
常用图像分类预训练模型大小及准确度比较
近年来,深度学习技术的发展使得图像分类任务变得越来越容易。预训练模型的出现更是使得图像分类任务变得更加简单和高效。然而,随着预训练模型的数量和大小的增加,我们需要了解每个模型的特点和优缺点,以便更好地选择和使用它们。使用预训练模型作为起点,通过迁移学习来学习新任务,可以大大加快训练速度,并提高模型的性能。
近年来,深度学习技术的发展使得图像分类任务变得越来越容易。预训练模型的出现更是使得图像分类任务变得更加简单和高效。然而,随着预训练模型的数量和大小的增加,我们需要了解每个模型的特点和优缺点,以便更好地选择和使用它们。
在图像分类领域,预训练模型扮演着至关重要的角色。它们不仅可以帮助我们更快地实现图像分类的效果,还可以提高模型的准确性和泛化能力。然而,不同的预训练模型在大小和准确度方面存在差异。本文将对一些常用的图像分类预训练模型进行大小和准确度的比较,以便读者在选择模型时能够更加明确。
一、预训练模型的重要性
预训练模型是通过在大量数据集上进行训练得到的,已经学习到了一些强大且信息丰富的通用的特征表示。这些特征表示可以被用于不同的图像分类任务,通过微调(fine-tuning)的方式,使得模型能够适应特定的任务需求。
使用预训练模型作为起点,通过迁移学习来学习新任务,可以大大加快训练速度,并提高模型的性能。
下图描述了从 K 个分类迁移到 K* 个分类:
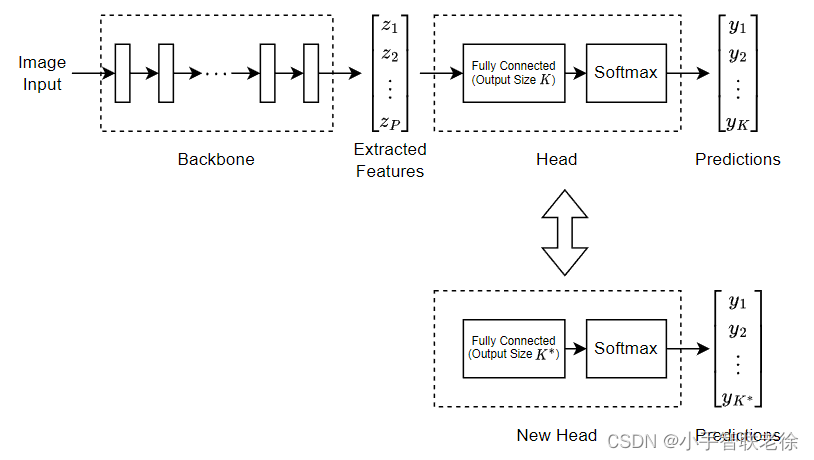
二、常用图像分类预训练模型比较
-
Inception 系列
Inception 系列是由 Google 开发的深度卷积神经网络模型,包括 Inception V3 和 Inception V4 等。这些模型在 ImageNet 数据集上取得了很高的准确度。然而,由于模型结构复杂,Inception 系列的预训练模型文件通常较大。例如,Inception V4 的预训练模型文件大小远大于Inception V3。在训练速度方面,Inception V3 通常比 Inception V4 更快。
-
ResNet 系列
ResNet(残差网络)是由微软研究院开发的深度卷积神经网络模型,通过引入残差连接解决了深度神经网络训练过程中的梯度消失问题。ResNet 系列模型在 ImageNet 数据集上取得了很高的准确度,并且由于其结构相对简单,预训练模型文件大小适中。此外,ResNet 系列模型具有很好的泛化能力,可以方便地适配到其他视觉任务中。
-
EfficientNet 系列
EfficientNet 是一种高效的卷积神经网络模型,通过统一调整网络深度、宽度和分辨率来优化模型性能。EfficientNet 系列模型在 ImageNet 数据集上取得了很高的准确度,并且其预训练模型文件大小相对较小。然而,EfficientNet 系列模型在计算量方面较大,可能导致推理速度较慢。
-
MobileNet 系列
MobileNet 是一种轻量级的卷积神经网络模型,专为移动和嵌入式设备设计。MobileNet 系列模型具有较小的预训练模型文件大小,并且推理速度较快。然而,由于其结构相对简单,MobileNet 系列模型在准确度方面可能稍逊于其他大型模型。
-
Vision Transformer 系列
近年来,Transformer 模型在自然语言处理领域取得了巨大成功,例如 BERT、RoBERTa 等模型。最近,研究者们开始将 Transformer 模型应用于计算机视觉领域,提出了一种新的模型:Vision Transformer(ViT)。
ViT 是一种基于 Transformer 架构的图像分类模型。它将图像分割成固定大小的 patch,然后将每个 patch 视为一个 token,输入到 Transformer 编码器中。ViT 模型使用自注意力机制来捕捉图像中的长期依赖关系,从而实现图像分类任务。
它具有全局感知、平移不变和参数效率等优点。然而,ViT 模型也具有计算成本高和需要大量数据等缺点,是一种非常有前途的图像分类模型。
三、模型大小与准确度权衡
在选择图像分类预训练模型时,需要权衡模型大小和准确度。对于需要快速推理和较小存储空间的场景(如移动应用),可以选择轻量级的模型如 MobileNet 系列。而对于需要较高准确度的场景(如医疗诊断),可以选择大型模型如 ResNet 系列或 EfficientNet 系列。
这些网络已经在一百多万张图像上进行了训练,并能够将图像分类到 1000 个对象类别中,输入是 RGB 图像,输出是预测的标签和得分。
下表是图像分类模型的准确性和大小的比较:
| Network | Size (MB) | Classes | Accuracy % |
| googlenet | 27 | 1000 | 66.25 |
| squeezenet | 5.2 | 1000 | 55.16 |
| alexnet | 227 | 1000 | 54.1 |
| resnet18 | 44 | 1000 | 69.49 |
| resnet50 | 96 | 1000 | 74.46 |
| resnet101 | 167 | 1000 | 75.96 |
| mobilenetv2 | 13 | 1000 | 70.44 |
| vgg16 | 515 | 1000 | 70.29 |
| vgg19 | 535 | 1000 | 70.42 |
| inceptionv3 | 89 | 1000 | 77.07 |
| inceptionresnetv2 | 209 | 1000 | 79.62 |
| xception | 85 | 1000 | 78.2 |
| darknet19 | 78 | 1000 | 74 |
| darknet53 | 155 | 1000 | 76.46 |
| densenet201 | 77 | 1000 | 75.85 |
| shufflenet | 5.4 | 1000 | 63.73 |
| nasnetmobile | 20 | 1000 | 73.41 |
| nasnetlarge | 332 | 1000 | 81.83 |
| efficientnetb0 | 20 | 1000 | 74.72 |
| ConvMixer | 7.7 | 10 | - |
| Vison Transformer (Large-16) | 1100 | 1000 | 85.59 |
| Vison Transformer (Base-16) | 331.4 | 1000 | 85.49 |
| Vison Transformer (Small-16) | 84.7 | 1000 | 83.73 |
| Vison Transformer (Tiny-16) | 22.2 | 1000 | 78.22 |
四、小结
本文介绍了常用图像分类预训练模型的大小和准确度比较。
不同的预训练模型在大小和准确度方面存在差异,需要根据具体需求选择合适的模型。在选择模型时,我们需要权衡模型大小和准确度,以便在满足性能要求的同时实现快速推理和较小的存储空间需求。
老徐,2024/5/28
更多推荐
 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)