
LlamaFactory微调大模型参数介绍
在的webui里面,一切微调都是可视化,方便我们入手。我们可以不用了解每个参数背后的具体实现手段,但一定要知道每个参数的含义,大模型的微调不是一蹴而就,而是不断更新和优化。我们可能要调试各种参数之间的搭配,最后得到一个接近我们任务的大模型。
LlamaFactory是一个用于微调大型语言模型的强大工具,特别是针对 LLaMA 系列模型。
可以适应不同的模型架构和大小。支持多种微调技术,如全参数微调、LoRA( Low-Rank Adaptation )、QLoRA( Quantized LoRA )等。还给我们提供了简单实用的命令行接口。
支持多 cpu 训练,多任务微调,还有各种内存优化技术,如梯度检查点、梯度累积等。
支持混合精度训练,提高训练效率。
一、LlamaFactory的安装与运行
LlamaFactory 的安装过程详细见官方文档安装 - LLaMA Factory
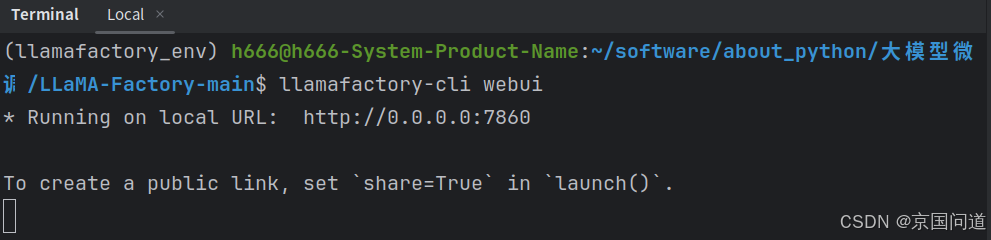
打开LlamaFactory的web运行界面,进入根目录执行以下命令:
llamafactory-cli webui服务运行详细信息如下,在浏览器输入URLhttp://0.0.0.0:7860
二、LlamaFactory微调参数设置
1.通用参数
依次介绍页面上半部分的每个参数
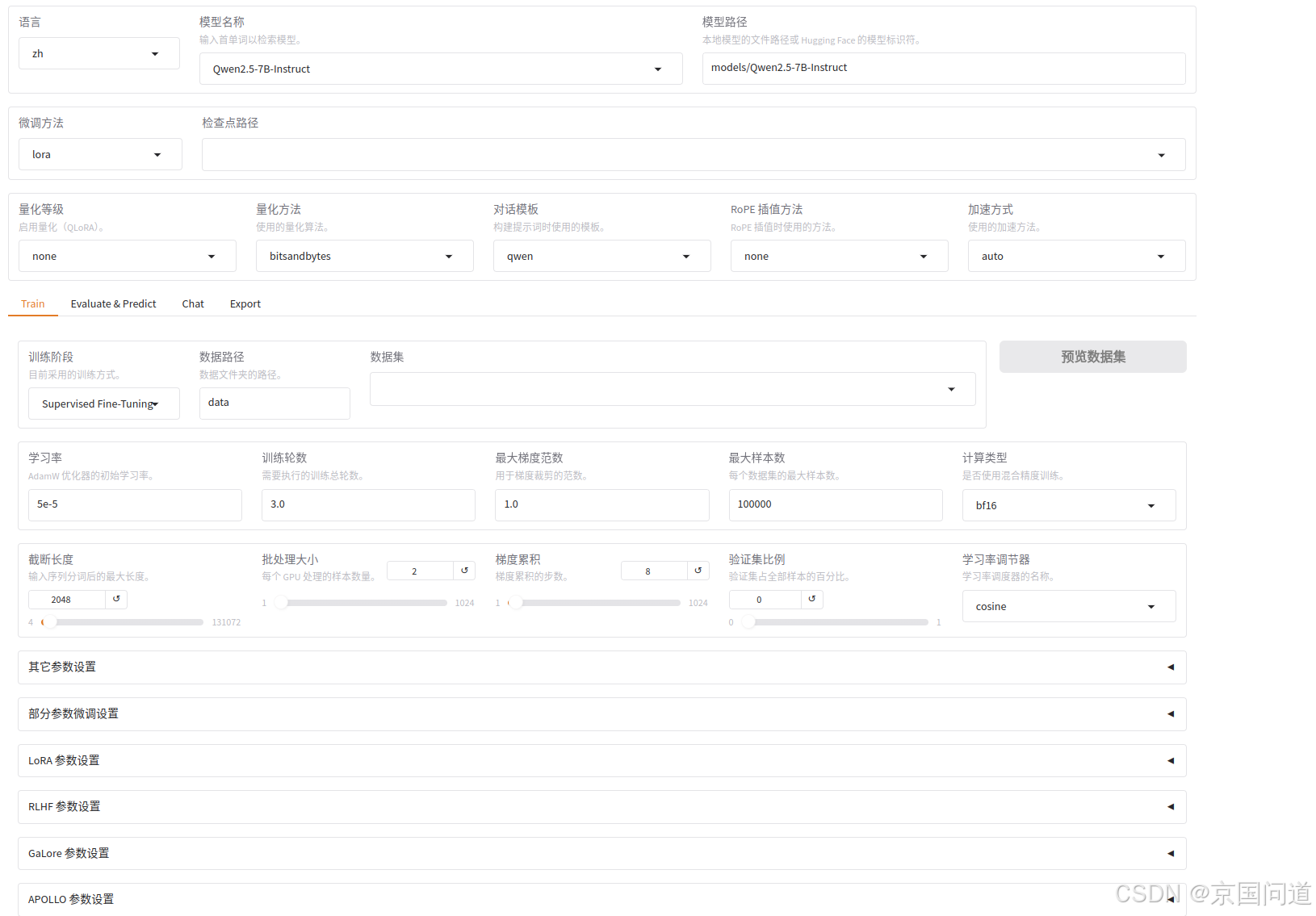
1.语言:我们选择中文zh,
2.模型选择:选择微调的模型名称
3.模型路径:默认情况下是是从HuggingFace上下载路径,也可以进行自定义设置本地模型。由于国内无法正常登录HuggingFace网站,我这里是使用提前从魔塔社区下载好的模型文件。models/Qwen2.5-7B-Instruct,是我的模型文件存放的路径。
4.微调方法:可以选择三种方法,full全参数微调,freeze冻结部分参数,LoRA(Low-Rank Adaptation)低秩矩阵适配器。
full全参数微调是对全部参数进行调整,是模型最大的适应性,用全面调整模型以适应新任务。通常能够达到最佳性能。但是全参数微调需要计算和更新大量的参数,对计算资源和数据要求非常高,一般很难达到。
freeze冻结部分参数,训练速度比全参数微调快,会降低计算资源需求。
LoRA :显著减少了可训练参数数量,降低内存需求,训练速度快,计算效率高。还可以为不同任务保存多个小型适配器,减少了过拟合风险。
QLoRA训练速度跟 LoRA 差不多,基本保持了 LoRa 的优势,会进一步减少内存使用。
综合性能和资源来看,我选择LoRA方法进行微调。
5.检查点路径:是模型训练过程中的一个快照,保存了模型的权重、优化器状态等信息。主要用于保存训练进度允许从中断点恢复训练,性能评估等。如果不需要从中断点恢复训练,此项可以不用填。
6.量化等级:量化等级有8位量化和4位量化,QLoRA允许使用低位量化,减少计算资源,使得LoRA方法更加高效进行。默认选择位none,在这里我不使用量化,故选择none。
量化方法:分为bitsandbytes、hqq、eetq,其中bitsandbytes方法是最常用和最流行的量化方法。
BitsandBytes 是一种基于低精度数值表示的量化方法,通常将模型参数从浮点数(如FP32)转换为低精度格式(如INT8、INT4),从而减少存储和计算开销。这个方法精度损失可能会比较大,但是简单高效,适合通用场景。
HQQ 是一种基于半精度(FP16)和四分位数的混合量化方法。它通过将模型参数分为高精度和低精度两部分,分别用FP16和四分位数表示,从而实现高效的量化。这个方法平衡了精度和性能,适合高精度任务,但是复杂程度较高。
EETQ 是一种基于张量分解和弹性量化的方法,通过将模型参数分解为多个低秩张量,并对每个张量进行弹性量化,从而实现高效的压缩和加速。这个方法实现了高压缩率,适合大规模模型,实现起来比较复杂,计算开销大。
7.提示模板:就是构建结构化输入的一种方式,好的提示模板可以显著提高模型的性能和使用性,根据不同的需求,定义不同的提示模板。
8.RoPE插值方法:线性插值和动态NTK缩放,线性插值简单直观,动态NTK缩放更灵活,可以适应不同长度的输入。
在模型量化中,RoPE(Rotary Position Embedding)插值方法 是一种用于处理位置编码的技术,特别适用于基于Transformer的模型(如LLaMA、GPT等)。RoPE 是一种相对位置编码方法,通过旋转矩阵将位置信息嵌入到模型的注意力机制中。在模型量化过程中,RoPE 插值方法可以帮助减少位置编码的存储和计算开销,同时尽量保持模型的性能。
由于目前我在使用过程中没有进行量化,所以上面有关量化的几个参数暂时不做深入研究。
9.加速方式:auto,unsloth,flashattn2。
auto自动模式会根据你的硬件配置和当前的训练任务自动选择最适合的加速技术。这是最简单的一种方式,不需要用户进行任何额外配置。
FlashAttention2 是一种优化的注意力机制,旨在加速 Transformer 模型的训练。它通过优化内存访问和计算流程来提高训练速度。
Unsloth 是一种特定的优化技术,用于减少训练过程中的计算冗余和内存占用,从而加快训练速度。
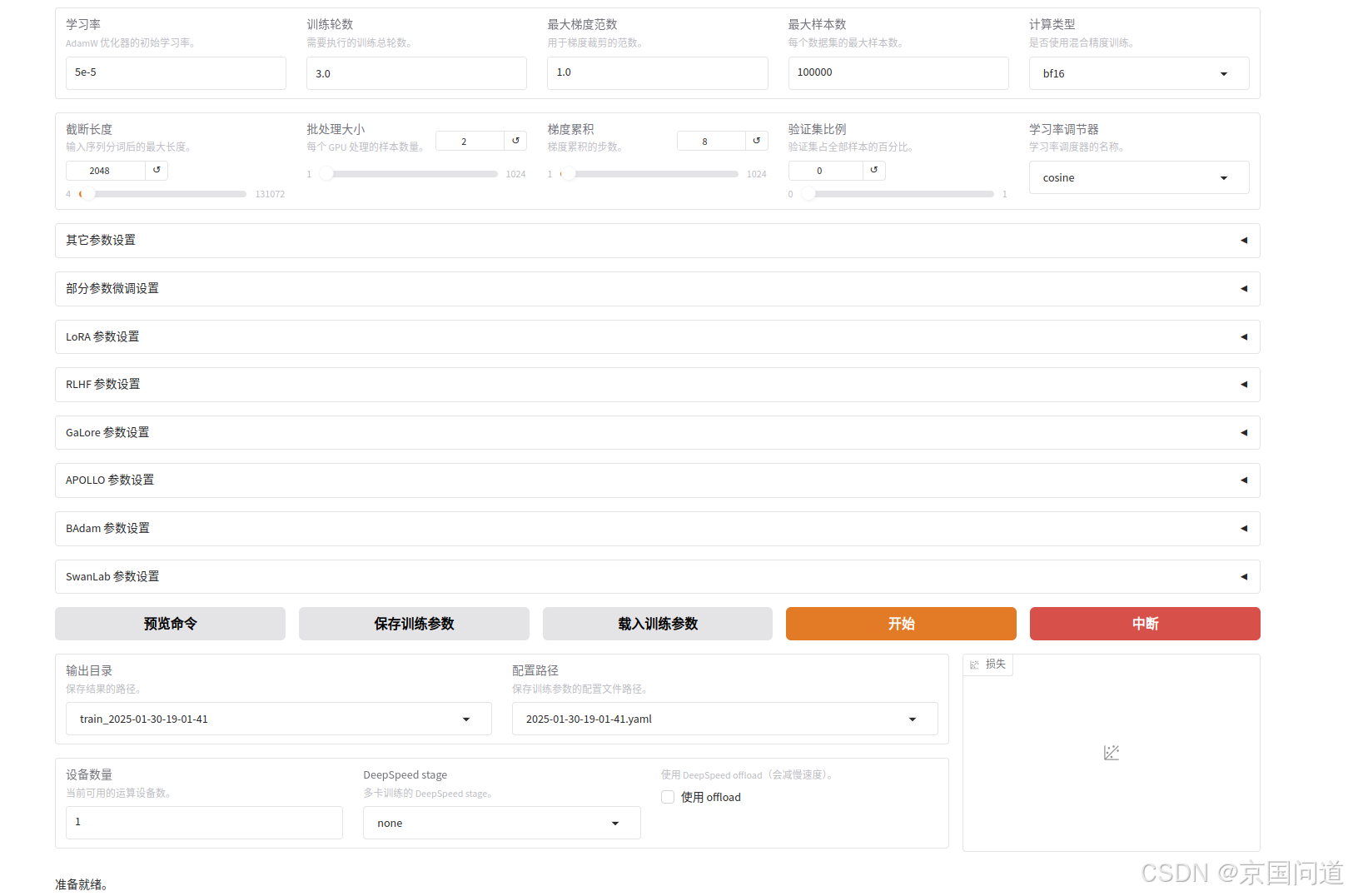
2.训练参数
1.训练阶段:常用的就是监督学习微调,还有奖励模型等。
2.数据路径:默认使用data路径。
3.数据集:根据需要进行选择。我的数据集使用的是修改后的identy.json文件。
4.学习率:在模型微调(Fine-tuning)过程中,学习率(Learning Rate) 是一个非常重要的超参数,它控制着模型参数在每次更新时的调整幅度。学习率的大小直接影响模型的训练速度、收敛性以及最终性能。较大的学习率参数更新幅度较大,可能会导致模型在最优解附近震荡,甚至无法收敛。较小的学习率参数更新幅度较小,可能会导致模型收敛速度过慢,训练时间长。
学习率的选择,在微调预训练模型时,学习率通常设置为一个较小的值,如e−5 到 e−3。因为预训练模型的参数已经接近最优解,只需要小幅度调整即可。在对identy进行训练时,由于数据集较小,我使用的学习率为也比较小,为1e-5。
5.训练轮数:对于大语言模型的微调,通常在2-10个epoch之间,轮数过多可能会导致过拟合,特别是小数据集。经过反复测试后发现,对于小的数据集,训练10轮以内,模型没有学会,无奈将训练轮数设置为了20。
6.最大梯度范围:(Max Gradient Norm)是一种用于防止梯度爆炸的技术,也称为梯度裁剪(Gradient Clipping)。这个参数设置了梯度的最大允许值,如果梯度超过这个值,就会被缩放到这个最大值。最大梯度范围通常在 0.1 到 10 之间,太小:可能会限制模型学习,太大:可能无法有效防止梯度爆炸。
梯度爆炸是指在深度学习模型的训练过程中,梯度值变得异常大,导致模型参数更新时出现剧烈波动,进而影响训练的稳定性和收敛性。梯度爆炸形成的原因:
1.网络深度:深层网络在反向传播时,梯度通过链式法则逐层积累,可能导致梯度值指数级增长。
2.激活函数:某些激活函数在特定区域梯度较大,容易引发梯度报站。
3.权重初始化:权重初始化不当,尤其是初始值过大,也会导致梯度爆赞。
4.学习率:过高的学习率会使参数更新幅度过大,增加梯度爆炸的风险。
7.最大样本数:它决定了每个数据集中使用多少样本进行训练,如果原始数据集很大,设置一个合理的最大样本数可以减少训练时间,如果计算资源有限,较小的样本数可以加快训练速度。样本是模型训练的基本单位,具体形式因任务而异,可以是一个单轮对话,也可以是一个多轮对话,也可以是一个文本生成任务。
8.计算类型:有 bf16 fp16 fp32 purebf16,如果你的硬件支持 bfloat16,且你希望最大化内存效率和计算速度,可以选择 bf16 或 purebf16。
如果你的硬件支持 fp16,你希望加速训练过程且能够接受较低的数值精度,可以选择 fp16。
如果你不确定你的硬件支持哪些类型,或你需要高精度计算,可以选择 fp32。
FP16为半精度浮点数,数值范围为±65504,尾数位为10位,精度高。
BF16相比FP16,数据范围更大,精度更高,数值范围为±3.39e38,尾数位为7位,精度相对较差。
9.截断长度:是指在处理输入序列时,模型所能接受的最大标记(token)数量。如果输入序列超过了这个长度,多余的部分将被截断,以确保输入序列长度不会超出模型的处理能力。
对于文本分类任务,通常截断到 128 或 256 个标记可能就足够了;而对于更复杂的任务,如文本生成或翻译,可能需要更长的长度。
截断长度通常根据模型的输入限制和任务需求设置。
10.批处理大小:批处理大小是指在每次迭代中输入到模型中的样本数量。在深度学习训练过程中,数据通常会被分成多个批次(batch)进行处理,每个批次包含一组样本。较大的批处理大小会占用更多的内存(显存)。如果批处理大小过大,可能导致显存不足,训练无法进行。
合理的批处理大小可以提高计算效率,大批量的数据可以更有效地利用 GPU 进行并行计算。
11.梯度累计:是一种有效的策略,用于在受限的 GPU 内存情况下模拟更大的批处理大小。
12.验证集比例:是指在机器学习和深度学习模型训练过程中,从训练数据集中划分出来的一部分数据,用于评估模型的性能。
验证集的数据不参与模型的训练,仅用于在训练过程中监控模型的表现,以防止过拟合和调整模型的超参数,常见的比例有 10%、20%等,具体选择取决于数据集的大小和具体的应用场景。
13.学习率调节器:训练过程中保持学习率不变。随着训练进行,逐步减小学习率。
每隔一定的训练轮数(epoch),将学习率按某个比例缩小。在每个周期内,学习率呈现余弦函数形态变化。如 Adam 、Adagrad 、RMSprop 等,根据梯度变化动态调整学习率。
14.在LoRA参数设置中还存在两个比较重要的参数,LoRA秩, 是低秩矩阵的维度,决定了低秩矩阵的大小。默认值为8,经过反复试验,在进行小数据集训练时,由于模型记不住训练数据,将LoRA矩阵的秩调整为32。增加更多的参数去扩大微调对整个模型的影响。
秩的作用
-
控制参数数量:秩 r越小,低秩矩阵 A和 B的参数数量越少,训练开销越小。
-
影响模型能力:秩 r越大,低秩矩阵的表示能力越强,但训练开销也会增加。
典型值
-
秩 r 的典型取值范围是 4 到 64,具体取决于任务复杂度和模型规模。
-
对于较小的任务,可以使用较小的秩(如 8 或 16)。
-
对于复杂的任务,可以使用较大的秩(如 32 或 64)。
15.在LoRA参数设置中的LoRA缩放系数(Alpha),默认值为16。缩放系数 是一个超参数,用于控制低秩矩阵 AA和 B 对原始权重矩阵 W 的更新强度。在我的小数据集微调中,LoRA缩放系数为128。
作用
-
控制更新强度:缩放系数 α越大,低秩矩阵对原始权重的更新强度越大。
-
平衡训练稳定性:合适的缩放系数可以避免更新过大或过小,从而保证训练的稳定性。
典型值
-
缩放系数 α 通常设置为秩 r的 2 倍左右。例如:
-
如果秩 r=8,则 α=16。
-
如果秩 r=16,则 α=32。
-
-
秩 r决定了低秩矩阵的规模,直接影响参数数量和模型能力。
-
缩放系数 α决定了低秩矩阵对原始权重的更新强度。
-
关系公式:
更新强度=α/r
这意味着:
-
如果 α固定,增加秩 r会降低更新强度。
-
如果秩 r 固定,增加 α会提高更新强度。
-
16.训练
然后接下来选择我们微调要保存的目录即可。点击开始,然后右边会有微调过程中损失函数曲线,会越来越收敛,误差越来越小,直到某个阀值。
3.chat页面参数设置
在chat页面需要指定模型、 适配器 及 推理引擎 后输入对话内容与模型进行对话观察效果。
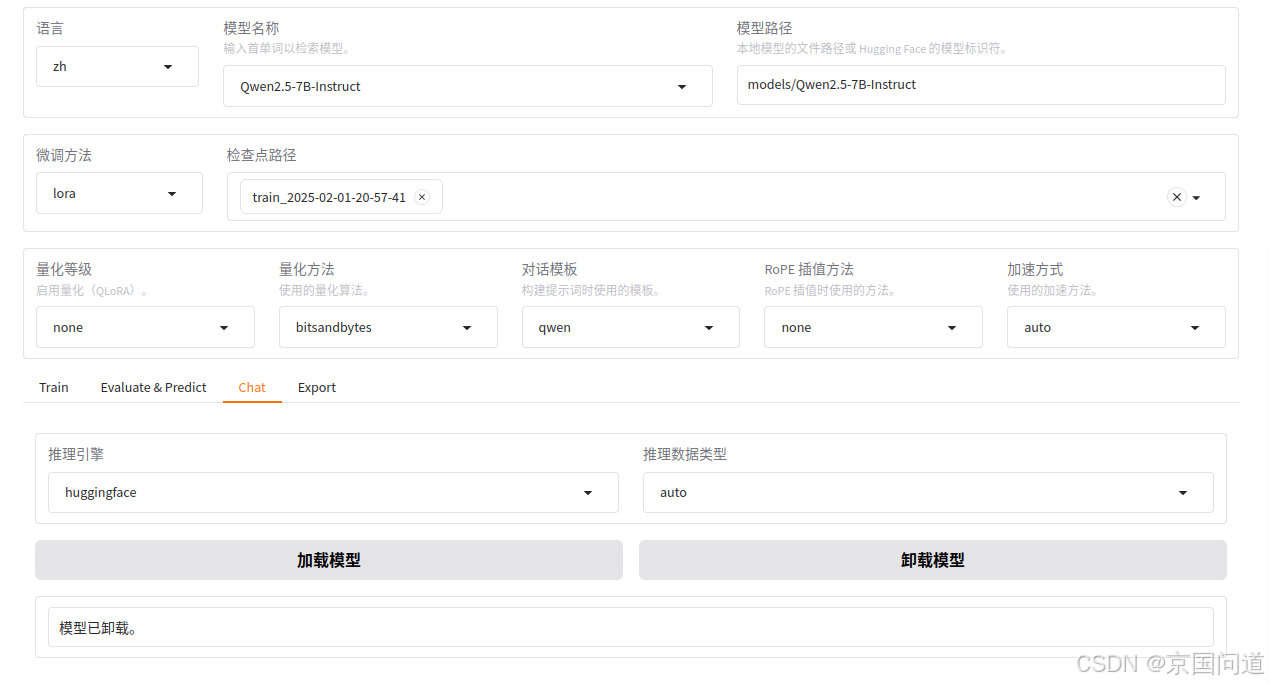
在通用参数部分有一个参数为检查点路径,从下拉列表中选择你训练好的适配器,
推理引擎选择huggingface,推理数据类型选择auto,
点击加载模型,会同时加载微调模型和微调后的适配器,完成chat对话。
4.export页面参数设置
export页面的作用是将模型和适配器进行合并。
当我们使用 LoRA 训练结束以后,获得的实际上是一个适配器。单独的适配器需要和模型一起使用,我们也可以使用 LLaMA Factory 的模型合并功能将适配器和模型基座组装成一个完整的模型。
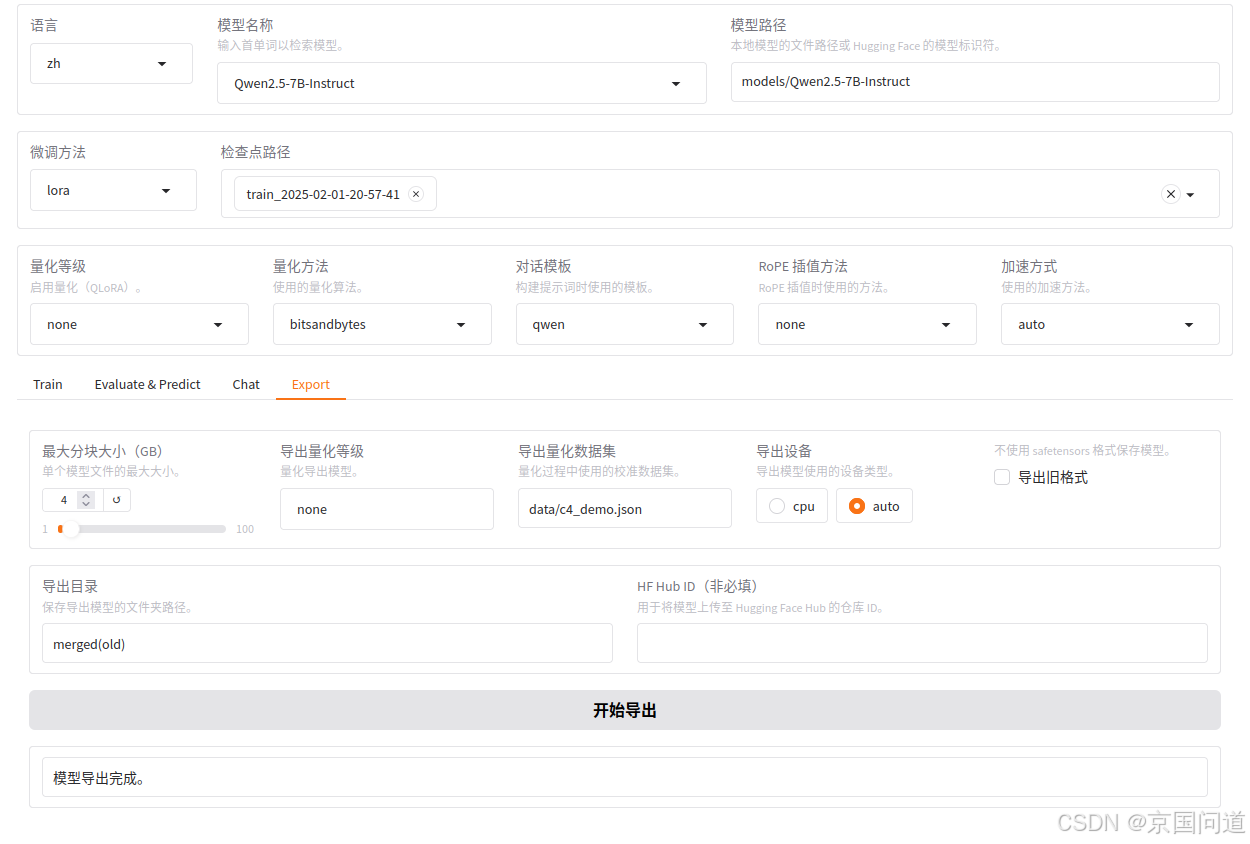
适配器路径、提示模板、RoPE 插值方法的选择应与上述模型推理和对话过程中的选择保持一致。
适配器路径为检查点路径,然后在下面点击 Export 面板,最大分块大小、导出量化等级、导出量化数据集均不需要修改,只需要指定导出目录。点击开始导出,等待导出完毕即可。
三、总结
在 LLaMA Factory 的 webui 里面,一切微调都是可视化,方便我们入手。
我们可以不用了解每个参数背后的具体实现手段,但一定要知道每个参数的含义,大模型的微调不是一蹴而就,而是不断更新和优化。
我们可能要调试各种参数之间的搭配,最后得到一个接近我们任务的大模型。
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)