
LLM-03 大模型 15分钟 FineTuning 微调 GPT2 模型 finetuning GPT微调实战 仅需6GB显存 单卡微调 数据 10MB数据集微调
这里提供一个例子,运行可以自动把模型下载下来。这边建议独立环境,避免相互影响。执行之后,观察显卡的情况,大致占用。的显卡,小显卡也可以正常运行)。LLM-03 大模型 15分钟 FineTuning 微调 GPT2 模型 finetuning GPT微调实战 仅需6GB显存 单卡微调 Kaggle数据 10MB数据集微调。观察显卡的情况,大致占用4.6GB的显存(虽然我这里是3090 24GB的显

参考资料
Why will you need fine-tuning an LLM?
LLMs are generally trained on public data with no specific focus. Fine-tuning is a crucial step that adapts a pre-trained LLM model to a specific task, enhancing the LLM responses significantly. Although text generation is a well-known application of an LLM, the neural network embeddings obtained from the model are equally valuable for various downstream applications.
项目地址
https://huggingface.co/openai-community/gpt2
安装依赖
这边建议独立环境,避免相互影响。可看LLM-01 和 LLM-02 章节中的 Pyenv 的使用
pip install transformers
下载模型
有很多方式下载 HuggingFace的模型:
- 利用官方提供的 huggingface_hub库 下载
- 直接下载(比如Git方式)
- 镜像代理下载(国内,如果没有科学上网的话)
- 其他···
这里提供一个例子,运行可以自动把模型下载下来
from transformers import AutoTokenizer, AutoModel, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
直接运行,可以看到如下的效果:

数据下载
项目地址: 参考的项目
数据来自 Kaggle 一个短笑话合集 10MB(压缩后):
下载链接
编写代码
加载数据
class JokesDataset(Dataset):
def __init__(self, jokes_dataset_path = './'):
super().__init__()
short_jokes_path = os.path.join(jokes_dataset_path, 'shortjokes.csv')
self.joke_list = []
self.end_of_te xt_token = "<|endoftext|>"
with open(short_jokes_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
x = 0
for row in csv_reader:
joke_str = f"JOKE:{row[1]}{self.end_of_text_token}"
self.joke_list.append(joke_str)
def __len__(self):
return len(self.joke_list)
def __getitem__(self, item):
return self.joke_list[item]
加载模型
# 如果你是默认的 那应该是:openai-community/gpt2
model_path = "./gpt2"
tokenizer = GPT2Tokenizer.from_pretrained(model_path)
model = GPT2LMHeadModel.from_pretrained(model_path)
model = model.to(device)
训练代码
for epoch in range(EPOCHS):
print(f"EPOCH {epoch} started" + '=' * 30)
for idx,joke in enumerate(joke_loader):
#################### "Fit as many joke sequences into MAX_SEQ_LEN sequence as possible" logic start ####
joke_tens = torch.tensor(tokenizer.encode(joke[0])).unsqueeze(0).to(device)
#Skip sample from dataset if it is longer than MAX_SEQ_LEN
if joke_tens.size()[1] > MAX_SEQ_LEN:
continue
#The first joke sequence in the sequence
if not torch.is_tensor(tmp_jokes_tens):
tmp_jokes_tens = joke_tens
continue
else:
#The next joke does not fit in so we process the sequence and leave the last joke
#as the start for next sequence
if tmp_jokes_tens.size()[1] + joke_tens.size()[1] > MAX_SEQ_LEN:
work_jokes_tens = tmp_jokes_tens
tmp_jokes_tens = joke_tens
else:
#Add the joke to sequence, continue and try to add more
tmp_jokes_tens = torch.cat([tmp_jokes_tens, joke_tens[:,1:]], dim=1)
continue
################## Sequence ready, process it trough the model ##################
outputs = model(work_jokes_tens, labels=work_jokes_tens)
loss, logits = outputs[:2]
loss.backward()
sum_loss = sum_loss + loss.detach().data
proc_seq_count = proc_seq_count + 1
if proc_seq_count == BATCH_SIZE:
proc_seq_count = 0
batch_count += 1
optimizer.step()
scheduler.step()
optimizer.zero_grad()
model.zero_grad()
if batch_count == 100:
print(f"sum loss {sum_loss}")
batch_count = 0
sum_loss = 0.0
# Store the model after each epoch to compare the performance of them
torch.save(model.state_dict(), os.path.join(models_folder, f"gpt2_medium_joker_{epoch}.pt"))
保存目录
models_folder = "trained_models"
if not os.path.exists(models_folder):
os.mkdir(models_folder)
完整代码
完整的代码如下
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
import numpy as np
from torch.utils.data import Dataset, DataLoader
from transformers import AdamW, get_linear_schedule_with_warmup
import os
import json
import csv
import logging
logging.getLogger().setLevel(logging.CRITICAL)
import warnings
warnings.filterwarnings('ignore')
class JokesDataset(Dataset):
def __init__(self, jokes_dataset_path = './'):
super().__init__()
short_jokes_path = os.path.join(jokes_dataset_path, 'shortjokes.csv')
self.joke_list = []
self.end_of_te xt_token = "<|endoftext|>"
with open(short_jokes_path) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
x = 0
for row in csv_reader:
joke_str = f"JOKE:{row[1]}{self.end_of_text_token}"
self.joke_list.append(joke_str)
def __len__(self):
return len(self.joke_list)
def __getitem__(self, item):
return self.joke_list[item]
device = 'mps'
if torch.cuda.is_available():
device = 'cuda'
model_path = "./gpt2"
tokenizer = GPT2Tokenizer.from_pretrained(model_path)
model = GPT2LMHeadModel.from_pretrained(model_path)
model = model.to(device)
dataset = JokesDataset()
joke_loader = DataLoader(dataset, batch_size=1, shuffle=True)
BATCH_SIZE = 16
EPOCHS = 2
LEARNING_RATE = 3e-5
WARMUP_STEPS = 5000
MAX_SEQ_LEN = 400
model.train()
optimizer = AdamW(model.parameters(), lr=LEARNING_RATE)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=WARMUP_STEPS, num_training_steps = -1)
proc_seq_count = 0
sum_loss = 0.0
batch_count = 0
tmp_jokes_tens = None
models_folder = "trained_models"
if not os.path.exists(models_folder):
os.mkdir(models_folder)
for epoch in range(EPOCHS):
print(f"EPOCH {epoch} started" + '=' * 30)
for idx,joke in enumerate(joke_loader):
#################### "Fit as many joke sequences into MAX_SEQ_LEN sequence as possible" logic start ####
joke_tens = torch.tensor(tokenizer.encode(joke[0])).unsqueeze(0).to(device)
#Skip sample from dataset if it is longer than MAX_SEQ_LEN
if joke_tens.size()[1] > MAX_SEQ_LEN:
continue
#The first joke sequence in the sequence
if not torch.is_tensor(tmp_jokes_tens):
tmp_jokes_tens = joke_tens
continue
else:
#The next joke does not fit in so we process the sequence and leave the last joke
#as the start for next sequence
if tmp_jokes_tens.size()[1] + joke_tens.size()[1] > MAX_SEQ_LEN:
work_jokes_tens = tmp_jokes_tens
tmp_jokes_tens = joke_tens
else:
#Add the joke to sequence, continue and try to add more
tmp_jokes_tens = torch.cat([tmp_jokes_tens, joke_tens[:,1:]], dim=1)
continue
################## Sequence ready, process it trough the model ##################
outputs = model(work_jokes_tens, labels=work_jokes_tens)
loss, logits = outputs[:2]
loss.backward()
sum_loss = sum_loss + loss.detach().data
proc_seq_count = proc_seq_count + 1
if proc_seq_count == BATCH_SIZE:
proc_seq_count = 0
batch_count += 1
optimizer.step()
scheduler.step()
optimizer.zero_grad()
model.zero_grad()
if batch_count == 100:
print(f"sum loss {sum_loss}")
batch_count = 0
sum_loss = 0.0
# Store the model after each epoch to compare the performance of them
torch.save(model.state_dict(), os.path.join(models_folder, f"gpt2_medium_joker_{epoch}.pt"))
运行代码
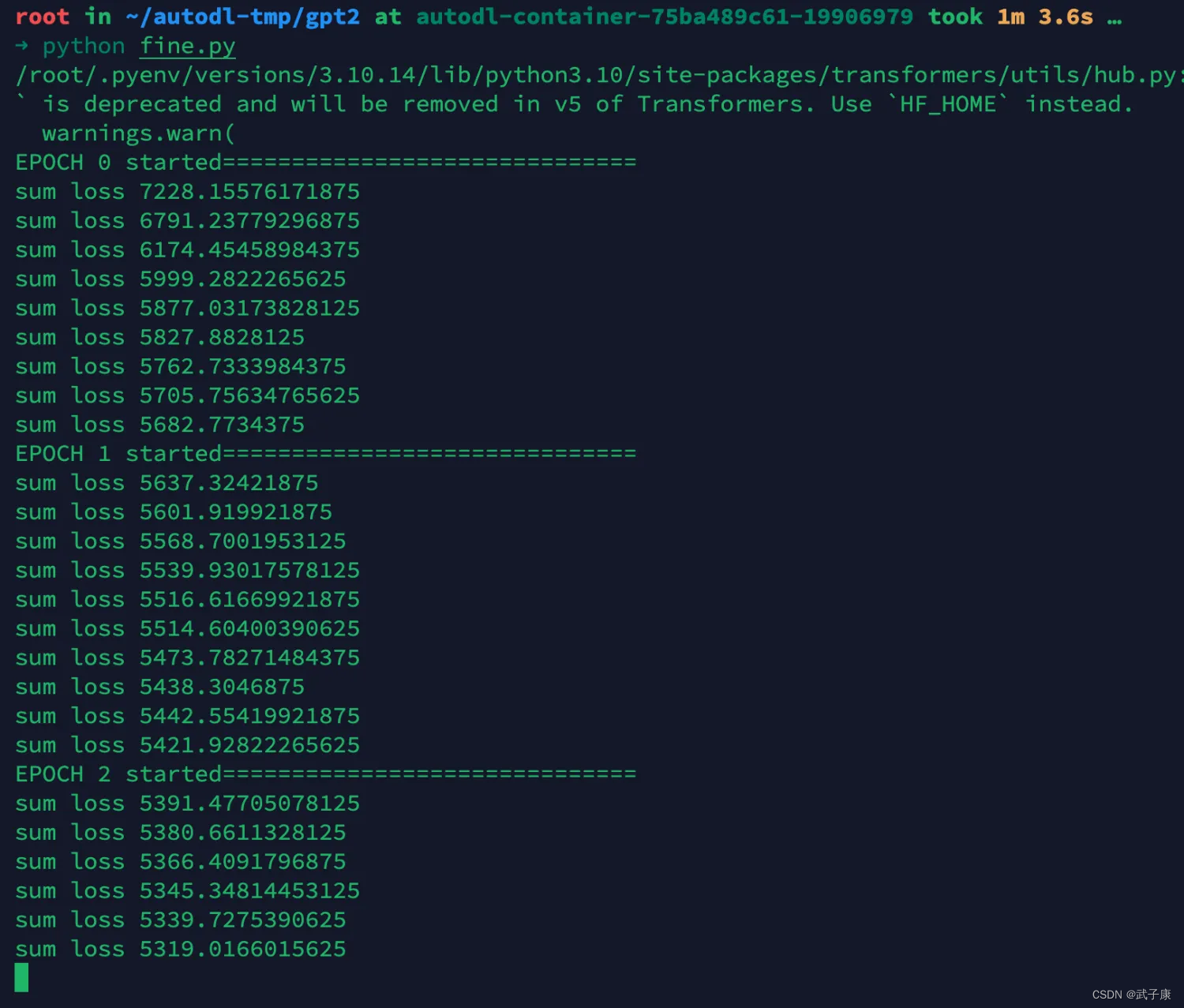
python fine.py
执行之后,观察显卡的情况,大致占用4.6GB的显存(虽然我这里是3090 24GB的显卡,小显卡也可以正常运行)

训练过程会打印 LOSS ,
训练结束
经过漫长等待···

测试结果
原始模型
编写几行代码,简单测试一下:
from transformers import pipeline,GPT2LMHeadModel, GPT2Tokenizer
model_path = "openai-community/gpt2"
model = GPT2LMHeadModel.from_pretrained(model_path)
tokenizer = GPT2Tokenizer.from_pretrained(model_path)
text_generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
texts = text_generator("Once upon a time ", max_length=50, num_return_sequences=1)
for text in texts:
print("========================")
print(text["generated_text"])
运行输出:
Once upon a time 『My Name is』 I'll call myself a boy. I won't reveal my true name.

微调模型
微调之后,效果就变了:
import torch
from transformers import pipeline, GPT2LMHeadModel, GPT2Tokenizer
model_path = "openai-community/gpt2"
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model = GPT2LMHeadModel.from_pretrained(model_path).to(device)
tokenizer = GPT2Tokenizer.from_pretrained(model_path)
model.load_state_dict(torch.load('./trained_models/gpt2_medium_joker_9.pt', map_location='cuda:0'))
model.eval()
text_generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
texts = text_generator("Once upon a time ", max_length=50, num_return_sequences=1)
print("===================")
for text in texts:
print(text["generated_text"])
测试第一次:
Once upon a time someone in England tried to insult me by saying, "I'm Scottish."
附带翻译:
从前,有人在英格兰试图侮辱我,说:“我是苏格兰人。”笑点在于暗示苏格兰人与英格兰人有种族或地域上的不同,但实际上这种“侮辱”反而使苏格兰人自豪。

测试第二次:
Once upon a time someone like that was doing something wrong. When I went to dinner with them the first thing I did was drop my food on the ground and start a fire.
附带翻译:
从前,有个像那个人那样做错事的人。当我和他们一起吃饭时,我第一件事就是把食物掉在地上,然后引起了一场火灾。笑点在于出乎意料的行为,以及食物掉在地上导致火灾这种离奇的情节,使整个场景变得荒诞有趣。

更多推荐

 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)