
手把手教你如何全参微调QWEN2.5
本次实战采用QWEN2.5的0.5b的小体量模型在弱智吧数据集上进行微调。通过本次实战,希望大家能够掌握以下技能:1,如何快速获取廉价算力2,如何在QWEN模型上进行全参微调。
前言
本次实战采用QWEN2.5的0.5b的小体量模型在弱智吧数据集上进行微调。
总所周知,弱智吧里面有很多问题十分的无厘头。这种无厘头的发问虽然在人类的角度来看其实大部分都是对中文语义的强行模糊,但对于模型来说确实锻炼模型逻辑能力的高质量预料。
通过本次实战,希望大家能够掌握以下技能:
1,如何快速获取廉价算力
2,如何在QWEN模型上进行全参微调
算力准备
🚀 新人注册专享,4090免费9小时体验
SuperTi GPU算力租赁平台正式上线啦!我们首次推出了万众瞩目的NVIDIA RTX 4090显卡,首次注册并完成实名认证的用户,将直接获得NVIDIA RTX 4090显卡的9小时免费使用权。这不仅是我们对新用户的诚挚欢迎,更是你体验云端加速魅力的绝佳机会。无需复杂的配置,无需担忧成本问题,只需轻点鼠标,你就能在云端享受到前所未有的计算性能,让AI项目在SuperTi平台上飞速前进。

💰 限时特价卡1.98元/时,性价比之选
除了震撼的新人福利外,我们还推出了限时特价卡活动,以回馈广大用户的支持与厚爱。即日起至2025年3月30日,每卡只需1.98元/时,会员包月更能享受低至1.52元/时的惊人优惠。这一价格不仅远低于市场平均水平,更是对你项目成本控制的强力支持。无论是小规模测试还是大规模部署,我们都能为你提供灵活、高效的算力解决方案。
【专享链接】 ![]() https://www.superti-cloud.com/ 环境配置
https://www.superti-cloud.com/ 环境配置
本次实战我们的硬件配置采用4090训练。由于模型体积很小,所以我们直接使用全量微调。训练框架采用llamafactory。
硬件配置流程
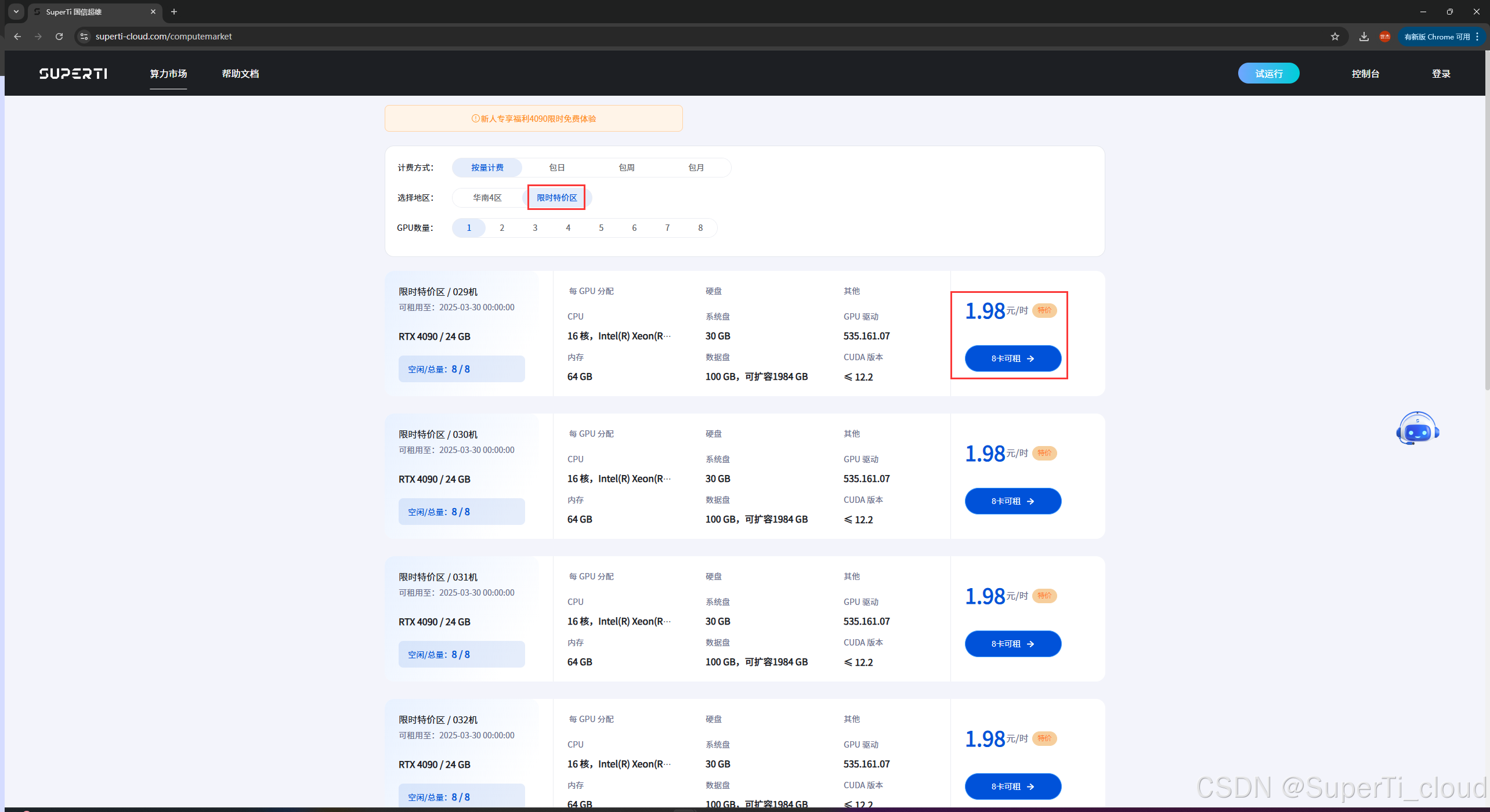
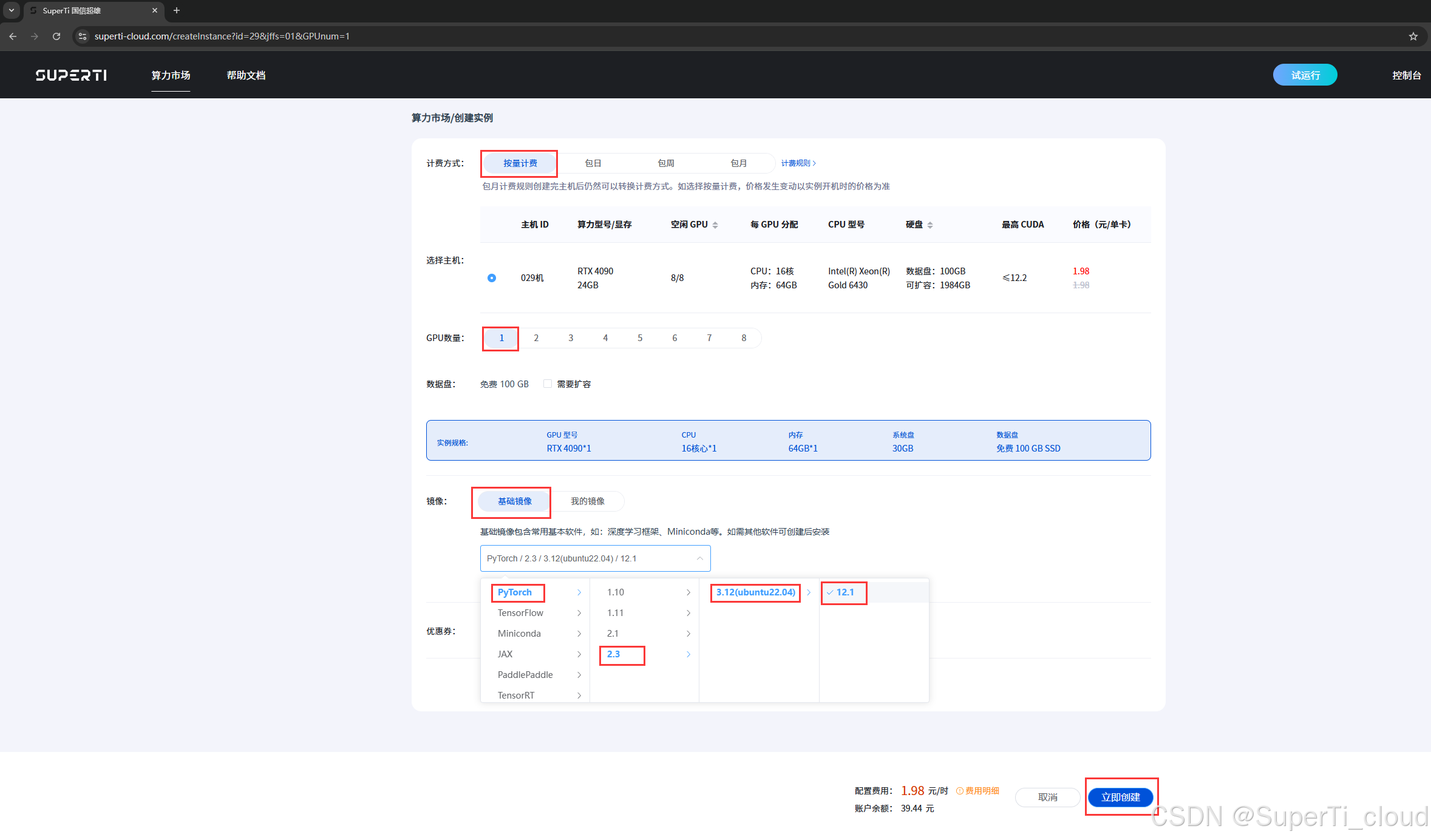
如上图记录,我们选用一卡4090来训练。选好配置之后创建实例。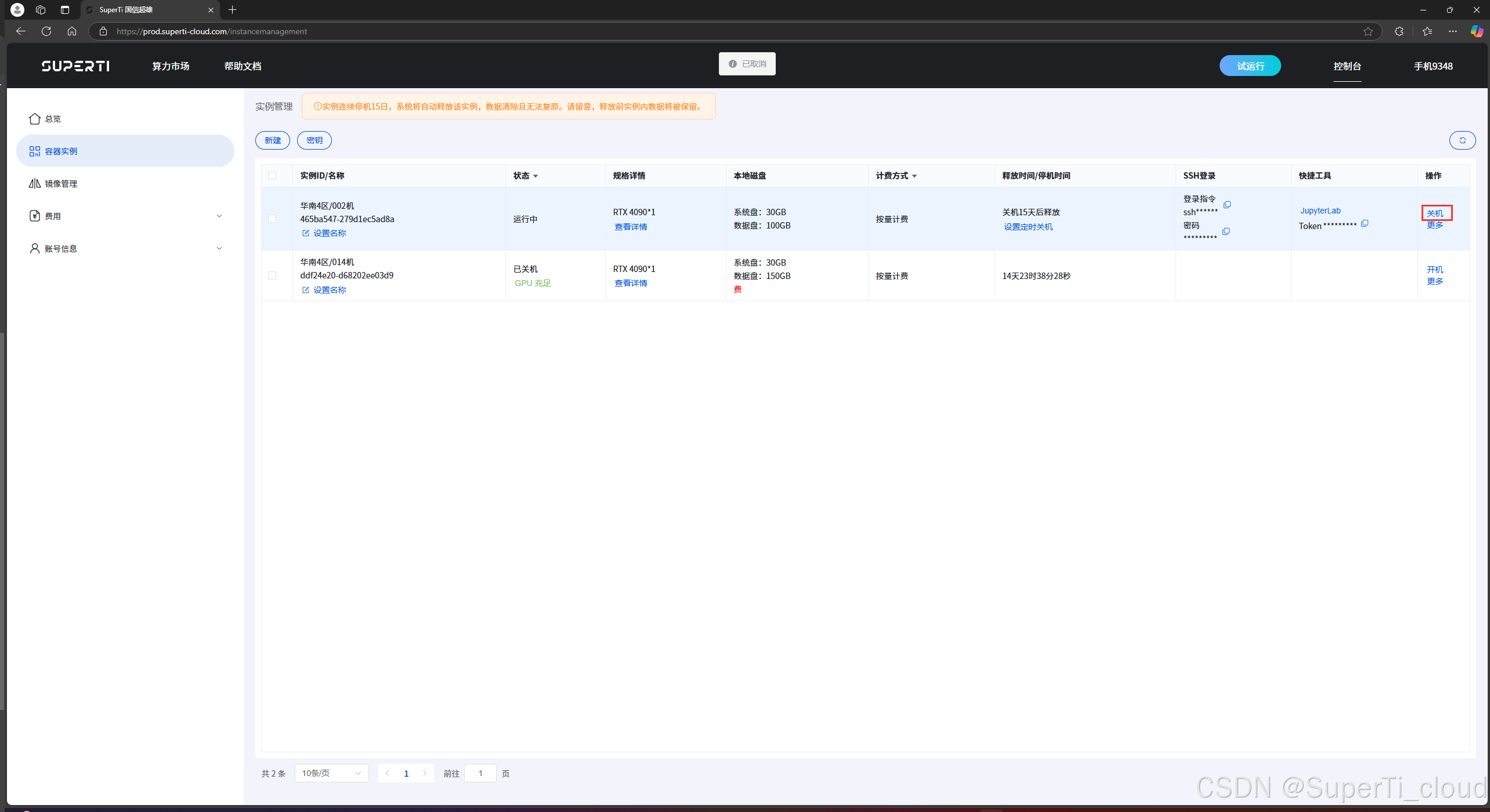
如上图所记录,我们的训练过程中包含了数据集下载,python环境安装和相关微调训练任务只有最后的训练需要GPU资源,所以我们在创建实例之后先点击关机按钮,等待关机之后点击无卡模式开机按钮,节约资源。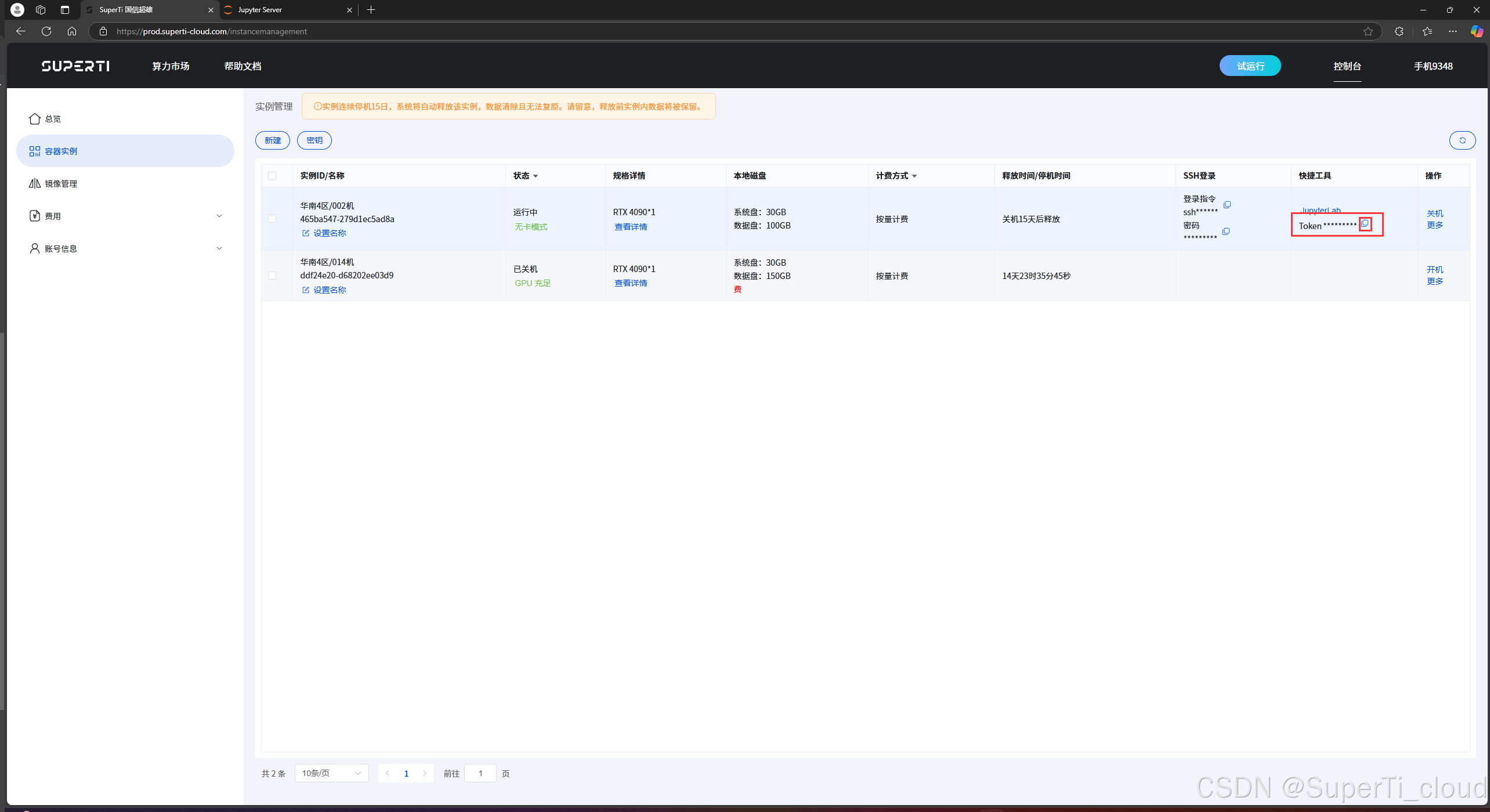
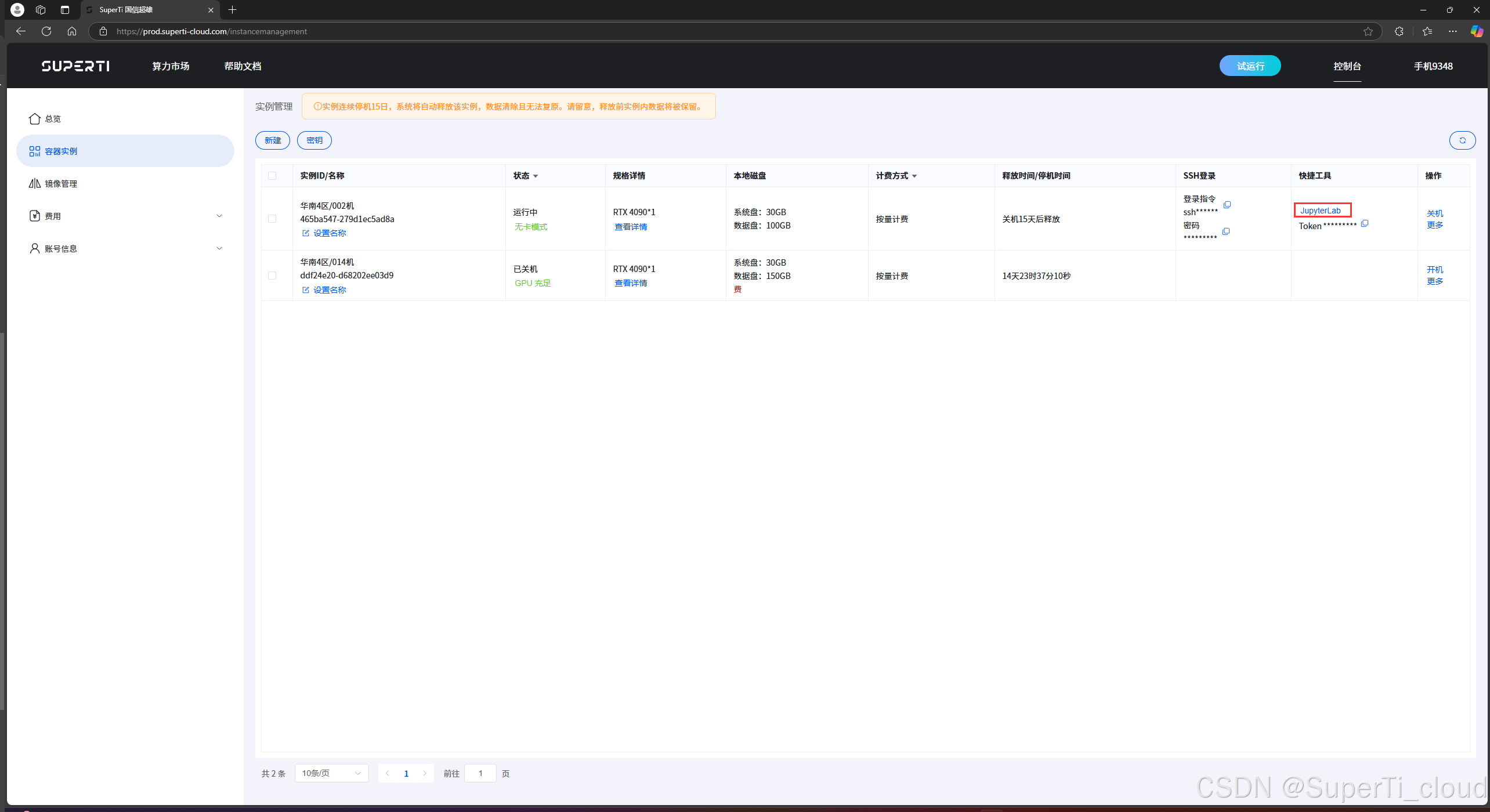
如上图记录,我们先点击复制token按钮,然后点击进入jupyterlab。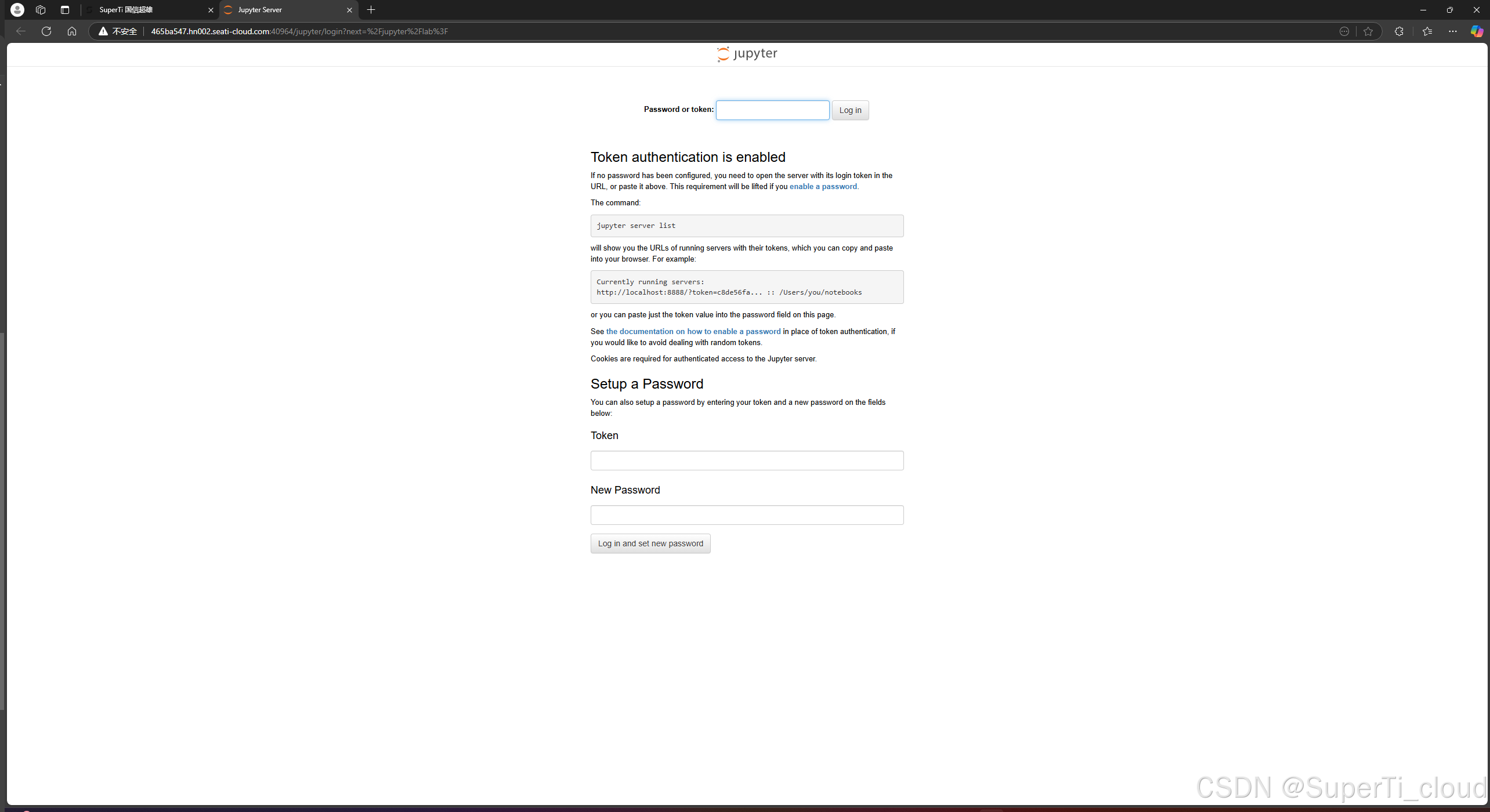
第一次出现如下安全验证界面之后我们在里面粘贴我们刚刚复制的token。然后登陆。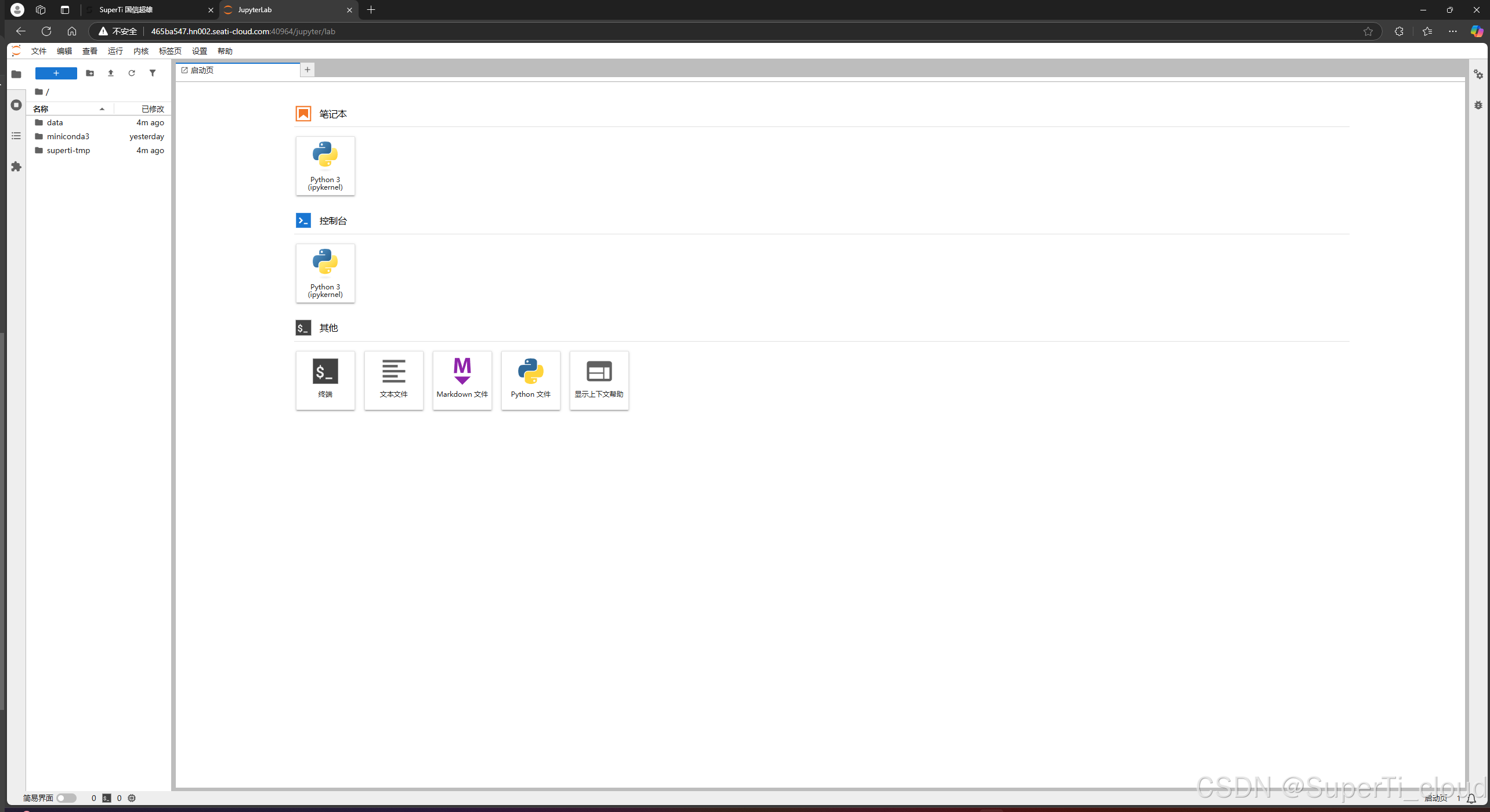
数据集与模型准备
(1)本次实战是用的0.5B的qwen2.5在弱智吧数据集上进行微调。
首先开启conda功能,执行如下命令:
/root/miniconda3/bin/conda init(2)然后打开一个新终端。
(3)接着创建环境:
conda create -n sft python=3.10(4)安装完成之后进入环境
conda activate sft(5)在环境里安装modelscope包,
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple我们就是利用modelscope这个包下载数据集和模型
(6)分别运行如下命令下载数据集和模型
modelscope download --dataset zhuangxialie/SFT-Chinese-Dataset ruozhiba/ruozhiout_qa_cn.jsonl --local_dir your_dataset_path
modelscope download --model Qwen/Qwen2.5-0.5B --local_dir your_dataset_path模型训练
本次实战的训练框架是使用的llamafactory。框架安装命令如下:
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" -i https://pypi.tuna.tsinghua.edu.cn/simple我们在LLaMA-Factory下创建一个qwen-inference.yaml文件。配置内容如下:
model_name_or_path: your_model_path
template: qwen
infer_backend: huggingface # choices: [huggingface, vllm]
trust_remote_code: true然后在LLaMA-Factory目录下运行推理命令:
llamafactory-cli chat qwen-inference.yaml命令运行和加载模型完之后,我们用弱智吧的经典问题进行的测试: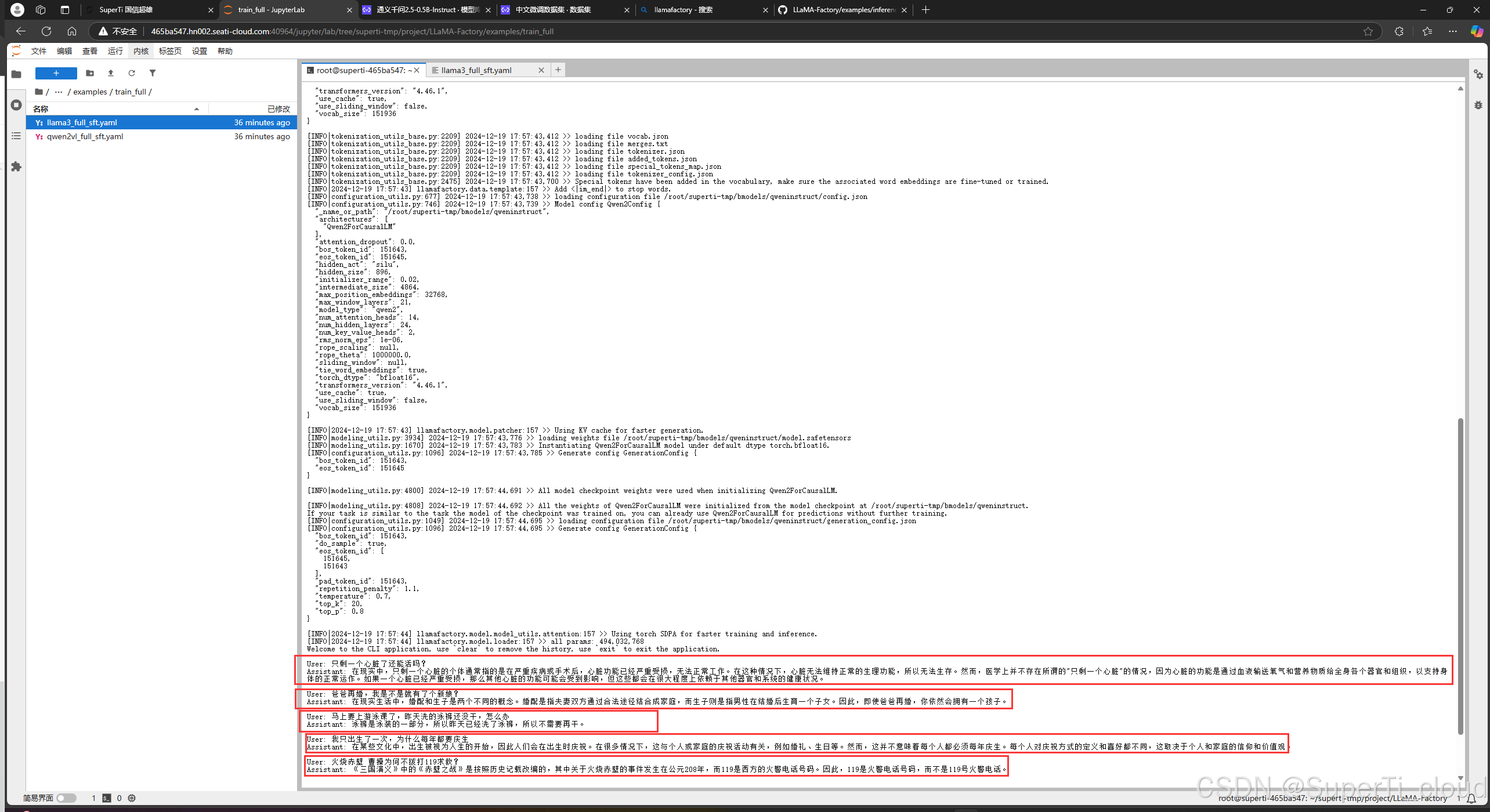
可以看出,没有微调的模型的逻辑能力还是有些欠缺,有点胡言乱语
接下来我们就开始微调。
我们需要进入llamafactory的工程目录下的data目录进行数据集的简单配置。
进入data目录之后打开dataset_info.json添加如下配置: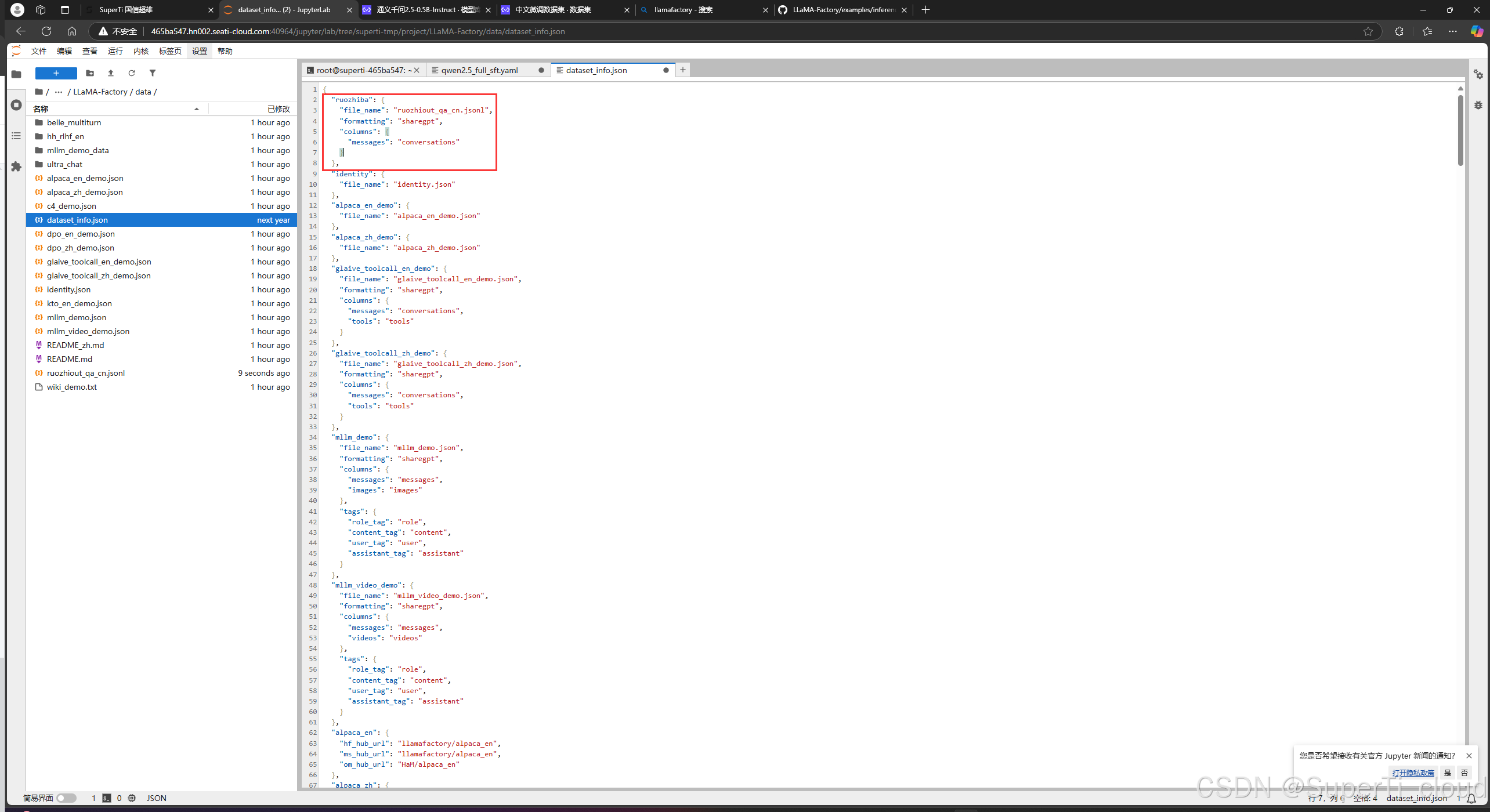
其中的file_name更改为弱智吧的jsonl数据集的文件路径
然后创建一个训练配置文件qwen2.5_full_sft.yaml
### model
model_name_or_path: your_model_path
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: full
#deepspeed: examples/deepspeed/ds_z3_config.json # choices: [ds_z0_config.json, ds_z2_config.json, ds_z3_config.json]
### dataset
dataset: ruozhiba
template: qwen
cutoff_len: 2048
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: save_path
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 2
learning_rate: 1.0e-5
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500需要修改的路径:
(1)model_name_or_path字段的内容修改为自己下载的模型路径。
(2)output_dir字段内容修改为模型训练后的保存路径
然后用如下命令进行训练
llamafactory-cli train qwen2.5_full_sft.yaml训练过程很快,如下图所示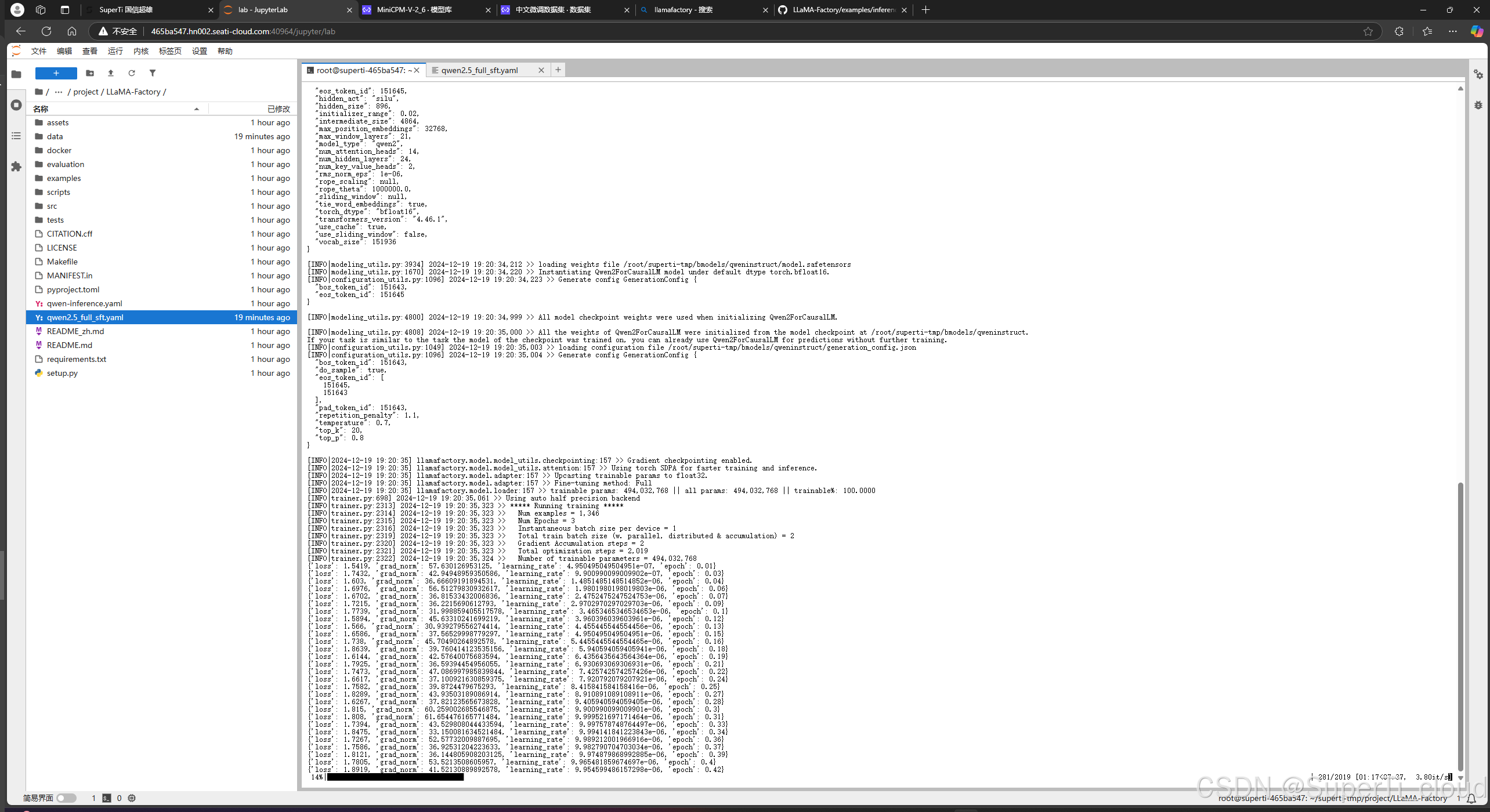
训练完成之后,我们可以进行推理测试,只需要将之前的推理配置文件qwen-inference.yaml中的模型路径修改为我们训练之后保存的模型路径,然后运行推理命令:
llamafactory-cli chat qwen-inference.yaml加载完毕之后就可以开始测试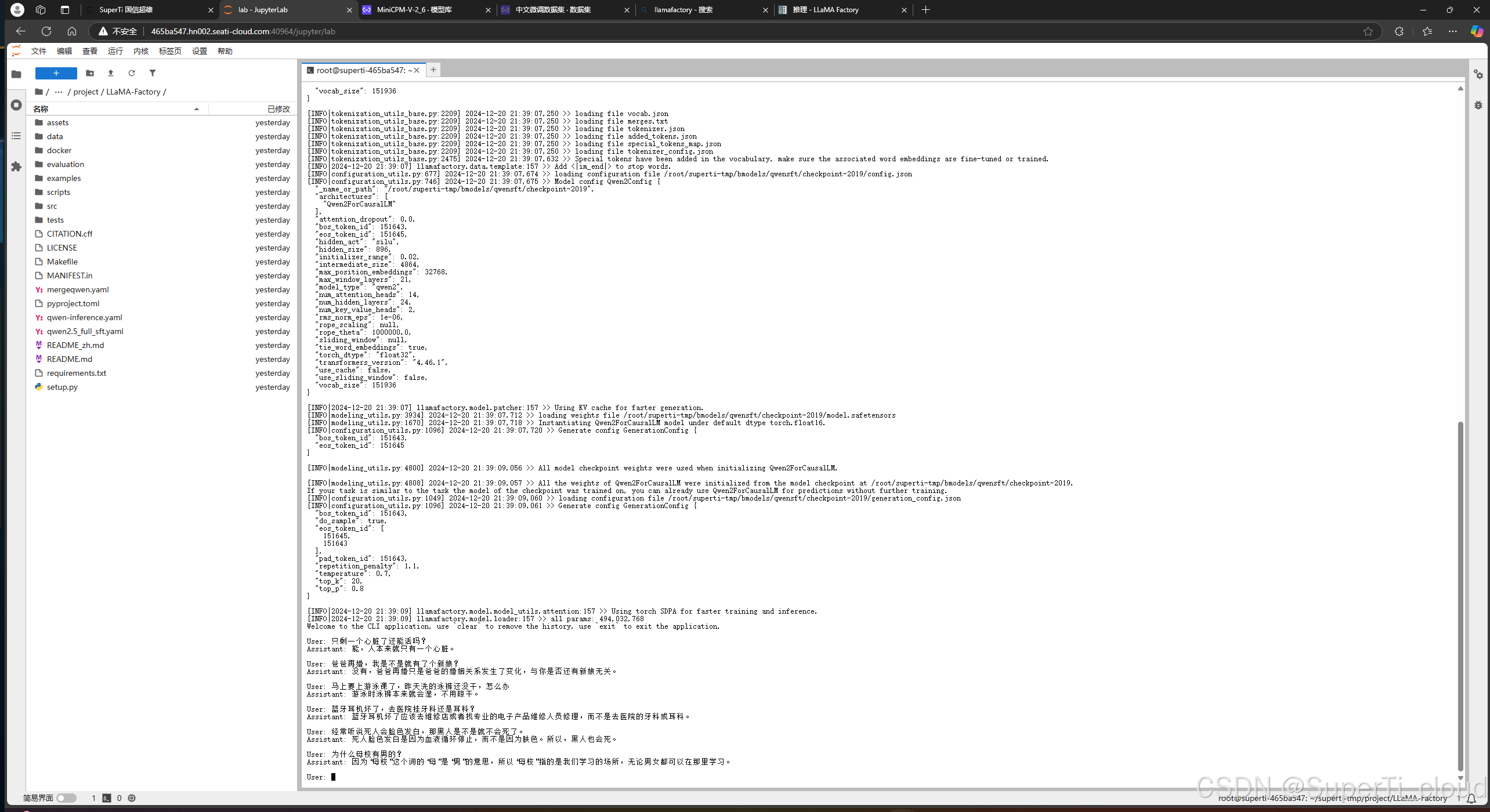
可以发现,大模型在训练了之后对部分问题是可以有逻辑的回答的。
立即行动,共创未来
选择SuperTi GPU算力租赁平台,就是选择了高性能、低成本、灵活便捷的云端解决方案。我们致力于以技术创新推动行业发展,让强大的计算能力成为你成功的坚实后盾。别再犹豫,立即访问我们的官方网站,开启你的云端算力特惠之旅!更多详情与咨询,请直接联系我们的客服团队。让我们携手并进,共创辉煌!
在SuperTi GPU算力租赁平台,每一次计算都是对未来的投资。现在,就让我们一起在云端驰骋,探索算力的无限可能!
🔥立即点击这里,开启您的算力租赁之旅吧!🔥
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)