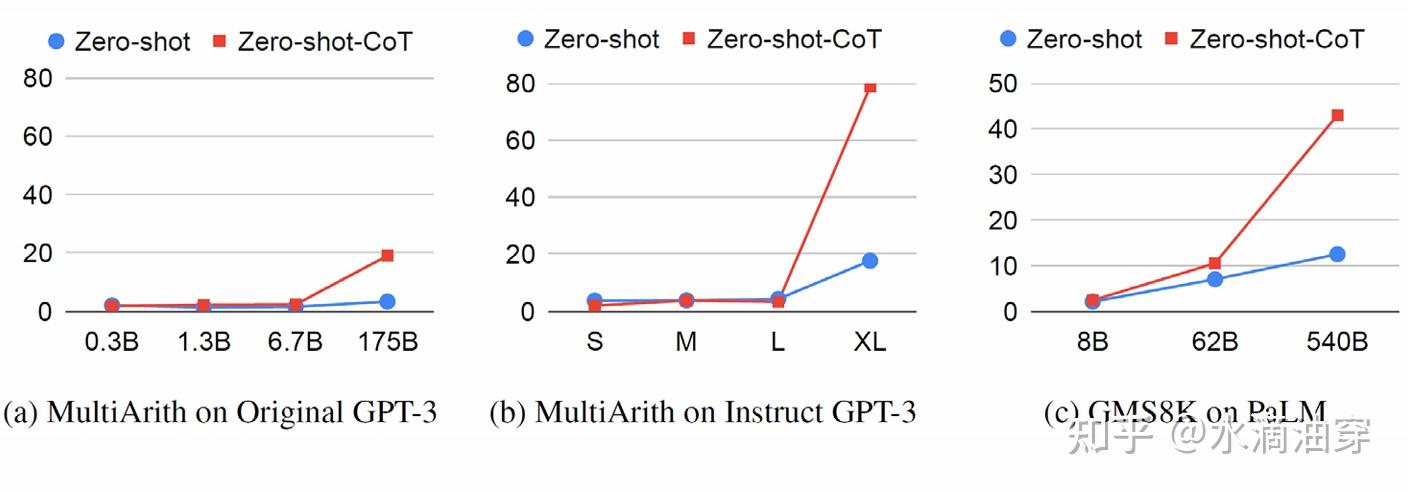
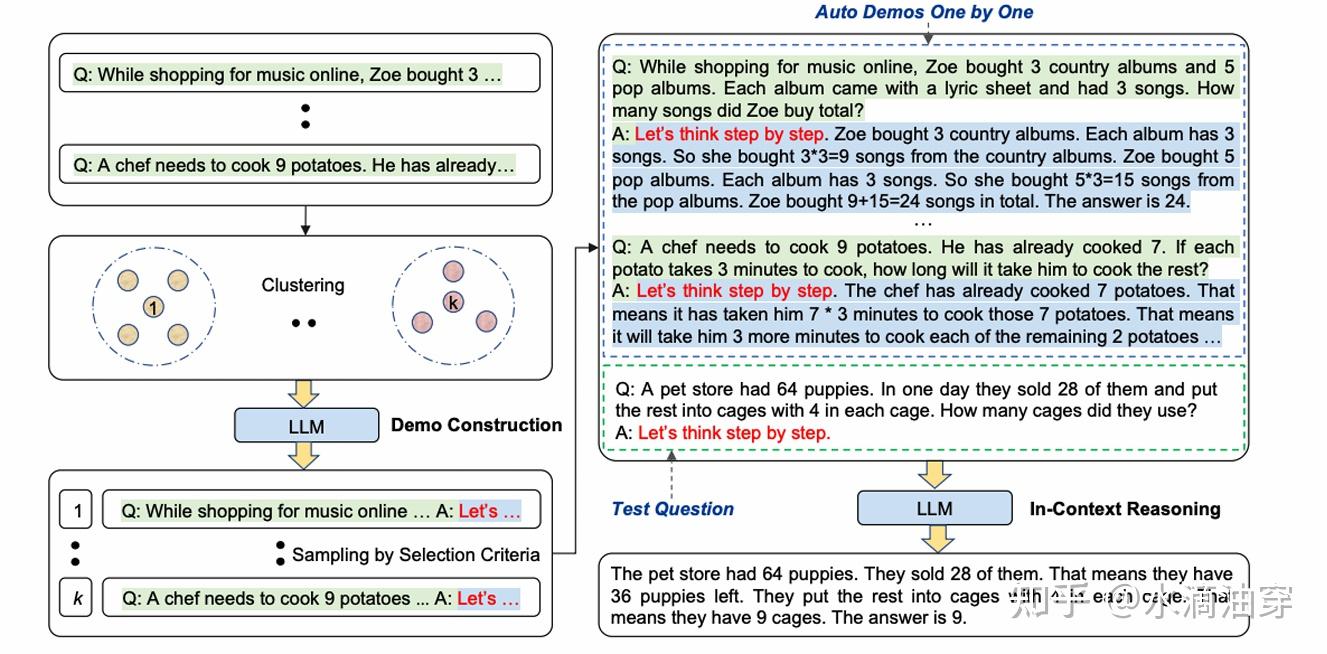
另外,也有研究者提出可以针对不同的问题进行聚类,然后再使用zero-shot方法,这种方法是Automatic chain-of-Thought(Auto-CoT),如下所示:
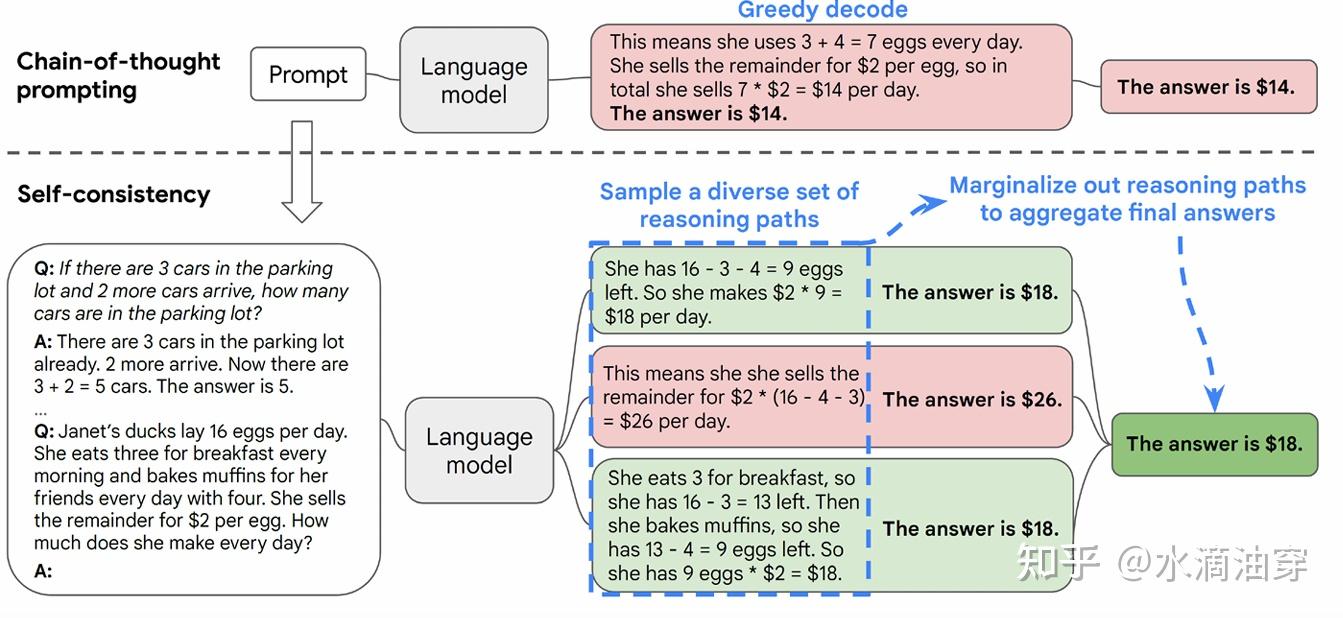
除此之外,也有研究者提出针对一个问题按照CoT方法输出多个答案,由此对答案进行筛选来提升模型性能。具体来说,这种方法需要对多个推理路径进行采样,并不断迭代从而找到最优的答案。本质上来说,LLM生成的结果是一个概率分布,因而如果不进行筛选而直接简单greedy的生成一个答案,显然不一定能得到我们想要的结果。这种方法被称为self-consistent,framework如下:
在self-consistent的基础上,有研究者从数据结构的角度出发对CoT进行改进,因为本质上来说,CoT是一条单线程的推理过程,而self-consistent则是多线程并行的推理过程(通过对多个推理路径进行采样找到最优答案),那么ToT(Tree of Thought)就是将树引入其中,通过不同推理过程的交叉拓展使得信息能够更全面的共享,从而提高得到期望结果的概率,对比图如下所示:
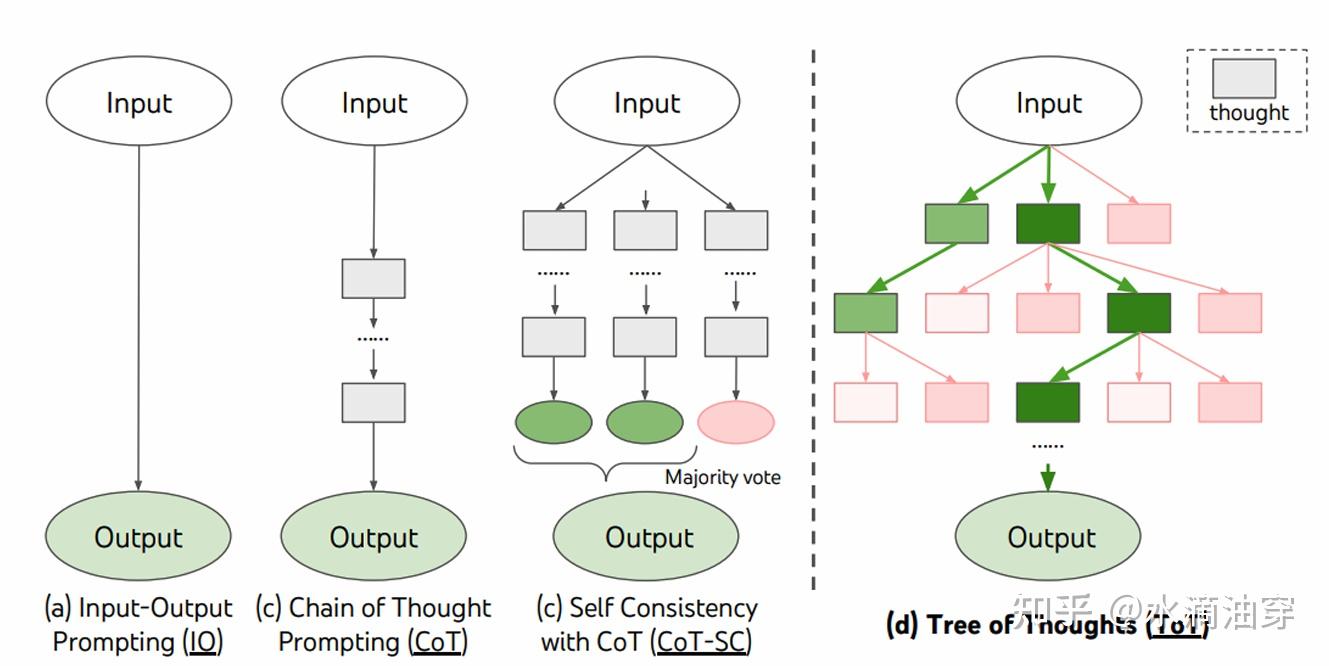
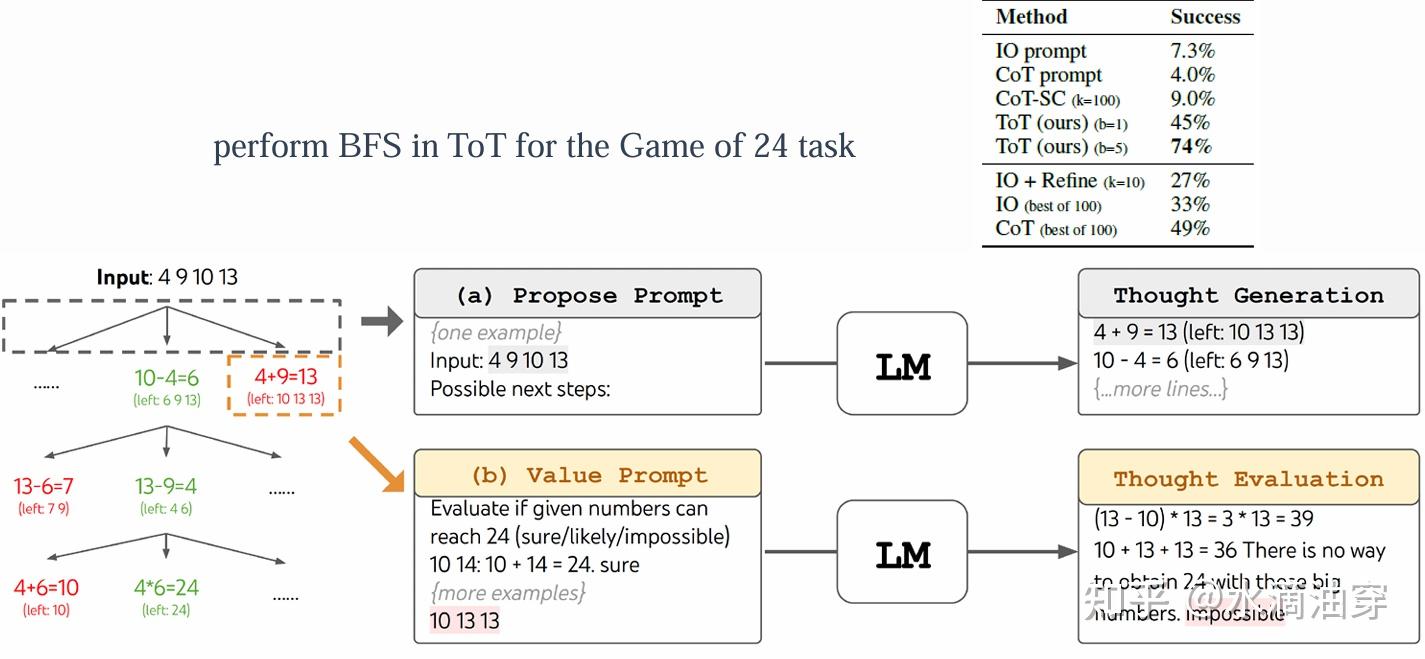
以下是一个用ToT进行24点的例子,实验结果表明其结果有显著的提升:
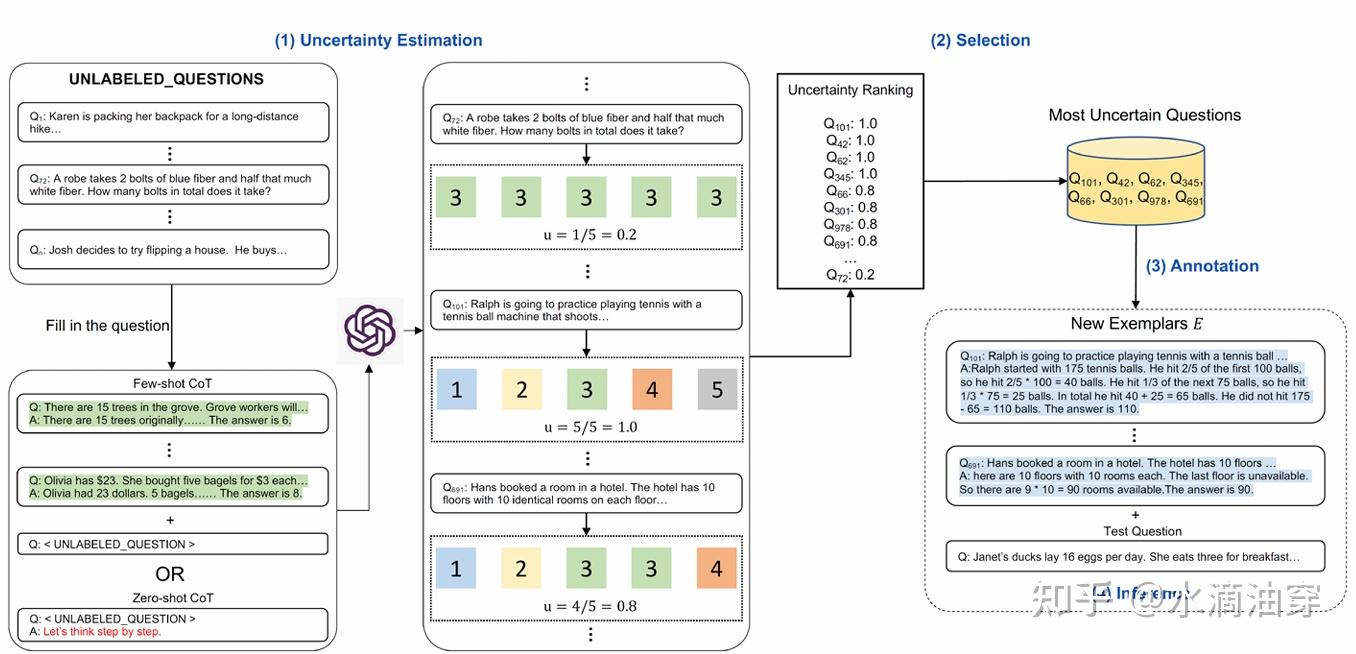
我们并没有对CoT的shot和prompt进行过多的讨论,而有研究者认为不同类型的任务应该对shot有针对性的调整。Active-Prompt是基于调整和多次询问的一种方法,我们首先给定一个问题集D,让LLM对每个问题都回答k次,然后根据这k次回答计算其差异度u,按照u的从高到低排名,对于排名较高的一系列问题,说明了现有的shot可能不太适合这些问题,我们对这些问题重新编写shot并重复上述过程,framework如下:
除了在思维模式上对LLM进行引导,研究者还试图让LLM在解决问题的过程中调动知识,这种方法被称为Generate-Knowledge Prompting。framework如下所示:
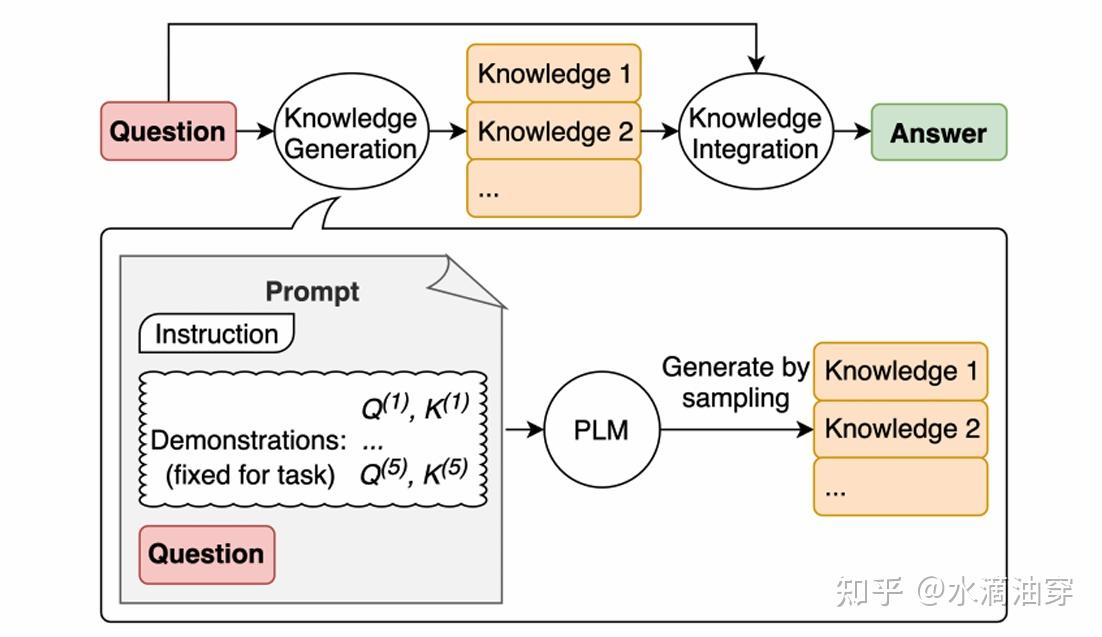
具体的操作过程中,我们首先引导模型生成知识,这个过程是通过few-shot prompt实现的,如下所示:

根据这样的prompt,模型就会生成对应的knowledge,如下所示:

那么,我们已经让模型复述出了这些知识,相当于我们“提醒”了模型这些知识的存在并让它“浮于表面”。我们再将同样的问题抛给模型时,模型就自然而然的会调动这些知识:

在此基础上,检索增强技术(RAG)被提出,也被现在的诸多大模型广泛采用。所谓RAG,就是在大模型思考问题时同时进行外部知识的检索、查阅和理解,这提升了大模型面对各种问题的能力,也能有效缓解大模型的“幻觉”问题,当然了,这需要我们在大模型中加入一个信息检索模块和一个文本生成器。有关RAG的研究很多,此处不做详细讨论,可参考论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
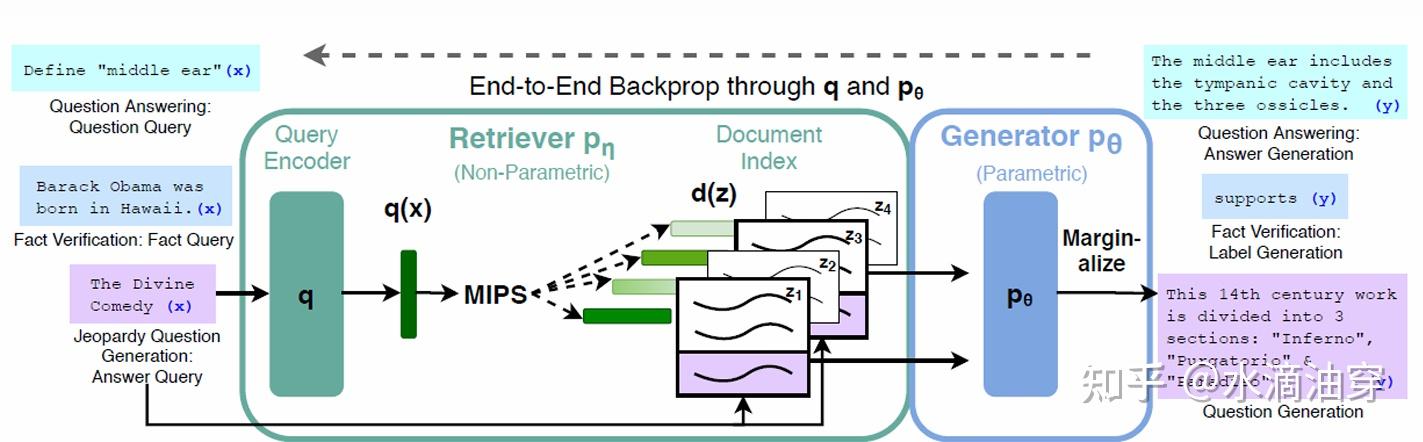
类似的,LLM所面对的一些任务已经超出了NLP本身的范畴,例如可能需要在模型运行时进行代码运行等,同时对CoT的使用也常常需要外部工具的介入,为了实现一个完整、自动的CoT,我们需要实现LLM与外部工具的对接,因而一个自动完整运行CoT的程序Automatic Reasoning and Tool-use (ART)被提出。以下是一个实例,在这个实例中模型使用了Google查询、Openai Codex和Python等多种工具,将大模型作为一个多种工具集成的端口。这也可能是未来的发展方向。

我们已经完成了一长篇关于提示词工程的系统介绍,这部分介绍包含在我们的微调方法介绍中。接下来我们将介绍另一种广泛使用的微调方法LoRA。虽然我们前面讲述的prompt tuning有众多的优势,但其有一个天然的问题在于,prompt的内容是不可训练的,同时它本身也会占用大量的token。因而研究者考虑微调一个任务对应的大模型就是对原有的参数矩阵附加一个low-rank的矩阵T,这一点可以参照文章前部在介绍其他参数微调时所提到的low-rank limitation方法。
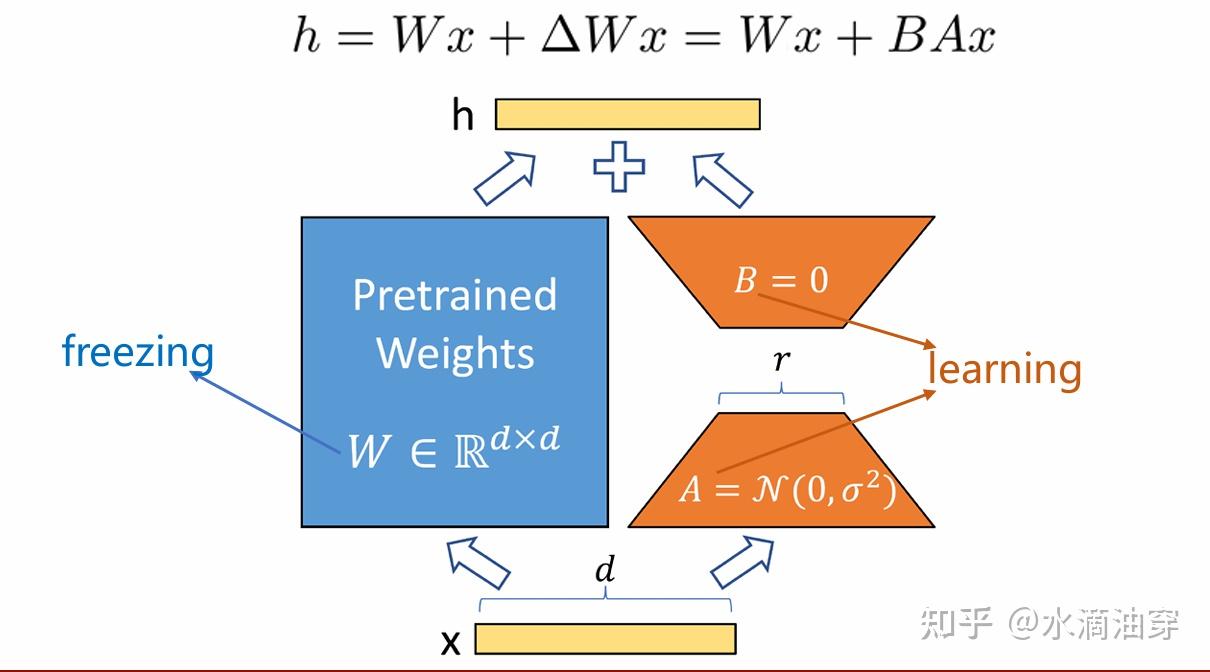
LoRA的原理和残差连接很类似。如下图所示,我们尝试微调 Δθ=θM−θT ,但我们认为 Δθ 是低秩的。
这一个认为是怎么实现的呢,参照我们之前讲的low-rank limitation的原理,我们可以控制附加矩阵T的秩(我们通过学习T来学习残差),如下图所示,在微调的过程中一种可能的方法是让需要附加的矩阵进行低秩分解,具体的原理已经在上面阐述过。其中,在实际操作的过程中,我们通常用正态分布来控制矩阵A,用零矩阵来控制矩阵B,这样能保证在预训练的时候AB=0,从而不对训练造成干扰。
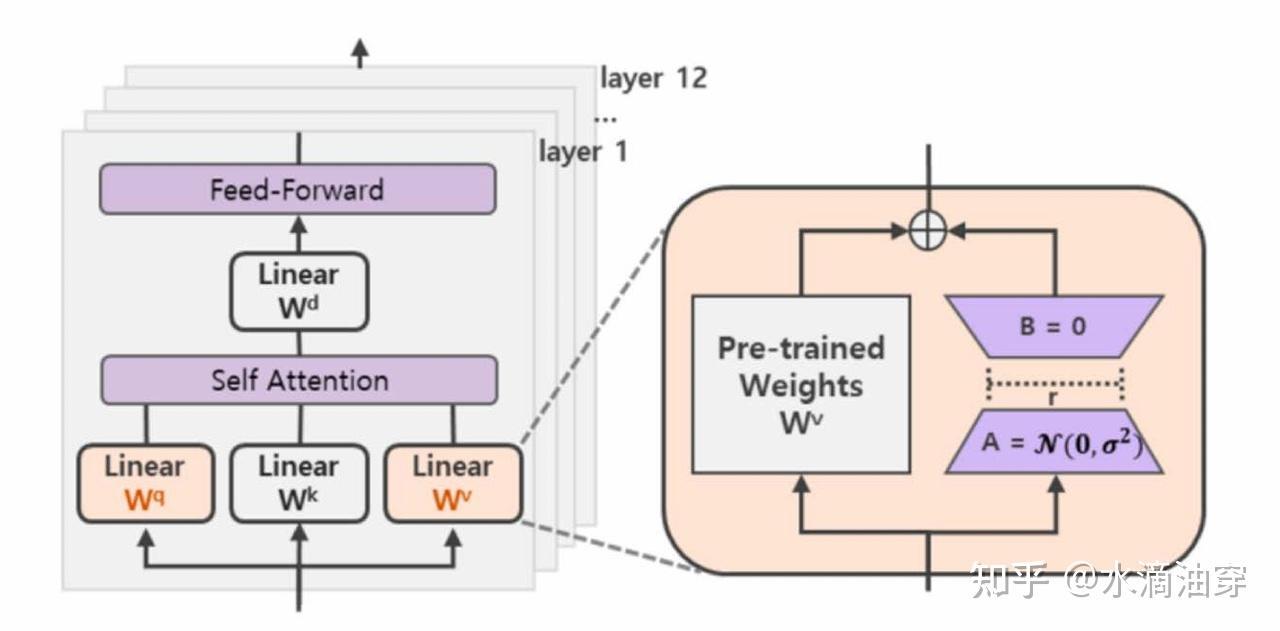
放置在具体的transformer中,如下所示:
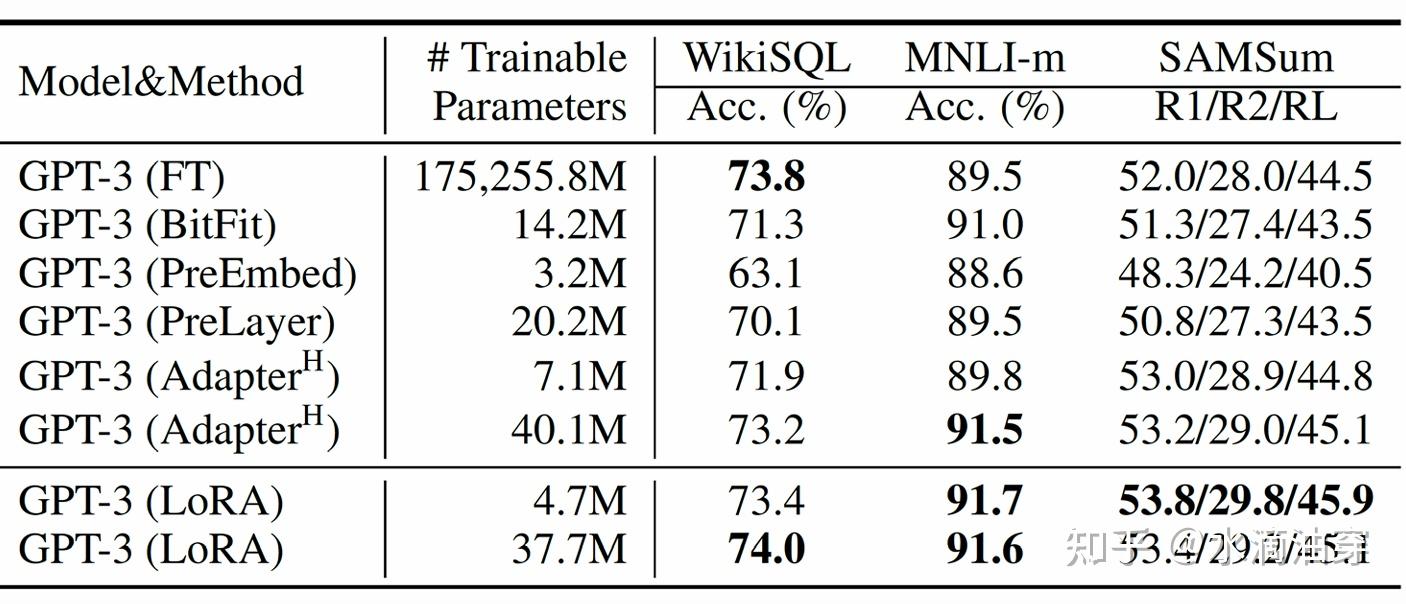
针对GPT-3的实验结果如下所示:
二、基于强化学习的大模型对齐
所谓对齐(alignment),就是尽可能保证模型的输出符合人类的偏好。这里面涉及到一系列的问题,如模型输出的安全问题、伦理问题等等,如果笔者有时间,会专门开一篇笔记详细讲述有关对齐的内容,但此处为了使“让LLM效果更加优秀”这一主题更加完整,笔者在此只简单介绍基于强化学习的对齐方法RLHF(Reinforcement Learning from Human Feedback).
我们首先需要再次强调大模型需要遵守的3个准则,这也是我们对齐的目标:
• Helpful:模型综合能力强,能够有效地遵循指令、提供信息。
• Honest:模型提供尽可能符合事实的信息,降低幻觉率。对自己的回答能够给出正确的置信度。
• Harmless:模型不提供有害信息,例如危险物品制作、歧视相关。对相关的诱导和攻击(Red-Teaming) 具有识别和抵抗能力。
其次,我们需要明确RLHF的概念:语言模型通过解码产生回复,人类对回复提供反馈(例如,喜欢/不喜欢),模型根据反馈信号,通过强化学习调整回答策略。我们可以看到,RLHF最重要的一点就是对人类反馈机制的引入。相较于SFT,RLHF的回复不是刻板的外部监督,而是根据策略生成的结果,能有效避免模型的幻觉,同时也能提供模型超越人类的可能(在监督学习的情况下绝无可能)。
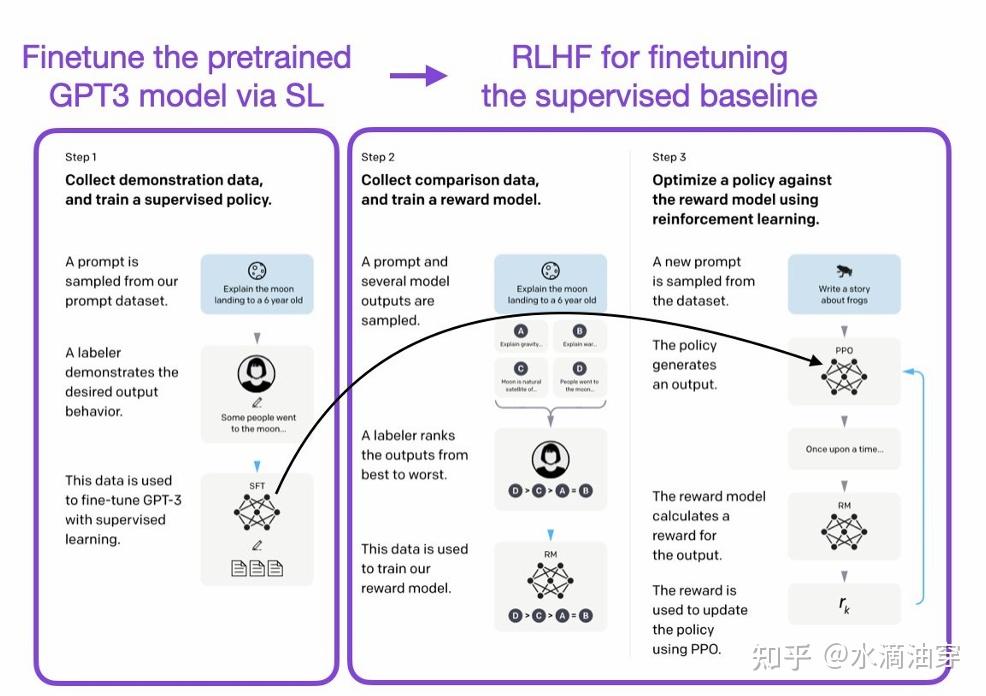
使用RLHF的经典模型是instruct-GPT和chatGPT的PPO(Proximal Policy Optimization)方法。如下图所示,其步骤大致分为三块:Step1是对预训练好的大模型给予一些输入,然后用人工标注这些输入结果,并利用这些标签对模型进行SFT,这一微调好的模型将会在Step3中用到。Step2是对同一个指令采集多个回复,让人工对这些回复进行偏好排序,用这些数据训练一个奖励模型。Step3则将这两步的结果结合,利用微调好的模型给予输出,用奖励模型对输出进行奖励,以此不断迭代的训练模型。
对奖励模型的训练基于基础的人类偏好模型Bradley-Terry,它是一种用来预测两个竞争者结果的模型,常用来比较成对的结果,下面我们对这个模型做一个简单的推导。
给定偏好数据的概率是:
p(i>j)=pipi+pj
也可以按照选手对应的指数分数函数 pi=eβi 重改写为:P(i>j)=eβieβi+eβj=11+e−(βi−βj)我们可以发现这个函数的形式与sigmoid函数相类似: σ(x)=11+e−x
我们可以用MLE估算出每个选手的分数: argminβ∑ij−logσ(βi−βj)
根据这个简单的模型形式,我们可以定义复杂的奖励模型。首先,我们根据输入 x 得到输出 y1,y2 ,根据reward function预测出分数 r∗(y,x) ,通过BT模型建模偏好分布:p∗(y1,y2|x)=exp(r∗(y1,x)exp(r∗(y1,x)+exp(r∗(y2,x)给定数据集 D=(x(i),yw(i),yl(i))i=1N ,则可以最大化期望reward(其中 ϕ 是训练参数):
LR(rϕ,D)=−E(x,yw,y1)∼Dlogσ(rϕ(x,yw)−rϕ(x,yl))根据给出的reward model形式及优化前后策略的KL惩罚,可以写出RLHF的优化函数:
maxEx∼D,y∼πθ(y|x)[rθ(x,y)]−βDKL[πθ(y|x)|πref(y|x)]
在instruct GPT中,这一待优化的函数被修正为:
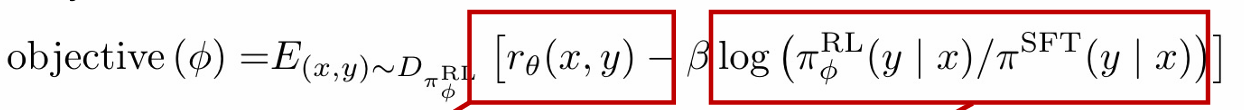
其中标红框的第一项仍然是最大化reward model的奖励,与之前的模型相一致,标红框的第二项是一个修正项,使RL后的模型尽可能靠近SFT的模型参数。下图是这一函数对应的模型架构的framework:
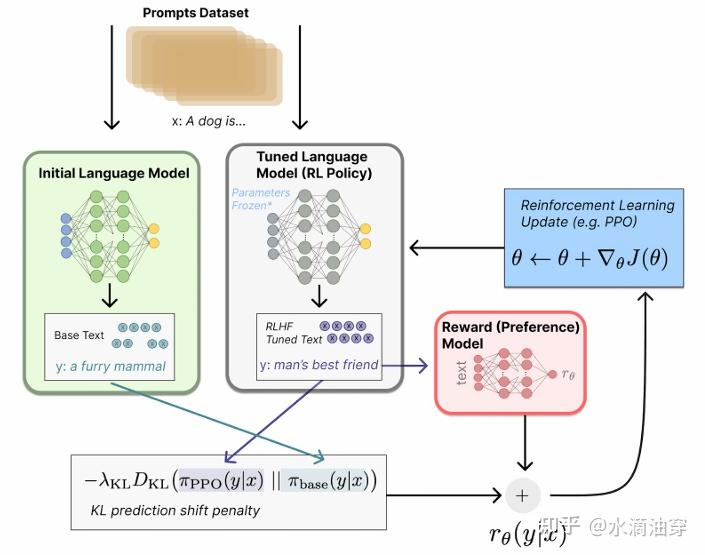
但PPO模型存在一个显著的弊端,就是其巨大的存储占用。我们可以将PPO模型拆解为四个模型:
Reference模型:在SFT之后,RL之前存储模型参数的模型,固定;
Actor模型:即主模型Policy Model,可训练;
Reward模型:奖励模型,在外部训练好,固定;
Critic模型:PPO算法中的value function,可训练;
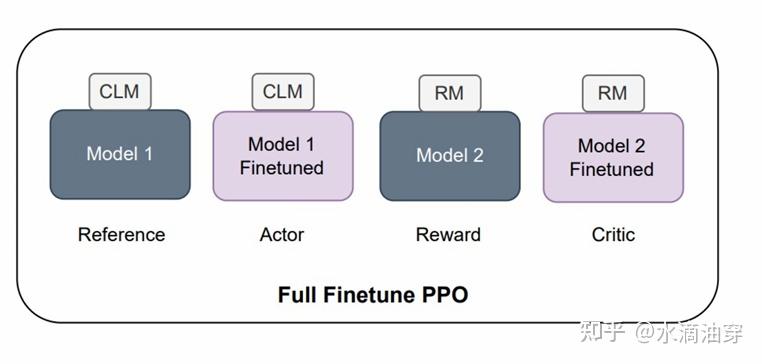
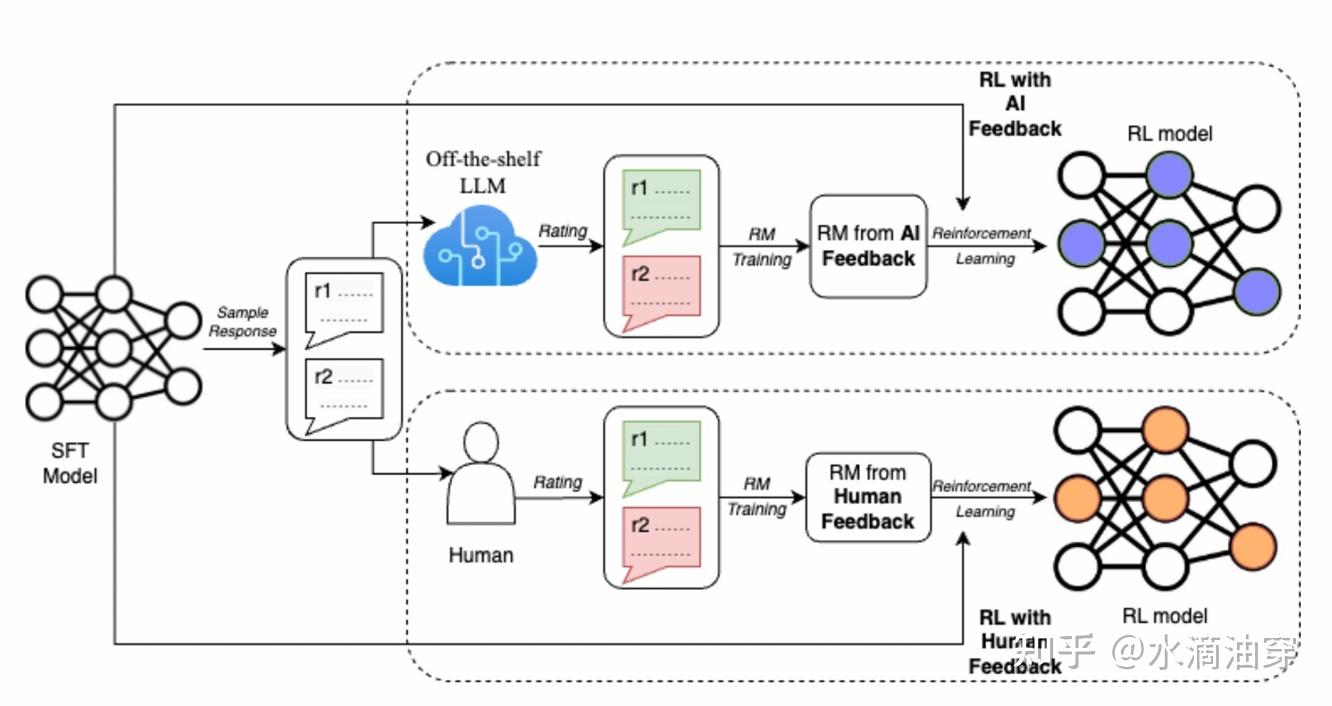
那么,一个结论就是PPO模型是传统微调(这本身已经很大了)的4倍,这种模型参数级别是巨大的。针对这一问题,有各种各样的优化方法,如Google Sparrow的底层参数共享,在训练时用LoRA等技术代替全参数训练等。另外,也有研究者针对人工标注成本过高问题选择用AI进行标注:
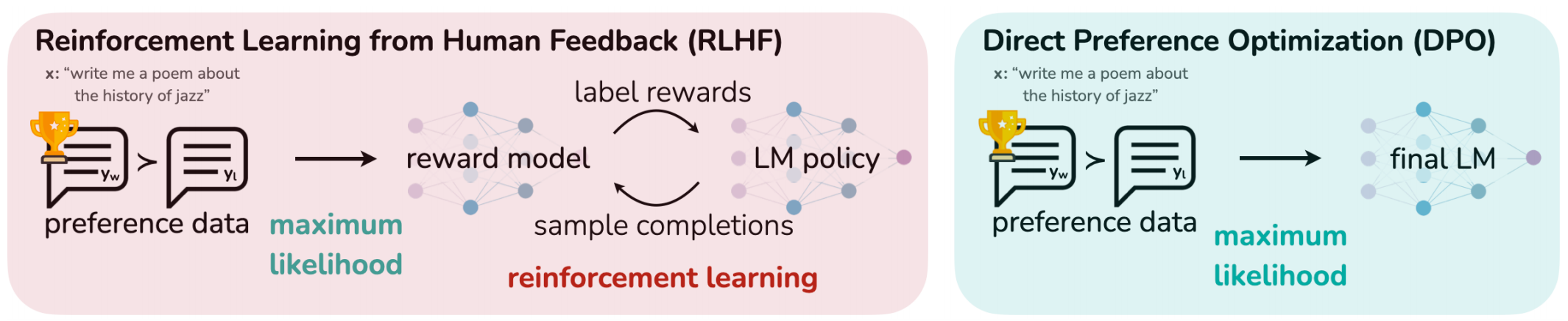
在此介绍一种被广泛使用的思路DPO(Direct Preference Optimization from Human Feedback),简单来说,传统的PPO算法的chain是:获取偏好数据->训练奖励模型->PPO训练主模型;DPO的思路是直接使用偏好数据训练主模型,从而跳过奖励模型的训练。下面给出这一思路的数学推导:
首先,重写reward model的优化函数:
maxπEx∼D,y∼π[r(x,y)]−βDKL[π(y∣x)‖πref(y∣x)]=maxπEx∼DEy∼π(y∣x)[r(x,y)−βlogπ(y∣x)πref(y∣x)]=minπEx∼DEy∼π(y∣x)[logπ(y∣x)πref(y∣x)−1βr(x,y)]=minπEx∼DEy∼π(y∣x)[logπ(y∣x)1Z(x)πref(y∣x)exp(1βr(x,y))−logZ(x)]其中配分函数:
Z(x)=∑yπref(y∣x)exp(1βr(x,y))配分函数只与 x,πref 有关,而与原始的策略 π 无关,因而我们依据此构造概率分布:
π∗(y∣x)=1Z(x)πref(y∣x)exp(1βr(x,y))这个式子满足求和为1,且每项大于0,考虑将这个式子代回原来的优化函数中,得到:minπEx∼D[Ey∼π(y∣x)[logπ(y∣x)π∗(y∣x)]−logZ(x)]=minπEx∼D[DKL(π(y∣x)‖π∗(y∣x))−logZ(x)]令KL为0,得到:π(y∣x)=π∗(y∣x)=1Z(x)πref(y∣x)exp(1βr(x,y))根据这个式子我们可以反解出奖励函数:
r(x,y)=βlogπr(y∣x)πref(y∣x)+βlogZ(x)再代入到BT模型的表达式中重新计算,得到:p∗(y1≻y2∣x)=exp(r∗(x,y1))exp(r∗(x,y1))+exp(r∗(x,y2))=11+exp(r∗(x,y2)−r∗(x,y1))=11+exp(βlogπ∗(y2∣x)πref(y2∣x)−βlogπ∗(y1∣x)πref(y1∣x))=11+exp(βlogπ∗(y2∣x)πref(y2∣x)−βlogπ∗(y1∣x)πref(y1∣x))=σ(βlogπ∗(y1∣x)πref(y1∣x)−βlogπ∗(y2∣x)πref(y2∣x))再使用MLE即得LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπθ(yw∣x)πref(yw∣x)−βlogπθ(yl∣x)πref(yl∣x))]要最小化整体的loss,我们只需要最大化-logsigmoid函数里面的内容,实质上就是在最大化模型对偏好数据和非偏好数据的选择差值,来使得模型尽可能的和人类对齐。
更详尽的推导过程,参见:
那么,如何快速系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

9周快速成为大模型工程师
第1周:基础入门
-
了解大模型基本概念与发展历程
-
学习Python编程基础与PyTorch/TensorFlow框架
-
掌握Transformer架构核心原理
-

第2周:数据处理与训练
-
学习数据清洗、标注与增强技术
-
掌握分布式训练与混合精度训练方法
-
实践小规模模型微调(如BERT/GPT-2)
第3周:模型架构深入
-
分析LLaMA、GPT等主流大模型结构
-
学习注意力机制优化技巧(如Flash Attention)
-
理解模型并行与流水线并行技术
第4周:预训练与微调
-
掌握全参数预训练与LoRA/QLoRA等高效微调方法
-
学习Prompt Engineering与指令微调
-
实践领域适配(如医疗/金融场景)
第5周:推理优化
-
学习模型量化(INT8/FP16)与剪枝技术
-
掌握vLLM/TensorRT等推理加速工具
-
部署模型到生产环境(FastAPI/Docker)
第6周:应用开发 - 构建RAG(检索增强生成)系统
-
开发Agent类应用(如AutoGPT)
-
实践多模态模型(如CLIP/Whisper)


第7周:安全与评估
-
学习大模型安全与对齐技术
-
掌握评估指标(BLEU/ROUGE/人工评测)
-
分析幻觉、偏见等常见问题
第8周:行业实战 - 参与Kaggle/天池大模型竞赛
- 复现最新论文(如Mixtral/Gemma)
- 企业级项目实战(客服/代码生成等)
第9周:前沿拓展
- 学习MoE、Long Context等前沿技术
- 探索AI Infra与MLOps体系
- 制定个人技术发展路线图

👉福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
更多推荐



 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)