
Keras预训练模型综合对比
一、说明参考文献:应用 Applications - Keras 中文文档https://keras.io/zh/applications/数据集:https://www.kaggle.com/c/dogs-vs-cats/data80%用于训练(10000张),20%用于验证(2500张)优化器为SGD,学习率0.0001,动量0.9无数据增强迭代次数30批量大小16输入图...
·
| model | convergence | acc | val_acc | loss | val_loss | size | time |
|---|---|---|---|---|---|---|---|
| VGG16 | 42 | 98.94% | 98.94% | 0.0333 | 0.0097 | 88.17MB | 10m12s |
| VGG19 | 38 | 98.39% | 100.00% | 0.0443 | 0.0067 | 100.93MB | 9m48s |
| ResNet50 | 42 | 99.14% | 99.17% | 0.0215 | 0.0134 | 188.21MB | 11m31s |
| InceptionV3 | 25 | 98.29% | 100.00% | 0.0420 | 0.0059 | 211.51MB | 9m12s |
| InceptionResNetV2 | 46 | 98.89% | 99.79% | 0.0284 | 0.0069 | 304.05MB | 30m26s |
| Xception | 20 | 97.73% | 99.79% | 0.0418 | 0.0090 | 279.75MB | 11m36s |
| MobileNet | 9 | 95.51% | 98.96% | 0.1255 | 0.9551 | 61.43MB | 2m5s |
| MobileNetV2 | 17 | 96.72% | 98.96% | 0.0870 | 0.0211 | 70.07MB | 5m0s |
| DenseNet121 | 32 | 98.39% | 99.78% | 0.0450 | 0.0084 | 76.31MB | 10m22s |
| DenseNet169 | 46 | 98.99% | 99.79% | 0.0261 | 0.0081 | 128.49MB | 19m41s |
| DenseNet201 | 20 | 98.24% | 100.00% | 0.0461 | 0.0058 | 162.53MB | 10m13s |
| NASNetMobile | 13 | 96.62% | 99.17% | 0.0843 | 0.0248 | 67.88MB | 9m50s |
| NASNetLarge | 4 | 98.28% | 99.80% | 0.0471 | 0.0045 | 801.81MB | 9m40s |
文章目录
1 说明
- 参考文献:Keras 中文文档 https://keras.io/zh/
- 数据集:https://www.kaggle.com/c/dogs-vs-cats/data 共用2500张,其中80%用于训练(2000张),20%用于验证(500张)
- 优化器为SGD,学习率0.0001,动量0.9
- 批量大小32,NASNetLarge网络为26
- 回调函数ModelCheckpoint,只保存权重
- 回调函数TensorBoard,保存模型图和模型数据
- 回调函数ReduceLROnPlateau,val_loss停止优化10代后学习率降低10倍
- 回调函数EarlyStopping,val_loss停止优化30代后停止训练
- 无数据增强,输入图片大小与网络默认一致
- 配置:4×Intel Xeon E5-2650,2×Tesla P100,Ubuntu 16.04,CUDA 8.0,cuDNN 5,TensorFlow-gpu 1.4.0,Keras 2.2.4
- 测试网络:
VGG16、VGG19、ResNet50、InceptionV3、InceptionResNetV2、Xception、MobileNet、MobileNetV2、DenseNet121、DenseNet169、DenseNet201、NASNetMobile、NASNetLarge
2 示例代码
2.1 notebooks及训练结果
https://download.csdn.net/download/lly1122334/11112642
2.2 目录结构
2.3 VGG16示例
In [1]:
import tensorflow as tf
from keras import optimizers
from keras import applications
from keras.utils import plot_model
from keras.utils import multi_gpu_model
from keras.models import Sequential, Model
from keras.layers import Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ModelCheckpoint, EarlyStopping, TensorBoard, ReduceLROnPlateau
# Parameter
epochs = 1000
batch_size = 32
img_width, img_height = 256, 256
nb_gpus = 2
nb_train_samples = 2000
nb_validation_samples = 500
train_dir = 'data/train'
validation_dir = 'data/validation'
log_dir = './logs/vgg16'
weight_dir = './weight/vgg16.h5'
pic_model_dir = './model/vgg16.png'
Using TensorFlow backend.
In [2]:
with tf.device('/cpu:0'):
# Pre-training network
base_model = applications.VGG16(
weights="imagenet",
include_top=False,
input_shape=(img_width, img_height, 3))
# Custom network
top_model = Sequential()
top_model.add(Flatten(input_shape=base_model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(1, activation='sigmoid'))
# Combined network
model = Model(
inputs=base_model.input, outputs=top_model(base_model.output))
# Plot model
plot_model(model, show_shapes=True, to_file=pic_model_dir)
model文件夹下有一张模型结构图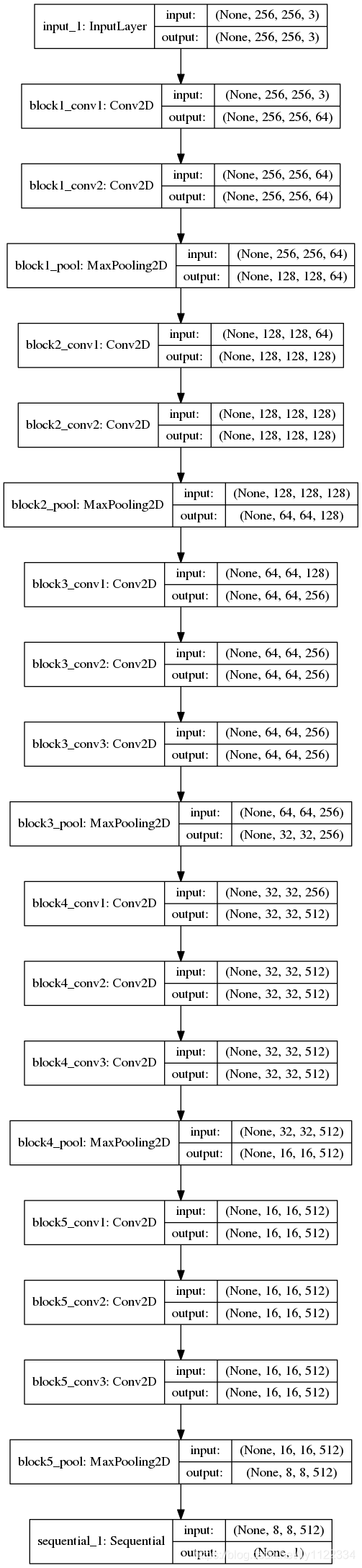
In [3]:
# Multiple GPU
parallel_model = multi_gpu_model(model, gpus=nb_gpus)
parallel_model.compile(
optimizer=optimizers.SGD(lr=0.0001, momentum=0.9),
loss='binary_crossentropy',
metrics=['accuracy'])
In [4]:
# Data generator
train_datagen = ImageDataGenerator(rescale=1. / 255)
validation_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary')
validation_generator = validation_datagen.flow_from_directory(
validation_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
shuffle=False)
Found 22500 images belonging to 2 classes.
Found 2500 images belonging to 2 classes.
In [5]:
# Callbacks
checkpointer = ModelCheckpoint(
filepath=weight_dir,
verbose=1,
save_best_only=True,
save_weights_only=True)
tensorBoard = TensorBoard(
log_dir=log_dir,
write_graph=True,
write_images=True)
reduceLROnPlateau = ReduceLROnPlateau(factor=0.1, patience=10, verbose=1)
earlystopping = EarlyStopping(patience=30, verbose=1)
In [6]:
# Fit
history = parallel_model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
verbose=1,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size,
callbacks=[checkpointer, tensorBoard, reduceLROnPlateau, earlystopping])
Epoch 1/1000
62/62 [==============================] - 19s 303ms/step - loss: 0.6373 - acc: 0.6346 - val_loss: 0.5899 - val_acc: 0.6958
Epoch 00001: val_loss improved from inf to 0.58985, saving model to ./weight/vgg16.h5
......
Epoch 42/1000
62/62 [==============================] - 14s 232ms/step - loss: 0.0333 - acc: 0.9894 - val_loss: 0.0097 - val_acc: 0.9979
Epoch 00042: val_loss improved from 0.01013 to 0.00973, saving model to ./weight/vgg16.h5
......
Epoch 52/1000
62/62 [==============================] - 14s 225ms/step - loss: 0.0364 - acc: 0.9849 - val_loss: 0.0197 - val_acc: 0.9917
Epoch 00052: val_loss did not improve from 0.00973
Epoch 00052: ReduceLROnPlateau reducing learning rate to 9.999999747378752e-06.
......
Epoch 62/1000
62/62 [==============================] - 14s 230ms/step - loss: 0.0227 - acc: 0.9919 - val_loss: 0.0248 - val_acc: 0.9896
Epoch 00062: val_loss did not improve from 0.00973
Epoch 00062: ReduceLROnPlateau reducing learning rate to 9.999999747378752e-07.
......
Epoch 72/1000
62/62 [==============================] - 14s 229ms/step - loss: 0.0194 - acc: 0.9929 - val_loss: 0.0348 - val_acc: 0.9833
Epoch 00072: val_loss did not improve from 0.00973
Epoch 00072: ReduceLROnPlateau reducing learning rate to 9.999999974752428e-08.
Epoch 00072: early stopping
训练过程中启动tensorboard,监视训练过程
tensorboard --logdir=logs/vgg16
Tensorboard SCALARS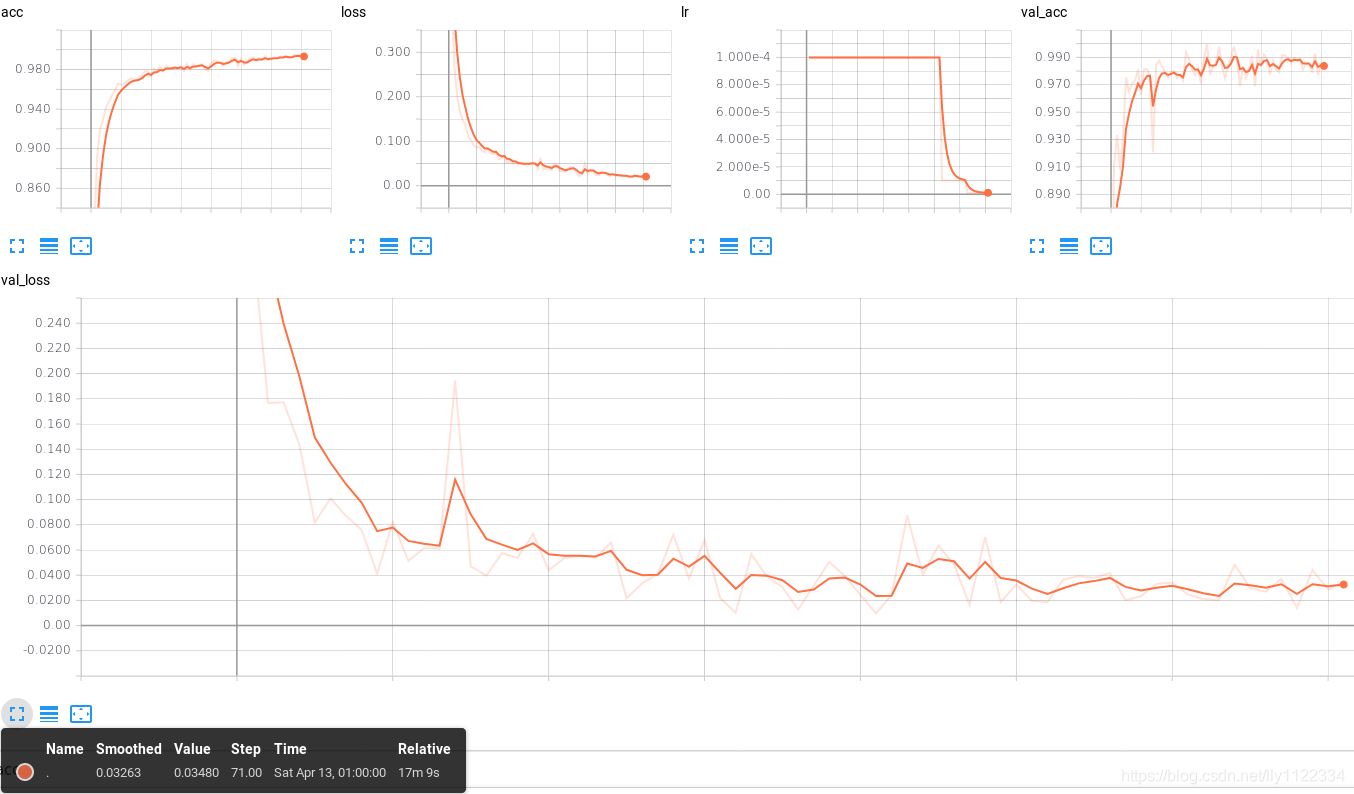
Tensorboard GRAPHS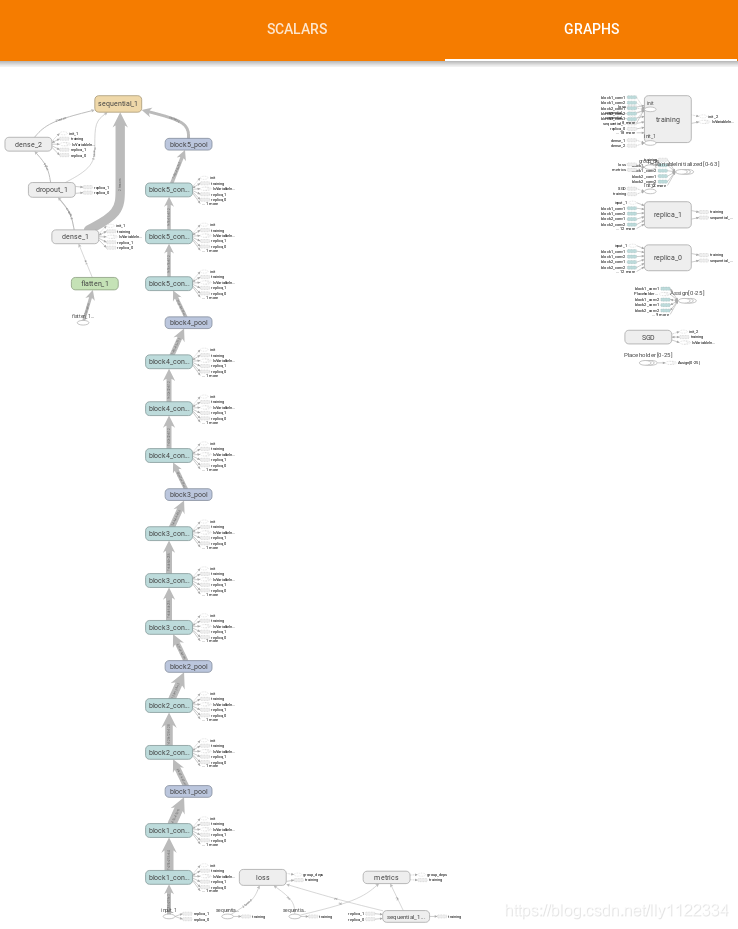
In [7]:
import sys
import matplotlib.pyplot as plt
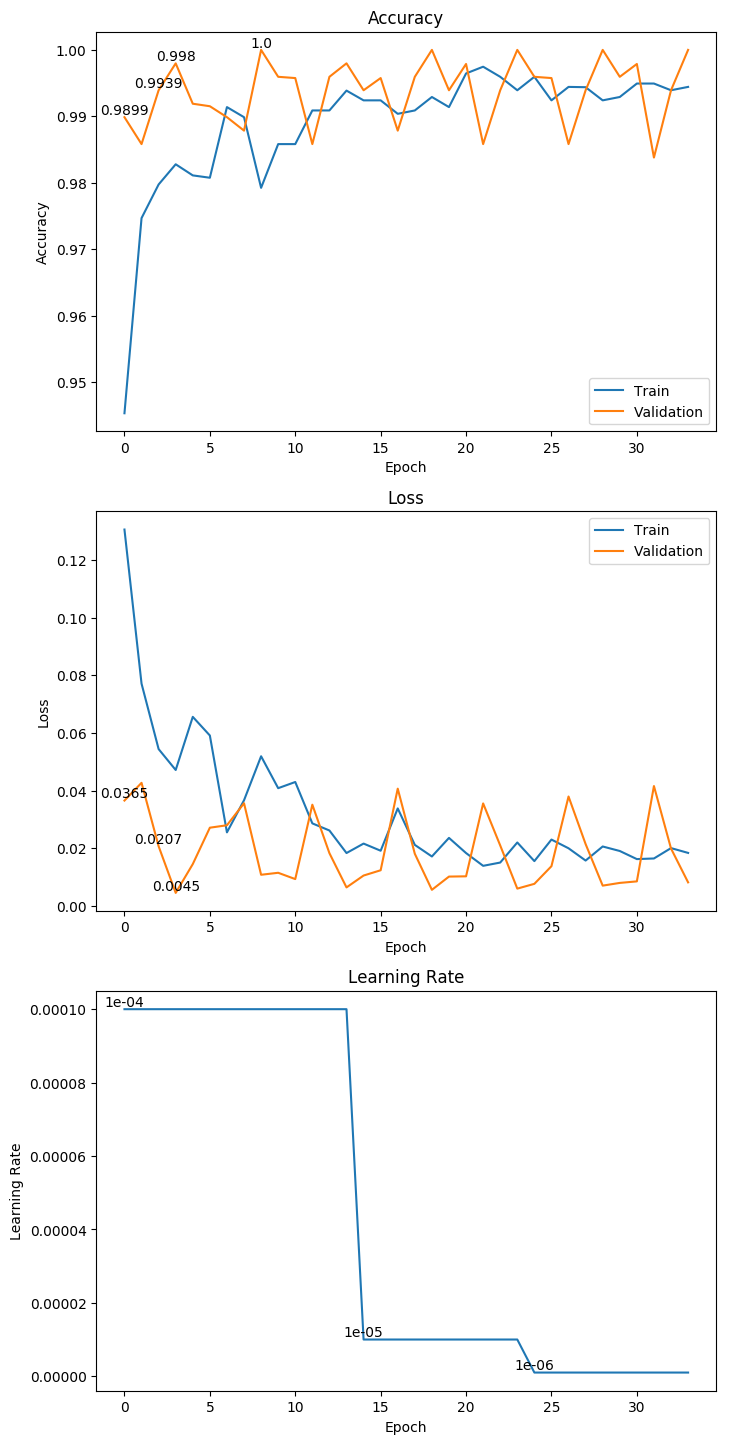
In [8]:
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
lr = history.history['lr']
plt.figure(1)
plt.figure(figsize=(8, 18), dpi=100)
#Plot accuracy
plt.subplot(311)
plt.plot(acc)
plt.plot(val_acc)
plt.title('Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(['Train', 'Validation'], loc='best')
x = 0
maximum = -sys.maxsize
for y in val_acc:
if y > maximum:
maximum = y
plt.text(x, y, round(y, 4), ha='center', va='bottom')
x += 1
# Plot loss
plt.subplot(312)
plt.plot(loss)
plt.plot(val_loss)
plt.title('Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(['Train', 'Validation'], loc='best')
x = 0
minimum = sys.maxsize
for y in val_loss:
if y < minimum:
minimum = y
plt.text(x, y, round(y, 4), ha='center', va='bottom')
x += 1
# Plot learning rate
plt.subplot(313)
plt.plot(lr)
plt.title('Learning Rate')
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
x = 0
minimum = sys.maxsize
for y in lr:
if y < minimum:
minimum = y
plt.text(x, y, y, ha='center', va='bottom')
x += 1
plt.show()
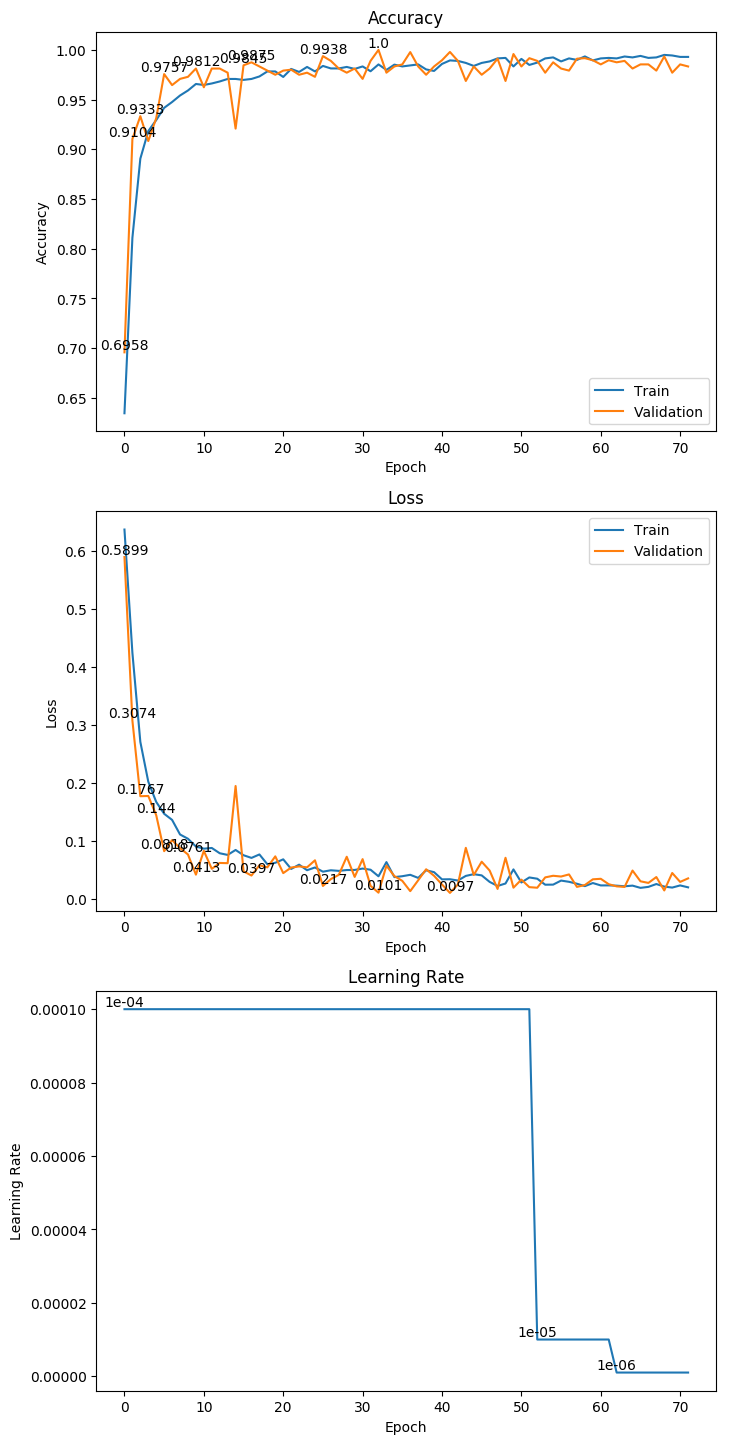
3 测试结果
3.1 VGG16
权重大小:88.17MB
Epoch 42/1000
62/62 [==============================] - 14s 232ms/step - loss: 0.0333 - acc: 0.9894 - val_loss: 0.0097 - val_acc: 0.9979
Epoch 00042: val_loss improved from 0.01013 to 0.00973, saving model to ./weight/vgg16.h5
3.2 VGG19
权重大小:100.93MB
Epoch 38/1000
62/62 [==============================] - 13s 216ms/step - loss: 0.0443 - acc: 0.9839 - val_loss: 0.0067 - val_acc: 1.0000
Epoch 00038: val_loss improved from 0.01237 to 0.00675, saving model to ./weight/vgg19.h5
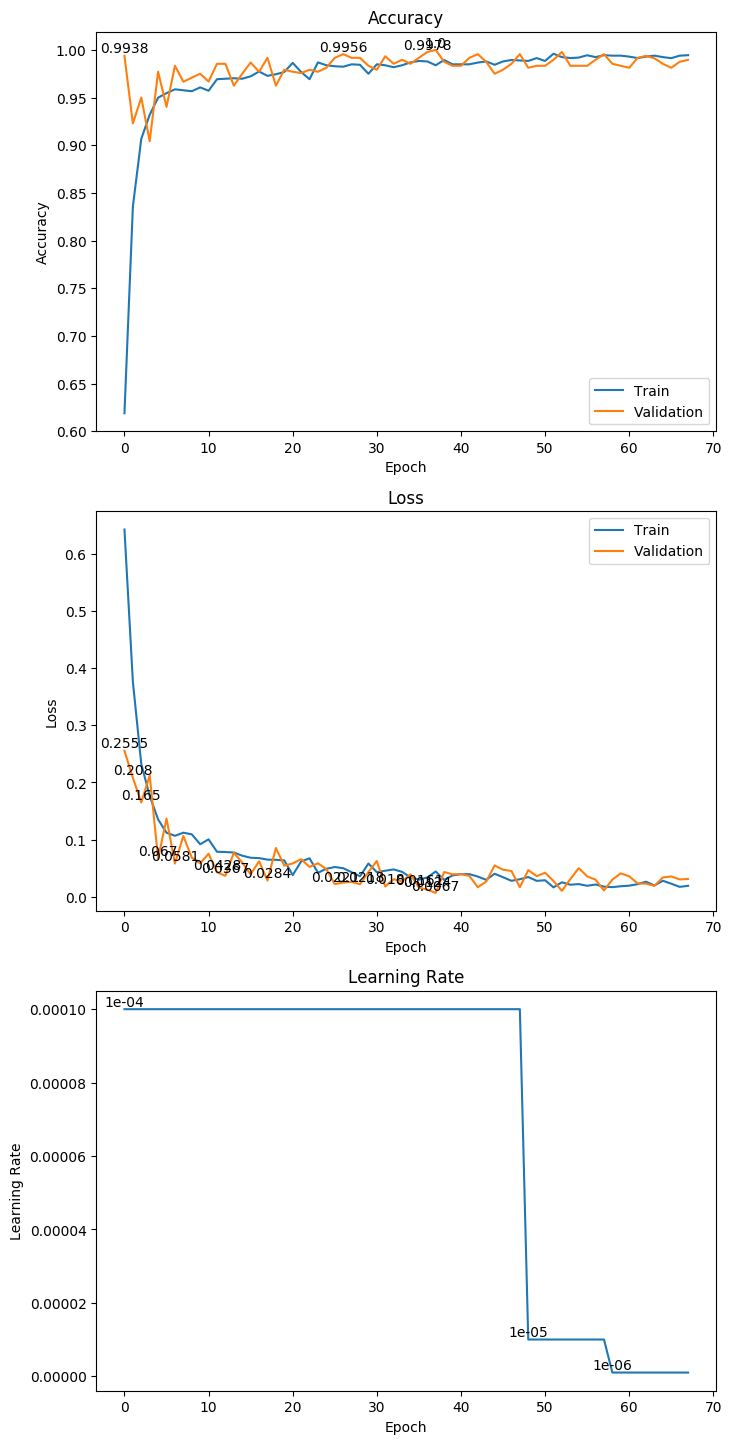
3.3 ResNet50
权重大小:188.21MB
Epoch 42/1000
62/62 [==============================] - 16s 258ms/step - loss: 0.0215 - acc: 0.9914 - val_loss: 0.0134 - val_acc: 0.9917
Epoch 00042: val_loss improved from 0.01615 to 0.01336, saving model to ./weight/ResNet50.h5
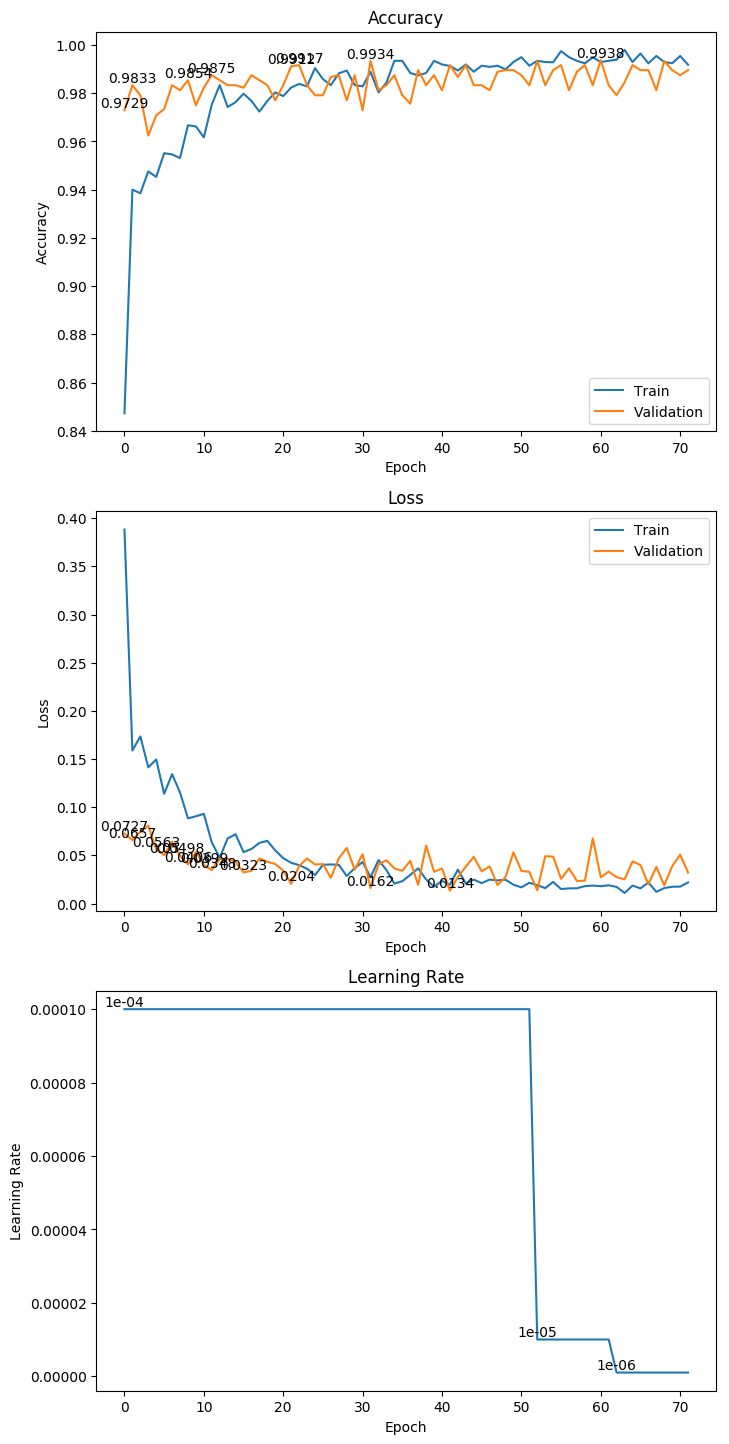
3.4 InceptionV3
权重大小:211.51MB
Epoch 25/1000
62/62 [==============================] - 22s 350ms/step - loss: 0.0420 - acc: 0.9829 - val_loss: 0.0059 - val_acc: 1.0000
Epoch 00025: val_loss improved from 0.01020 to 0.00590, saving model to ./weight/InceptionV3.h5
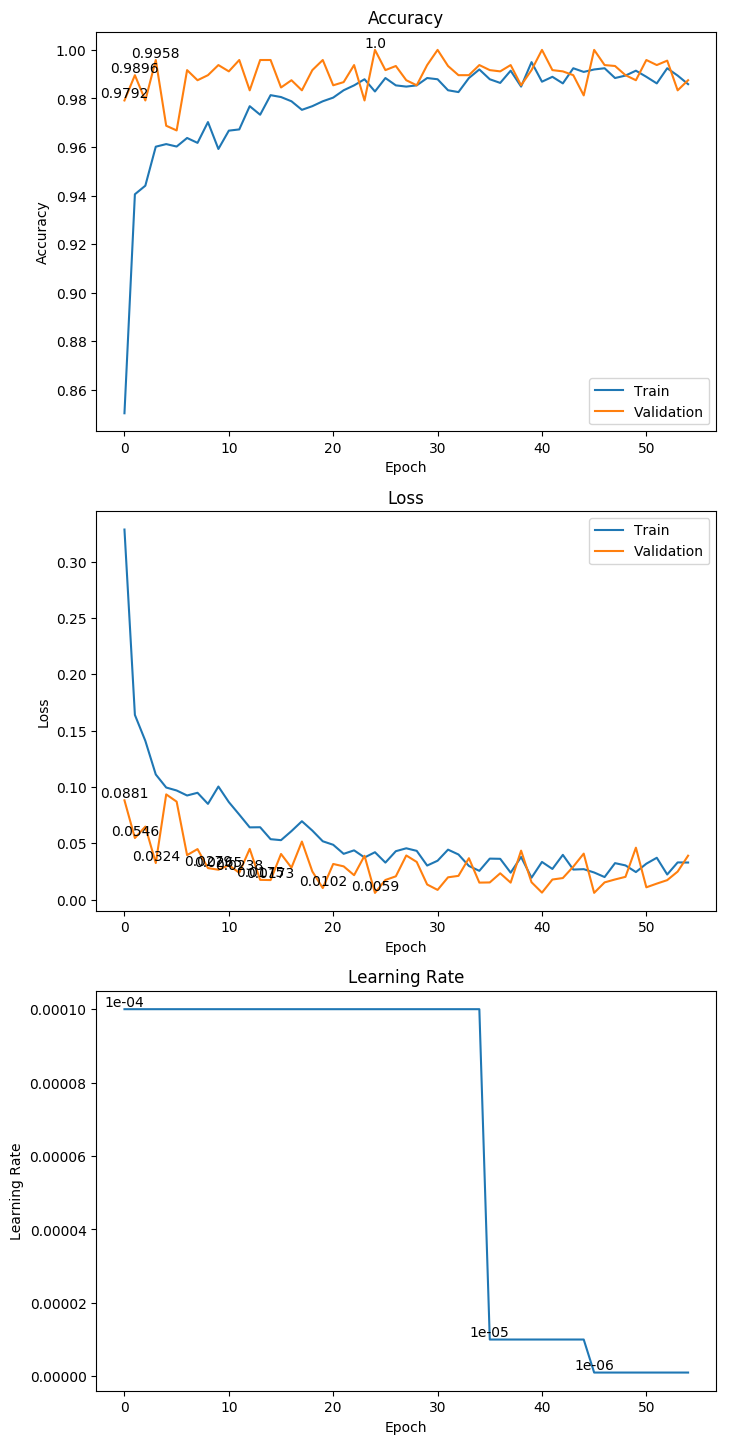
3.5 InceptionResNetV2
权重大小:304.05MB
Epoch 46/1000
62/62 [==============================] - 39s 636ms/step - loss: 0.0284 - acc: 0.9889 - val_loss: 0.0069 - val_acc: 0.9979
Epoch 00046: val_loss improved from 0.00855 to 0.00692, saving model to ./weight/InceptionResNetV2.h5
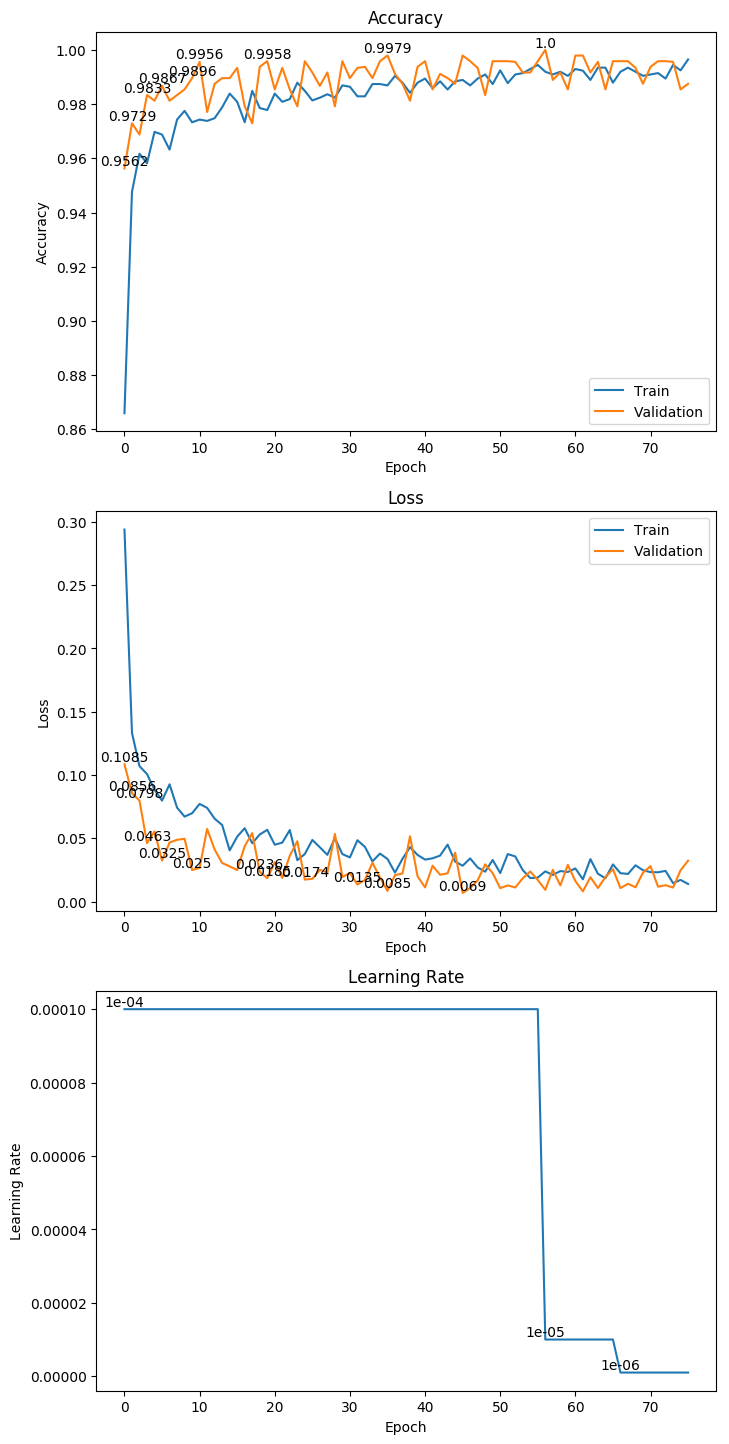
3.6 Xception
权重大小:279.75MB
Epoch 20/1000
62/62 [==============================] - 34s 555ms/step - loss: 0.0474 - acc: 0.9773 - val_loss: 0.0090 - val_acc: 0.9979
Epoch 00020: val_loss improved from 0.01220 to 0.00898, saving model to ./weight/Xception.h5
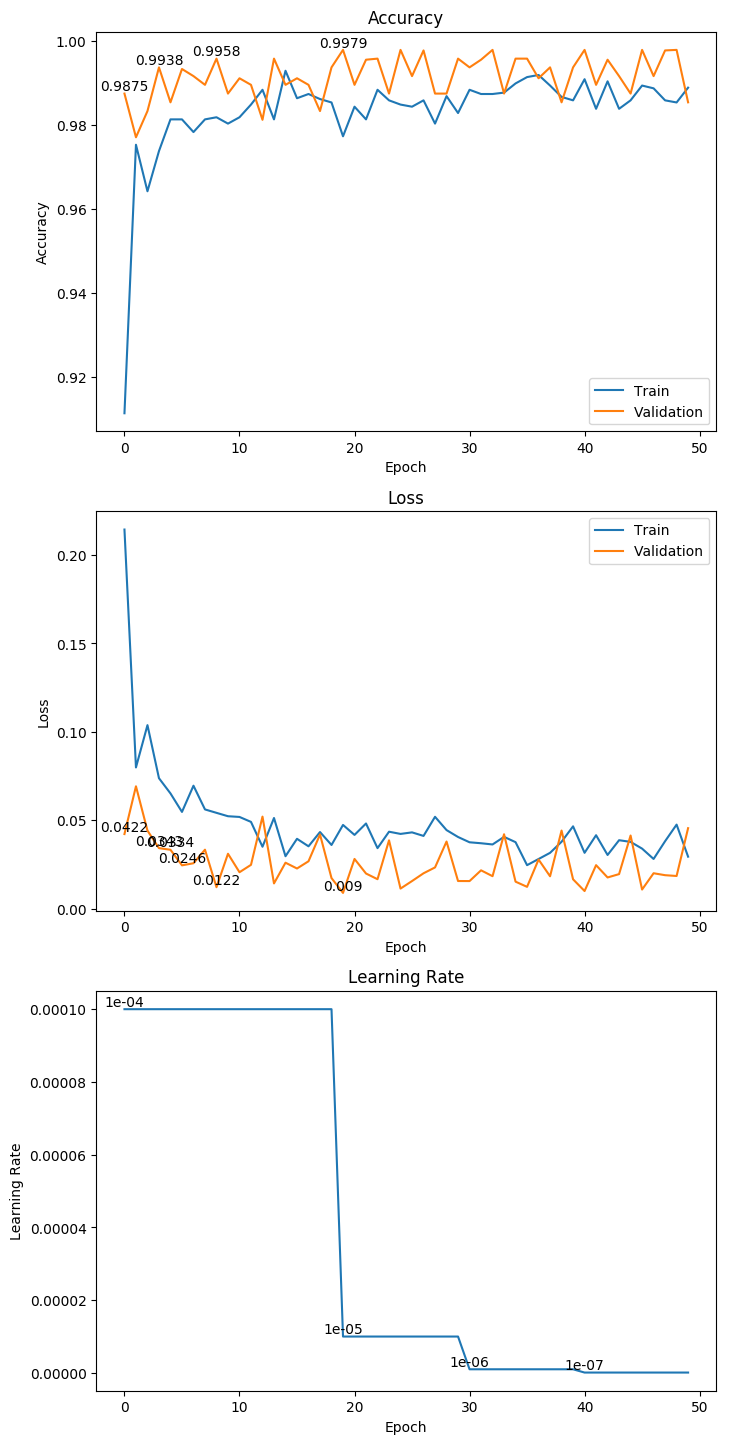
3.7 MobileNet
权重大小:61.43MB
Epoch 9/1000
62/62 [==============================] - 14s 221ms/step - loss: 0.1255 - acc: 0.9551 - val_loss: 0.0217 - val_acc: 0.9896
Epoch 00009: val_loss improved from 0.03307 to 0.02166, saving model to ./weight/MobileNet.h5
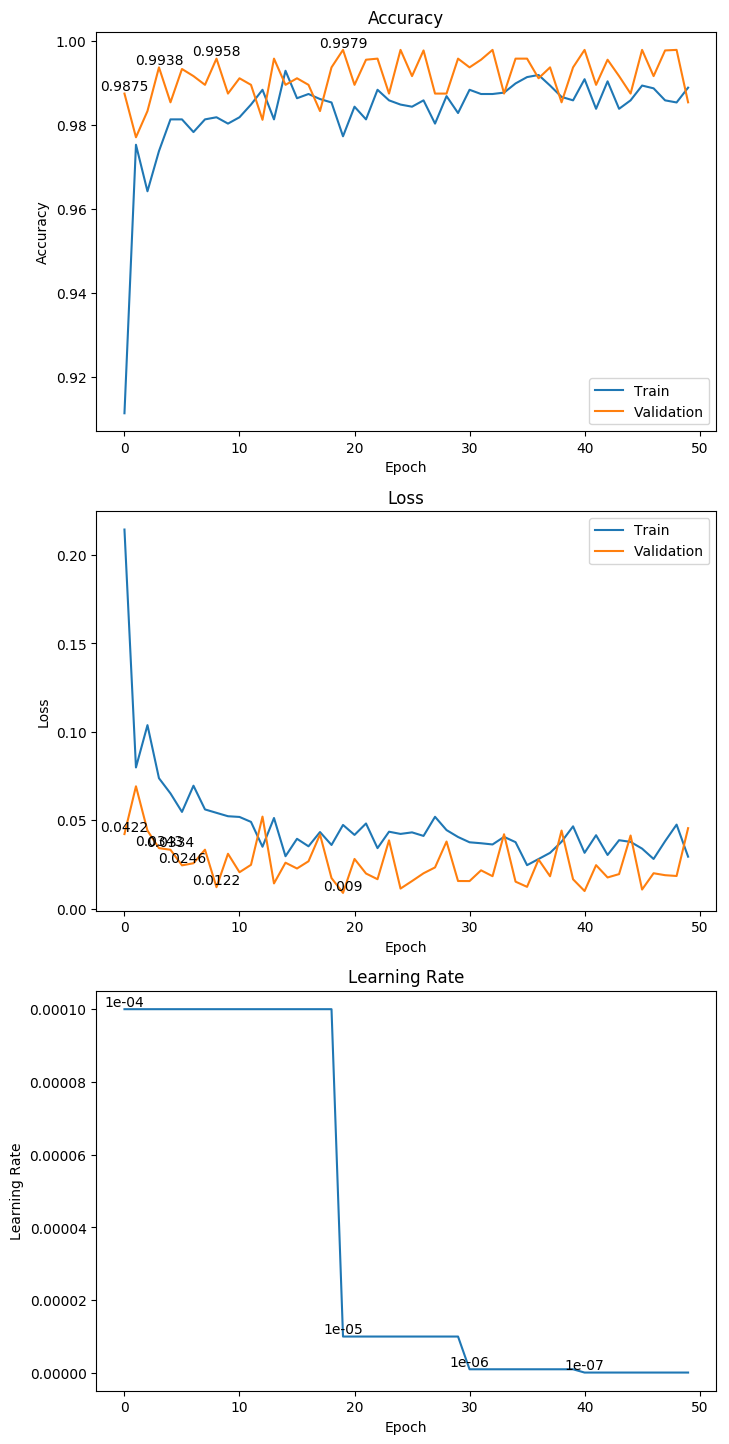
3.8 MobileNetV2
权重大小:70.07MB
Epoch 17/1000
62/62 [==============================] - 17s 279ms/step - loss: 0.0870 - acc: 0.9672 - val_loss: 0.0211 - val_acc: 0.9896
Epoch 00017: val_loss improved from 0.03336 to 0.02112, saving model to ./weight/MobileNetV2.h5
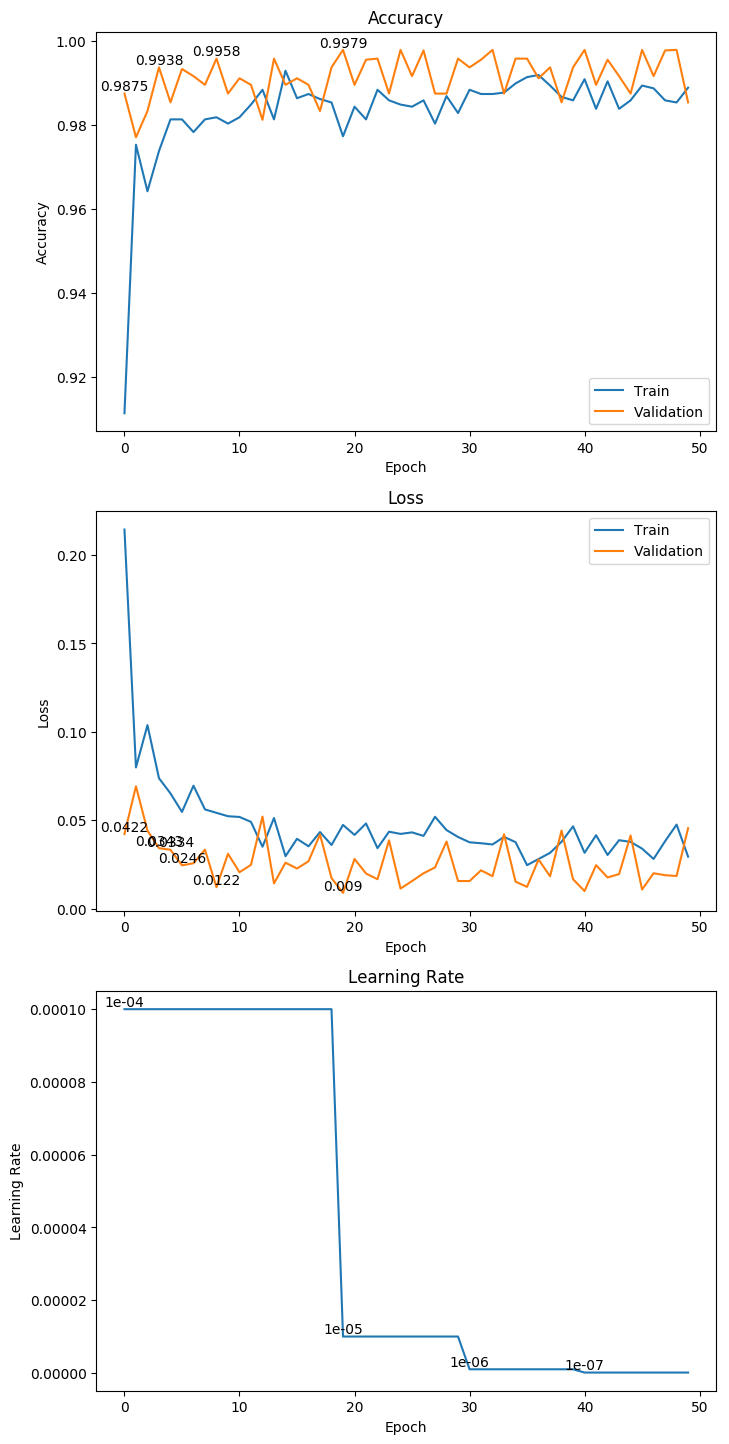
3.9 DenseNet121
权重大小:76.31MB
Epoch 32/1000
62/62 [==============================] - 20s 317ms/step - loss: 0.0450 - acc: 0.9839 - val_loss: 0.0084 - val_acc: 0.9978
Epoch 00032: val_loss improved from 0.01282 to 0.00844, saving model to ./weight/DenseNet121.h5
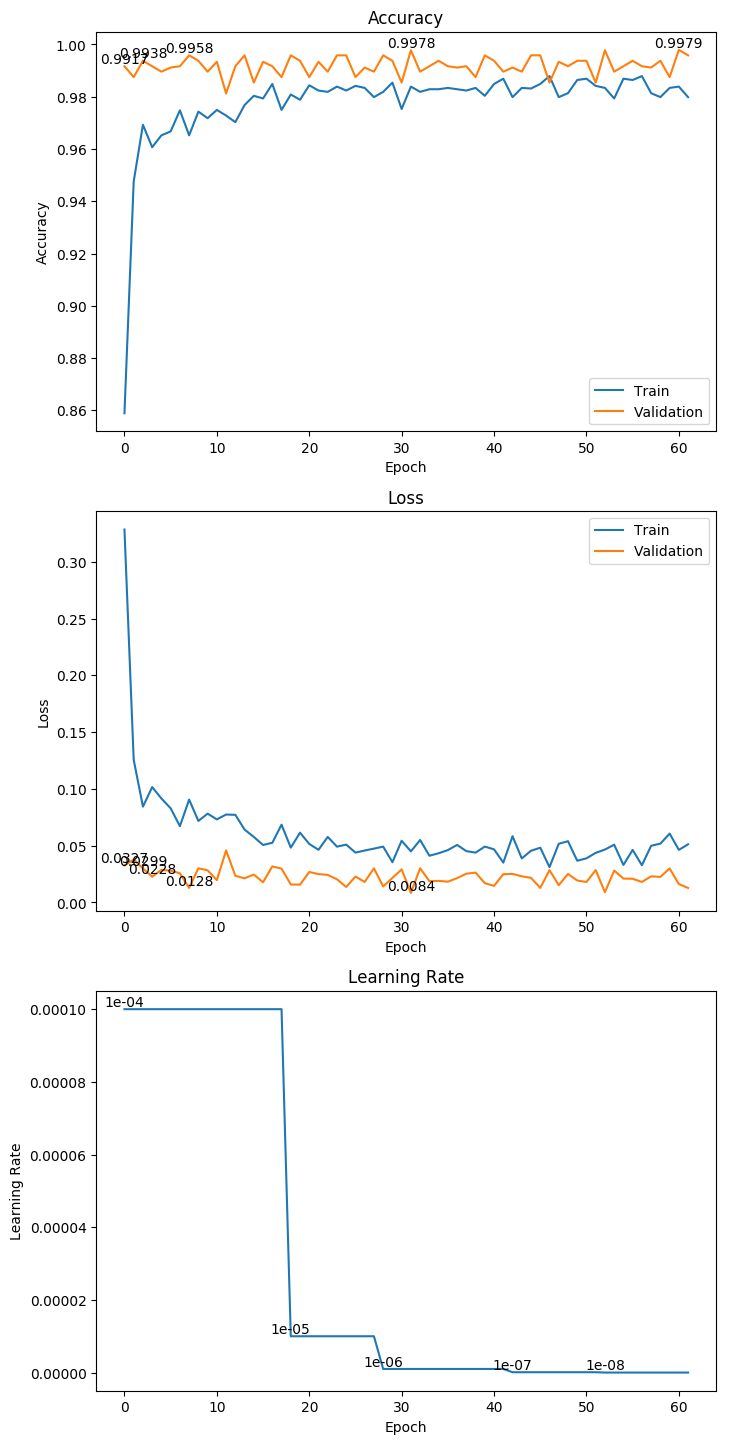
3.10 DenseNet169
权重大小:128.49MB
Epoch 46/1000
62/62 [==============================] - 26s 415ms/step - loss: 0.0261 - acc: 0.9899 - val_loss: 0.0081 - val_acc: 0.9979
Epoch 00046: val_loss improved from 0.00868 to 0.00806, saving model to ./weight/DenseNet169.h5
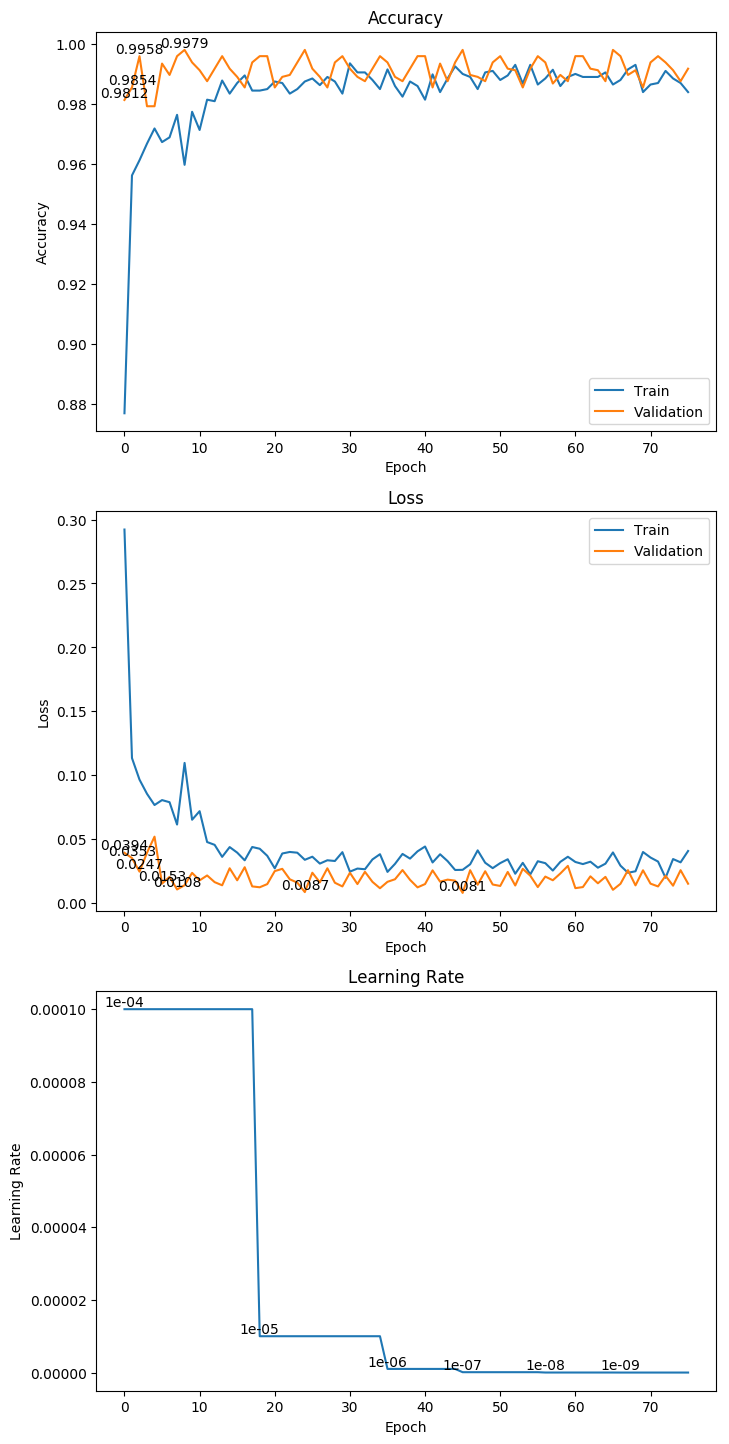
3.11 DenseNet201
权重大小:162.53MB
Epoch 20/1000
62/62 [==============================] - 30s 485ms/step - loss: 0.0461 - acc: 0.9824 - val_loss: 0.0058 - val_acc: 1.0000
Epoch 00020: val_loss improved from 0.01274 to 0.00580, saving model to ./weight/DenseNet201.h5
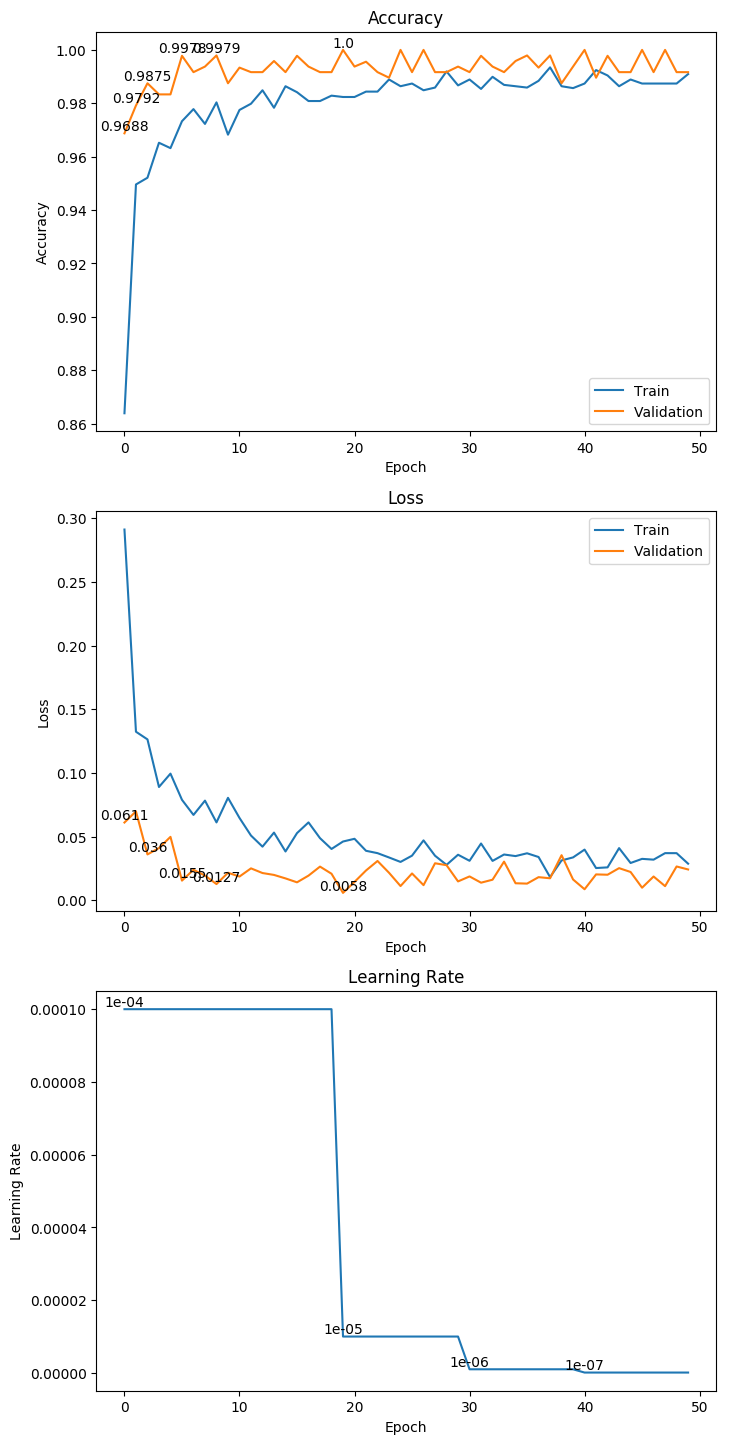
3.12 NASNetMobile
权重大小:67.88MB
Epoch 13/1000
62/62 [==============================] - 45s 730ms/step - loss: 0.0843 - acc: 0.9662 - val_loss: 0.0248 - val_acc: 0.9917
Epoch 00013: val_loss improved from 0.03313 to 0.02478, saving model to ./weight/NASNetMobile.h5
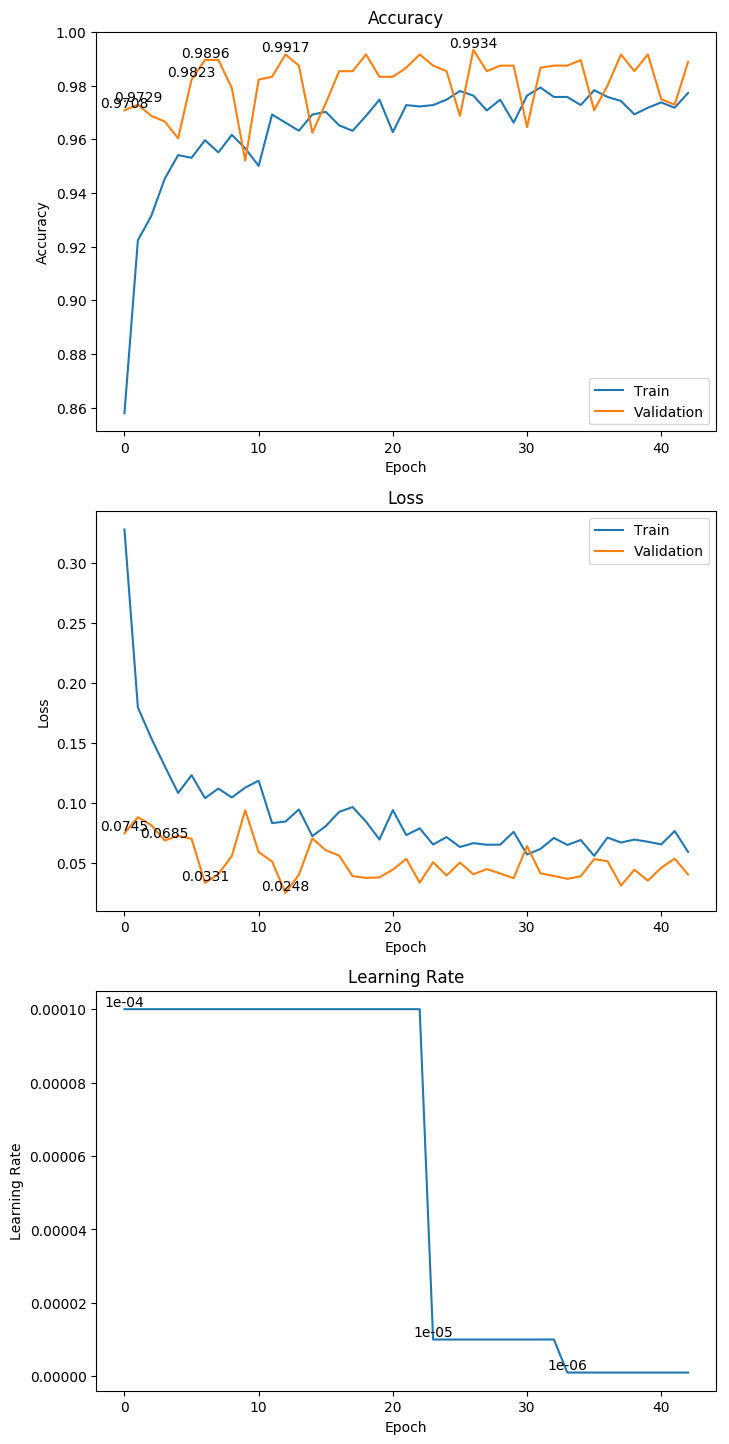
3.13 NASNetLarge
权重大小:801.81MB
Epoch 4/1000
76/76 [==============================] - 144s 2s/step - loss: 0.0471 - acc: 0.9828 - val_loss: 0.0045 - val_acc: 0.9980
Epoch 00004: val_loss improved from 0.02069 to 0.00451, saving model to ./weight/NASNetLarge.h5
更多推荐


 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)