
【喂饭教程】LoRA微调Qwen3 Embedding,全程干货,小白也能轻松学会!!
最近 Qwen 又有大动作,发布 Qwen3 Embedding 系列模型,而且 MTEB 排行榜上获取多个第一,最重要的还是模型全系列开源。不得不说 Qwen 可能已经完成 rag(Retrieval-Augmented Generation)技术栈的大一统了。以后 Retrieval 部分:语义召回可以使用 Qwen3 Embeding召回排序可以使用 Qwen3 Reranking
前言
最近 Qwen 又有大动作,发布 Qwen3 Embedding 系列模型,而且 MTEB 排行榜上获取多个第一,最重要的还是模型全系列开源。
不得不说 Qwen 可能已经完成 rag(Retrieval-Augmented Generation)技术栈的大一统了。
以后 Retrieval 部分:
- 语义召回可以使用 Qwen3 Embeding
- 召回排序可以使用 Qwen3 Reranking
Generation 部分:
- 问答生成可以使用 Qwen3 Chat
真香啊,接下来笔者会简单介绍一下 Qwen3 Embedding 系列模型,同时实战将 Qwen3 Embeding 的向量模型采用 lora 的方式微调成一个领域 Embeding 模型,让模型在这个领域的语义搜索性能进一步提升。
其中涉及到:
- 难负样本的挖掘的方案
- infoNCEloss 的原理
- ms-swift 微调 Qwen3 Embedding 的实战
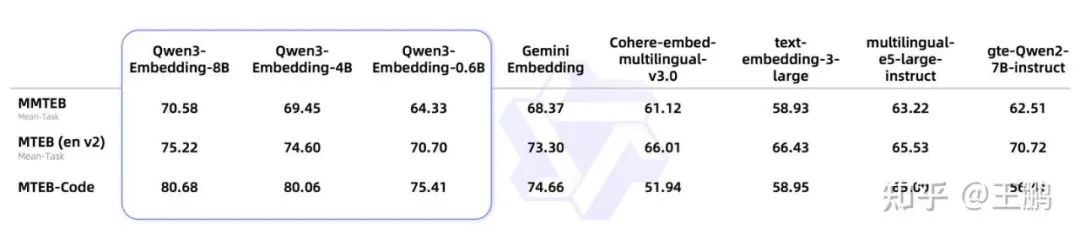
01、Qwen3 Embedding 系列模型
主要有两个系列,一个 embedding 模型系列,一个 Reranking 模型系列。
Embeding 模型: 以单个文本片段作为输入,通过利用与最终[结束符]([EOS])标记对应的隐藏状态向量来提取语义表示。
Reranking 模型: 文本对(例如用户查询与候选文档)作为输入,抽取最后一层的,yes 和 no 这两个 token 的 logit 取 log_softmax 后,取 yes 所在位置的分数作为 score。
token_false_id = tokenizer.convert_tokens_to_ids("no")token_true_id = tokenizer.convert_tokens_to_ids("yes")def compute_logits(inputs, **kwargs): batch_scores = model(**inputs).logits[:, -1, :] true_vector = batch_scores[:, token_true_id] false_vector = batch_scores[:, token_false_id] batch_scores = torch.stack([false_vector, true_vector], dim=1) batch_scores = torch.nn.functional.log_softmax(batch_scores, dim=1) scores = batch_scores[:, 1].exp().tolist() return scores
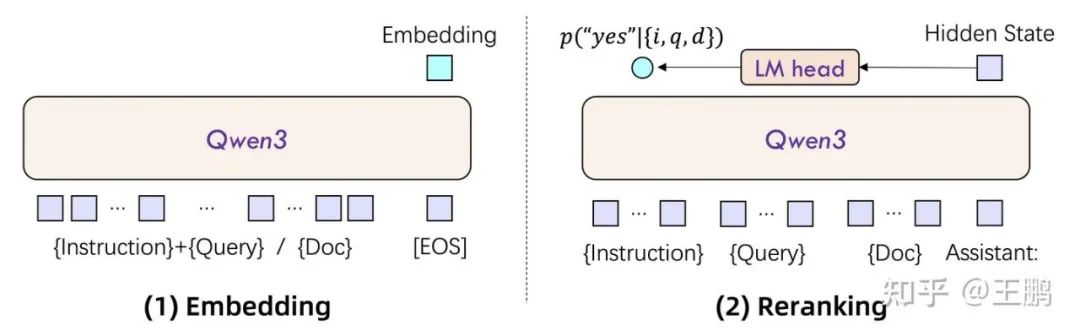
qwen3 embeding 和 reranking
02、训练方法
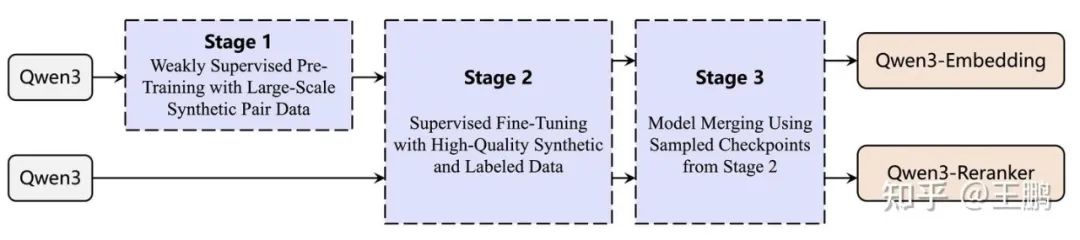
三阶段分层训练机制:
- 对比预训练阶段:使用海量弱监督数据打底,增强模型泛化能力
- 精调阶段:采用高质量标注数据进行监督训练,提升任务适配性
- 模型融合阶段:通过集成策略合并多个候选模型,实现性能突破
下面废话不多说,实战微调 Qwen3-Embedding-0.6B,将这个通用的 embedding 模型变成一个农林牧渔领域垂域的 embedding 模型。
03、Lora 微调 Qwen3 Embedding 模型实战
(1)负样本和 loss
负样本的构建
我们都知道,训练模型数据最重要,其中这种 embedding 和 reranker 模型,负样本的构建算是重中之重。
这里笔者用 sentence_transformer 库中自带的 mine_hard_negatives 挖掘负样本,调整参数挑选出那些相似但不相关的样本。
数据来自这:农林牧渔中文问答数据
https://huggingface.co/datasets/Mxode/Chinese-QA-Agriculture_Forestry_Animal_Husbandry_Fishery
主要采用下方流程:
相似度计算和候选生成:通过恶 embedding 模型或者 reranker 模型,计算查询与语料库的相似度,获取 top-k 最相似的候选。
负样本的挑选:排除正例,应用各种筛选条件对负样本进行挑选:
- absolute_margin:绝对相似度差异阈值
- relative_margin:相对相似度比例阈值
- max_score/min_score:相似度分数阈值
可以根据向量模型或者 reranker 的输出值去动态调整这些参数,挑选出合适的负样本。
from datasets import load_datasetfrom sentence_transformers import SentenceTransformerfrom sentence_transformers.util import mine_hard_negativesdataset = load_dataset("parquet", data_files="/mnt/d/wsl/work/jupyter/data_hub/Chinese-QA-Agriculture/Chinese-QA-AFAF-train-v2.parquet")split_dataset = dataset["train"].train_test_split(test_size=0.95, seed=42)# 输出划分后的数据集信息print("划分后的数据集:", split_dataset)print(f"训练集大小: {len(split_dataset['train'])}")print(f"测试集大小: {len(split_dataset['test'])}")# 加载小的embeding模型embedding_model = SentenceTransformer("/mnt/d/wsl/work/jupyter/model_hub/m3e-small")train_dataset = split_dataset['train']#挖掘难负样本hard_train_dataset = mine_hard_negatives( train_dataset, embedding_model, anchor_column_name="prompt", positive_column_name="response", num_negatives=5, # How many negatives per question-answer pair range_min=20, # Skip the x most similar samples range_max=50, # Consider only the x most similar samples max_score=0.8, # Only consider samples with a similarity score of at most x absolute_margin=0.1, # Similarity between query and negative samples should be x lower than query-positive similarity sampling_strategy="top", # Randomly sample negatives from the range batch_size=64, # Use a batch size of 4096 for the embedding model output_format="labeled-list", use_faiss=True, # Using FAISS is recommended to keep memory usage low (pip install faiss-gpu or pip install faiss-cpu))def convert_format(example): # 获取正确答案和被拒绝的答案 correct_response = next(resp for resp, label in zip(example['response'], example['labels']) if label == 1) rejected_responses = [resp for resp, label in zip(example['response'], example['labels']) if label == 0] return { "query": example['prompt'], "response": correct_response, "rejected_response": rejected_responses }# 数据格式转换transformed_dataset = hard_train_dataset.map(convert_format, remove_columns=hard_train_dataset.column_names)transformed_dataset.to_json("./data_hub/qwen3_emb.json",force_ascii=False)
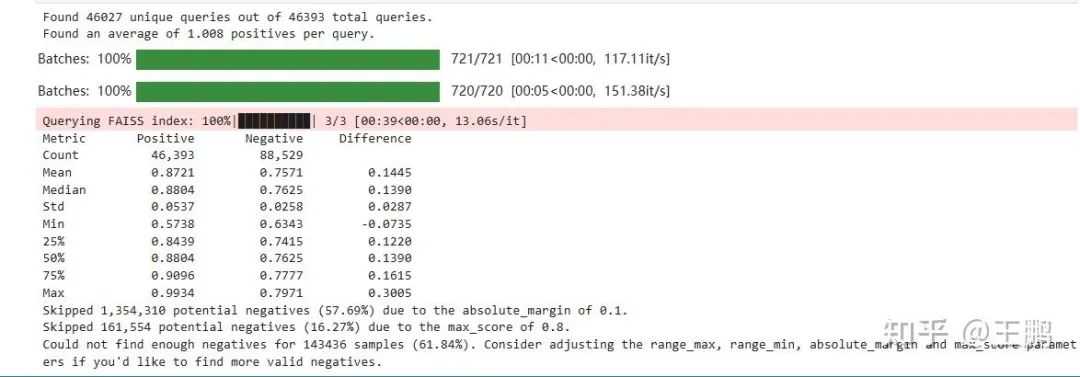
最终统计结果
负样本和正样本在 m3e 这个模型的平均相似度是 0.87 和 0.75。
可以看一条筛选出来的样本:确实很多样本和 query 很相似,但是不相关。
{'response': '绿色环境可以帮助老年人放松紧张的中枢神经,改善和调节身体功能,降低皮肤温度,减少脉搏和呼吸频率,保持血压稳定,减轻心脏负担,提供精神舒适感。这对于冠心病、高血压患者以及身体机能退化的老年人尤为有益。', 'query': '绿色对老年人有哪些健康益处?', 'rejected_response': ['绿茶的主要功效是预防癌症和心血管疾病,还能抗氧化,提高免疫力,抑制和杀灭细菌等;白茶的主要功效有保护脑神经,增强记忆,减少焦虑等。', '绿茶水洗脸可以防止肌肤衰老,抗辐射,尤其适合长期用电脑的女性,可抑制皮肤色素沉着,减少过敏反应的发生。', '绿色食物代表有花椰菜,菠菜,芦笋。它们具有超强的减肥功效,每杯绿果蔬的热量还不到50千卡,适合于大量食用;它们含有的抗氧化剂具有延长寿命的功效。', '生态养殖可以改善肉、蛋、奶品质,能生产出天然绿色食品。', '绿水对锦鲤有发色和提供营养的作用,还能对锦鲤有一定的康复作用。锦鲤在游动时可能会遇到小的擦伤,将鱼放在绿水中进行调养可以促进康复。']}
(2)InfoNCE Loss
loss 采用的是带有负样本的 InfoNCE Loss:
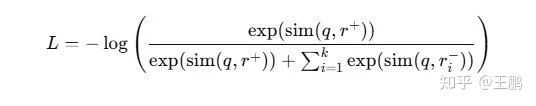
其中:
- q 是 query 的 embedding;
- r+ 是对应正样本的 embedding,r- 是对应负样本的 embedding;
- sim 是点积(或 cosine)
这个 loss 惩罚 query 跟负样本更相似的情况,鼓励 query 跟正样本相似度更高。
04、训练实战
数据格式如下: response 为正样本,rejected_response 为负样本。
{'response': '绿色环境可以帮助老年人放松紧张的中枢神经,改善和调节身体功能,降低皮肤温度,减少脉搏和呼吸频率,保持血压稳定,减轻心脏负担,提供精神舒适感。这对于冠心病、高血压患者以及身体机能退化的老年人尤为有益。', 'query': '绿色对老年人有哪些健康益处?', 'rejected_response': ['绿茶的主要功效是预防癌症和心血管疾病,还能抗氧化,提高免疫力,抑制和杀灭细菌等;白茶的主要功效有保护脑神经,增强记忆,减少焦虑等。', '绿茶水洗脸可以防止肌肤衰老,抗辐射,尤其适合长期用电脑的女性,可抑制皮肤色素沉着,减少过敏反应的发生。', '绿色食物代表有花椰菜,菠菜,芦笋。它们具有超强的减肥功效,每杯绿果蔬的热量还不到50千卡,适合于大量食用;它们含有的抗氧化剂具有延长寿命的功效。', '生态养殖可以改善肉、蛋、奶品质,能生产出天然绿色食品。', '绿水对锦鲤有发色和提供营养的作用,还能对锦鲤有一定的康复作用。锦鲤在游动时可能会遇到小的擦伤,将鱼放在绿水中进行调养可以促进康复。']}
训练脚本
比较重要的三个参数:
- –task_type embedding
- –model_type qwen3_emb
- –loss_type infonce
INFONCE_MASK_FAKE_NEGATIVE=trueswift sft \ --model /mnt/d/wsl/work/jupyter/model_hub/Qwen3-Embedding-0.6B \ --task_type embedding \ --model_type qwen3_emb \ --train_type lora \ --dataset /mnt/d/wsl/work/jupyter/data_hub/qwen3_emb.json \ --split_dataset_ratio 0.05 \ --eval_strategy steps \ --output_dir output \ --eval_steps 100 \ --num_train_epochs 1 \ --save_steps 100 \ --per_device_train_batch_size 4 \ --per_device_eval_batch_size 4 \ --gradient_accumulation_steps 4 \ --learning_rate 6e-6 \ --loss_type infonce \ --label_names labels \ --dataloader_drop_last true
训练结果
采用最新的 ms-swift 的版本,训练脚本如下,可以看到 loss 在下降,而且正负样例的 margin 从 0.20 上升到 0.235。
其中 margin = sim(q,r+) - sim(q,r-) ,可以看到模型对正负样本的区分能力显著变强。
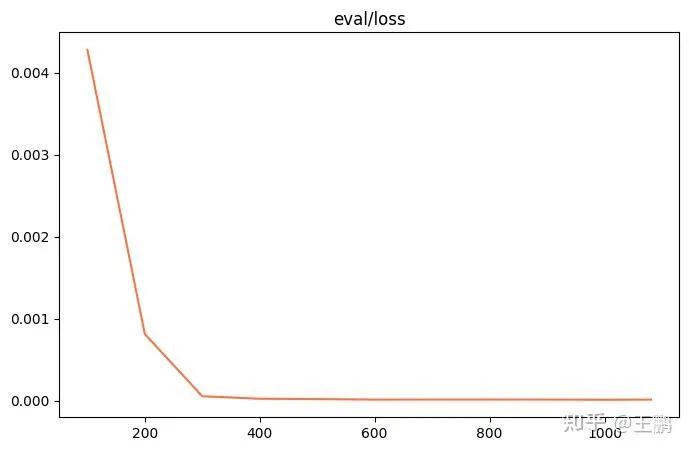
eval_loss
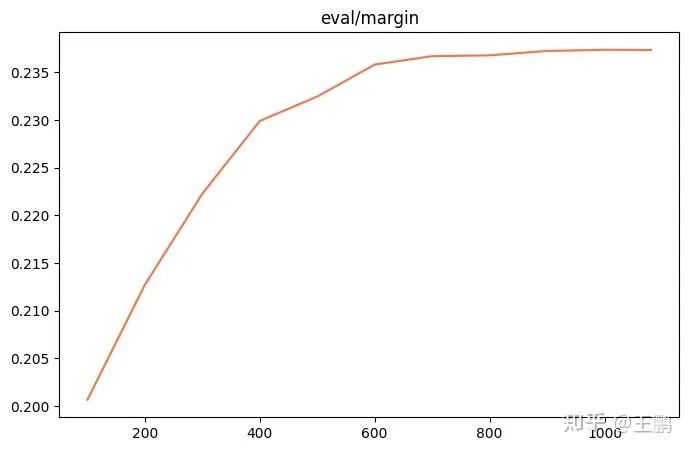
eval_margin
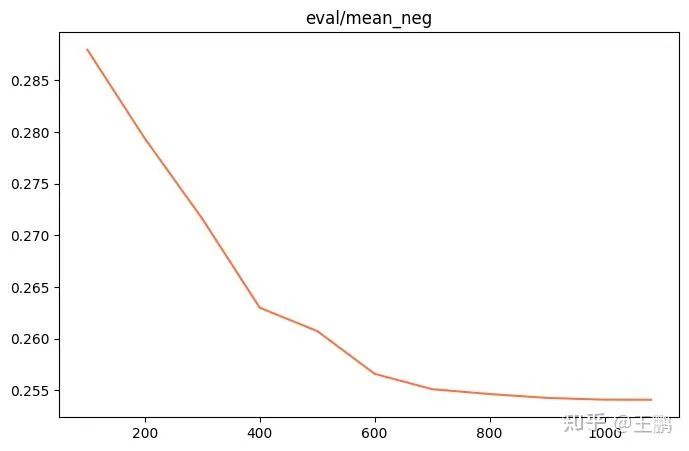
eval_neg
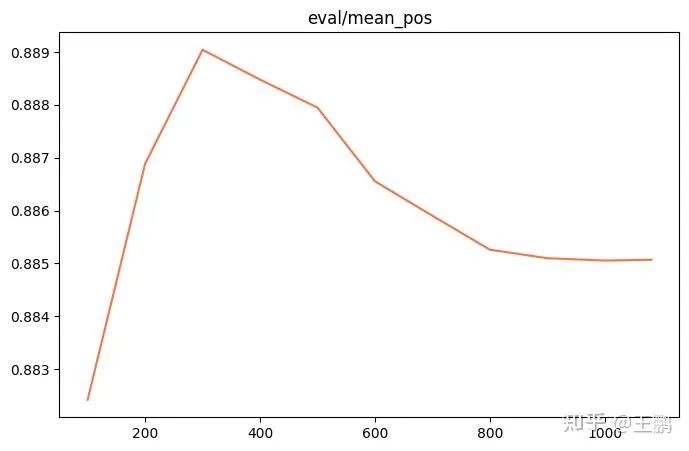
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
更多推荐



 31
31 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)