

大模型微调知识分享 | 微调Deepseek-R1-1.5B代码案例
大模型微调分享JBPMG&ITCenter(该内容已经过敏感词和机密词过滤,欢迎大家在保密基础上进行基础技术讨论)
大模型微调分享
JBPMG&ITCenter(该内容已经过敏感词和机密词过滤,欢迎大家在保密基础上进行基础技术讨论)
目录

一、模型下载
权威网站
下载方式
以魔塔网站为例
- cmd命令
#pip方式
pip install "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
#modelscope方式
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
- python下载
from modelscope import snapshot_download
model_id = 'deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B'# 指定模型ID和本地存储路径
local_dir = 'LLaMA-Factory/bbmodel/qwen'
snapshot_download(model_id, local_dir=local_dir)# 调用snapshot_download函数下载模型
- 直接官网下载

二、模型vllm部署
常用的源码包
peft (Parameter-Efficient Fine-Tuning)
用于参数高效微调,只微调模型的一小部分参数,从而减少计算资源和时间的消耗:
- 提供多种参数高效微调技术,如Adapter、LoRA、Prompt Tuning等。
- 支持多种流行的预训练模型,如BERT、GPT等
- 易于集成到现有的训练流程中。
- 其中LoRA通过在预训练模型的权重矩阵中引入低秩矩阵来减少参数数量。在模型微调阶段,可以在不显著增加参数的情况下对模型进行定制。
deepspeed
一款用于加速深度学习训练的开源库:
- 提供多种优化技术,如混合精度训练、梯度累积、分布式训练等。
- 提供易于使用的API,方便用户集成到现有的训练流程中。
- 适用于需要加速深度学习训练的场景,特别是针对大型模型和大规模数据集的训练任务
Flash Attention
是一种高效的注意力机制实现,旨在加速Transformer模型的训练和推理过程:
- 利用高效的算法和数据结构,减少注意力机制的计算复杂度。
- 支持多种硬件平台,如CPU、GPU等。
- 易于集成到现有的Transformer模型中。
vLLM(Virtual Large Language Model)
是一款专为大语言模型推理加速而设计的框架,实现了 KV 缓存内存几乎零浪费,解决了内存管理
特点:
- 使用 PagedAttention 高效管理注意力键和值的内存,连续批处理传入请求。
- 使用 CUDA/HIP 图实现快速执行模型,优化的 CUDA 内核。
- 提供LoRA适配器。**LoRA(Low-Rank Adaptation)**是一种针对大规模预训练模型的参数高效微调方法。它通过在模型层中引入低秩矩阵来减少需要训练的参数数量,从而实现快速、高效的模型适配。以下是LoRA的详细介绍:
vllm部署
大模型vllm总结与代码理解https://blog.csdn.net/weixin_45320238/article/details/144431366?spm=1001.2014.3001.5502
我们在我们的环境中使用下面命令安装vllm,并进行模型部署
# 安装vllm
pip install vllm
# 部署vllm
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
vllm部署后会形成api,我们通过代码调用api即可访问。稍后我们会在微调模型的过程中演示以下
三、模型微调
以如何教一个小孩子看书为例,介绍模型微调的4个过程
数据处理
数据收集、数据预处理(质量过滤、去重、隐私删减、token化、数据清洗、格式化、归一化等步骤)、数据调度(多数据源数据混合配比、数据课表控制数据训练顺序)
| 过程 | 训练大模型 | 小孩子学习看书 |
|---|---|---|
| 数据处理 | 数据处理是机器学习中的第一步 | 想象一个小孩子在开始读书之前,需要确保书是干净的、没有破损的,并且书的排版和字体是他能容易阅读的。这个过程就像数据处理,孩子需要把书整理好,比如把撕破的页角粘好(数据清洗),确保书中的文字大小和间距适合阅读(格式化),并且把书中的内容按照他能够理解的方式重新组织(归一化)。 |
提示词工程
| 过程 | 训练大模型 | 小孩子学习看书 |
|---|---|---|
| 提示词工程 | 在输入数据中设计特定的提示词或模板,以引导模型生成更符合预期的输出。 | 当小孩子读书时,家长或老师可能会在书中某些部分做标记或给出提示,比如“这里很重要,仔细读”或者“想想这部分和前面学过的内容有什么联系”。这些标记和提示就像提示词工程,它们帮助孩子在阅读时关注重点,引导孩子更好地理解和记忆书中的内容。 |
超参数工程
调参经验总结https://blog.csdn.net/weixin_45320238/article/details/143118301?spm=1001.2014.3001.5502
| 超参数 | 训练大模型 | 小孩子学习看书 |
|---|---|---|
| epochs | 整个数据集上训练的轮数 | 他需要反复阅读同一本书来加深理解。每一遍阅读可以类比为一次epoch。如果孩子阅读了这本书10遍,那么就相当于进行了10个epochs的训练。 |
| batch_size | 每次训练时输入模型的样本数量 | 小孩子每次阅读书中的一页可以类比为一个batch。如果孩子每次阅读多页(大的batch_size),他可以更全面地理解书的内容,但同时需要更好的专注力和更长的时间;如果孩子每次只阅读几行(小的batch_size),他可以更快地完成阅读,但可能无法很好地把握整体内容。 |
| accumulation steps | 累积多少个小batch后进行一次参数更新 | 假设小孩子每次只能理解书中的几句话,他需要把这几句话的意思积累起来,才能理解一个段落。这里,每理解几句话就相当于一个步数,累积足够多的步数(比如5步)后,他才能完全理解一个段落,这就像是模型累积了5个步数后进行一次模型权重的更新。 |
| cutoff_len | 模型在训练或推理时,输入序列的最大长度 | 假设小孩子每次只能集中注意力阅读书中的10行文字。这10行文字就相当于模型的cutoff len。如果书中的一段文字超过了10行,孩子就会忽略超出的部分,只专注于他能够处理的10行 |
| learning rate | 学习率决定了模型在每次更新时,参数变化的幅度 | 小孩子学习看书的速度可以类比为学习率。如果孩子学习速度太快(学习率过高),他可能会错过书中的细节;如果学习速度太慢(学习率过低),他可能需要花费很长时间才能掌握书中的内容 |
模型评估与测试
常见模型评估标准https://blog.csdn.net/weixin_45320238/article/details/144676787?spm=1001.2014.3001.5502
| 过程 | 训练大模型 | 小孩子学习看书 |
|---|---|---|
| 模型测试 | 衡量模型性能的过程,通过使用测试数据集来检查模型的准确率、召回率、F1 score等指标。 | 小孩子读完书后,家长或老师会通过提问或小测验来检查孩子对书中内容的掌握程度。比如,问孩子书中的主要情节是什么,或者让孩子复述书中的某个故事。这个过程就像模型评估,通过提问(测试数据集)来评估孩子(模型)对书(任务)的理解程度(性能指标)。一次判断孩子是否看懂书,看不懂书让他再学习(再次调整参数训练),这样的每次训练大概要经历20个小时。 |
数据评估方法:
方法一:损失值判断。通过llama_factory框架计算的损失值判断模型优劣。
缺陷:由于loss低不代表准确率就高,可能会出现模型幻觉等问题,以及不同类别准确率的迁移。比如模型得出的loss虽然很低,但他对于我们想要的分类准确率却不理想。
方法二:标注计算准确率。数据评估阶段,需要通过数据标注中的output判断,通过统计数据以评估模型的性能。
四、现场微调一个模型
带领大家花费10分钟时间,通过微调工具llama factory微调一个deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B的大模型。
使用命令
# 微调前的模型部署。deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
# 微调模型10分钟
llamafactory-cli train /home/ubuntu/githubs/LLaMA-Factory/examples/train_lora/qwen2__5_3b_lora.sft.yaml
# 微调后的模型部署。outputparam/aitraining
llamafactory-cli api /home/ubuntu/githubs/LLaMA-Factory/examples/inference/qwen2__5_3b_chat.yaml
使用的数据集:
alpaca_zh_demo是alpaca-chinese-dataset的一个子集,专门用于中文指令微调。该数据集旨在为中文大语言模型提供高质量的训练数据,以提升模型在理解和执行中文指令方面的能力。
{
"0": {
"instruction": "写一个关于上周末你做了什么的简短叙述。",
"input": "",
"output": "由于我是一个人工智能助手,所以我并不能真正的“做”什么事情。我的“工作”时间是24/7无休,确保我随时可供用户提供帮助和服务。所以在上周末,我一直都在“工作”,在响应用户的指令,帮助他们查询信息,执行操作,解决问题。"
},
"1": {
"instruction": "创建一个程序,打印以下图案:",
"input": "",
"output": "您好!以下是一个打印指定图案的示例 Python 程序,它可以打印出一个类似字母“X”的图案。您可以使用程序中的一些规律性代码并对它进行更改,以打印您所需的图案。 ```python size = 7 for row in range(size): for col in range(size): if row == col or row + col == size-1: "}
}
使用的微调框架llama factory
LLaMA-Factory,全称Large Language Model Factory,即大型语言模型工厂。它支持多种预训练模型和微调算法,提供了一套完整的微调工具和接口,使得用户能够轻松地对预训练的模型进行定制化的训练和调整,以适应特定的应用场景,如智能客服、语音识别、机器翻译等。 为下面的包提供接口服务。
LLaMA-Factory框架源码介绍 | 大模型监督微调https://blog.csdn.net/weixin_45320238/article/details/144515546?spm=1001.2014.3001.5502
面向LLaMA-Factory的大模型网格搜索微调工具LLaMA-Factory-Grid-Funetuning-Toolhttps://blog.csdn.net/weixin_45320238/article/details/144497942?spm=1001.2014.3001.5502
输出(微调前)
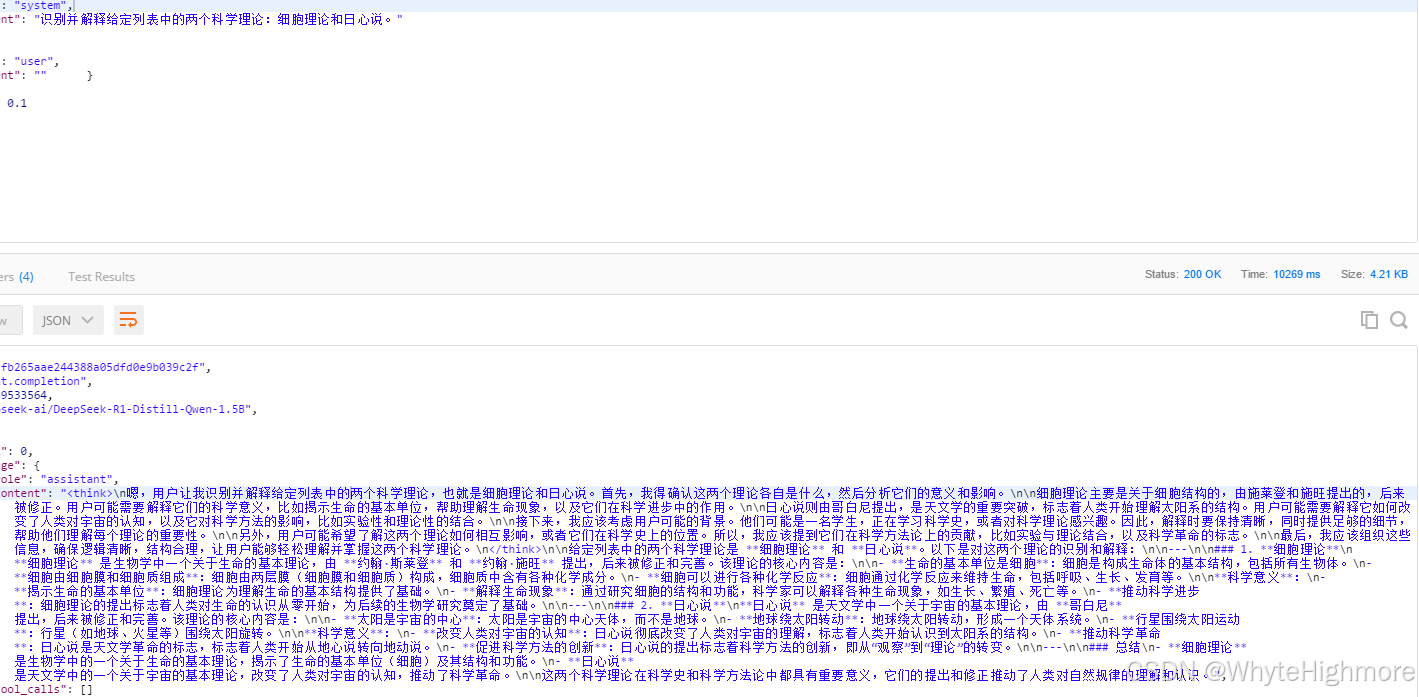
输出(微调后)

五、大模型基础
综述性的论文
内容来源:A Survey of Large Language Models大模型综述论文章节总结https://blog.csdn.net/weixin_45320238/article/details/143023925?spm=1001.2014.3001.5502
Large Multimodal Agents: A Survey大模型多模态综述论文概要总结https://blog.csdn.net/weixin_45320238/article/details/142884989?spm=1001.2014.3001.5502
Large Language Models: A Survey大模型综述论文章节总结https://blog.csdn.net/weixin_45320238/article/details/142884963?spm=1001.2014.3001.5502
大模型发展
最初是解决数学问题。SLM》NLM》PLM》LLM


再到2024年的deepseek(强化学习和知识蒸馏)
大模型的组成
四个agent
3感知代理负责对目标应用程序界面进行离线分析,生成基于UI元素的潜在子任务列表,然后将其存储在应用程序内存中。在在线执行阶段,4选择代理根据用户命令和当前屏幕状态确定要执行的特定子任务。1推理代理进一步识别并完成所选子任务所需的基本动作序列,通过提示LLM。同时,2记忆代理在遇到与先前学习到的任务类似的任务时,可以直接调用和执行来自内存的相应子任务和动作序列。

大模型四种方法
RAG
检索增强生成
工作原理:
检索:根据输入的提示(prompt),模型在大型外部知识库中检索相关的信息片段。
生成:将这些信息片段与输入提示一起作为上下文,生成最终的回答或文本。
prompt
工作原理:
设计提示:创建包含任务指令和部分输入数据的提示。
生成输出:将提示输入到预训练模型中,模型根据提示生成剩余的输出。
fine-tuning
工作原理:
微调:在特定任务的标注数据上继续训练,通常使用较小的学习率。
agent
工作原理:
交互:agent在环境中执行动作,并根据环境的反馈调整其策略。
学习:通过不断的尝试和错误,agent学习如何最大化累积奖励。
RAG适合需要外部知识辅助的问答系统,prompt适合自然语言生成任务,微调适合各种特定的NLP任务,而agent则适合需要连续决策的问题。
微调的种类
| 方法 | 详细方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Adapter Tuning | Transformer 层中添加微调模块 | 参数高效,可自定义适配器 | 适配器设计需要经验 | 想要自定义适配器功能的场景 |
| Prefix Tuning | Transformer 层前添加微调模块 | 参数高效,训练稳定 | 需要设计MLP函数,可能需要额外的数据 | 需要增强特定任务性能的场景 |
| Prompt Tuning | 输入添加提示向量 | 参数最少,简单易用 | 选择一个性能良好的底层模型 | 快速微调场景 |
| QLoRA | 引入了16位网络节点,量化为4位,并采用分页机制交换二进制数据 | 以处理内存有限的大型模型 | 有一些信息损失,但它被认为是可以接受 | |
| 全量微调 | 对预训练模型的全部参数进行微调 | 完全适应特定任务或领域 | 计算资源高,数据量大 | 大型模型 |
| LoRA | 对所选权重矩阵的密集层更新,并添加低秩自适应约束 | 减少模型参数与内存 | 需要选择合适的低秩 | 更适用于有明确任务、需要高性能的场景,如文本分类等。 |
| 强化微调RLFT | 智能体试错,环境反馈,学习策略,最大化奖励,逐步优化 | 无需大量标注数据、自适应性强 | 奖励函数设计困难、训练不稳定,易受环境的影响。 | 强化微调更适用于需要与环境互动、需要学习策略的场景,如游戏、机器人控制等。 |
建议首先尝试通过 prompt engineering、prompt chaining(将复杂的任务分解为多个提示和 function/tool 调用)来获得良好的结果,主要原因是:
- 对于许多任务,我们的模型最初可能表现不佳,但通过更好的提示,我们可以获得更好的结果并且可能不需要进行微调
- 迭代 Prompt 和其他策略比微调迭代具有更快
- 在仍然需要微调的情况下,最初的提示工程工作不会浪费 -在微调数据中使用良好的 Prompt(或将 prompt chaining/function caling 与微调相结合)时,我们通常会看到最佳结果
回来看一下我们模型的输出
六、模型学习与问题解决途径推荐
大模型调研学习途径:
-
大模型类书籍
-
知网、百度学术、谷歌学术等论文调研网站
-
哔哩哔哩、等视频学习网站
-
美团、腾讯等互联厂商的AI腾讯会议论坛
-
深度学习探索等微信公众号
大模型问题解决途径:
- 各个大模型官网
- github论坛
- 飞书问题评论
- CSDN博客(会员申请中,重要VIP材料可以找我下载)
- 智谱清言大模型(用于日常思维问题解决)
- DeepSeek大模型(用于代码生成与提示词规划)
- 秘塔AI大模型(用于学术类概念问题解决)
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)