
【工程开发】Qwen2.5-VL-32B-Instruct 微调(一)
在原有公式的基础上,我们通过进一步增强了 Qwen2.5-VL-32B 的数学和问题解决能力。这也显著改善了模型的主观用户体验,响应风格调整得更符合人类偏好。特别是在数学、逻辑推理和知识问答等客观查询中,响应的细节程度和格式清晰度得到了显著提升。简介自 Qwen2-VL 发布以来的五个月中,许多开发者基于 Qwen2-VL 视觉语言模型构建了新的模型,并为我们提供了宝贵的反馈。在此期间,我们专注于
Qwen2.5-VL-32B-Instruct 基础(摘自官方)
https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
Qwen2.5 VL!Qwen2.5 VL!Qwen2.5 VL! | Qwen
在原有公式的基础上,我们通过强化学习进一步增强了 Qwen2.5-VL-32B 的数学和问题解决能力。这也显著改善了模型的主观用户体验,响应风格调整得更符合人类偏好。特别是在数学、逻辑推理和知识问答等客观查询中,响应的细节程度和格式清晰度得到了显著提升。
简介
自 Qwen2-VL 发布以来的五个月中,许多开发者基于 Qwen2-VL 视觉语言模型构建了新的模型,并为我们提供了宝贵的反馈。在此期间,我们专注于构建更有用的视觉语言模型。今天,我们很高兴向大家介绍 Qwen 家族的最新成员:Qwen2.5-VL。
主要增强功能:
-
视觉理解能力:Qwen2.5-VL 不仅擅长识别常见物体(如花、鸟、鱼和昆虫),还具有分析图像中的文本、图表、图标、图形和布局的强大能力。
-
具备代理能力:Qwen2.5-VL 可直接作为视觉代理,能够进行推理并动态调用工具,支持电脑和手机的使用。
-
理解长视频并捕捉事件:Qwen2.5-VL 能够理解超过 1 小时的视频,这次还新增了通过定位相关视频片段来捕捉事件的能力。
-
支持多种格式的视觉定位:Qwen2.5-VL 能通过生成边界框或点精确定位图像中的对象,并能为坐标和属性提供稳定的 JSON 输出。
-
生成结构化输出:对于发票扫描件、表单、表格等数据,Qwen2.5-VL 支持生成其内容的结构化输出,适用于金融、商业等领域。
模型架构更新
与 Qwen2-VL 相比,Qwen2.5-VL 增强了模型对时间和空间尺度的感知能力,并进一步简化了网络结构以提高模型效率。
- 时间和图像尺寸的感知
在空间维度上,Qwen2.5-VL 不仅能够动态地将不同尺寸的图像转换为不同长度的 token,还直接使用图像的实际尺寸来表示检测框和点等坐标,而不进行传统的坐标归一化。这使得模型能够直接学习图像的尺度。在时间维度上,引入了动态 FPS (每秒帧数)训练和绝对时间编码,将 mRoPE id 直接与时间流速对齐。这使得模型能够通过时间维度 id 的间隔来学习时间的节奏。
- 动态分辨率和帧率训练以理解视频
我们通过采用动态 FPS 采样将动态分辨率扩展到时间维度,使模型能够以不同的采样率理解视频。相应地,我们在时间维度中更新了 mRoPE,结合 ID 和绝对时间对齐,使模型能够学习时间序列和速度,最终获得定位特定时刻的能力。
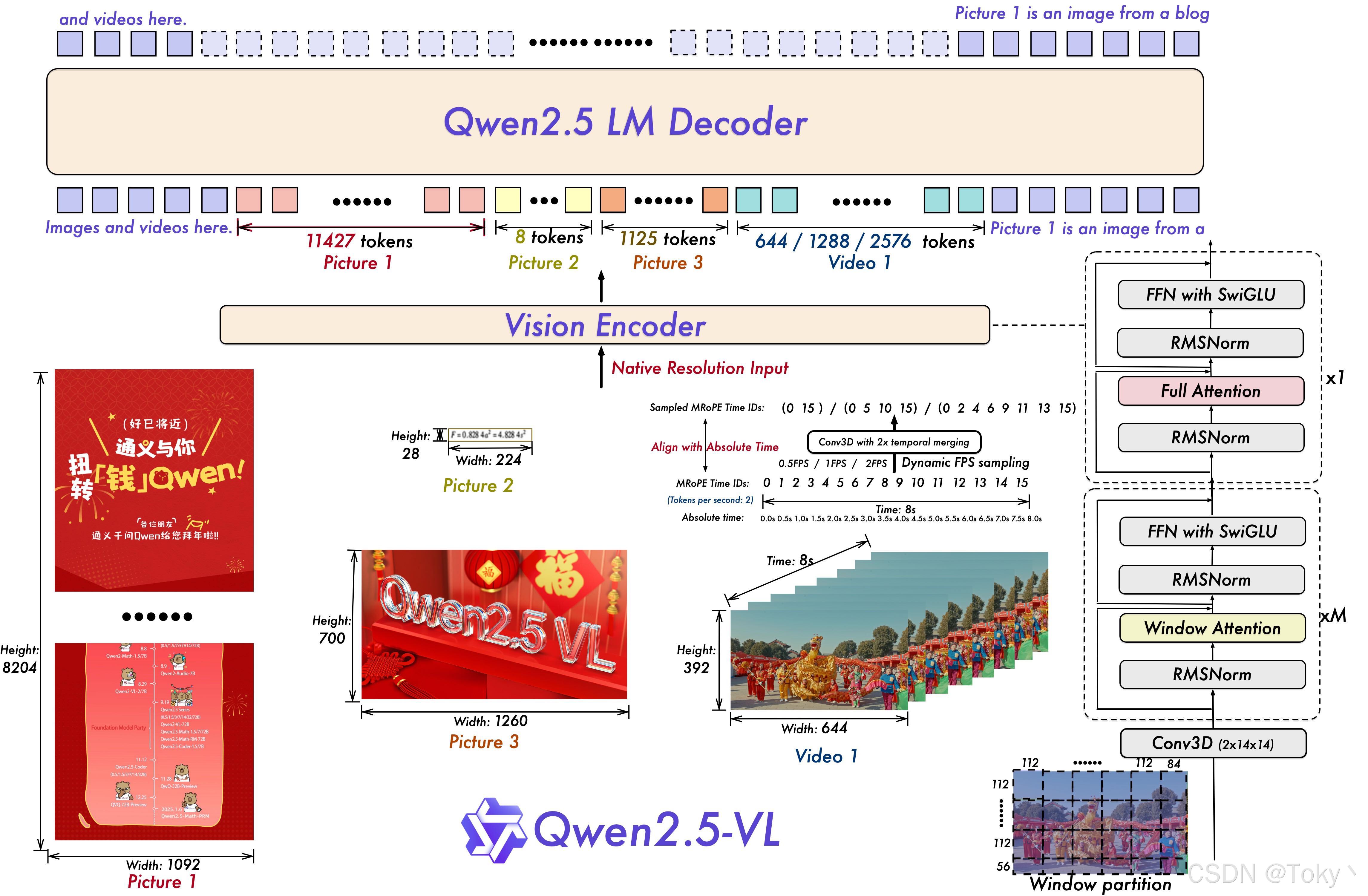
- 精简高效的视觉编码器
我们通过在 ViT 中战略性地实现窗口注意力机制,提升了训练和推理速度。ViT 架构进一步通过 SwiGLU 和 RMSNorm 进行了优化,与 Qwen2.5 LLM 的结构保持一致。
- 更简洁高效的视觉编码器
视觉编码器在多模态大模型中扮演着至关重要的角色。我们从头开始训练了一个原生动态分辨率的 ViT,包括 CLIP、视觉-语言模型对齐和端到端训练等阶段。为了解决多模态大模型在训练和测试阶段 ViT 负载不均衡的问题,我们引入了窗口注意力机制,有效减少了 ViT 端的计算负担。在我们的 ViT 设置中,只有四层是全注意力层,其余层使用窗口注意力。最大窗口大小为 8x8,小于 8x8 的区域不需要填充,而是保持原始尺度,确保模型保持原生分辨率。此外,为了简化整体网络结构,我们使 ViT 架构与 LLMs 更加一致,采用了 RMSNorm 和 SwiGLU 结构。
我们提供了三个模型,分别具有 3 亿、7 亿和 72 亿参数。本仓库包含经过指令微调的 32B Qwen2.5-VL 模型。更多信息,请访问我们的 博客 和 GitHub。
评估
视觉
| 数据集 | Qwen2.5-VL-72B (🤗🤖) |
Qwen2-VL-72B (🤗🤖) |
Qwen2.5-VL-32B (🤗🤖) |
|---|---|---|---|
| MMMU | 70.2 | 64.5 | 70 |
| MMMU Pro | 51.1 | 46.2 | 49.5 |
| MMStar | 70.8 | 68.3 | 69.5 |
| MathVista | 74.8 | 70.5 | 74.7 |
| MathVision | 38.1 | 25.9 | 40.0 |
| OCRBenchV2 | 61.5/63.7 | 47.8/46.1 | 57.2/59.1 |
| CC-OCR | 79.8 | 68.7 | 77.1 |
| DocVQA | 96.4 | 96.5 | 94.8 |
| InfoVQA | 87.3 | 84.5 | 83.4 |
| LVBench | 47.3 | - | 49.00 |
| CharadesSTA | 50.9 | - | 54.2 |
| VideoMME | 73.3/79.1 | 71.2/77.8 | 70.5/77.9 |
| MMBench-Video | 2.02 | 1.7 | 1.93 |
| AITZ | 83.2 | - | 83.1 |
| Android Control | 67.4/93.7 | 66.4/84.4 | 69.6/93.3 |
| ScreenSpot | 87.1 | - | 88.5 |
| ScreenSpot Pro | 43.6 | - | 39.4 |
| AndroidWorld | 35 | - | 22.0 |
| OSWorld | 8.83 | - | 5.92 |
文本
| 模型 | MMLU | MMLU-PRO | MATH | GPQA-diamond | MBPP | Human Eval |
|---|---|---|---|---|---|---|
| Qwen2.5-VL-32B | 78.4 | 68.8 | 82.2 | 46.0 | 84.0 | 91.5 |
| Mistral-Small-3.1-24B | 80.6 | 66.8 | 69.3 | 46.0 | 74.7 | 88.4 |
| Gemma3-27B-IT | 76.9 | 67.5 | 89 | 42.4 | 74.4 | 87.8 |
| GPT-4o-Mini | 82.0 | 61.7 | 70.2 | 39.4 | 84.8 | 87.2 |
| Claude-3.5-Haiku | 77.6 | 65.0 | 69.2 | 41.6 | 85.6 | 88.1 |
要求
Qwen2.5-VL 的代码已在最新的 Hugging face transformers 中,我们建议您使用以下命令从源代码构建:
pip install git+https://github.com/huggingface/transformers accelerate
否则您可能会遇到以下错误
KeyError: 'qwen2_5_vl'
快速开始
下面,我们提供了简单的示例,展示如何使用 🤖 ModelScope 和 🤗 Transformers 使用 Qwen2.5-VL。
Qwen2.5-VL 的代码已在最新的 Hugging face transformers 中,我们建议您使用以下命令从源代码构建:
pip install git+https://github.com/huggingface/transformers accelerate
否则您可能会遇到以下错误:
KeyError: 'qwen2_5_vl'
我们提供了一个工具包,帮助您更方便地处理各种类型的视觉输入,就像使用 API 一样。这包括 base64、URL 和交错的图像和视频。您可以使用以下命令安装它:
# 强烈推荐使用 `[decord]` 功能以加快视频加载速度。
pip install qwen-vl-utils[decord]==0.0.8
如果您不使用 Linux,可能无法从 PyPI 安装 decord。在这种情况下,您可以使用 pip install qwen-vl-utils,它将回退到使用 torchvision 进行视频处理。不过,您仍然可以 从源代码安装 decord 以在加载视频时使用 decord。
使用 🤗 Transformers 进行聊天
这里我们展示了一个代码片段,展示如何使用 transformers 和 qwen_vl_utils 使用聊天模型:
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# 默认:在可用设备上加载模型
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-32B-Instruct", torch_dtype="auto", device_map="auto"
)
# 我们建议启用 flash_attention_2 以获得更好的加速和内存节省,特别是在多图像和视频场景中。
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-32B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# 默认处理器
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-32B-Instruct")
# 模型中每张图像的视觉标记数量的默认范围是 4-16384。
# 您可以根据需要设置 min_pixels 和 max_pixels,例如 256-1280 的标记范围,以平衡性能和成本。
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-32B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "描述这张图片。"},
],
}
]
# 推理准备
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# 推理:生成输出
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
多图像推理
# 包含多张图片和文本查询的消息
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "找出这些图片的相似之处。"},
],
}
]
# 推理准备
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# 推理
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)视频推理
# 包含图像列表作为视频和文本查询的消息
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": [
"file:///path/to/frame1.jpg",
"file:///path/to/frame2.jpg",
"file:///path/to/frame3.jpg",
"file:///path/to/frame4.jpg",
],
},
{"type": "text", "text": "描述这个视频。"},
],
}
]
# 包含本地视频路径和文本查询的消息
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "file:///path/to/video1.mp4",
"max_pixels": 360 * 420,
"fps": 1.0,
},
{"type": "text", "text": "描述这个视频。"},
],
}
]
# 包含视频 URL 和文本查询的消息
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-VL/space_woaudio.mp4",
},
{"type": "text", "text": "描述这个视频。"},
],
}
]
# 在 Qwen 2.5 VL 中,帧率信息也会输入到模型中以与绝对时间对齐。
# 推理准备
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs, video_kwargs = process_vision_info(messages, return_video_kwargs=True)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
fps=fps,
padding=True,
return_tensors="pt",
**video_kwargs,
)
inputs = inputs.to("cuda")
# 推理
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)视频 URL 的兼容性在很大程度上取决于第三方库的版本。详情见下表。如果您更喜欢不使用默认的后端,可以通过 FORCE_QWENVL_VIDEO_READER=torchvision 或 FORCE_QWENVL_VIDEO_READER=decord 更改后端。
| 后端 | HTTP | HTTPS |
|---|---|---|
| torchvision >= 0.19.0 | ✅ | ✅ |
| torchvision < 0.19.0 | ❌ | ❌ |
| decord | ✅ | ❌ |
批量推理
# 批量推理的示例消息
messages1 = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "这些图片中有哪些共同元素?"},
],
}
]
messages2 = [
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "你是谁?"},
]
# 组合消息以进行批量处理
messages = [messages1, messages2]
# 批量推理准备
texts = [
processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True)
for msg in messages
]
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=texts,
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# 批量推理
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_texts = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_texts)🤖 ModelScope
我们强烈建议用户,特别是中国大陆的用户使用 ModelScope。snapshot_download 可以帮助您解决下载检查点的问题。
更多使用技巧
对于输入图像,我们支持本地文件、base64 和 URL。对于视频,我们目前只支持本地文件。
# 您可以直接在文本中插入本地文件路径、URL 或 base64 编码的图像。
## 本地文件路径
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/your/image.jpg"},
{"type": "text", "text": "描述这张图片。"},
],
}
]
## 图像 URL
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "http://path/to/your/image.jpg"},
{"type": "text", "text": "描述这张图片。"},
],
}
]
## Base64 编码的图像
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "data:image;base64,/9j/..."},
{"type": "text", "text": "描述这张图片。"},
],
}
]
提高性能的图像分辨率
模型支持广泛的分辨率输入。默认情况下,它使用原生分辨率进行输入,但更高的分辨率可以提高性能,代价是更多的计算。用户可以设置最小和最大像素数,以实现最佳配置,例如 256-1280 的标记数量范围,以平衡速度和内存使用。
min_pixels = 256 * 28 * 28
max_pixels = 1280 * 28 * 28
processor = AutoProcessor.from_pretrained(
"Qwen/Qwen2.5-VL-32B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels
)
此外,我们提供了两种方法来细粒度控制输入到模型的图像大小:
- 定义 min_pixels 和 max_pixels:图像将被调整大小以保持其纵横比在 min_pixels 和 max_pixels 范围内。
- 指定确切的尺寸:直接设置
resized_height和resized_width。这些值将四舍五入到最接近的 28 的倍数。
# min_pixels 和 max_pixels
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "file:///path/to/your/image.jpg",
"resized_height": 280,
"resized_width": 420,
},
{"type": "text", "text": "描述这张图片。"},
],
}
]
# resized_height 和 resized_width
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "file:///path/to/your/image.jpg",
"min_pixels": 50176,
"max_pixels": 50176,
},
{"type": "text", "text": "描述这张图片。"},
],
}
]
处理长文本
当前的 config.json 设置为上下文长度最多 32,768 个标记。 为了处理超过 32,768 个标记的广泛输入,我们使用 YaRN,这是一种增强模型长度外推的技术,确保在处理长文本时的最佳性能。
对于支持的框架,您可以在 config.json 中添加以下内容以启用 YaRN:
{ ..., "type": "yarn", "mrope_section": [ 16, 24, 24 ], "factor": 4, "original_max_position_embeddings": 32768 }
然而,需要注意的是,这种方法对时间和空间定位任务的性能有显著影响,因此不推荐使用。
同时,对于长视频输入,由于 MRoPE 本身在 ID 上更为经济,可以直接将 max_position_embeddings 修改为更大的值,例如 64k。
模型性能
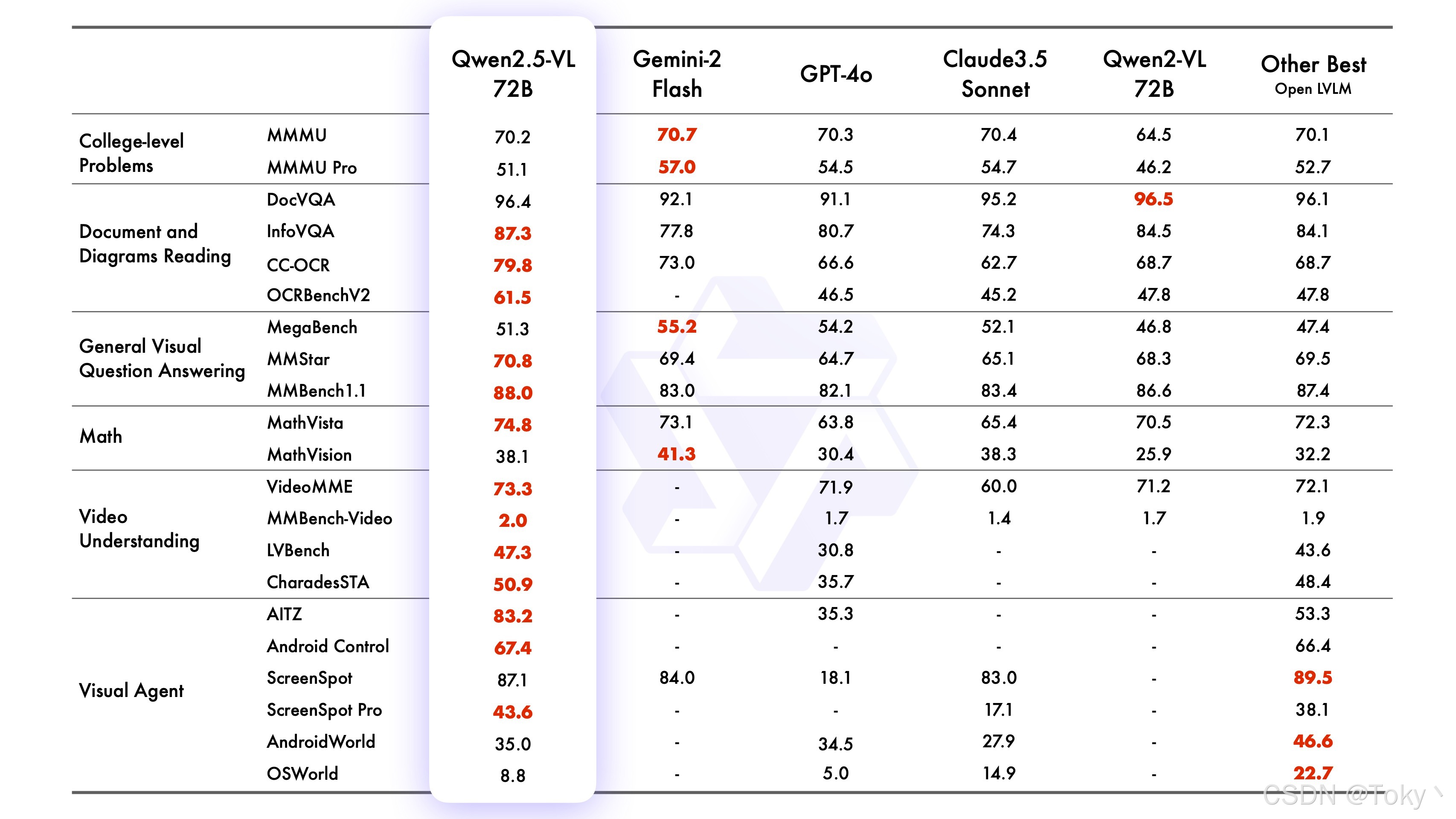
我们对视觉语言模型进行了全面的评估,比较了 SOTA 模型以及同尺寸规模模型中表现最好的模型。在旗舰模型 Qwen2.5-VL-72B-Instruct 的测试中,它在一系列涵盖多个领域和任务的基准测试中表现出色,包括大学水平的问题、数学、文档理解、视觉问答、视频理解和视觉 Agent。值得注意的是,Qwen2.5-VL 在理解文档和图表方面具有显著优势,并且能够作为视觉 Agent 进行操作,而无需特定任务的微调。
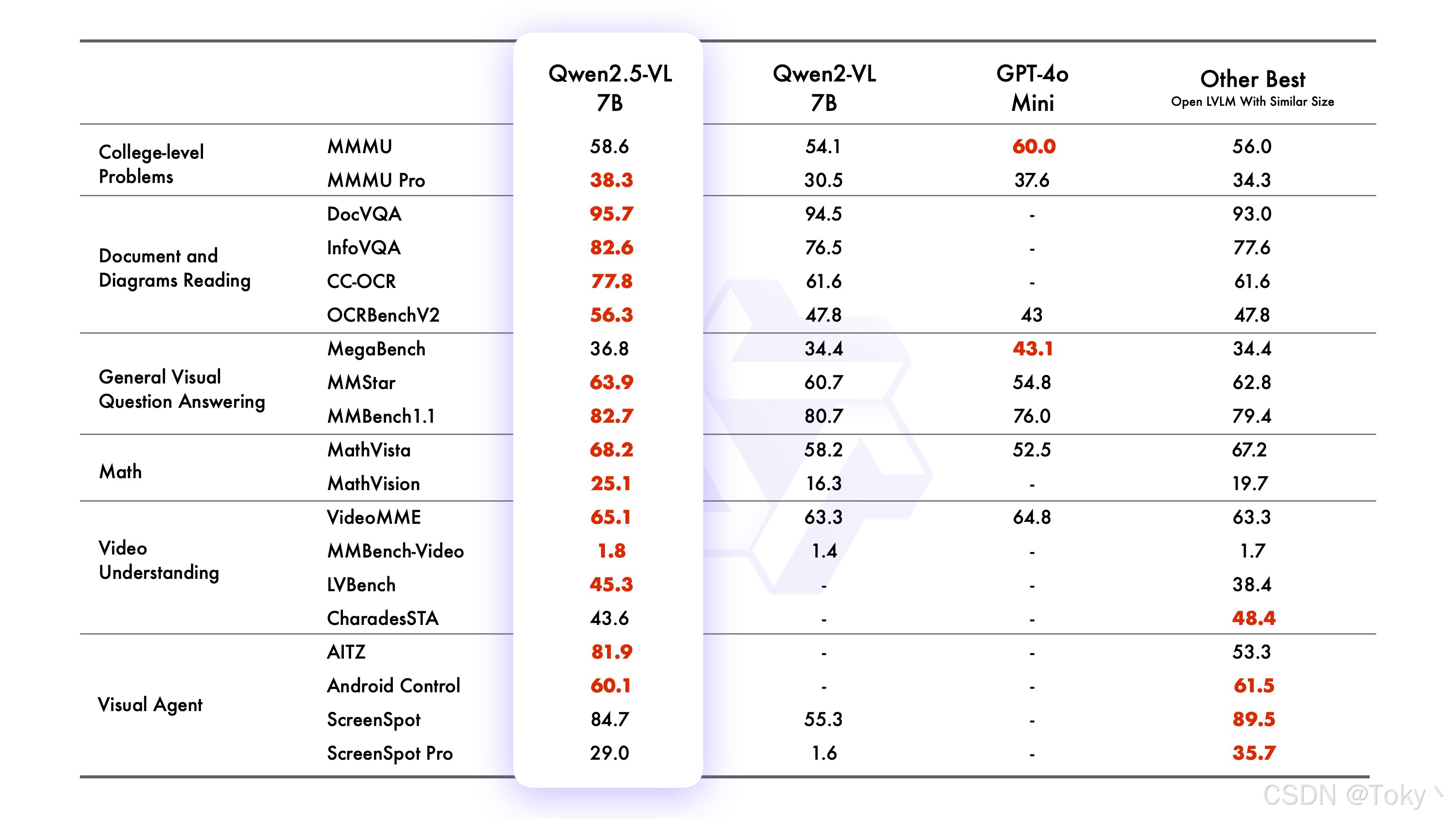
在较小的模型方面,Qwen2.5-VL-7B-Instruct 在多个任务中超越了 GPT-4o-mini,而 Qwen2.5-VL-3B 作为端侧 AI 的潜力股,甚至超越了我们之前版本 Qwen2-VL 的 7B 模型。
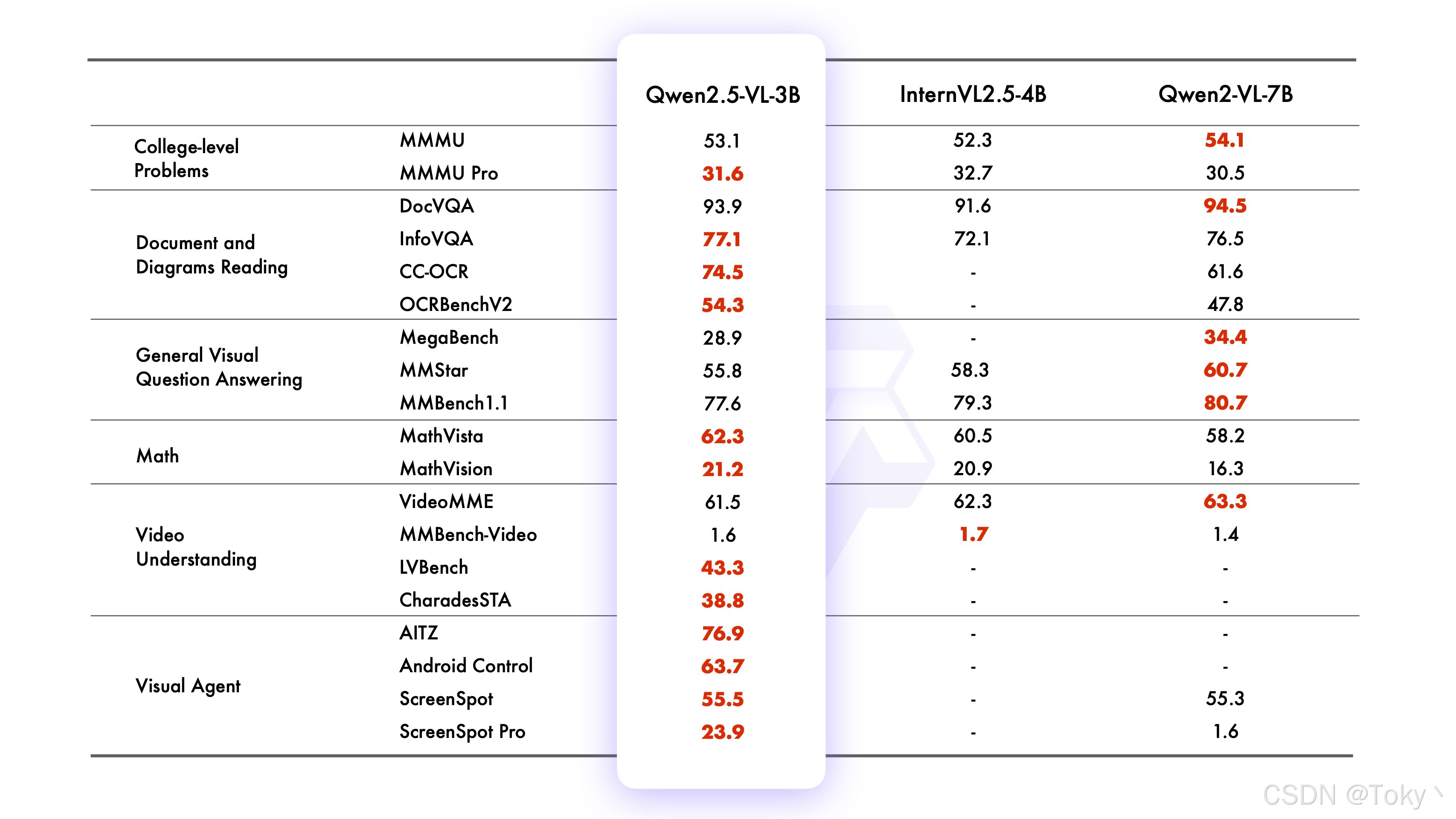
模型能力案例
1. 万物识别
Qwen2.5-VL 显著增强了其通用图像识别能力,大幅扩大了可识别的图像类别量级。不仅包括植物、动物、著名山川的地标,还包括影视作品中的 IP,以及各种各样的商品。
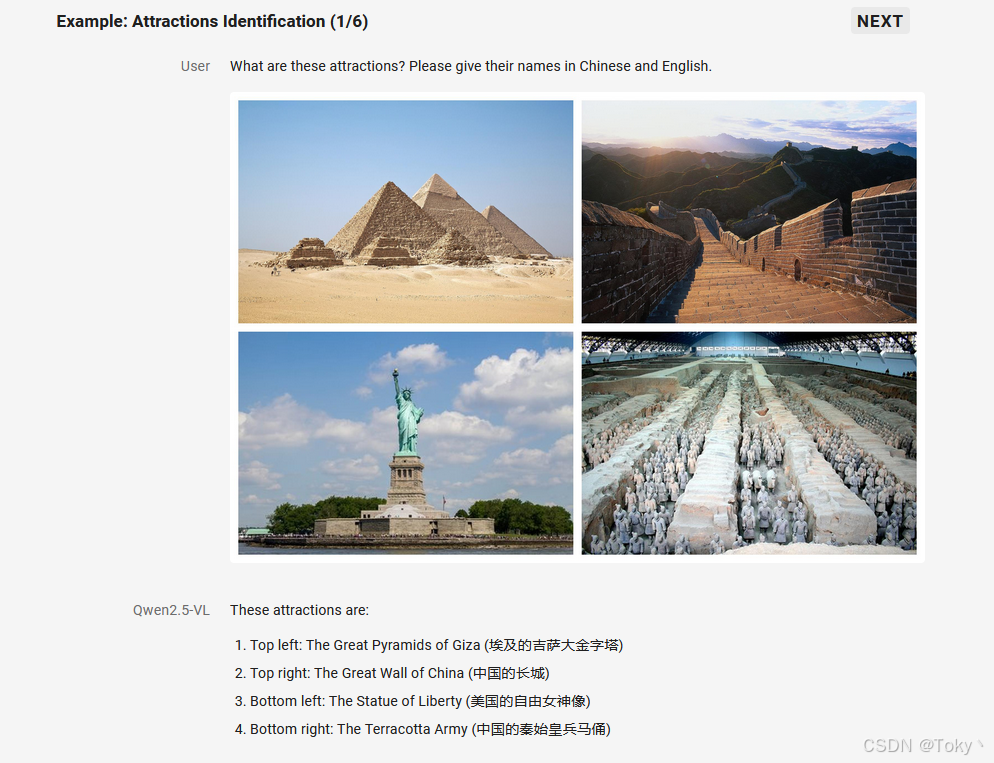
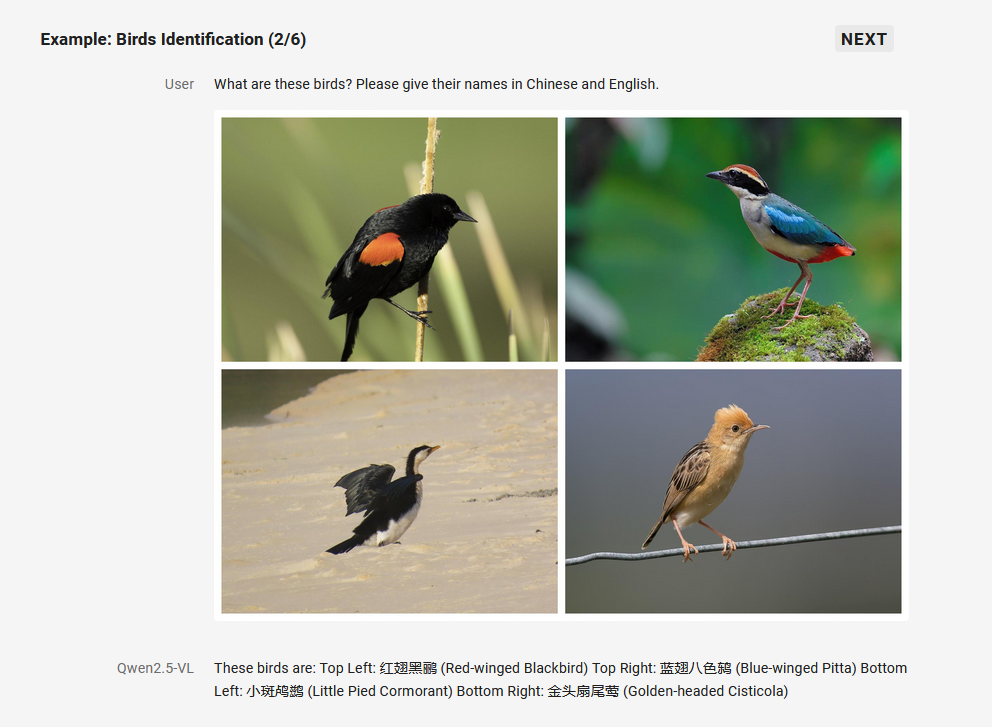
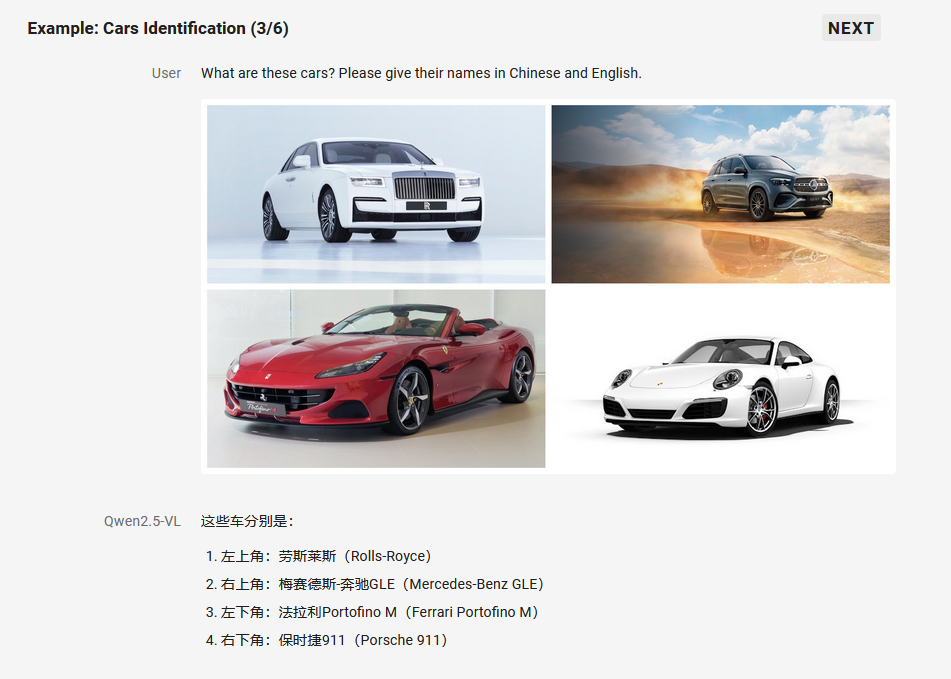

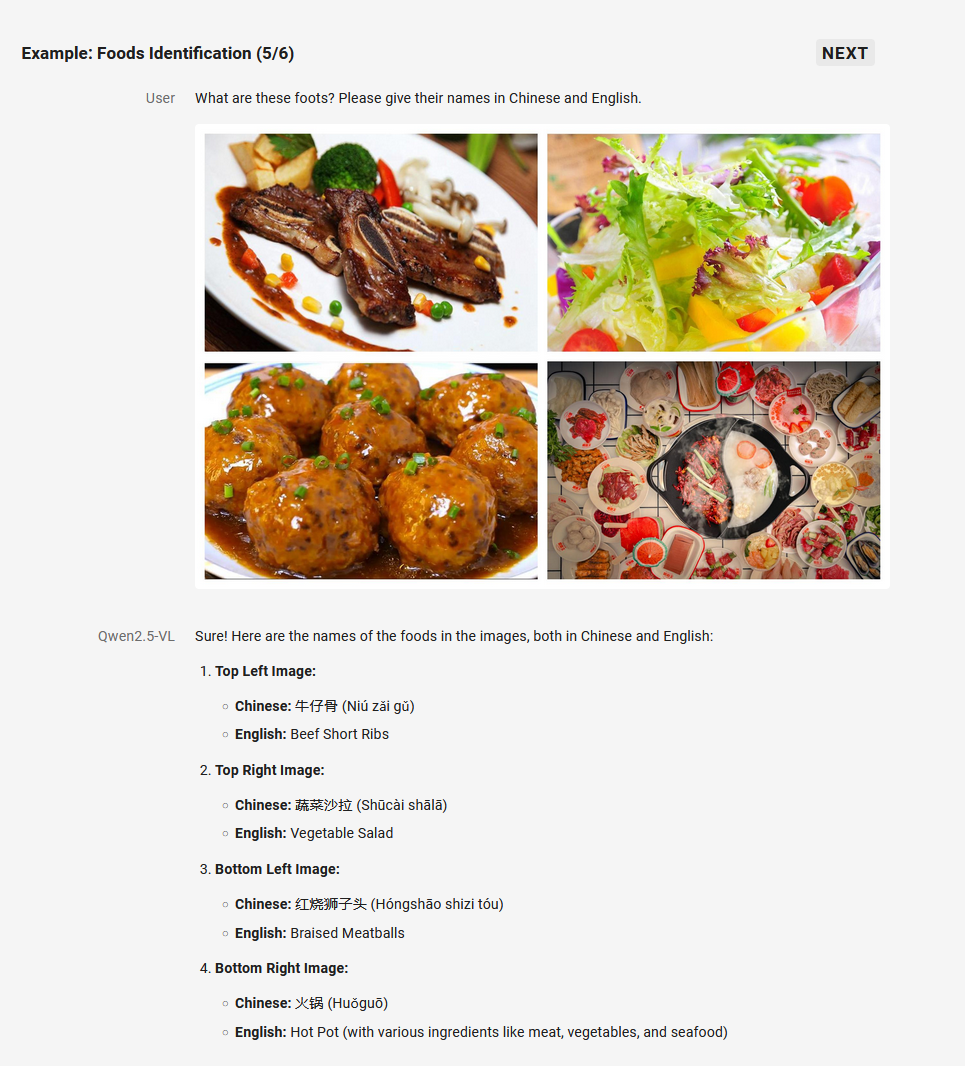

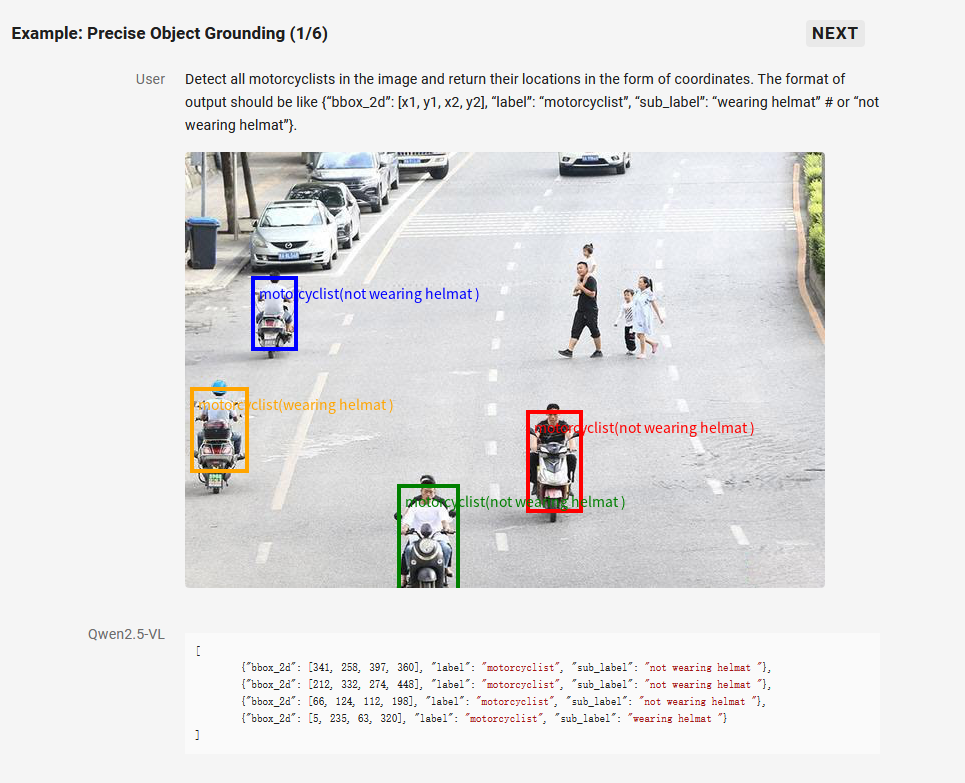
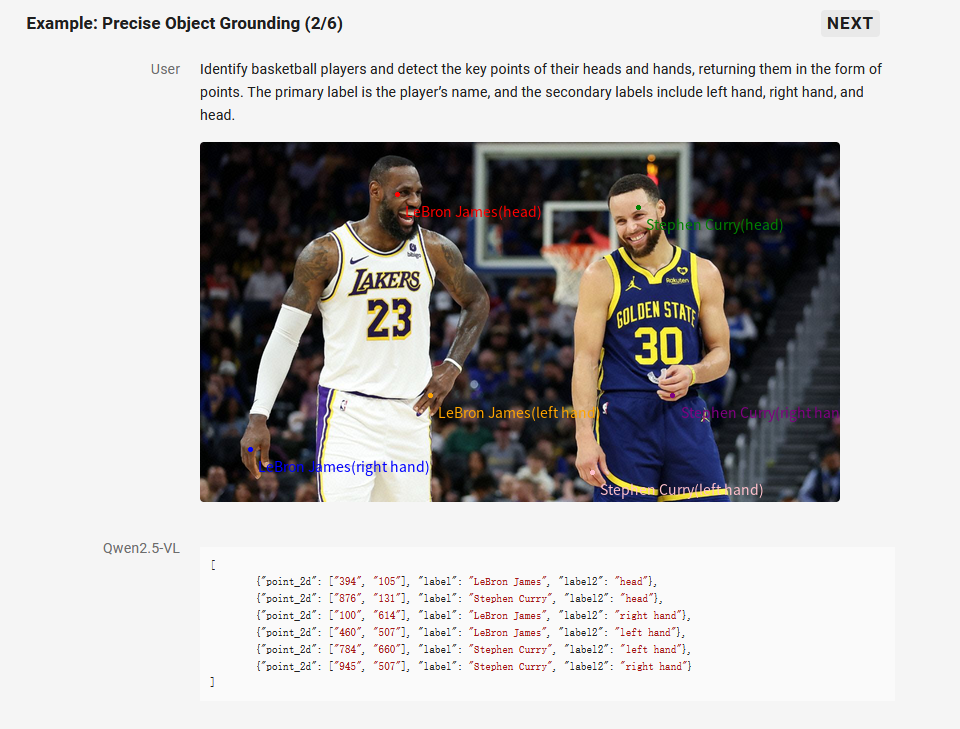
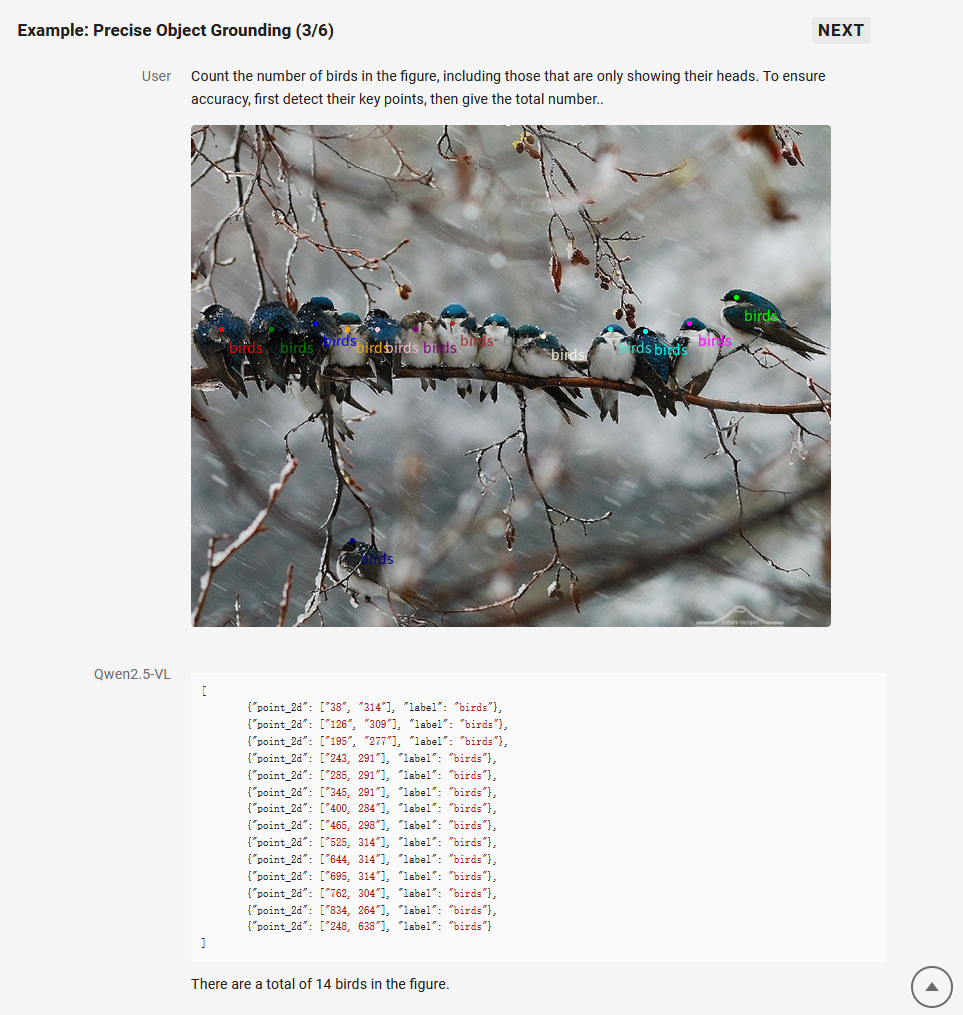
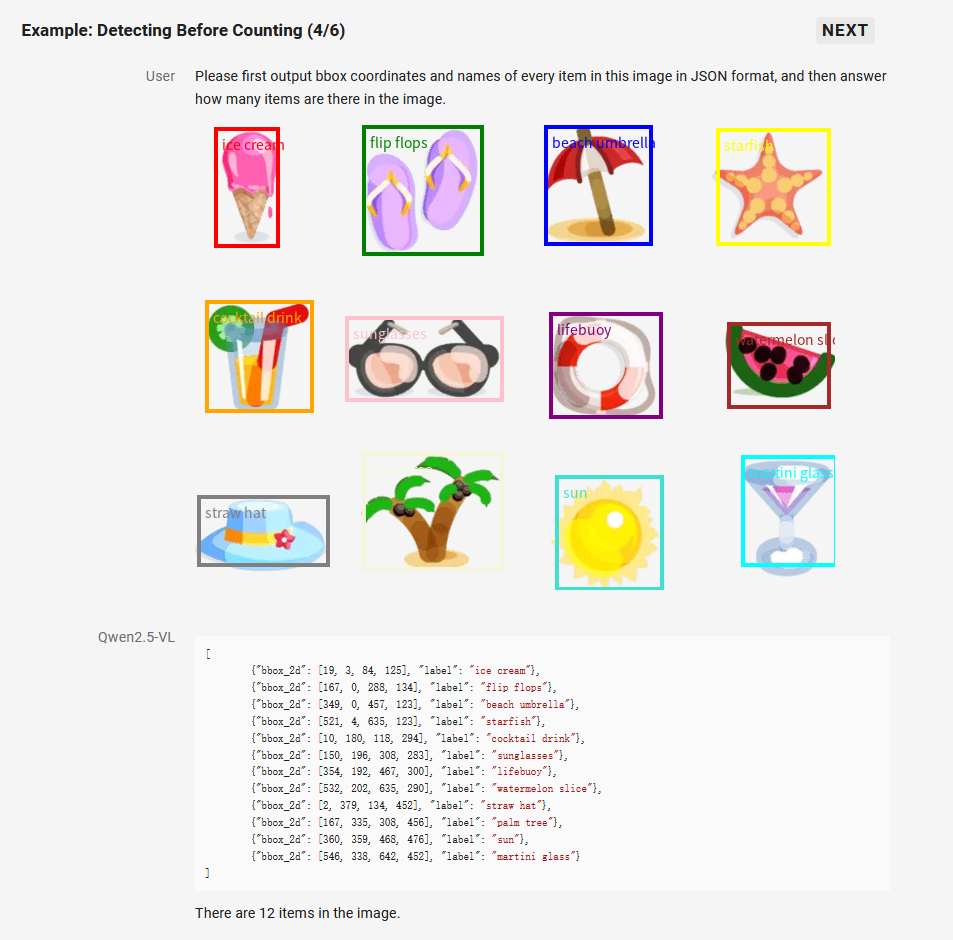
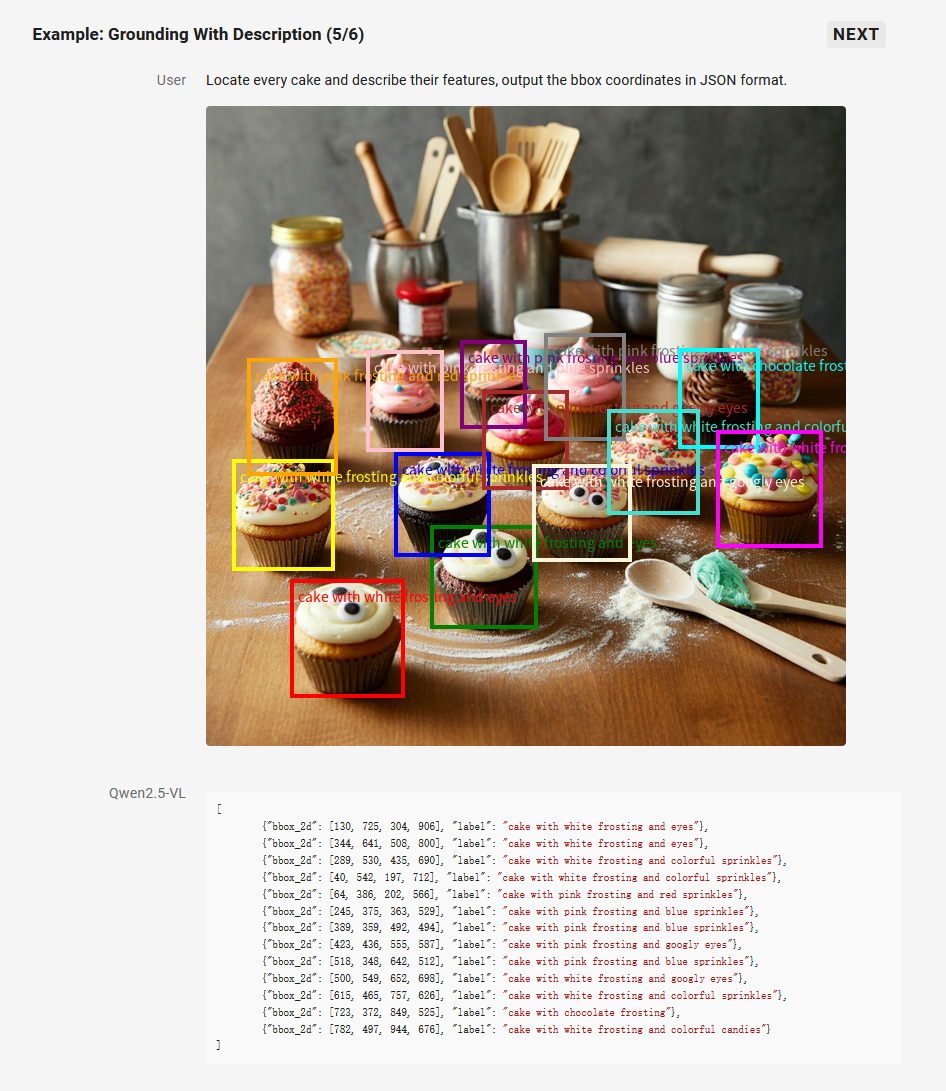
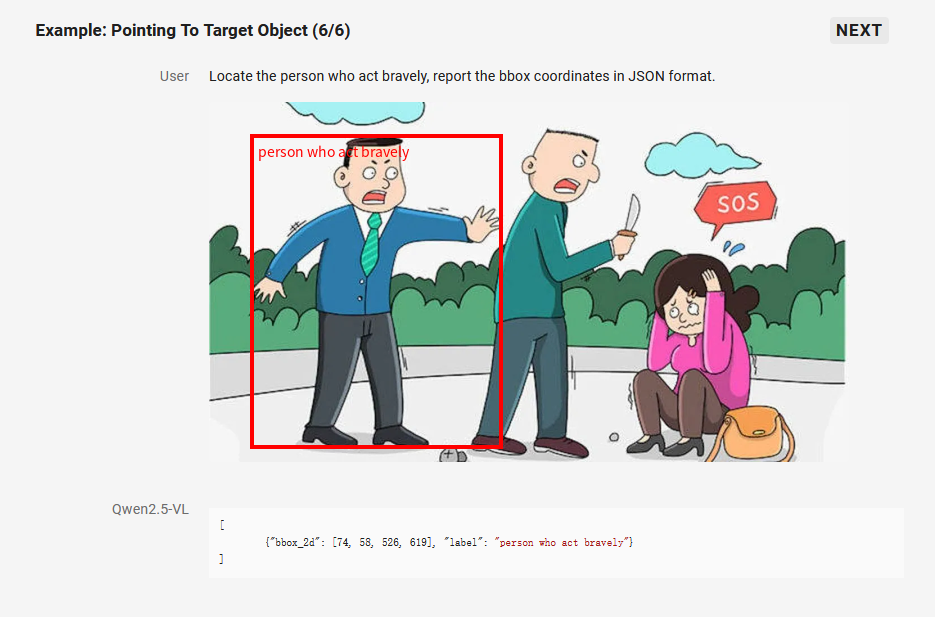
2. 精准的视觉定位
Qwen2.5-VL 采用矩形框和点的多样化方式对通用物体定位,可以实现层级化定位和规范的 JSON 格式输出。增强的定位能力为复杂场景中的视觉 Agent 进行理解和推理任务提供了基础。
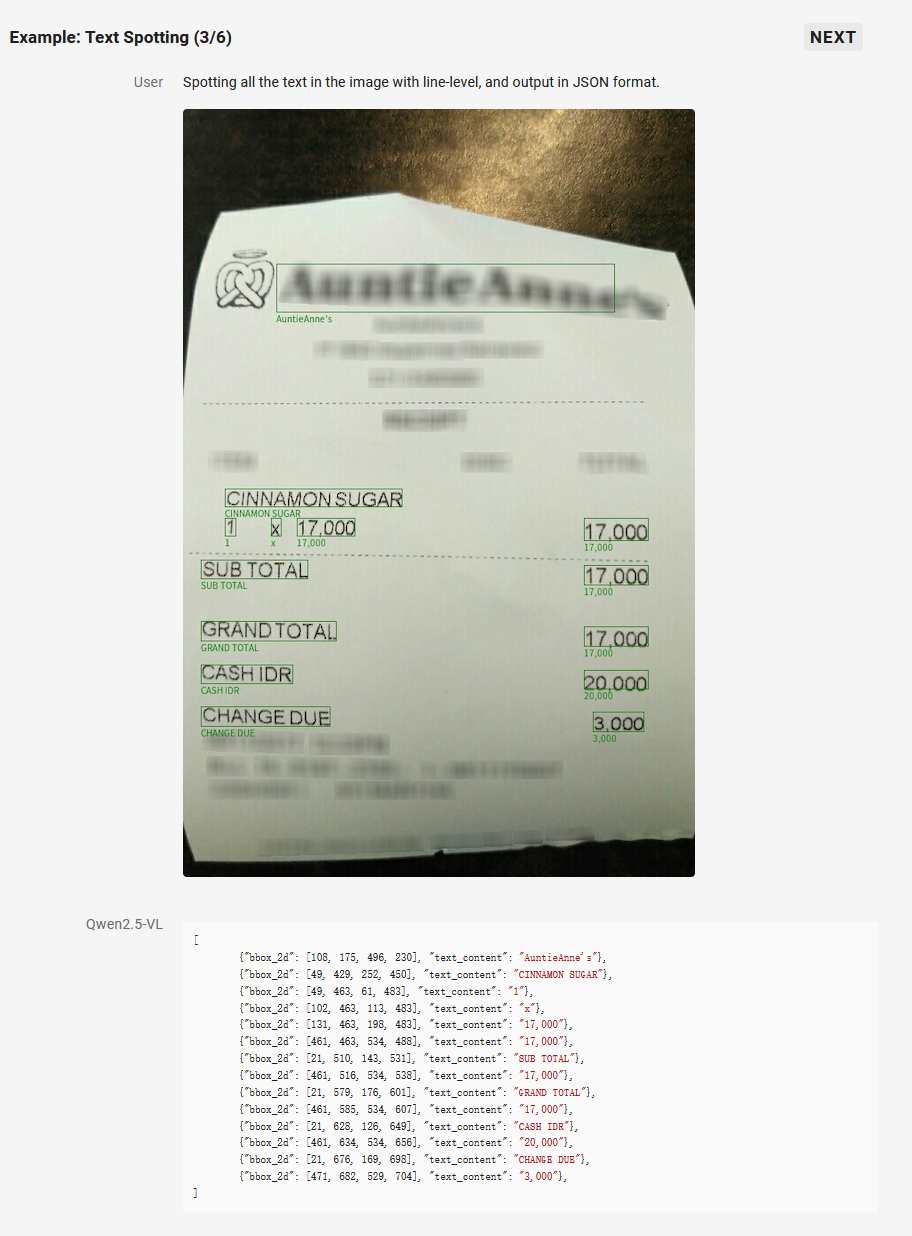
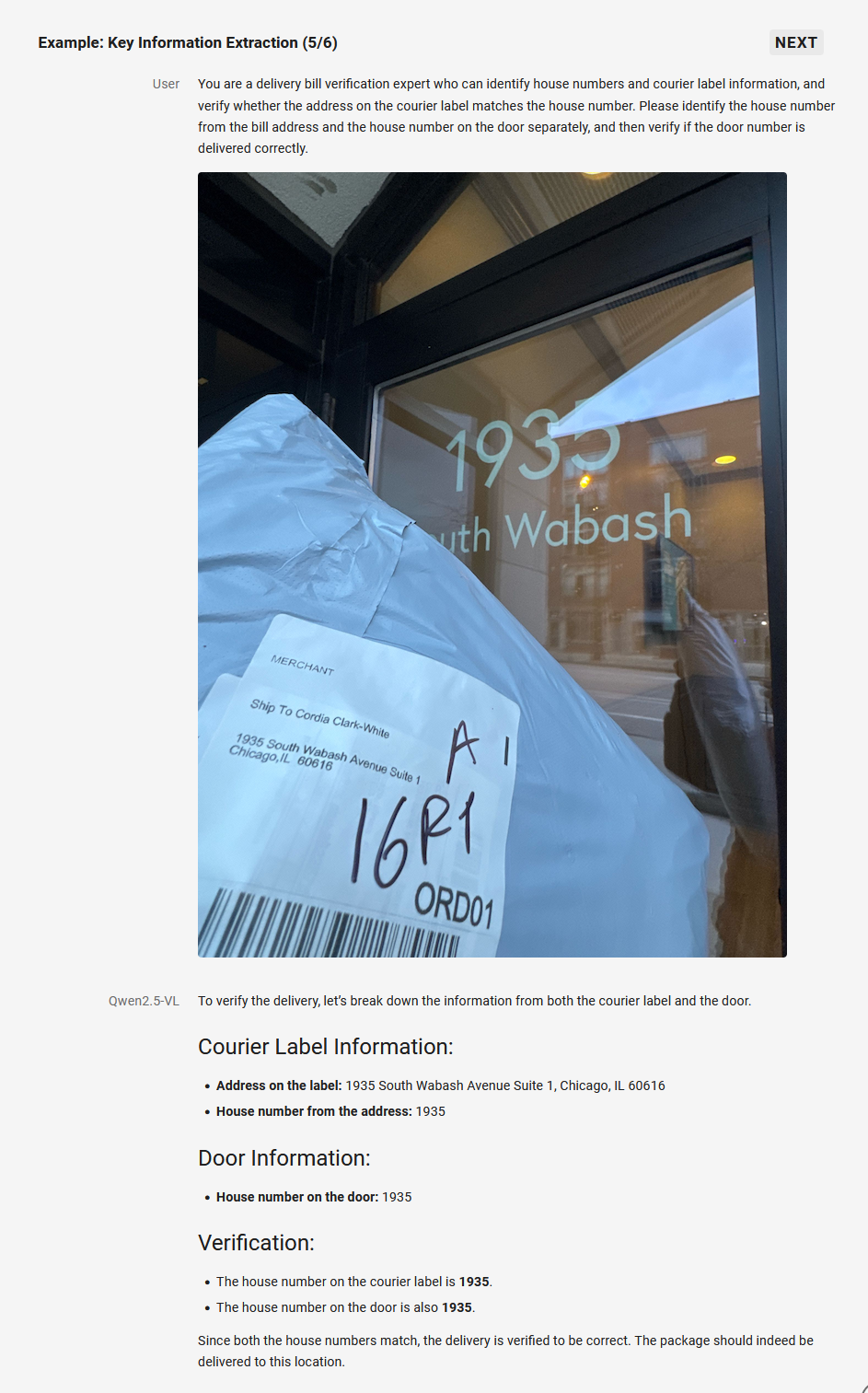
3. 全面的文字识别和理解
Qwen2.5-VL 将 OCR 识别能力提升至一个新的水平,增强了多场景、多语言和多方向的文本识别和文本定位能力。同时,在信息抽取能力上进行大幅度增强,以满足日益增长的资质审核、金融商务等数字化、智能化需求。

4. Qwen特色的文档解析
在 Qwen2.5-VL 中,我们在设计了一种更全面的文档解析格式,称为 QwenVL HTML 格式,它既可以将文档中的文本精准地识别出来,也能够提取文档元素(如图片、表格等)的位置信息,从而准确地将文档中的版面布局进行精准还原。基于精心构建的海量数据,QwenVL HTML 可以对广泛的场景进行鲁棒的文档解析,比如杂志、论文、网页、甚至手机截屏等等。


5. 增强的视频理解
Qwen2.5-VL 的视频理解能力经过全面升级,在时间处理上,我们引入了动态帧率(FPS)训练和绝对时间编码技术。这样一来,模型不仅能够支持小时级别的超长视频理解,还具备秒级的事件定位能力。它不仅能够准确地理解小时级别的长视频内容,还可以在视频中搜索具体事件,并对视频的不同时间段进行要点总结,从而快速、高效地帮助用户提取视频中蕴藏的关键信息。
Example: Information Extraction from Videos (1/6) Next
User
video_ocr
Watch the video and list the paper titles in a table.
Qwen2.5-VL
Here is a table listing the paper titles from the video:
| Paper Title |
|---|
| A New Sequential Prediction Framework with Spatial-temporal Embedding |
| NeW CRFs: Neural Window Fully-connected CRFs for Monocular Depth Estimation |
| Deep Unified Representation for Heterogeneous Recommendation |
| OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework |
| KoMen: Domain Knowledge Guided Interaction Recommendation for Emerging Scenarios Yiqing Xie |
| Vision-Language Pre-Training for Boosting Scene Text Detectors |
6. 能够操作电脑和手机的视觉 Agent
通过利用内在的感知、解析和推理能力,Qwen2.5-VL 展现出了不错的设备操作能力。这包括在手机、网络平台和电脑上执行任务,为创建真正的视觉代理提供了有价值的参考点。
引用
如果您觉得我们的工作对您有帮助,请随时引用我们。
@article{Qwen2.5-VL,
title={Qwen2.5-VL Technical Report},
author={Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Zesen and Zhang, Hang and Yang, Zhibo and Xu, Haiyang and Lin, Junyang},
journal={arXiv preprint arXiv:2502.13923},
year={2025}
}
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)