

大模型参数高效微调技术原理综述(四)-Prompt Tuning
首先我们看一下论文摘要,快速理解论文的核心内容问题与一样,都是以任务为中心的思路解决问题。以任务为中心:它们都在试图解决FFT针对不同的下游任务都需产生一个新的微调后大模型而导致的成本效率问题。解决方案:论文提出的,也是一种使用Soft Prompt(软提示)进行迁移学习的方法。统一不同下游任务的训练数据格式,并将这些不同下游任务的训练数据汇总成一个乱序的数据集,微调预训练模型,最终获得一个能处理
紧接着Stanford的Prefix Tuning论文,Google迅速发表了Prompt Tuning技术论文。Google声称该技术比Prefix Tuning更易上手且成本更低,因此该技术随后也成为了微调技术中的一个重要分支。
本文解读论文**《The Power of Scale for Parameter-Efficient Prompt Tuning》**,与大家共同感受Prompt Tuning技术的奇妙之处。

Prompt的分类
这个分类非常重要,大量的论文都会提到软提示,希望认真阅读!
硬提示/离散提示(Hard Prompt/Discrete Prompt)
硬提示就是指人为设计上面提到的Prompt。硬提示一般需要模型在这个域上有比较多的经验,并且使用前需要知道这个模型的底层是什么样的。否则,硬提示的性能一般会比Fine-tuning的SOTA差很多。
根据2021年的两份研究,硬提示有两个性质:
- 人类认为不错的硬提示对于LM来说不一定是一个好的硬提示,这个性质被称为硬提示的sub-optimal(次优)性。
- 硬提示的选择对于预训练模型的影响非常大。
这两个性质可以在如下例子中显现得淋漓尽致:

发现问题了吗?其实最上面在我们看来是最简单的完形填空(也就意味着我们认为最上面的性能最强),但是实际上计算机认为最下面才是最好的完形填空,而且几乎差了一倍的性能!
软提示/连续提示(Soft Prompt/Continuous Prompt)
就是因为硬提示存在这样的问题,2020年,科学家提出了软提示。软提示与硬提示恰好相反,把Prompt的生成本身作为一个任务进行学习,相当于把Prompt的生成从人类一个一个尝试(离散)变换成机器自己进行学习、尝试(连续)。
由于需要机器自己学习,软提示不可避免地往模型内引入了新的参数。这里就又出来一个问题:如何参数有效地学习软提示?目前的研究热点有:
- P-tuning:将prompt变成token,用BiLSTM进行学习。
- P-tuning:使用混合的prompt初始化策略(如CLInit和SelectInit)。
- Prefix-tuning:对于不同模型,将prompt注入输入的不同位置。原理图如下:

- Soft Prompts:使用组合法,例如mixture-of-experts。
Prompt Tuning(论文:The Power of Scale for Parameter-Efficient Prompt Tuning),该方法可以看作是 Prefix Tuning 的简化版本,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。

从Prompt到Prompt Tuning:让机器学习写Prompt
了解了软提示后,Prompt Tuning就非常好理解了。
所谓Prompt Tuning,就是在Prompt中插入一段task-specific的可以tune的prompt token。
由于这个token对于每个任务都是不同的,所以可以帮助机器识别任务到底是什么。又因为机器自己学习(tune)这个prompt token,所以这个token对于机器会有非常好的效果。
1.Abstract(摘要)
首先我们看一下论文摘要,快速理解论文的核心内容:
-
问题:Prompt Tuning与Prefix Tuning一样,都是以任务为中心的思路解决问题。
- 以任务为中心:它们都在试图解决FFT针对不同的下游任务都需产生一个新的微调后大模型而导致的成本效率问题。
-
解决方案:论文提出的
Prompt Tuning,也是一种使用Soft Prompt(软提示)进行迁移学习的方法。统一不同下游任务的训练数据格式,并将这些不同下游任务的训练数据汇总成一个乱序的数据集,微调预训练模型,最终获得一个能处理不同下游任务的大模型。 -
实验效果:
- 在小参数规模的T5上,Prompt Tuning略差于FFT性能。
- 在中参数规模的T5上,Prompt Tuning快速接近于FFT性能。
- 在大参数规模的T5上,Prompt Tuning与FFT性能持平。
- 因此,Prompt Tuning在大参数规模的模型上,更具成本效率优势。

2.Introduction(介绍)
-
背景技术1:论文中提到的Prompt Design可以理解为大家耳熟能详的提示词及提示词工程。
- 经过工程实践,大家都知道提示词工程有一定的效果,但效果远不及FFT。为什么呢?论文中总结了提示词工程的两个短板:the discrete space of words(离散空间的单词)和requires human involvement(人类的投入)。
- the discrete space of words(离散空间的单词):提示词工程中的提示词是数学意义上的离散,大语言模型不能很好地学习其隐含的特征。隐含特征不是提示词内容本身的显式特征,而是诸如提示词的句式、问法、潜台词等隐式特征。业界针对提取离散空间词汇也提出了一些算法(如:a search algorithm over the discrete space of words),但效果也非常限。
- requires human involvement(人类的投入):提示词工程依赖有经验的提示词工程师,针对不同下游任务设计提示词,工作量巨大,并且对大模型推理能力的提升又极其有限。
-
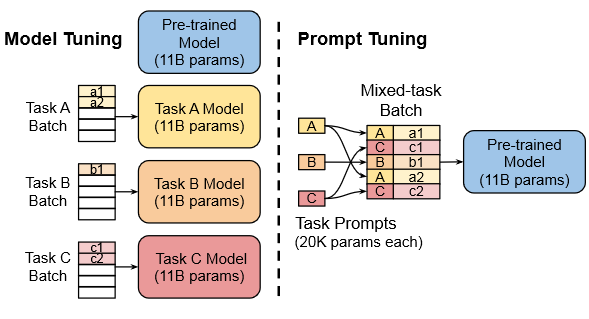
背景技术2:论文中提到的Model Tuning和Model Tuning(Multi Task),可以理解为FFT。
- Model Tuing(Multi Task):Model Tuning(Multi Task)是针对每个下游任务都微调出一个大模型,而Model Tuning是将N个下游任务都微调到一个大模型中。
-
Prompt Tuning的核心思想:
- 统一下游任务的数据格式:论文中提到
an additional k tunable tokens per downstream task to be prepended to the input text,就是为了达成统一下游任务的数据格式。如:['[CLS]’, ‘中’, ‘国’, ‘的’, ‘春’, ‘节’, ‘是’, ‘[MASK]’, ‘[MASK]’, ‘。’, ‘[SEP]']。 - 合并下游任务的数据集合:当我们统一了下游任务的数据格式,就可以将这些下游任务数据集合混合在一起。
- LLM具备学习数据集合隐式特征的能力:论文假设LLM是具备学习上述数据格式隐式特征的能力,并通过实验验证了这个假设。
- Prompt Tuning的本质:该技术的本质是LLM的核心能力之一就是提特征。如果特征很明显,LLM就可以低成本提取。如果特征很隐晦,LLM无法低成本提取、甚至无法提取,Prompt Tuning就是改变数据集,将隐式特征转为显式特征。
- 统一下游任务的数据格式:论文中提到
- 实验效果:
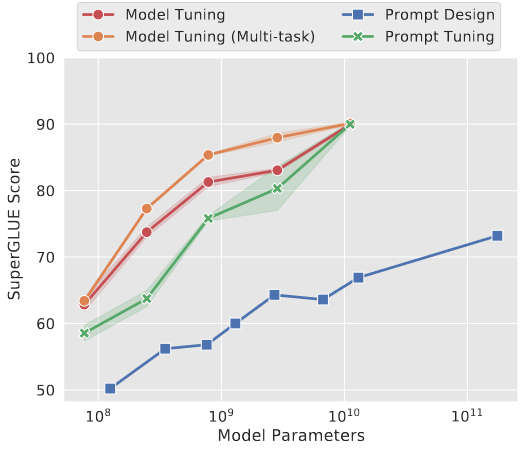
- 在小规模T5模型上,提示词工程效果最差、FFT效果最好、Promp Tuning效果中等。
- 在大规模T5模型上,Promp Tuing效果与FFT持平。
- 因此,在大规模模型上,Promp Tuning具备巨大的成本优势。
3.Design Decisions(实验设计)
(1)下游任务数据格式归一化的理论基础
论文的实验对象是T5,因为T5有一个有趣的观点:
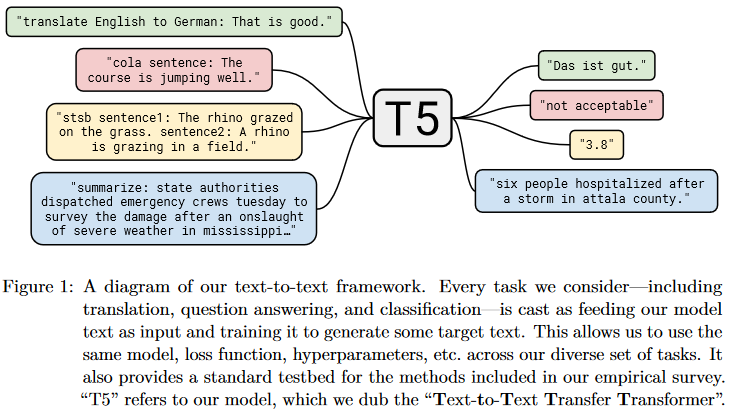
- Following the “text-to-text” approach of T5 (Raffelet al., 2020), we cast all tasks as text generation:所有的下游任务都可以等效于文本生成。这个观点就可以支撑Prompt Tuning将所有下游任务的训练数据格式统一起来。
- 如:翻译下游任务,可以将训练数据构造为:“translate English to German: hello world!”
- 如:摘要下游任务,可以将训练数据构造为:“summarize: xxxxxxxxxxxxxxxxxxx”
(2)问题建模
论文对问题进行了数学建模:
- Prθ(Y|X):在不同下游任务的训练数据可归一化的前提下,大语言模型可被建模为Prθ(Y|X),X是用户输入的Tokens,Y是在X发生的概率下模型的输出。
- Prompt Design的短板:提示词工程需要人类不断尝试寻找出合适提示词,这种不断尝试方法可能是人工寻找的,也可能采用了非可微的搜索方法(如:前文提到的a search algorithm over the discrete space of words)。
- Prθ;θP (Y|[P; X]):这个公式表达了Prompt Tuning的核心思想——在训练数据中植入特殊Token,大模型除了学习训练数据中的显式特征外,还能学习Prompt形式训练数据的隐式特征。对于Prompt隐式特征的学习最终影响的不是预训练模型的参数θ,而是在修正θP。
- [Pe; Xe] ∈ R(p+n)×e:Prompt中的普通标记被大模型嵌入后得到Xe(e是向量空间的维度),Prompt中的特殊标记被大模型嵌入后得到Pe(e是向量空间的维度)。[Pe; Xe]则表示输入给大模型后续神经网络层的高维向量。训练的影响并不会修正Xe关联的模型参数,只会修正Pe关联的模型参数。


因此,实验的关注点如下:
- Pe的初始值:和Prefix Tuning一样,都需要关注软提示的初始值,以提升训练速度和效果。
- Pe的长度:和Prefix Tuning一样,也需要关注软提示的长度,以降低训练成本。
- Prompt Tuning的参数成本=E*P:E是普通标记的向量维数,P是特殊标记的长度。
(3)如何消减特殊标记的影响
由于增加了特殊标记,大模型学习的内容就不再是原汁原味的"人类自然语言"了。这样就可能导致大模型无法用自然语言作答——这就好像你在训练大模型鸟语但又期待它能说人话、你在用中文教英语最后学会的是Chinglish。
论文中提出了**Span Corruption(跨度损失)**的概念:
- Span Corruption(跨度损失):比如,训练数据
Thank you [X] me to your party [Y] week, 、[Y]就是特殊标记,将这种特殊标记植入自然语言的目的是"问题模式等隐式特征的显性化”,但弊端就是让大语言模型学会了非人类的自然语言。 - 论文提出了三种解决方法:
- Span Corruption法:啥都不做,任由大语言模型输出特殊标记,忽略这种影响。
- Span Corruption+Sentinel法:在大语言模型中增加Sentinel,一定程度地降低这种影响。
- LM Adaptation法:采用Raffel提出的一个小模型,纠正大语言模型输出特殊标记的倾向,最终输出纯粹的自然语言。

4.Experiments(实验结果)
4.1.实验结果
论文阐述了详细的实验过程、实验数据,最终的实验结果如前文所述:
- 在小规模T5模型上,提示词工程效果最差、FFT效果最好、Promp Tuning效果中等。
- 在大规模T5模型上,Promp Tuing效果与FFT持平。
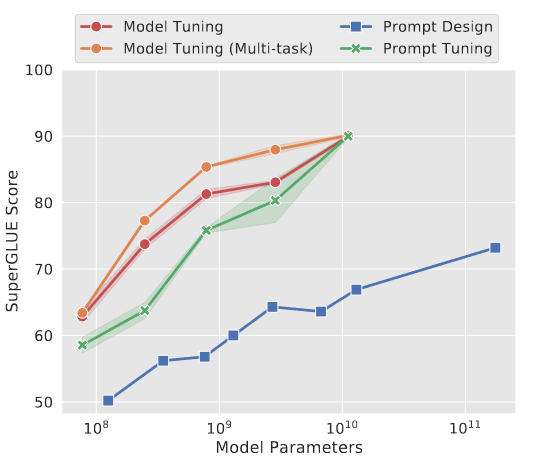
- 当模型规模逐渐变大,Promp Tuning涉及的参数相较于Prefix Tuning更少,但微调效果持平,因此Prompt Tuning具备巨大的成本优势。
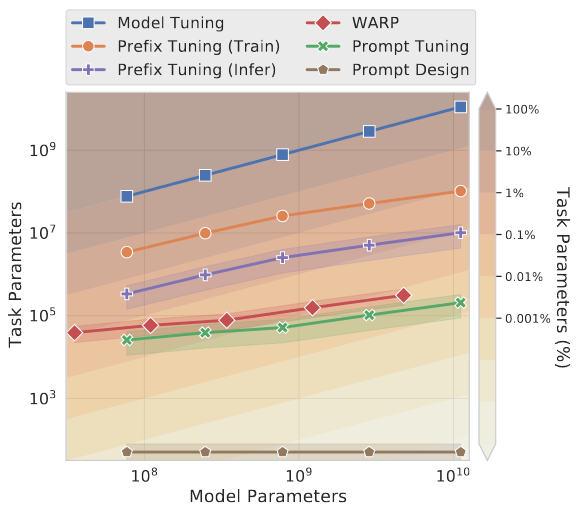
4.2.重要发现
论文在前述实验结果下,有如下重要发现:
论文从可解释性方面发现了语义聚合现象,进一步证明了Prompt形式的数据更有利于大语言模型学习其隐式特征:
- 语义聚合现象:观测被大语言模型嵌入后的特殊标记和普通标记,可以发现出现了物以类聚的现象:
- 如:Technology / technology / Technologies / technological / technologies相关的训练数据,向量相似度发生了语义聚合。
- 语义聚合的出现,说明了大语言模型学习到了Prompt形式的训练数据中的隐式特征,因此可以举一反三地处理为见过的下游任务相关输入。
论文还证明了Prompt Ensembling(提示集成能力):
- 基于Prompt Tuning的技术思想,可以做到数据格式统一、不同下游任务的训练数据混合训练,进而达到”一个大模型支持多种不同下游任务"。
- 这种思想可以在超大规模的模型上极大地降低训练成本、使用成本。
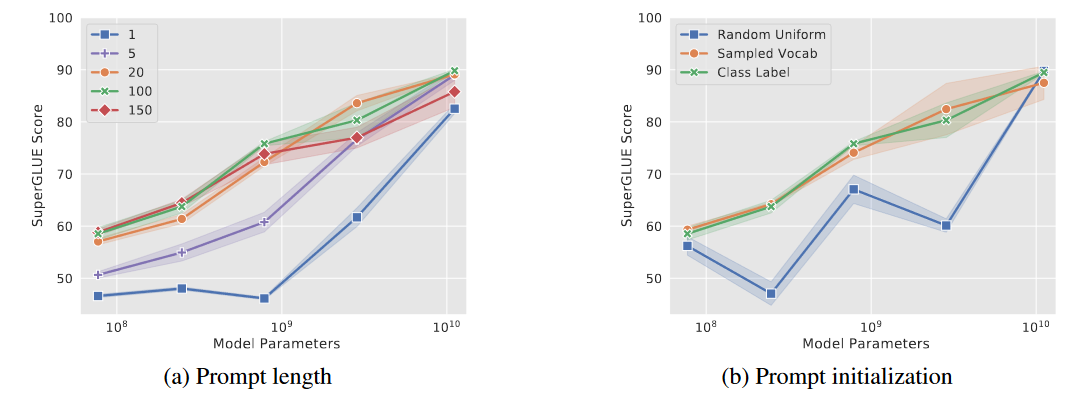
在工程实践方面,论文也给出了Prompt长度、Prompt初始值的相关推荐:
-
Prompt长度的影响:
- 在中小参数规模的模型上,Prompt长度越长,提示效果越好,但过犹不及(实验长度的临界值是150)——超过了一定的阈值,就会出现推理性能下降。
- 在大参数规模的模型上,Prompt长度反而没有什么影响了。
-
Prompt的初始值选择的影响:随机初始化Prompt的效果远差于用下游任务相关联提示词做初始值的效果。
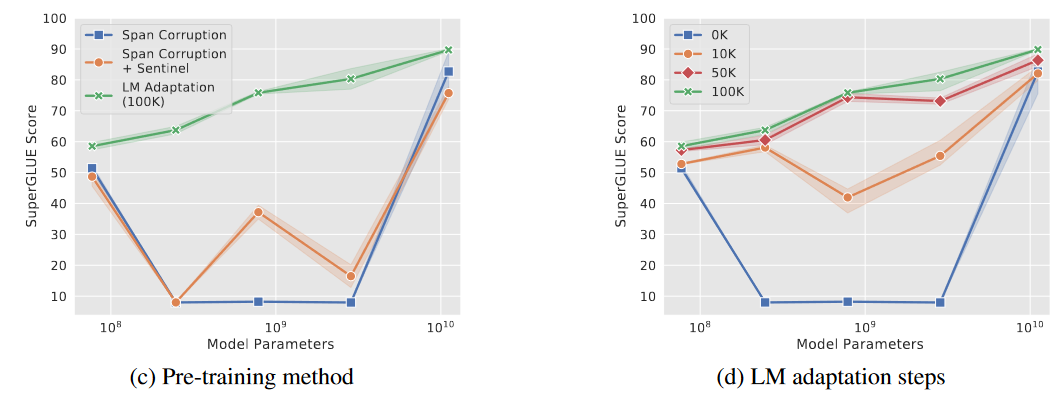
最后,论文还通过消融实验,补充了消减Span Corruption的建议:
- LM Adaptation:在中小规模模型上,采用LM Adaptation,对大语言模型的纠正效果更好。LM Adaptation增加步数会达到更好的纠正效果。
- 在大规模模型上,Span Corruption的影响也可以忽略不计了。
4.3 示例代码
第一步,引进必要的库,如:Prompt Tuning 配置类 PromptTuningConfig。
from peft import get_peft_config, get_peft_model, PromptTuningInit, PromptTuningConfig, TaskType, PeftType
第二步,创建 Prompt Tuning 微调方法对应的配置。
peft_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM,
prompt_tuning_init=PromptTuningInit.TEXT,
num_virtual_tokens=8,
prompt_tuning_init_text="Classify if the tweet is a complaint or not:",
tokenizer_name_or_path=model_name_or_path,
)
参数说明:
- prompt_tuning_init:提示嵌入的初始化方法。PEFT支持文本(TEXT)和随机(RANDOM)初始化。在原理篇中提到过 Prompt token 的初始化方法和长度对于模型性能有影响。与随机初始化和使用样本词汇表初始化相比,Prompt Tuning 采用类标签初始化模型的效果更好。不过随着模型参数规模的提升,这种gap最终会消失。因此,如果需要使用类标签和样本词汇表初始化需指定为TEXT。
- prompt_tuning_init_text:用于初始化提示嵌入的文本,在使用文本(TEXT)初始化方法时使用。
- task_type:指定任务类型。如:条件生成任务(SEQ_2_SEQ_LM),因果语言建模(CAUSAL_LM)等。
- num_virtual_tokens:指定虚拟Token数。在原理篇中,提到过提示虚拟 Token 的长度在20左右时的表现已经不错(超过20之后,提升Prompt token长度,对模型的性能提升不明显了);同样的,这个gap也会随着模型参数规模的提升而减小(即对于超大规模模型而言,即使提示虚拟 Token 长度很短,对性能也不会有太大的影响)。
第三步,通过调用 get_peft_model 方法包装基础的 Transformer 模型。
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
通过 print_trainable_parameters 方法可以查看可训练参数的数量(仅为8,192)以及占比(仅为0.00146%)。
trainable params: 8,192 || all params: 559,222,784 || trainable%: 0.0014648902430985358
Prompt Tuning 模型类结构如下所示:
PeftModelForCausalLM(
(base_model): BloomForCausalLM(
(transformer): BloomModel(
(word_embeddings): Embedding(250880, 1024)
(word_embeddings_layernorm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(h): ModuleList(
...
)
(ln_f): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=1024, out_features=250880, bias=False)
)
(prompt_encoder): ModuleDict(
(default): PromptEmbedding(
(embedding): Embedding(8, 1024)
)
)
(word_embeddings): Embedding(250880, 1024)
)
从模型类结构可以看到,Prompt Tuning 只在输入层加入 prompt virtual tokens,其他地方均没有变化,具体可查看 PromptEmbedding 的源码。
class PromptEmbedding(torch.nn.Module):
def __init__(self, config, word_embeddings):
super().__init__()
total_virtual_tokens = config.num_virtual_tokens * config.num_transformer_submodules
# 初始化 embedding 层
self.embedding = torch.nn.Embedding(total_virtual_tokens, config.token_dim)
# 如果使用文本进行初始化,执行如下逻辑,PromptTuningConfig 配置类需要传入初始化文本。
if config.prompt_tuning_init == PromptTuningInit.TEXT:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(config.tokenizer_name_or_path)
init_text = config.prompt_tuning_init_text
init_token_ids = tokenizer(init_text)["input_ids"]
# Trim or iterate until num_text_tokens matches total_virtual_tokens
num_text_tokens = len(init_token_ids)
if num_text_tokens > total_virtual_tokens:
init_token_ids = init_token_ids[:total_virtual_tokens]
elif num_text_tokens < total_virtual_tokens:
num_reps = math.ceil(total_virtual_tokens / num_text_tokens)
init_token_ids = init_token_ids * num_reps
init_token_ids = init_token_ids[:total_virtual_tokens]
word_embedding_weights = word_embeddings(torch.LongTensor(init_token_ids)).detach().clone()
word_embedding_weights = word_embedding_weights.to(torch.float32)
# 初始化embedding层的权重
self.embedding.weight = torch.nn.Parameter(word_embedding_weights)
def forward(self, indices):
# Just get embeddings
prompt_embeddings = self.embedding(indices)
return prompt_embeddings
第四步,模型训练的其余部分均无需更改,当模型训练完成之后,保存高效微调部分的模型权重以供模型推理即可。
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)
输出的模型权重文件如下所示:
/data/nfs/llm/model/bloomz-560m_PROMPT_TUNING_CAUSAL_LM
├── [ 500] adapter_config.json
├── [ 33K] adapter_model.bin
└── [ 111] README.md
0 directories, 3 files
注意:这里只会保存经过训练的增量 PEFT 权重。其中,adapter_config.json 为 Prompt Tuning 配置文件;adapter_model.bin 为 Prompt Tuning 权重文件。
第五步,加载微调后的权重文件进行推理。
from peft import PeftModel, PeftConfig
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
# 加载PEFT配置
config = PeftConfig.from_pretrained(peft_model_id)
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
# 加载PEFT模型
model = PeftModel.from_pretrained(model, peft_model_id)
# Tokenizer编码
inputs = tokenizer(f'{text_column} : {dataset["test"][i]["Tweet text"]} Label : ', return_tensors="pt")
# 模型推理
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_new_tokens=10,
eos_token_id=3
)
# Tokenizer 解码
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
至此,我们完成了Prompt Tuning的训练及推理。
5.总结
从上述论文解读中,我们收获了如下技术观点:
- Prompt Tuning的价值:追求一套预训练模型,搞定多个下游任务。
- Prompt Tuning的核心思想:通过归一化不同下游任务的训练数据,并将隐式特征显性化,帮助大语言模型学习。
- Prefix Tuning的工程实践经验:
- Prompt形式的训练数据有助于LLM学习隐式特征。
- 采用Prompt Tuning可用一套模型搞定多个下游任务。
- 对于大规模参数的模型,Prompt长度和初始化影响很小。
- 对于中小规模参数的模型,Prompt长度和初始值可参考Prefix Tuning的实践。
论文链接:https://arxiv.org/pdf/2104.08691.pdf
更多推荐


 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)