
从零开始进行模型微调训练(基于BERT的中文评价情感分析)
如何使用 Hugging Face 的 BERT 模型进行中文评价情感分析的微调训练,从加载数据集、制作 Dataset、词汇表操作、模型设计、自定义训练,到最后的效果评估与测试,逐步讲解了整个微调过程
前言
在掌握了如何使用hugging face上模型的用法包括:如何将模型下载到本地、进行简单的推理,以及如何加载数据集、vocab字典操作,有了模型、数据、编码格式的基本认识后,就可以开始训练定制化的模型,即基于BERT的中文评价情感分析模型。
模型微调的基本概念
微调是指在预训练模型的基础上,通过进一步的训练来适应特定的下游任务。BERT 模型通过预训练来学习语言的通用模式,然后通过微调来适应特定任务,如情感分析、命名实体识别等。微调过程中,通常冻结 BERT 的预训练层,只训练与下游任务相关的层。
准备并载入数据集
情感分析任务的数据通常包括文本及其对应的情感标签。使用 Hugging Face 的 datasets 库可以轻松地加载和处理数据集。
首先下载数据集(需要将整个data文件都下载下来):
链接: https://pan.baidu.com/s/1UWOLi52u-GlKW6D_uMGmmA 提取码: y8a5数据集的text和label分别是评价的内容、消极或者积极评论的标识
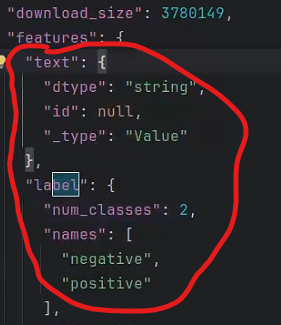
接着载入数据集:
在项目中新建一个python文件并命名MyData用于设计dataset类,使用pytorch进行数据加载:
from torch .utils.data import Dataset
from datasets import load_from_disk #从磁盘导入数据集
设计dataset类(通过pytorch固定模板):
from torch .utils.data import Dataset
from datasets import load_from_disk #从磁盘导入数据集
class MyDataset(Dataset):
#初始化数据
def __init__(self,spilt):#设置一个参数spilt判断要用数据集干什么
#加载从磁盘数据
self.dataset= load_from_disk(r"/home/chn/PycharmProjects/demo_2/data/ChnSentiCorp")
if spilt=="train":
self.dataset=self.dataset["train"]
elif spilt=="validation": #等于验证集
self.dataset=self.dataset["validation"]
elif spilt=="test": #测试集
self.dataset=self.dataset["test"]
else:
print("数据集名称错误!")
#获取数据集大小
def __len__(self):
return len(self.dataset)
#对数据做定制化处理
def __getitem__(self, item):#处理自然语义返回数据和标签对
text=self.dataset[item]["text"]#text从数据集的dataset_info.json里面获得
label=self.dataset[item]["label"]#同上
return text,label
#数据示例: {"text":"诉讼诉讼诉讼诉讼","label":"0"}
if __name__=="__main__":#验证数据集,如果正常加载运行后会输出验证集的内容
dataset=MyDataset("validation")
for data in dataset:
print(data)
正常加载数据集后的输出为:
下游任务模型设计
在微调 BERT 模型之前,需要设计一个适应情感分析任务的下游模型结构。通常包括一个或多个全连接层,用于将 BERT 输出的特征向量转换为分类结果。由于数据只有negative和positive两个分类,所以之后要设计的是二分类的下游模型
模型结构
下游任务模型通常包括以下几个部分:
BERT 模型:用于生成文本的上下文特征向量。
Dropout 层:用于防止过拟合,通过随机丢弃一部分神经元来提高模型的泛化能力。
全连接层:用于将 BERT 的输出特征向量映射到具体的分类任务上。
创建名为net的python文件用于设计模型
#加载预训练模型,由于我指导知道上有上游模型Bert,所以直接调用
from transformers import BertModel
import torch
#定义训练设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
pretrained = BertModel.from_pretrained("/home/chn/PycharmProjects/demo_2/model/bert-base-chinese").to(device)
print(pretrained)
#定义下游任务模型(将主干网络所提取的特征进行分类)
class Model(torch.nn.Module):
#模型结构设计,将768个特征输入进来,得到两个输出做二分类
def __init__(self):
super().__init__()
self.fc=torch.nn.Linear(768,2)#分类任务用全连接来做,bert输出就是全连接特征
def forward(self,input_ids,attention_mask,token_type_ids):#前向推理过程,把bert模型的输入输出搞清楚
#上游任务不参与训练,只需加载
with torch.no_grad():#权重锁死就能不参与训练,这句话的意思是不进行梯度更新
out=pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)#进行前向计算的参数,得到上游人任务的输出
#下游任务参与训练
out=self.fc(out.last_hidden_state[:,0])#传入pretrained输出结果,因为是个序列结果,所以之取最后一层的状态
out=out.softmax(dim=1)
return out模型训练
首先是导入bert模型到GPU上,接着对数据进行编码处理,加载train数据集,使用net中的Model类加载设计好的模型进行训练
import torch
from torch.optim import AdamW
from MyData import MyDataset
from torch.utils.data import DataLoader
from net import Model
from transformers import BertTokenizer,AdamWeightDecay
#定义训练设备
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
EPOCH=100
token=BertTokenizer.from_pretrained("/home/chn/PycharmProjects/demo_2/model/bert-base-chinese")
#自定义函数,对数据进行编码处理,因为数据集里面都是文本,先处理工作量太大
def collate_fn(data):
sentes=[i[0] for i in data]
label =[i[1] for i in data]
#编码
data=token.batch_encode_plus(batch_text_or_text_pairs=sentes,
padding="max_length",
truncation=True,
max_length=350,
return_tensors="pt",
return_length=True)
input_ids=data["input_ids"]
attention_mask=data["attention_mask"]
token_type_ids=data["token_type_ids"]
labels = torch.LongTensor(label)
return input_ids,attention_mask,token_type_ids,labels
#创建数据集
train_dataset = MyDataset("train")
#创建数据加载器,每次加载32条数据,shuffle打乱数据集
train_loader = DataLoader(train_dataset, batch_size=32,
shuffle=True,
drop_last=True,
collate_fn=collate_fn
)
if __name__=="__main__":
#开始训练
print(DEVICE)
model=Model().to(DEVICE)
optimizer=AdamW(model.parameters(),lr=5e-4)#lr是初始学习率,0.0001
loss_func=torch.nn.CrossEntropyLoss()
model.train()
for epoch in range(EPOCH):
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(train_loader):
#将数据放到device上
input_ids, attention_mask, token_type_ids, labels=input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE),labels.to(DEVICE)
#执行向前计算得到输出
out=model(input_ids,attention_mask,token_type_ids)
loss=loss_func(out,labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%5==0:
out=out.argmax(dim=1)
acc=(out==labels).sum().item()/len(labels)
print(epoch,i,loss.item(),acc)
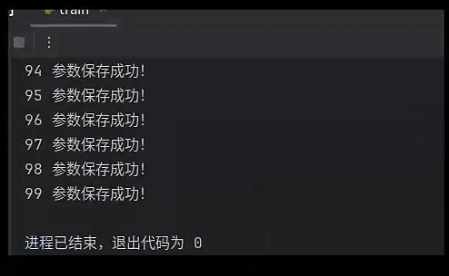
#保存模型参数
torch.save(model.state_dict(),f"params/{epoch}.pt")
print(epoch,"参数保存成功!")
if i%5==0:条件判断,表示每处理5个batch后执行一次监控输出(i是当前batch的序号)
out=out.argmax(dim=1):对模型输出做argmax操作,将预测概率分布转换为预测类别(适用于分类任务),dim=1 表示在特征维度(通常是类别维度)取最大值索引
acc=(out==labels).sum().item()/len(labels)
计算当前batch的准确率:
out==labels 生成布尔张量(预测正确的为True)
.sum() 统计正确预测的数量
.item() 将单值张量转为Python数值
/len(labels) 计算正确率比例
print(epoch,i,loss.item(),acc)输出监控信息,包含:
当前epoch序号
当前batch序号
当前batch的损失值(.item()转换)
当前batch的准确率
典型输出示例:3 15 0.452 0.875 表示第3个epoch的第15个batch,损失值为0.452,准确率87.5%
正常运行的结果:
最终效果评估与测试
在模型训练完成后,需要评估其在测试集上的性能。通常使用准确率、精确率、召回率和 F1 分数等指标来衡量模型的效果。我这里使用精确率来测试。创建名为test的python文件
test代码与train代码类似,都是固定写法,值得注意的是加载train后保存的模型参数文件(params中)使用model.load_state_dict(torch.load("params/99.pt",)),加载的是第99个训练周期。用acc/total来输出精确率
import torch
from torch.optim import AdamW
from MyData import MyDataset
from torch.utils.data import DataLoader
from net import Model
from transformers import BertTokenizer,AdamWeightDecay
#定义训练设备
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
EPOCH=100
token=BertTokenizer.from_pretrained("/home/chn/PycharmProjects/demo_2/model/bert-base-chinese")
#自定义函数,对数据进行编码处理,因为数据集里面都是文本,先处理工作量太大
def collate_fn(data):
sentes=[i[0] for i in data]
label =[i[1] for i in data]
#编码
data=token.batch_encode_plus(batch_text_or_text_pairs=sentes,
padding="max_length",
truncation=True,
max_length=350,
return_tensors="pt",
return_length=True)
input_ids=data["input_ids"]
attention_mask=data["attention_mask"]
token_type_ids=data["token_type_ids"]
labels = torch.LongTensor(label)
return input_ids,attention_mask,token_type_ids,labels
#创建数据集
test_dataset = MyDataset("test")
#创建数据加载器,每次加载32条数据,shuffle打乱数据集
test_loader = DataLoader(test_dataset, batch_size=32,
shuffle=True,
drop_last=True,
collate_fn=collate_fn
)
if __name__=="__main__":
acc=0#精度变量
total=0
#开始测试
print(DEVICE)
model=Model().to(DEVICE)#加载模型
model.load_state_dict(torch.load("params/99.pt",))#加载模型参数
model.eval()#开启测试模式
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(test_loader):
input_ids, attention_mask, token_type_ids, labels=input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE),labels.to(DEVICE)
out=model(input_ids,attention_mask,token_type_ids)
out = out.argmax(dim=1)
acc += (out == labels).sum().item()
total+=len(labels)
print(acc/total)正常运行的结果应该是输出

说明模型效果还不错,不过也和验证集和训练集的数据相关性有关。
部署到本地使用(从命令行输入语句让模型判断)
创建一个名为run的python文件做接口让我们在本队使用该模型。test函数就是实现从命令行输入语句让模型判断最后输出结果
import torch
from net import Model
from transformers import BertTokenizer
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
names=["负向评价","正向评价"]
print("模型加载到:",DEVICE)
model=Model().to(DEVICE)
token=BertTokenizer.from_pretrained("/home/chn/PycharmProjects/demo_2/model/bert-base-chinese")
#自定义函数,对数据进行编码处理,因为数据集里面都是文本,先处理工作量太大
def collate_fn(data):
sentes=[]
sentes.append(data)
#编码
data=token.batch_encode_plus(batch_text_or_text_pairs=sentes,
padding="max_length",
truncation=True,
max_length=350,
return_tensors="pt",
return_length=True)
input_ids=data["input_ids"]
attention_mask=data["attention_mask"]
token_type_ids=data["token_type_ids"]
return input_ids,attention_mask,token_type_ids
def test():
model.load_state_dict(torch.load("params/99.pt"))
model.eval()
while True:
data=input("请输入测试数据(按q退出):")
if data=="q":
print("测试结束")
break
input_ids, attention_mask, token_type_ids = collate_fn(data)
input_ids, attention_mask, token_type_ids = input_ids.to(DEVICE), attention_mask.to(
DEVICE), token_type_ids.to(DEVICE)
with torch.no_grad():
out=model(input_ids,attention_mask,token_type_ids)
out=out.argmax(dim=1)
print("模型判定:",names[out],"\n")
if __name__=="__main__":
test()正常运行结果

总结
本文档作为一个记录防止遗忘,实现的功能很简单,意义在于了解怎么微调怎么缝合模型
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)