

【飞桨黑客松】AIGC - DreamBooth LoRA 文生图模型微调
【PaddlePaddle Hackathon 第四期】No.105 官方Baseline指导:基于PaddleNLP PPDiffusers 训练 AIGC 趣味模型
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>

本教程将从以下三个方面带领大家熟悉整个流程。
- 1. 准备工作
- 1.1 环境安装
- 1.2 Hugging Face Space 注册和登录
- 2. 如何训练
- 2.1 上传图片
- 2.2 训练参数调整
- 2.3 可视化训练过程
- 2.4 挑选满意的权重上传至Huggingface
- 3. 其他个性化微调方法
- 3.1 Textual Inversion
- 3.2 Dreambooth
- 3.3 Controlnet
1. 准备工作
1.1 环境安装
在开始之前,我们需要准备我们所需的环境,运行下面的命令安装依赖。为了确保安装成功,安装完毕请重启内核!(注意:这里只需要运行一次!)
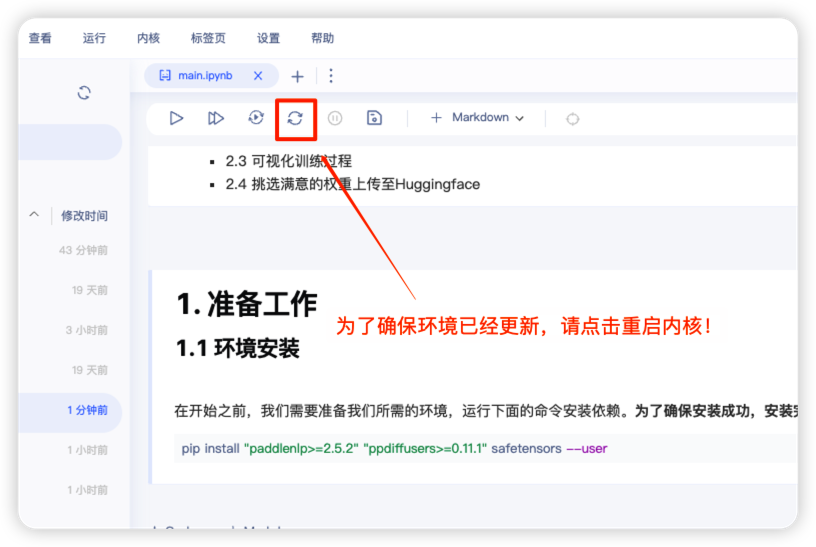
pip install "paddlenlp>=2.5.2" "ppdiffusers>=0.11.1" safetensors --user
# 请运行这里安装所需要的依赖环境!!
!pip install "paddlenlp>=2.5.2" safetensors "ppdiffusers>=0.11.1" --user
1.2 Hugging Face Space 注册和登录
题目要求将模型上传到 Hugging Face,需要先注册、登录。
-
注册和登录:https://huggingface.co/join

-
获取登录 Token



-
Aistudio 登录 Huggingface Hub

Tips:为了方便我们之后上传权重,我们需要登录 Huggingface Hub,想要了解更多的信息我们可以查阅 官方文档。
!git config --global credential.helper store
from huggingface_hub import login
login()
VBox(children=(HTML(value='<center> <img\nsrc=https://huggingface.co/front/assets/huggingface_logo-noborder.sv…
- tips:如何检测是否登录成功?
打开日志控制控制台,查看日志。

登录成功时,日志如下:

2. 如何训练模型,并上传到HF
2.1 上传图片
- 首先,我们需要将所需训练的图片上传到aistudio上的文件夹, 我们可以通过👉拖拽上传 的方式,将我们所需的图片上传至指定的文件夹。
- 在这里,我们已经在👉dogs文件夹准备好了如下所示的5张图片。

2.2 训练参数调整
在训练过程中,我们可以尝试修改训练的默认参数,下面将从三个方面介绍部分参数。
👉主要修改的参数:
- pretrained_model_name_or_path :想要训练的模型名称或者本地路径的模型,例如:
"runwayml/stable-diffusion-v1-5",更多模型可参考 PaddleNLP 文档。- instance_data_dir:训练图片所在的文件夹目录,我们可以将图片上传至aistudio项目。
- instance_prompt:训练所使用的
Prompt文本。- resolution:训练时图像的分辨率,建议为
512。- output_dir:训练过程中,模型保存的目录。
- checkpointing_steps:每隔多少步保存模型,默认为
100步。- learning_rate:训练使用的学习率,当我使用
LoRA训练模型的时候,我们需要使用更大的学习率,因此我们这里使用1e-4而不是2e-6。- max_train_steps:最大训练的步数,默认为
500步。
👉可选修改的参数:
- train_batch_size:训练时候使用的
batch_size,当我们的GPU显存比较大的时候可以加大这个值,默认值为4。- gradient_accumulation_steps:梯度累积的步数,当我们GPU显存比较小的时候还想模拟大的训练批次,我们可以适当增加梯度累积的步数,默认值为
1。- seed:随机种子,设置后可以复现训练结果。
- lora_rank:
LoRA层的rank值,默认值为4,最终我们会得到 3.5MB 的模型,我们可以适当修改这个值,如:32、64、128、256等。- lr_scheduler:学习率衰减策略,可以是
"linear", "constant", "cosine"等。- lr_warmup_steps:学习率衰减前,
warmup到最大学习率所需要的步数。
👉训练过程中评估使用的参数:
- num_validation_images:训练的过程中,我们希望返回多少张图片,默认值为
4张图片。- validation_prompt:训练的过程中我们会评估训练的怎么样,因此我们需要设置评估使用的
prompt文本。- validation_steps:每隔多少个
steps评估模型,我们可以查看训练的进度条,知道当前到了第几个steps。
🔥Tips:
训练过程中会每隔 validation_steps 将生成的图片保存到 {你指定的输出路径}/validation_images/{步数}.jpg
👉权重上传的参数:
- push_to_hub: 是否将模型上传到
huggingface hub,默认值为False。- hub_token: 上传到
huggingface hub所需要使用的token,如果我们已经登录了,那么我们就无需填写。- hub_model_id: 上传到
huggingface hub的模型库名称, 如果为None的话表示我们将使用output_dir的名称作为模型库名称。
在下面的例子中,由于我们前面已经登录了,因此我们可以开启 push_to_hub 按钮,将最终训练好的模型同步上传到 huggingface.co
当我们开启push_to_hub后,等待程序运行完毕后会自动将权重上传到这个路径 https://huggingface.co/{你的用户名}/{你指定的输出路径} ,例如: https://huggingface.co/junnyu/lora_outputs
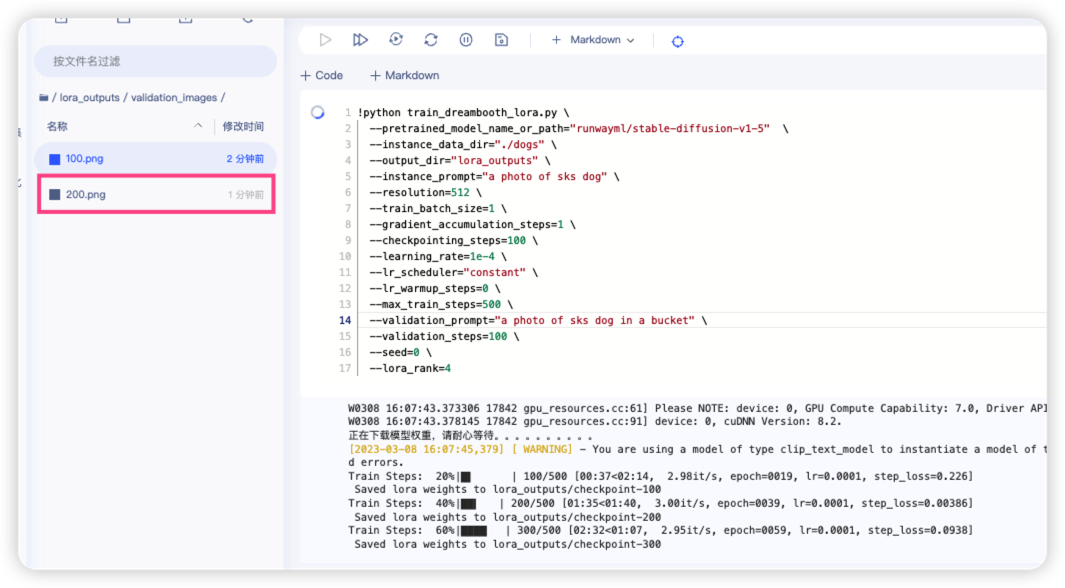
!python train_dreambooth_lora.py \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5" \
--instance_data_dir="./dogs" \
--output_dir="lora_outputs" \
--instance_prompt="a photo of sks dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--checkpointing_steps=100 \
--learning_rate=1e-4 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--seed=0 \
--lora_rank=4 \
--push_to_hub=False \
--validation_prompt="a photo of sks dog in a bucket" \
--validation_steps=100 \
--num_validation_images=2
W0314 10:41:55.169677 3273 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0314 10:41:55.174046 3273 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
正在下载模型权重,请耐心等待。。。。。。。。。。
100%|███████████████████████████████████████████| 312/312 [00:00<00:00, 202kB/s]
100%|████████████████████████████████████████| 842k/842k [00:00<00:00, 1.90MB/s]
100%|████████████████████████████████████████| 512k/512k [00:00<00:00, 3.20MB/s]
100%|████████████████████████████████████████| 2.00/2.00 [00:00<00:00, 1.85kB/s]
100%|███████████████████████████████████████████| 478/478 [00:00<00:00, 354kB/s]
100%|███████████████████████████████████████████| 592/592 [00:00<00:00, 403kB/s]
[33m[2023-03-14 10:41:59,583] [ WARNING][0m - You are using a model of type clip_text_model to instantiate a model of type . This is not supported for all configurations of models and can yield errors.[0m
100%|███████████████████████████████████████████| 342/342 [00:00<00:00, 262kB/s]
100%|████████████████████████████████████████| 469M/469M [04:03<00:00, 2.02MB/s]
100%|████████████████████████████████████████| 319M/319M [01:36<00:00, 3.46MB/s]
100%|███████████████████████████████████████████| 610/610 [00:00<00:00, 362kB/s]
100%|██████████████████████████████████████| 3.20G/3.20G [01:36<00:00, 35.6MB/s]
100%|███████████████████████████████████████████| 807/807 [00:00<00:00, 586kB/s]
Train Steps: 10%|▉ | 50/500 [00:19<02:31, 2.98it/s, epoch=0009, lr=0.0001, step_loss=0.158]
100%|███████████████████████████████████████████| 601/601 [00:00<00:00, 261kB/s][A
100%|███████████████████████████████████████████| 342/342 [00:00<00:00, 142kB/s][A
Train Steps: 20%|█▏ | 100/500 [00:50<02:14, 2.98it/s, epoch=0019, lr=0.0001, step_loss=0.00531]
Saved lora weights to lora_outputs/checkpoint-100
Train Steps: 40%|███▏ | 200/500 [01:51<01:41, 2.95it/s, epoch=0039, lr=0.0001, step_loss=0.026]
Saved lora weights to lora_outputs/checkpoint-200
Train Steps: 60%|████▊ | 300/500 [02:53<01:08, 2.94it/s, epoch=0059, lr=0.0001, step_loss=0.108]
Saved lora weights to lora_outputs/checkpoint-300
Train Steps: 80%|███████▏ | 400/500 [03:54<00:34, 2.92it/s, epoch=0079, lr=0.0001, step_loss=0.13]
Saved lora weights to lora_outputs/checkpoint-400
Train Steps: 100%|██████| 500/500 [04:55<00:00, 2.96it/s, epoch=0099, lr=0.0001, step_loss=0.00451]
Saved lora weights to lora_outputs/checkpoint-500
Model weights saved in lora_outputs/paddle_lora_weights.pdparams
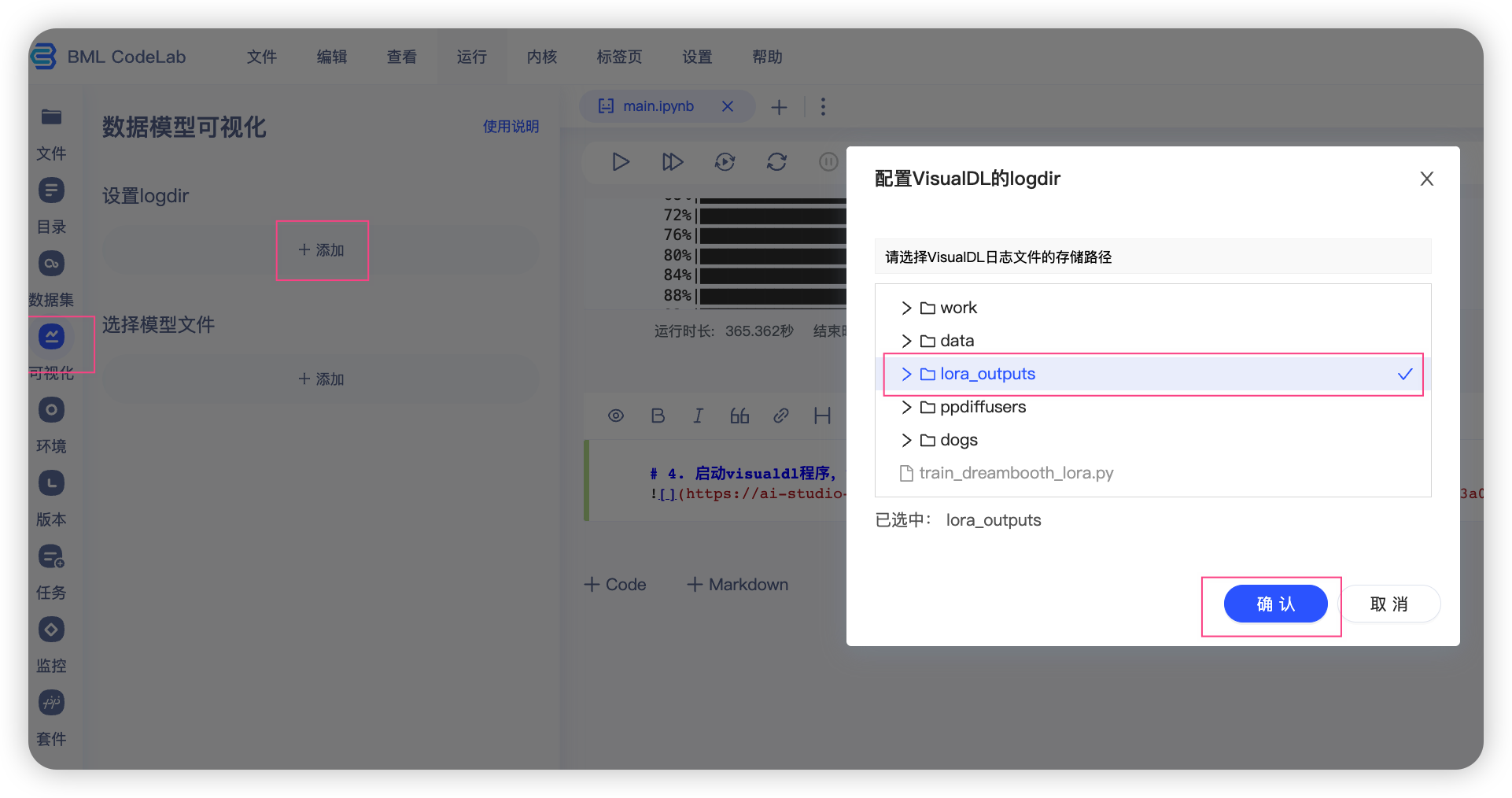
2.3 可视化训练过程
VisualDL使用参考:官方教程
我们可以参照如图所示的步骤,开启visualdl,然后查看训练过程中的指标变化。
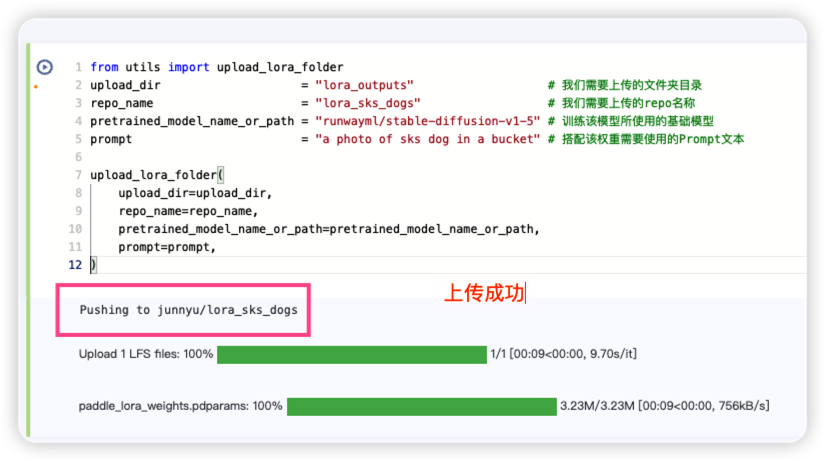
2.4 挑选满意的权重上传至Huggingface
参数解释:
- upload_dir:我们需要上传的文件夹目录。
- repo_name:我们需要上传的repo名称,最终我们会上传到 https://huggingface.co/{你的用户名}/{你指定的repo名称}, 例如: https://huggingface.co/junnyu/lora_sks_dogs.
- pretrained_model_name_or_path:训练该模型所使用的基础模型。
- prompt:搭配该权重需要使用的Prompt文本。
from utils import upload_lora_folder
# 使用前请确保已经登录了huggingface hub!
upload_dir = "lora_outputs" # 我们需要上传的文件夹目录
repo_name = "lora_sks_dogs" # 我们需要上传的repo名称
pretrained_model_name_or_path = "runwayml/stable-diffusion-v1-5" # 训练该模型所使用的基础模型
prompt = "a photo of sks dog in a bucket" # 搭配该权重需要使用的Prompt文本
upload_lora_folder(
upload_dir=upload_dir,
repo_name=repo_name,
pretrained_model_name_or_path=pretrained_model_name_or_path,
prompt=prompt,
)
paddle_lora_weights.pdparams: 0%| | 0.00/3.23M [00:00<?, ?B/s]
Upload 1 LFS files: 0%| | 0/1 [00:00<?, ?it/s]
模型权重已经上传到了, https://huggingface.co/junnyu/lora_sks_dogs/tree/main/
junnyu/lora_sks_dogs/tree/main/
3. 其他个性化微调方法
3.1 Textual Inversion
Textual inversion 是一种能够个性化定制文本生成图像 (text2image) 的技术。我们只需要给模型提供 3-5 张图片,就可以训练个性化的Stable Diffusion模型。
它的优势是轻量级、简单上手,它可以对主体(object)进行训练,让 AI 记住这个“人”或“物”。同时它也可以对画风(style)进行训练,比如可以记住某位在世艺术家的画风然后让 AI 以此画风来画任何事物。训练过程中我们只训练了部分参数,因此训练出的模型文件通常只有 5~10 KB 左右,我们可以以极低的代价将该权重加载到我们现有的模型中。
PPDiffusers 当前已经集成了该方法,我们可以参照教程快速体验。

3.2 Dreambooth
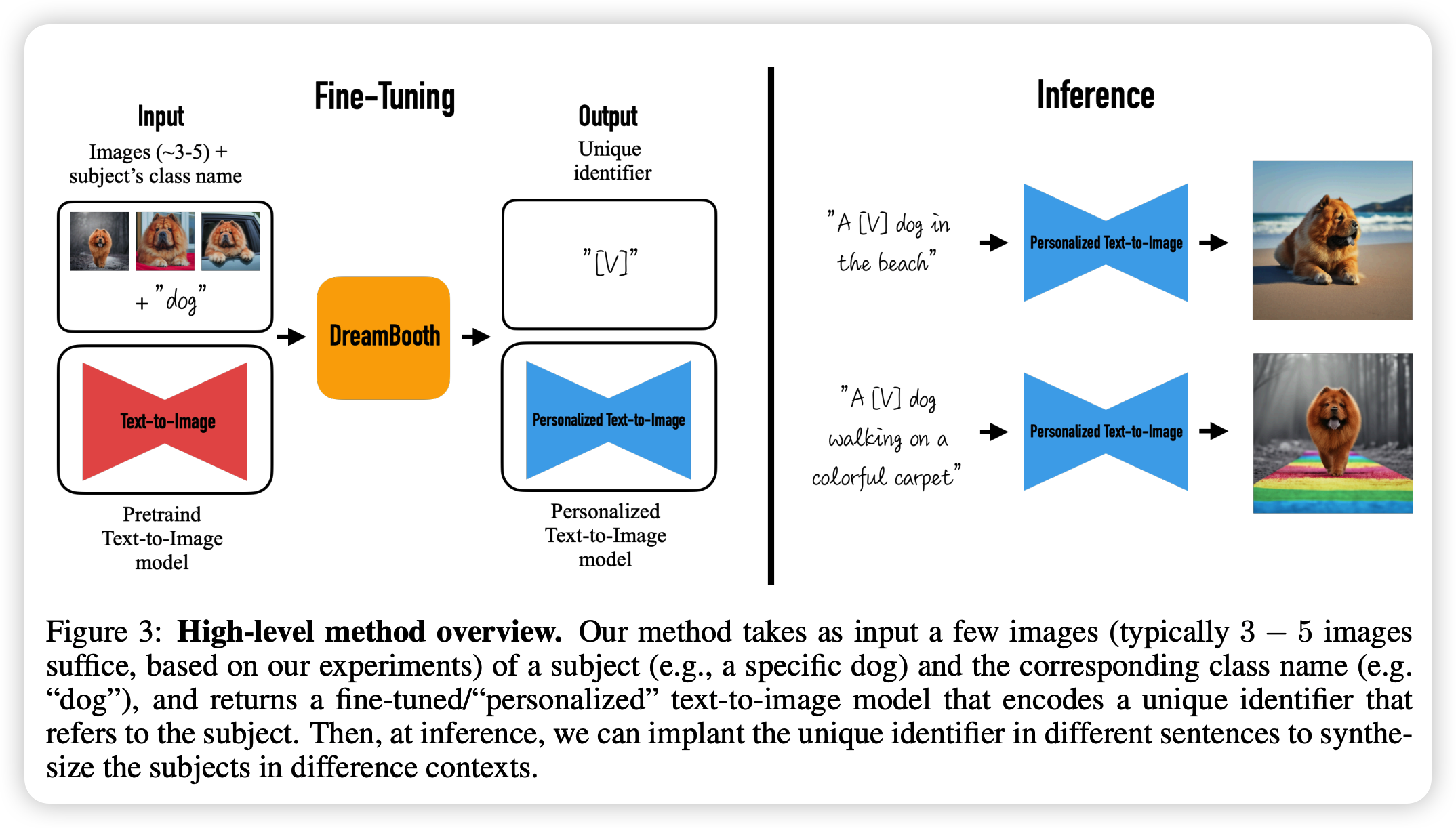
DreamBooth 同样也是一种能够个性化定制文本生成图像 (text2image) 的技术。我们也只需几张(通常 3~5 张)指定物体的照片和相应的类名(如“狗”)作为输入,并添加一个唯一标识符植入不同的文字描述中,DreamBooth 就能让被指定物体“完美”出现在用户想要生成的场景中。
由于该方法需要微调整个模型,因此该方法相对于 Textual Inversion 来说需要更多的计算资源。
PPDiffusers 当前已经集成了该方法,我们可以参照教程快速体验。
3.2 ControlNet
ControlNet 是最近非常火的一种可控生成技术,该模型通过添加额外条件来控制扩散模型的神经网络结构,从而实现对画面更细致的控制,更直观的表达就是,在随机扩散的画面体系里面,增加可控的神经网络结构(比如线稿,姿态),去约束扩散过程,从而实现准确的表达。
PPDiffusers 当前已经集成了该方法,我们可以参照教程快速体验。


欢迎加入NLP技术交流群,一起相互讨论交流~

更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)