
5分钟上手微调大模型 你的第一个大模型Hello Word!零基础入门到精通,看这篇就够了!赶紧收藏!
==文末附原视频地址,请耐心看一遍文档。假设你在 Windows 中有一个文件夹这里 just_train 就是压缩包解压以后的目录这里的意思是 挂载你 的Windows 路径,实在不会写, 像我一样丢给kimi写去.执行命令:./train.sh 开始等待开始等待,目前我的配置是:i7-14700KF64g内存4080 16gb 显卡微调这个0.5b qwen2.5 实际时间大约半小时遇到的问题
===
文末附原视频地址,请耐心看一遍文档。

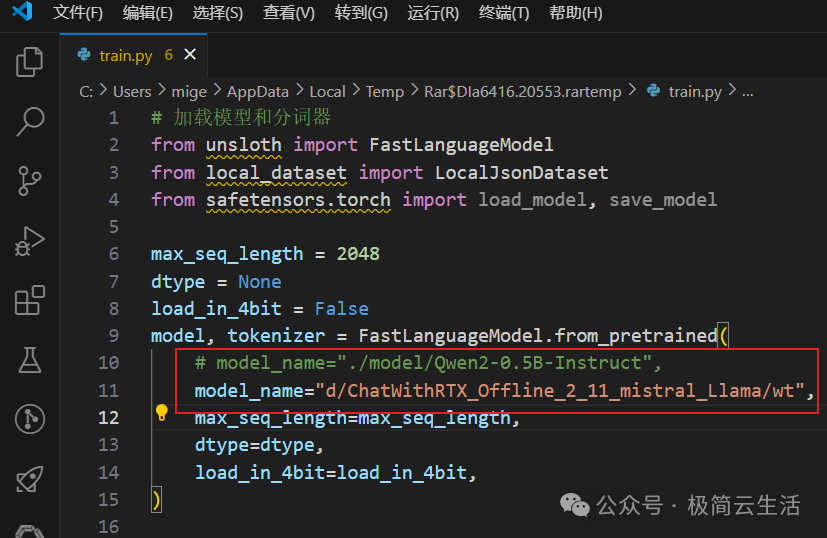
假设你在 Windows 中有一个文件夹 D:\ChatWithRTX_Offline_2_11_mistral_Llama\wt,并且你想在 WSL2 中访问它,可以按照以下步骤操作:
- 打开 WSL2 终端:
- 你可以通过 Windows 的“开始菜单”或搜索栏找到你的 Linux 发行版(如 Ubuntu),然后打开它。
- 导航到对应的目录:在 WSL2 终端中,输入以下命令:
cd /mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train
这里 just_train 就是压缩包解压以后的目录
这里的意思是 挂载你 的Windows 路径,实在不会写, 像我一样丢给kimi写去.

执行命令:
./train.sh 开始等待
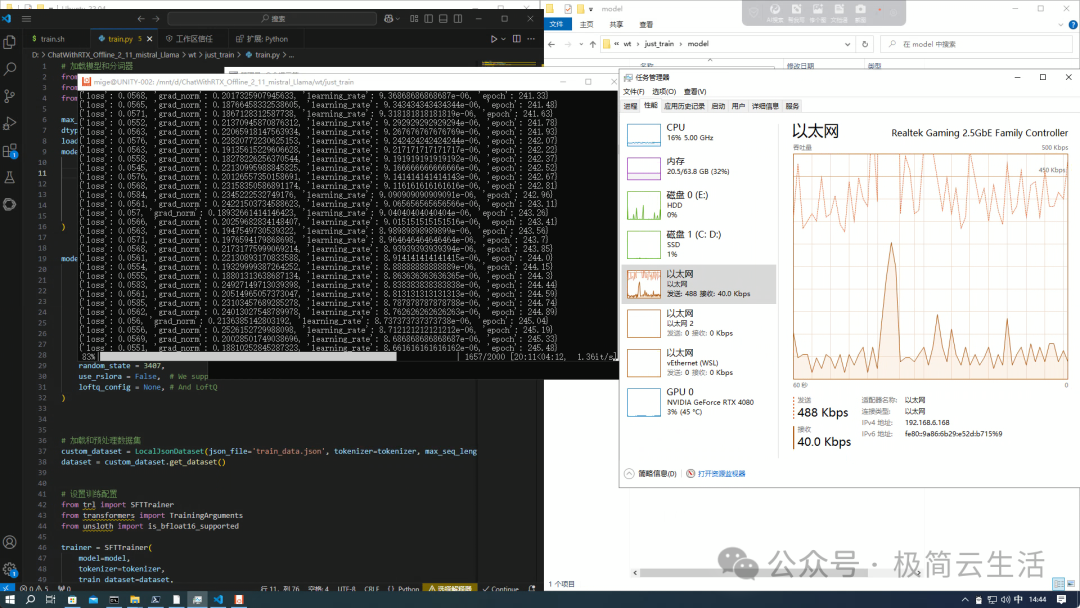
开始等待,目前我的配置是:
i7-14700KF
64g内存
4080 16gb 显卡
微调这个0.5b qwen2.5 实际时间大约半小时
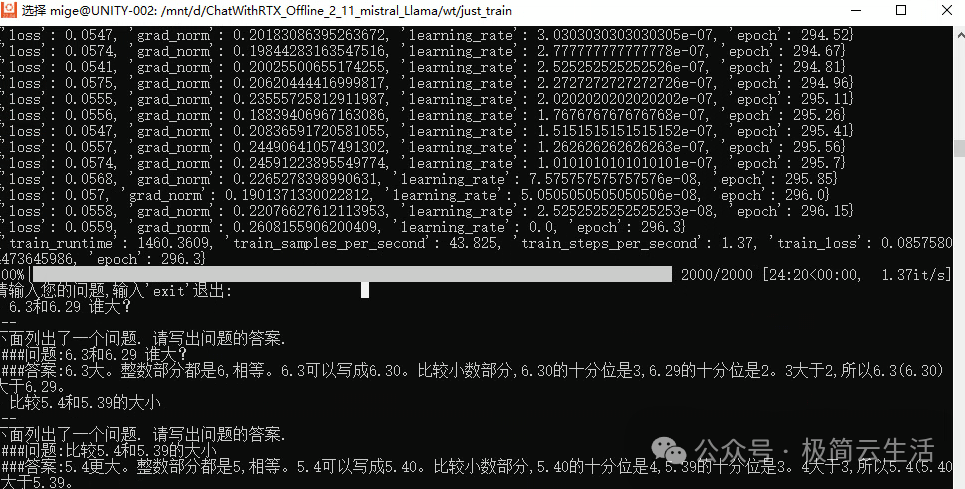
0.5b 的实际效果如下 :
遇到的问题:我用kimi 排查的
问题的核心是 Trizon 在编译 C/C++ 代码时未能找到 C 编译器。以下是一些可能的解决方案:
报错信息:
\`Traceback (most recent call last): File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/train.py", line 73, in <module> trainer.train() File "<string>", line 126, in train File "<string>", line 363, in \_fast\_inner\_training\_loop File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/transformers/trainer.py", line 3318, in training\_step loss = self.compute\_loss(model, inputs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/transformers/trainer.py", line 3363, in compute\_loss outputs = model(\*\*inputs) ^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1532, in \_wrapped\_call\_impl return self.\_call\_impl(\*args, \*\*kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1541, in \_call\_impl return forward\_call(\*args, \*\*kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/accelerate/utils/operations.py", line 819, in forward return model\_forward(\*args, \*\*kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/accelerate/utils/operations.py", line 807, in \_\_call\_\_ return convert\_to\_fp32(self.model\_forward(\*args, \*\*kwargs)) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/torch/amp/autocast\_mode.py", line 16, in decorate\_autocast return func(\*args, \*\*kwargs) ^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/unsloth/models/llama.py", line 957, in PeftModelForCausalLM\_fast\_forward return self.base\_model( ^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1532, in \_wrapped\_call\_impl return self.\_call\_impl(\*args, \*\*kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1541, in \_call\_impl return forward\_call(\*args, \*\*kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/peft/tuners/tuners\_utils.py", line 188, in forward return self.model.forward(\*args, \*\*kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/unsloth/models/llama.py", line 876, in \_CausalLM\_fast\_forward outputs = self.model( ^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1532, in \_wrapped\_call\_impl return self.\_call\_impl(\*args, \*\*kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1541, in \_call\_impl return forward\_call(\*args, \*\*kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/unsloth/models/llama.py", line 713, in LlamaModel\_fast\_forward hidden\_states = Unsloth\_Offloaded\_Gradient\_Checkpointer.apply( ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/torch/autograd/function.py", line 598, in apply return super().apply(\*args, \*\*kwargs) # type: ignore\[misc\] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/torch/cuda/amp/autocast\_mode.py", line 115, in decorate\_fwd return fwd(\*args, \*\*kwargs) ^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/unsloth/models/\_utils.py", line 601, in forward output = forward\_function(hidden\_states, \*args) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1532, in \_wrapped\_call\_impl return self.\_call\_impl(\*args, \*\*kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/torch/nn/modules/module.py", line 1541, in \_call\_impl return forward\_call(\*args, \*\*kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/unsloth/models/llama.py", line 464, in LlamaDecoderLayer\_fast\_forward hidden\_states = fast\_rms\_layernorm(self.input\_layernorm, hidden\_states) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/unsloth/kernels/rms\_layernorm.py", line 190, in fast\_rms\_layernorm out = Fast\_RMS\_Layernorm.apply(X, W, eps, gemma) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/torch/autograd/function.py", line 598, in apply return super().apply(\*args, \*\*kwargs) # type: ignore\[misc\] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/unsloth/kernels/rms\_layernorm.py", line 144, in forward fx\[(n\_rows,)\]( File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/triton/runtime/jit.py", line 167, in <lambda> return lambda \*args, \*\*kwargs: self.run(grid=grid, warmup=False, \*args, \*\*kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/triton/runtime/jit.py", line 363, in run device = driver.get\_current\_device() ^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/triton/runtime/driver.py", line 209, in \_\_getattr\_\_ self.\_initialize\_obj() File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/triton/runtime/driver.py", line 206, in \_initialize\_obj self.\_obj = self.\_init\_fn() ^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/triton/runtime/driver.py", line 239, in initialize\_driver return CudaDriver() ^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/triton/runtime/driver.py", line 102, in \_\_init\_\_ self.utils = CudaUtils() ^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/triton/runtime/driver.py", line 49, in \_\_init\_\_ so = \_build("cuda\_utils", src\_path, tmpdir) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/mnt/d/ChatWithRTX\_Offline\_2\_11\_mistral\_Llama/wt/just\_train/py311/lib/python3.11/site-packages/triton/common/build.py", line 83, in \_build raise RuntimeError("Failed to find C compiler. Please specify via CC environment variable.") RuntimeError: Failed to find C compiler. Please specify via CC environment variable. 0%| | 0/2000 \[00:00<?, ?it/s\]\` 报错了 怎么处理 ?
原话加上, 报错了 怎么处理 ? 丢给kimi,下面输出了处理办法。
1. 安装 C 编译器
确保你的系统中安装了 C 编译器(如 GCC)。在 WSL2 中,可以使用以下命令安装:
bash复制
sudo apt update
sudo apt install build-essential
2. 设置 CC 环境变量
如果 C 编译器已安装但未找到,可以手动设置 CC 环境变量:
bash复制
export CC\=/usr/bin/gcc-11
(/usr/bin/gcc-11 是 GCC 的路径,可以根据你的系统实际情况调整)
3. 检查依赖库
确保以下依赖库已安装:
bash复制
sudo apt install libgomp1
4. 重新启动并尝试
重新启动你的 WSL2 环境并重新运行代码:
bash复制
wsl \--shutdown
wsl
5.Trizon 在wsl 中执行模型微调 效率很慢 需要什么设置么 ?
在 WSL2 中进行模型微调时,如果使用 NVIDIA GPU 并且效率较低,可以尝试以下优化方法:
1. 启用 NVIDIA CUDA 支持
确保你的 WSL2 环境已正确配置 NVIDIA CUDA 支持,以便充分利用 GPU 加速:
- 安装支持 CUDA 的 GPU 驱动程序:
-
下载并安装支持 NVIDIA CUDA 的 WSL 驱动程序。
-
确保驱动程序版本与你的 CUDA 版本兼容。
- 安装 WSL2:
-
确保 WSL2 已启用,并安装基于 glibc 的 Linux 发行版(如 Ubuntu)。
-
确保 WSL2 的内核版本为 5.10.43.3 或更高版本。
- 安装 CUDA Toolkit:
-
在 WSL2 中安装 CUDA Toolkit,确保版本与你的 GPU 驱动程序兼容。
-
例如,运行以下命令安装 CUDA Toolkit:
bash复制
sudo apt update sudo apt install cuda
WSL2 中安装 CUDA 时,直接使用 sudo apt install cuda 命令可能会失败,因为 CUDA 的安装需要特定的步骤和配置。以下是正确的安装方法:
1. 移除旧的 NVIDIA 签名密钥
在安装 CUDA 之前,需要移除旧的 NVIDIA 签名密钥:
bash复制
sudo apt-key del 7fa2af80
2. 安装 CUDA 的 GPG 密钥
下载并安装 CUDA 的 GPG 密钥。根据 NVIDIA 官方文档,可以使用以下命令:
bash复制
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86\_64/cuda-keyring\_1.1-1\_all.deb
sudo dpkg -i cuda-keyring\_1.1-1\_all.deb
3. 更新 APT 软件包列表
更新 APT 的软件包列表,以确保可以找到 CUDA 的安装包:
bash复制
sudo apt update
4. 安装 CUDA Toolkit
安装 CUDA Toolkit:
bash复制
sudo apt install cuda-toolkit
5. 验证安装
安装完成后,可以通过以下命令验证 CUDA 是否安装成功:
bash复制
nvcc --version
如果安装成功,会显示 CUDA 的版本号。
6. 配置环境变量
为了确保系统能够找到 CUDA 的相关库和工具,需要配置环境变量。编辑 ~/.bashrc 文件,添加以下内容:
bash复制
export PATH=/usr/local/cuda/bin:$PATH
export LD\_LIBRARY\_PATH=/usr/local/cuda/lib64:$LD\_LIBRARY\_PATH
然后运行以下命令使环境变量生效:
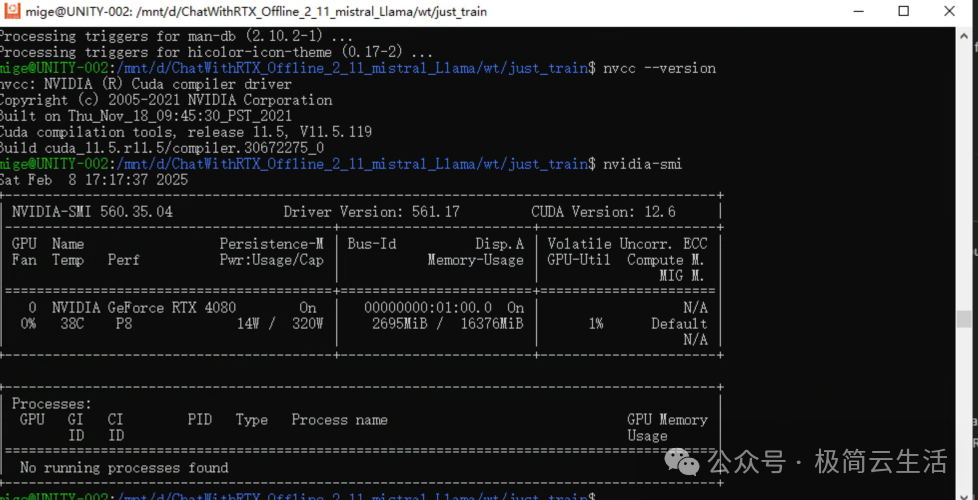
再用 nvidia-smi 验证驱动是否正确加载!
bash复制
source ~/.bashrc
ok nice
7. 重启系统
为了确保所有更改生效,建议重启系统:
bash复制
sudo reboot
或者
wsl \--shutdown
然后
wsl
再执行
nvcc \--version

视频原文:【5分钟学会微调大模型Qwen2】 https://www.bilibili.com/video/BV1BM4m117Jk/?share_source=copy_web&vd_source=a71d7d44d414c834ea4944e7bd912608
懒人包下载地址: 链接:https://pan.baidu.com/s/1nHs1WEzbC64GiKbNqiWpJw?pwd=4pje 预训练模型在model文件夹中,大家也可以下载其他的模型放到这个文件夹里面微调哦 (需要修改train.py 第10行的模型路径)
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
5.免费获取
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码或者点击以下链接都可以免费领取【保证100%免费】

本文转自 https://mp.weixin.qq.com/s/Fm-O-uL5p0FUKh2-J2A_0w,如有侵权,请联系删除。
更多推荐
 32
32 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)