
Ai大模型学习第一课:增量微调中的适配器微调(Adapter)
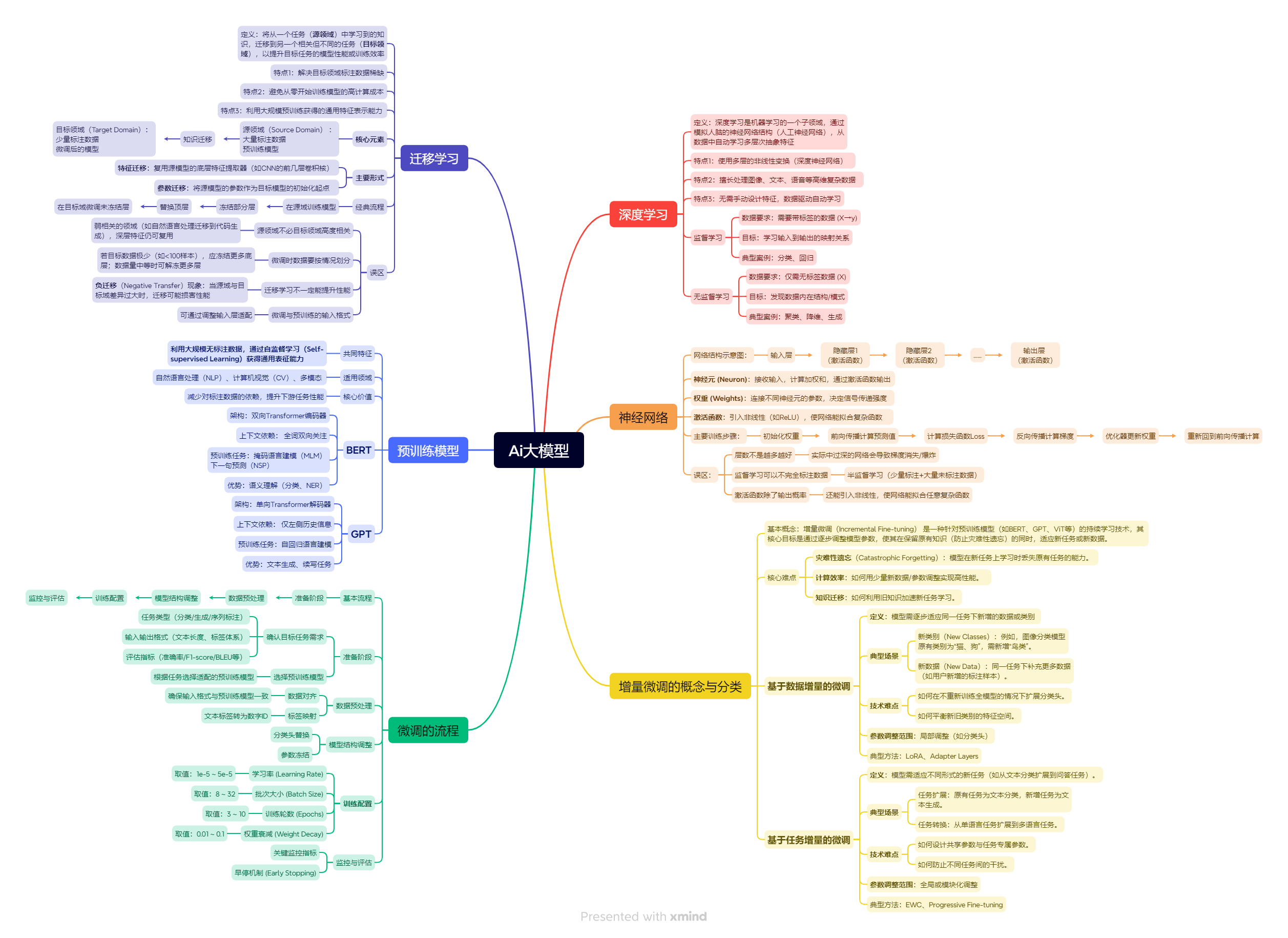
增量微调(Incremental Fine-tuning)是一种针对预训练模型的持续学习技术,旨在通过逐步调整模型参数,使其在保留原有知识的同时适应新任务或新数据。与传统微调相比,增量微调分阶段调整参数以适应多任务或多数据,避免了灾难性遗忘,并允许数据和任务的动态扩展。其核心挑战包括灾难性遗忘、计算效率和知识迁移。适配器微调是增量微调的基础技术,通过在预训练模型中插入小型可训练模块(Adapter
目录
1.深度学习技术基础
在进入增量微调的学习之前,需要具备一定的深度学习基础,对此在这里简单介绍一遍笔者所了解的深度学习。
2.增量微调的核心定义
2.1基本概念
增量微调(Incremental Fine-tuning) 是一种针对预训练模型(如BERT、GPT、ViT等)的持续学习技术,其核心目标是通过逐步调整模型参数,使其在保留原有知识(防止灾难性遗忘)的同时,适应新任务或新数据。
2.2与传统微调的区别
| 传统微调 | 增量微调 |
| 一次性调整所有参数以适应单一任务 | 分阶段调整参数以适应多任务/多数据 |
| 可能覆盖原有知识(灾难性遗忘) | 保留原有知识并整合新知识 |
| 依赖完整数据集(静态) | 允许数据/任务动态扩展(动态) |
2.3核心挑战
- 灾难性遗忘(Catastrophic Forgetting):模型在新任务上学习时丢失原有任务的能力。
- 计算效率:如何用少量新数据/参数调整实现高性能。
- 知识迁移:如何利用旧知识加速新任务学习。
2.4增量微调的技术分类
本文主要讲解适配器微调,也是最基础的增量微调,在这里对增量微调的技术分类做一个简单的总结。
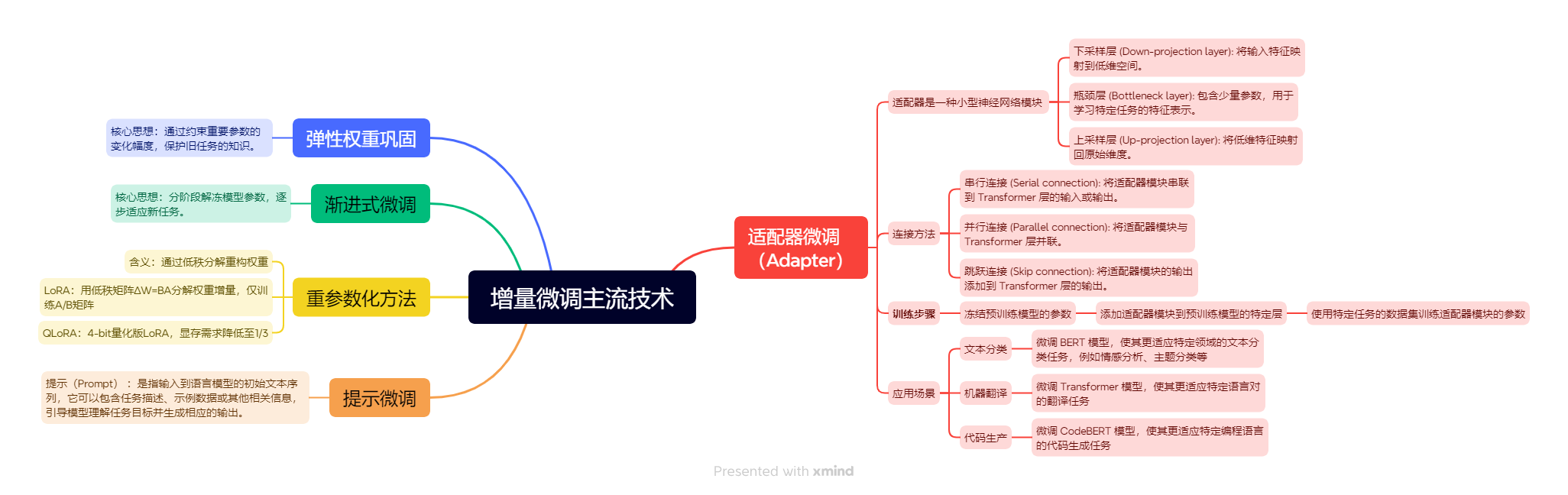
3.适配器(Adapter Layers)
3.1核心思想
在预训练模型的层中插入小型可训练模块(Adapter),冻结原始参数,仅训练Adapter部分。核心思路就是冻结预训练模型的参数,让其不参与模型训练,这能有效降低训练参数,提高训练效率。
3.2基本结构
适配器是一种轻量级可插入模块,通常由两个全连接层(降维+升维)和残差连接组成。以下以Transformer模型为例:
-
插入位置:Transformer层的两个子模块之后:
- 自注意力层(Self-Attention)之后
- 前馈网络(FFN)之后
-
数学公式:
- 输入特征
,适配器输出为:
- 输入特征
其中:
:降维矩阵(
≪
)
:升维矩阵
- Activation:激活函数(如GELU/ReLU)
3.3优势场景
3.3.1多任务学习
适用原因:
1.参数隔离:每个任务独立使用一个适配器,共享主干模型参数,避免任务间干扰。
2.低成本扩展:新增任务时仅需训练新适配器(约1%参数量),无需存储多个完整模型副本。
典型案例:
1.多语言模型:同一模型支持英语、中文、西班牙语的情感分析,每个语言对应一个适配器。
2.多模态任务:视觉-语言模型中,适配器分别处理图像描述生成(Captioning)和视觉问答(VQA)。
3.3.2持续学习
适用原因:
1.灾难性遗忘防御:冻结主干参数,仅更新适配器,保留原有知识。
2.增量扩展能力:逐步添加适配器适应新任务,无需回滚旧数据。
典型案例:
1.电商平台商品分类扩展:初始模型支持“服装”分类,新增“电子产品”类时,仅训练新适配器。
2.法律文本分析:从合同审查扩展到法律条款问答,逐步插入适配器。
3.3.3跨领域/跨语言迁移
适用原因:
1.领域自适应:适配器学习领域特征,主干模型保留通用语言理解能力。
2.零样本迁移:通过组合适配器实现跨语言/跨领域知识迁移。
典型案例:
1.跨语言迁移:谷歌的MAD-X框架,用语言适配器(Language Adapter)+任务适配器实现零样本跨语言任务(如用英语训练的问答适配器+中文语言适配器处理中文问答)。
2.领域迁移:金融领域适配器 + 通用BERT模型,用于财报情感分析。
4.增量微调简单实践
在进行增量微调实践前,我们要进行一些准备,包括数据集与预训练模型,所谓微调,就是在预训练模型的基础上进行调整。
4.1数据集
from torch.utils.data import Dataset
from datasets import load_from_disk
class MyDataset(Dataset):
#初始化数据集
def __init__(self,split):
#从磁盘加载数据
self.dataset = load_from_disk(r"/home/ubuntu/demo/demo_02/data/ChnSentiCorp")
if split == "train":
self.dataset = self.dataset["train"]
elif split == "test":
self.dataset = self.dataset["test"]
elif split == "validation":
self.dataset = self.dataset["validation"]
else:
print("数据名错误!")
#返回数据集长度
def __len__(self):
return len(self.dataset)
#对每条数据单独做处理
def __getitem__(self, item):
text = self.dataset[item]["text"]
label = self.dataset[item]["label"]
return text,label
if __name__ == '__main__':
dataset = MyDataset("train")
for data in dataset:
print(data)这里需要强调一点的是,在python中进行路径读取时,为了防止其将路径判断成字符串,所以要在绝对路径之前加上字母r来进行强调。
4.2定义增量模型
import torch
from transformers import BertModel
#定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(DEVICE)
#加载预训练模型
pretrained = BertModel.from_pretrained(r"/home/ubuntu/demo/demo_02/model/bert-base-chinese/models--bert-base-chinese/snapshots/c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f").to(DEVICE)
print(pretrained)
#定义下游任务(增量模型)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
#设计全连接网络,实现二分类任务
self.fc = torch.nn.Linear(768,2)
#使用模型处理数据(执行前向计算)
def forward(self,input_ids,attention_mask,token_type_ids):
#冻结Bert模型的参数,让其不参与训练
with torch.no_grad():
out = pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
#增量模型参与训练
out = self.fc(out.last_hidden_state[:,0])
return out在增量微调中,最重要的一定就是冻结预训练模型的参数,不让其参与训练,仅仅只训练增量模型,实现对模型的微调。
4.3模型训练
#模型训练
import torch
from MyData import MyDataset
from torch.utils.data import DataLoader
from net import Model
from transformers import BertTokenizer
from torch.optim import AdamW
#定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#定义训练的轮次(将整个数据集训练完一次为一轮)
EPOCH = 30000
#加载字典和分词器
token = BertTokenizer.from_pretrained(r"/home/ubuntu/demo/demo_02/model/bert-base-chinese/models--bert-base-chinese/snapshots/c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
#将传入的字符串进行编码
def collate_fn(data):
sents = [i[0]for i in data]
label = [i[1] for i in data]
#编码
data = token.batch_encode_plus(
batch_text_or_text_pairs=sents,
# 当句子长度大于max_length(上限是model_max_length)时,截断
truncation=True,
max_length=512,
# 一律补0到max_length
padding="max_length",
# 可取值为tf,pt,np,默认为list
return_tensors="pt",
# 返回序列长度
return_length=True
)
input_ids = data["input_ids"]
attention_mask = data["attention_mask"]
token_type_ids = data["token_type_ids"]
label = torch.LongTensor(label)
return input_ids,attention_mask,token_type_ids,label
#创建数据集
train_dataset = MyDataset("train")
train_loader = DataLoader(
dataset=train_dataset,
#训练批次
batch_size=90,
#打乱数据集
shuffle=True,
#舍弃最后一个批次的数据,防止形状出错
drop_last=True,
#对加载的数据进行编码
collate_fn=collate_fn
)
if __name__ == '__main__':
#开始训练
print(DEVICE)
model = Model().to(DEVICE)
#定义优化器
optimizer = AdamW(model.parameters())
#定义损失函数
loss_func = torch.nn.CrossEntropyLoss()
for epoch in range(EPOCH):
for i,(input_ids,attention_mask,token_type_ids,label) in enumerate(train_loader):
#将数据放到DVEVICE上面
input_ids, attention_mask, token_type_ids, label = input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE),label.to(DEVICE)
#前向计算(将数据输入模型得到输出)
out = model(input_ids,attention_mask,token_type_ids)
#根据输出计算损失
loss = loss_func(out,label)
#根据误差优化参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
#每隔60个批次输出训练信息
if i%60 ==0:
out = out.argmax(dim=1)
#计算训练精度
acc = (out==label).sum().item()/len(label)
print(f"epoch:{epoch},i:{i},loss:{loss.item()},acc:{acc}")
if epoch%50 == 0 and epoch!=0:
#每训练完五十轮,保存一次参数
torch.save(model.state_dict(),f"params/{epoch}_bert.pth")
print(epoch,"参数保存成功!")
if epoch%1000 == 0 and epoch!=0:
#平均一小时五十轮,定时二十个小时
exit()
4.4模型评估
#模型评估
import torch
from MyData import MyDataset
from torch.utils.data import DataLoader
from net import Model
from transformers import BertTokenizer
from torch.optim import AdamW
#定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#加载字典和分词器
token = BertTokenizer.from_pretrained(r"/home/ubuntu/demo/demo_03/model/bert-base-chinese/models--bert-base-chinese/snapshots/c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
#将传入的字符串进行编码
def collate_fn(data):
sents = [i[0]for i in data]
label = [i[1] for i in data]
#编码
data = token.batch_encode_plus(
batch_text_or_text_pairs=sents,
# 当句子长度大于max_length(上限是model_max_length)时,截断
truncation=True,
max_length=512,
# 一律补0到max_length
padding="max_length",
# 可取值为tf,pt,np,默认为list
return_tensors="pt",
# 返回序列长度
return_length=True
)
input_ids = data["input_ids"]
attention_mask = data["attention_mask"]
token_type_ids = data["token_type_ids"]
label = torch.LongTensor(label)
return input_ids,attention_mask,token_type_ids,label
#创建数据集
test_dataset = MyDataset("test")
test_loader = DataLoader(
dataset=test_dataset,
#训练批次
batch_size=100,
#打乱数据集
shuffle=True,
#舍弃最后一个批次的数据,防止形状出错
drop_last=True,
#对加载的数据进行编码
collate_fn=collate_fn
)
if __name__ == '__main__':
acc = 0.0
total = 0
#开始测试
print(DEVICE)
model = Model().to(DEVICE)
#加载模型训练参数
model.load_state_dict(torch.load(r"/home/ubuntu/demo/demo_02/params/1000_bert.pth"))
#开启测试模式
model.eval()
for i,(input_ids,attention_mask,token_type_ids,label) in enumerate(test_loader):
#将数据放到DVEVICE上面
input_ids, attention_mask, token_type_ids, label = input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE),label.to(DEVICE)
#前向计算(将数据输入模型得到输出)
out = model(input_ids,attention_mask,token_type_ids)
out = out.argmax(dim=1)
acc += (out==label).sum().item()
print(i,(out==label).sum().item())
total+=len(label)
print(f"test acc:{acc/total}")
# print(out.argmax(dim=1))
# print(label)
# exit()4.5模型预测
#模型使用接口(主观评估)
#模型训练
import torch
from net import Model
from transformers import BertTokenizer
#定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#加载字典和分词器
token = BertTokenizer.from_pretrained(r"/home/ubuntu/demo/demo_01/model/bert-base-chinese/models--bert-base-chinese/snapshots/c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
model = Model().to(DEVICE)
names = ["负向评价","正向评价"]
#将传入的字符串进行编码
def collate_fn(data):
sents = []
sents.append(data)
#编码
data = token.batch_encode_plus(
batch_text_or_text_pairs=sents,
# 当句子长度大于max_length(上限是model_max_length)时,截断
truncation=True,
max_length=512,
# 一律补0到max_length
padding="max_length",
# 可取值为tf,pt,np,默认为list
return_tensors="pt",
# 返回序列长度
return_length=True
)
input_ids = data["input_ids"]
attention_mask = data["attention_mask"]
token_type_ids = data["token_type_ids"]
return input_ids,attention_mask,token_type_ids
def test():
#加载模型训练参数
model.load_state_dict(torch.load(r"/home/ubuntu/demo/demo_02/params/1000_bert.pth"))
#开启测试模型
model.eval()
while True:
data = input("请输入测试数据(输入‘q’退出):")
if data=='q':
print("测试结束")
break
input_ids,attention_mask,token_type_ids = collate_fn(data)
input_ids, attention_mask, token_type_ids = input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE)
#将数据输入到模型,得到输出
with torch.no_grad():
out = model(input_ids,attention_mask,token_type_ids)
out = out.argmax(dim=1)
print("模型判定:",names[out],"\n")
if __name__ == '__main__':
test()更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)