
在Mac上10分钟玩转LoRA微调模型
摘要:本文介绍了如何利用LoRA技术在Mac上微调FlanT5小模型,无需显卡或云端资源。LoRA的优势在于轻量(仅训练0.1%-1%新参数)、可插拔适配器和避免灾难性遗忘。文章详细展示了环境配置、数据处理、模型训练和推理测试的全流程代码实现,并在M3 MacBook上3分钟内完成5轮训练。虽然演示效果受限于小模型和数据集,但验证了LoRA+M系列芯片的可行性,建议有条件的用户尝试更大模型以获得更
LoRA微调Flan T5小模型
“不用显卡、不用上云,只靠一台 Mac 就能训练属于自己的 AI 模型。”
1. 为什么选择 LoRA?
- 轻量:只训练0.1%~1% 新参数,速度快、显存占用低。
- 可插拔:多个 LoRA 适配器随时切换,一模多用。
- 免风险:基座模型冻结,不怕「灾难性遗忘」。
2. 环境准备
| 步骤 | 命令 |
|---|---|
| 安装pyenv | brew install pyenv |
| 安装python版本 | pyenv install 3.11.9 |
| 创建虚拟环境 | python3.9 -m venv .venv |
| 进入虚拟环境 | source .venv/bin/activat |
| 安装 PyTorch (MPS) | pip install torch torchvision --index-url https://download.pytorch.org/whl/cpu |
| 安装核心库 | pip install transformers datasets peft accelerate |
3. 准备数据 (举例:本地JSONL)

4. 创建脚本finetune_lora.py
import torch
from transformers import (
AutoModelForSeq2SeqLM, # —— Seq2Seq 架构模型(这里选用 google/flan-t5-small)
AutoTokenizer, # —— 与模型配套的分词器
TrainingArguments, # —— Trainer 的超参数容器
Trainer, # —— HuggingFace 训练循环封装器
DataCollatorForSeq2Seq # —— 动态批量 Padding + Label 处理器
)
from datasets import load_dataset # —— 轻松读取/流式加载各类数据集
from peft import ( # —— PEFT = Parameter-Efficient Fine-Tuning
LoraConfig, TaskType, get_peft_model, PeftModel
)
# ---------- Step 1: 读取 JSONL 数据 ----------
# data.jsonl 每行形如 {"instruction": "...", "output": "..."}
dataset = load_dataset("json", data_files="data.jsonl")
train_dataset = dataset["train"]
# ---------- Step 2: 文本预处理 ----------
model_name = "google/flan-t5-small"
tokenizer = AutoTokenizer.from_pretrained(model_name)
def preprocess(example):
# 将 “指令” 编码为 input_ids
model_input = tokenizer(
example["instruction"],
max_length=512,
truncation=True,
padding="max_length"
)
# 将 “答案” 编码为 labels(Teacher forcing)
labels = tokenizer(
example["output"],
max_length=128,
truncation=True,
padding="max_length"
)
model_input["labels"] = labels["input_ids"]
return model_input
train_dataset = train_dataset.map(preprocess)
# ---------- Step 3: 加载基座模型 + 注入 LoRA ----------
base_model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
lora_config = LoraConfig(
r=8, # 低秩矩阵秩
lora_alpha=16, # 缩放因子
lora_dropout=0.1, # dropout
bias="none",
task_type=TaskType.SEQ_2_SEQ_LM
)
model = get_peft_model(base_model, lora_config) # 返回仅新增数万参数的可训练模型
# ---------- Step 4: 设备 ----------
device = "mps"if torch.backends.mps.is_available() else"cpu"
model.to(device)
# ---------- Step 5: 训练参数 ----------
training_args = TrainingArguments(
output_dir="./lora_finetune_output",
per_device_train_batch_size=2, # 真实 batch size = 2 × gradient_accumulation
gradient_accumulation_steps=4,
num_train_epochs=5,
learning_rate=1e-4,
logging_steps=1,
save_strategy="no",
report_to="none",
fp16=False # Apple Silicon 上使用 float32 更稳定
)
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
# ---------- Step 6: 开始训练 ----------
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=data_collator,
tokenizer=tokenizer
)
trainer.train()
# ---------- Step 7: 保存 LoRA 适配器 ----------
model.save_pretrained("lora_adapter")
# ---------- Step 8: 推理测试 ----------
print("🎯 推理测试:")
base = AutoModelForSeq2SeqLM.from_pretrained(model_name).to(device)
lora_model = PeftModel.from_pretrained(base, "lora_adapter").to(device)
def infer(prompt: str) -> str:
"""单条推理:传入指令,返回模型生成的文本"""
inputs = tokenizer(prompt, return_tensors="pt").to(device)
outputs = lora_model.generate(**inputs, max_new_tokens=1)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
test_prompts = [
"what is the capital of China?",
"what is the capital of France?",
"what is the airplane?"
]
for p in test_prompts:
print(f"🧠 Prompt: {p}")
print(f"📝 Answer: {infer(p)}")
print("-" * 40)
- 训练日志打印
(.venv) ➜ aigc python finetune_lora.py
Generating train split: 1000 examples [00:00, 452655.30 examples/s]
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [00:00<00:00, 9258.42 examples/s]
{'loss': 41.4961, 'grad_norm': 3.4582340717315674, 'learning_rate': 0.0001, 'epoch': 0.01}
{'loss': 45.12, 'grad_norm': 4.7143425941467285, 'learning_rate': 9.984e-05, 'epoch': 0.02}
{'loss': 43.707, 'grad_norm': 3.819638252258301, 'learning_rate': 9.968000000000001e-05, 'epoch': 0.02}
{'loss': 40.973, 'grad_norm': 3.7596452236175537, 'learning_rate': 9.952e-05, 'epoch': 0.03}
{'loss': 45.6711, 'grad_norm': 4.67157506942749, 'learning_rate': 9.936000000000001e-05, 'epoch': 0.04}
{'loss': 42.3758, 'grad_norm': 4.384180068969727, 'learning_rate': 9.92e-05, 'epoch': 0.05}
{'loss': 36.1399, 'grad_norm': 3.7017316818237305, 'learning_rate': 9.904e-05, 'epoch': 0.06}
{'loss': 44.6688, 'grad_norm': 4.85175085067749, 'learning_rate': 9.888e-05, 'epoch': 0.06}
{'loss': 44.2394, 'grad_norm': 4.683821201324463, 'learning_rate': 9.872e-05, 'epoch': 0.07}
{'loss': 41.7887, 'grad_norm': 4.8903913497924805, 'learning_rate': 9.856e-05, 'epoch': 0.08}
{'loss': 44.2073, 'grad_norm': 4.807693004608154, 'learning_rate': 9.84e-05, 'epoch': 0.09}
{'loss': 42.7997, 'grad_norm': 4.235534191131592, 'learning_rate': 9.824000000000001e-05, 'epoch': 0.1}
{'loss': 39.6141, 'grad_norm': 4.627796173095703, 'learning_rate': 9.808000000000001e-05, 'epoch': 0.1}
{'loss': 41.5859, 'grad_norm': 4.959679126739502, 'learning_rate': 9.792e-05, 'epoch': 0.11}
{'loss': 44.5831, 'grad_norm': 5.254530429840088, 'learning_rate': 9.776000000000001e-05, 'epoch': 0.12}
{'loss': 43.8274, 'grad_norm': 5.325198173522949, 'learning_rate': 9.76e-05, 'epoch': 0.13}
{'loss': 41.8024, 'grad_norm': 5.138743877410889, 'learning_rate': 9.744000000000002e-05, 'epoch': 0.14}
{'loss': 41.099, 'grad_norm': 5.499021530151367, 'learning_rate': 9.728e-05, 'epoch': 0.14}
{'loss': 41.2216, 'grad_norm': 11.285901069641113, 'learning_rate': 9.712e-05, 'epoch': 0.15}
{'loss': 37.4023, 'grad_norm': 4.781173229217529, 'learning_rate': 9.696000000000001e-05, 'epoch': 0.16}
{'loss': 41.2696, 'grad_norm': 5.610023021697998, 'learning_rate': 9.680000000000001e-05, 'epoch': 0.17}
{'loss': 37.7613, 'grad_norm': 3.9915575981140137, 'learning_rate': 9.664000000000001e-05, 'epoch': 0.18}
....
可以看到损失值每轮递减,在M3 MacBook上,5 epoch≈3分钟,所以非常快就能看到结果。
6. 实战效果
这是我的问题:
test_prompts = [
"what is the capital of China?",
"what is the capital of France?",
"what is the airplane?"
]
loRa微调之后的模型输出如下:
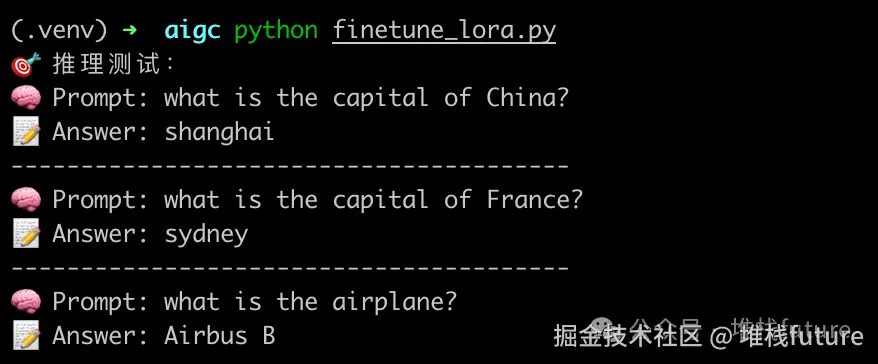
那么从结果来看回答还可以,但是你如果仔细看就会发现,答案是错的,很明显中国的首都是北京不是上海,法国的首都是巴黎不是悉尼。
因为我们只是拿google的t5基座小模型做微调演示,受各方面因素影响,比如数据集少,显卡不够,基座模型也一般等,所以微调出来的模型质量并不是很好。如果大家有更多的显卡,内存,那么建议尝试一下更大的模型,比如7B或者7B以上的,这样微调出来的模型应该效果不错。
7. 小结
- LoRA = 少动刀、多收获(冻结全部参数,只在需要微调的参数上做梯度并更新局部参数);
- M系Mac = 随时随地的小型“GPU”(提醒:必须内存16G以上 核心8及以上);
- HuggingFace + PEFT = 零门槛上手(HuggingFace数据集和模型非常多,可以直接拿来训练)。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 下方小卡片领取🆓↓↓↓
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)