
一文讲清楚大模型预训练、后训练、微调,看这一篇就够了!
最近,DeepSeek悄悄做了一次更新,发布了一个小版本:DeepSeek-V3-0324。
最近,DeepSeek悄悄做了一次更新,发布了一个小版本:DeepSeek-V3-0324。

这个版本大幅提高了在推理类任务上的表现水平,在数学、代码类相关评测集上取得了超过 GPT-4.5 的得分成绩。
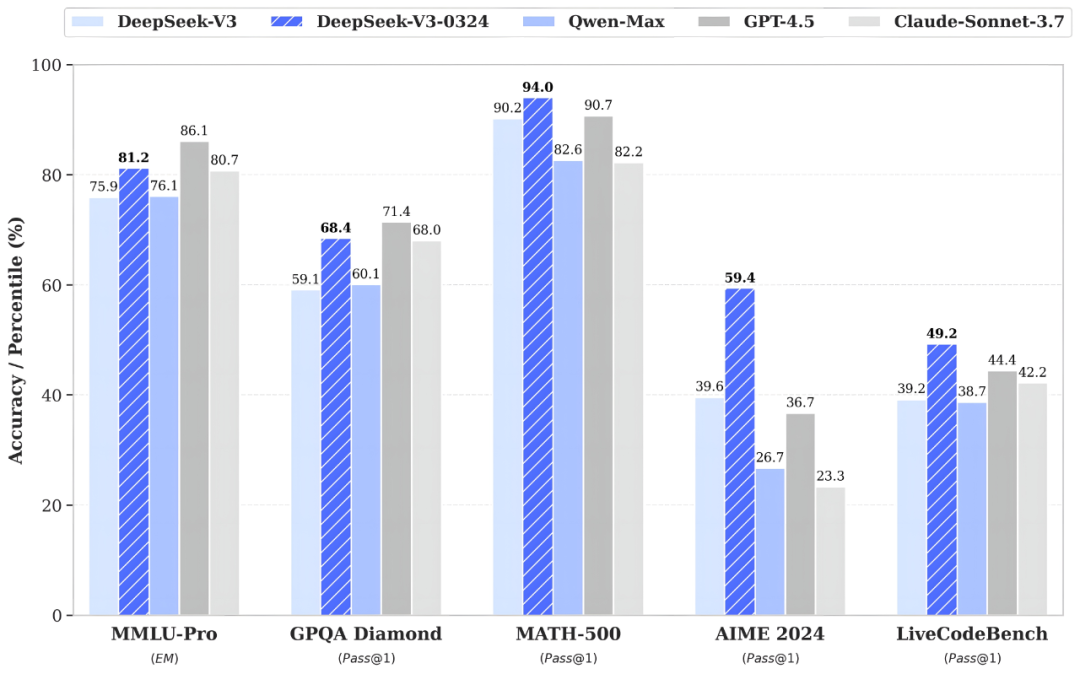
怎么做到的呢?DeepSeek官方文档是这么说↓
新版 V3 模型借鉴 DeepSeek-R1 模型训练过程中所使用的强化学习技术,与之前的 DeepSeek-V3 使用同样的 base 模型,仅改进了后训练方法。
这里面提到了一个词:后训练。
啥是后训练,跟预训练有啥区别?
今天我们用最通俗的比喻,来讲讲大模型三个不同阶段的训练方法:❶预训练(Pre-training)❷后训练(Post-training)❸微调(Fine-tuning)。
1、先看预训练
预训练就是用大量的通用数据集先训练模型,让它掌握基础知识和技能(通用语言能力和世界常识,比如刚发布的Llama 4在200种语言上进行预训练)。
这就好比我们的中小学阶段,系统地学习语文、数学、英语等基础学科知识。

这个阶段数据规模庞大,训练成本高,周期长(数万GPU天),比如Llama 4 Scout预训练就使用了40万亿tokens数据。
想想我们小时候刷过的题、吃过的苦、花费的时间、挨过的骂……
预训练的成本和时间一下子就具象化了。

2、再说后训练
后训练是指在预训练完成后的进一步训练阶段,目的在于让模型更好地适应实际的特定任务或应用场景。
这就好比高中毕业(预训练结束),考上大学,有了明确的专业方向,开始强化专业知识。

后训练阶段,数据规模小,通常是特定领域的数据(专业基础课和专业课),训练周期短(修够学分就行)。
回想一下你的大学生活,是不是比以前轻松多了。

不过,后训练往往不止一次,可能要根据实际需求,持续深造,不断优化。
这就好比我们上完本科,可能还要硕士、博士,持续深造,让自己的专业能力越来越扎实。
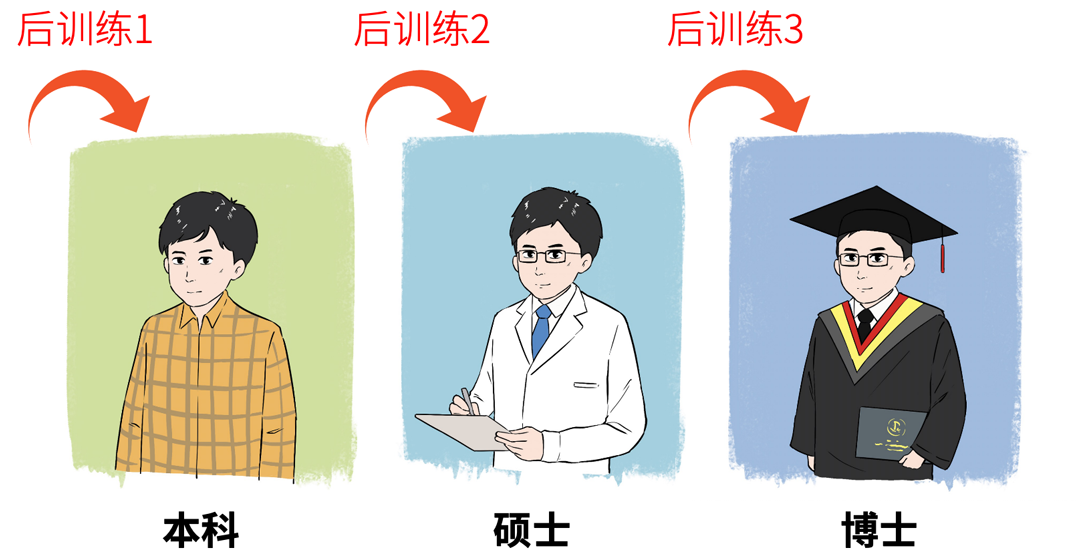
目前,在模型后训练环节,比较流行的是采用强化学习(RL:Reinforcement Learning)的方法。比如在DeepSeek-V3小版本发布的通告里,就特别指出了自己采用了强化学习进行后训练。
简单讲,强化学习就后训练的过程中不断告诉模型:①你做得好,继续保持(给正反馈);②你做的不好,赶紧改正(给负反馈)。

通过这种“奖惩机制”,让模型学习更有针对性,表现也更好。
但是这种”打一巴掌、给个甜枣“的方法,有时候会把模型心态搞崩,太过于追求奖励的结果了而走极端。

所以,为了避免走极端,最近流行一种新的强化学习方法,叫做GRPO(引导式正则化策略优化),比如DeepSeek R1的训练就采用了这种方法。
GRPO就是在传统强化学习的奖励机制之上,加入一个额外的约束(正则项),确保和最初的“比较好的模型”不会差距太大。

这样模型就可以平稳地进步,既能拿到高奖励,又不会走极端。
如此,GRPO成了当下大模型后训练中,最流行的强化学习手段,能更安全、稳定地提升AI的表现,生成的内容更符合人类喜欢的风格和预期。

3、最后说说微调
严格来讲,把微调单拎出来讲并不科学,因为微调其实也是模型「后训练」的一种方法。
不过,一般后训练(像前面说的强化学习方法),发生在模型提供商那里。模型提供商在「预训练」完成以后,通过多次「后训练」优化,最终把模型打造成可交付的产品或服务。

而微调这种「后训练」,通常发生在模型使用者那里(尤其是行业客户场景)。
只因出徒后的大模型虽然基础知识丰富、专业能力一流,可是实战技巧却是空白,到了行业场景没法直接上岗。
比如——

怎么办呢?进行上岗培训,这就是微调。
微调是针对特定任务(修电脑)的训练,数据量小但很精准、具体,老司机会把他的具体修理经验交给你,让你的知识更接地气。

至此,一个大模型经过预训练、后训练、微调。
终于可以上岗干活啦。

简单总结下↓
预训练: 基础知识广泛学;
后训练: 专业领域深入学;
微调: 具体实操岗前学。

好了,基本概念介绍完毕。
从目前的国内的趋势看,做大规模预训练的公司会越来越少(坊间传闻,今年上半年真正在做预训练的公司只有两三家)。
未来训练方面的主要需求都是后训练和微调(当然更大的需求是推理)。
可是说,随着DeepSeek的半路杀出,国内大模型战役的第一阶段,已经结束,“裸泳者”即将浮出水面。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)