
多语言模型微调统一框架 LlAMAFACTORY: 统一高效微调100多种语言模型
高效微调对于将大型语言模型(LLMs)适应下游任务至关重要。然而,在不同模型上实施这些方法需要付出相当大的努力。我们提出了LLAMAFACTORY,这是一个统一的框架,集成了一套尖端的高效训练方法。它允许用户通过内置的Web UI LLAMABOARD 灵活定制100多种LLMs的微调,无需编码。我们在语言建模和文本生成任务上经验性地验证了我们框架的效率和有效性。该框架已在发布,并已获得超过13,
文章目录
演示视频:https://youtu.be/W29FgeZEpus
Github链接:https://github.com/hiyouga/LLaMA-Factory
摘要
高效微调对于将大型语言模型(LLMs)适应下游任务至关重要。然而,在不同模型上实施这些方法需要付出相当大的努力。我们提出了LLAMAFACTORY,这是一个统一的框架,集成了一套尖端的高效训练方法。它允许用户通过内置的Web UI LLAMABOARD 灵活定制100多种LLMs的微调,无需编码。我们在语言建模和文本生成任务上经验性地验证了我们框架的效率和有效性。该框架已在https://github.com/hiyouga/LLaMA-Factory发布,并已获得超过13,000颗星和1,600个分支。
1 引言
大型语言模型(LLMs)(Zhao等,2023)具有出色的推理能力,为一系列应用提供支持,如问答(Jiang等,2023b)、机器翻译(Wang等,2023c;Jiao等,2023a)和信息提取(Jiao等,2023b)。随后,大量LLMs通过开源社区开发并可供使用。例如,Hugging Face的开放LLM排行榜(Beeching等,2023)拥有超过5,000个模型,为希望利用LLMs强大功能的个人提供了便利。
在有限资源下微调极其庞大数量的参数成为将LLM适应下游任务的主要挑战。一种流行的解决方案是高效微调(Houlsby等,2019;Hu等,2022;Ben Zaken等,2022;Dettmers等,2023;Zhao等,2024),它在适应各种任务时降低了LLMs的训练成本。然而,社区为高效微调LLMs贡献了各种方法,缺乏一个系统框架,将这些方法调整和统一应用于不同的LLMs,并为用户定制提供友好界面。
为解决上述问题,我们开发了LLAMAFACTORY,一个使LLMs微调民主化的框架。它通过可扩展的模块统一了各种高效微调方法,使用户能够以最小资源和高吞吐量微调数百种LLMs。此外,它简化了常用的训练方法,包括生成式预训练(Radford等,2018)、监督微调(SFT)(Wei等,2022)、从人类反馈中的强化学习(RLHF)(Ouyang等,2022)和直接偏好优化(DPO)(Rafailov等,2023)。用户可以利用命令行或Web界面定制和微调他们的LLMs,几乎不需要编码。
LLAMAFACTORY由三个主要模块组成:模型加载器、数据处理器和训练器。我们最小化这些模块对特定模型和数据集的依赖,使框架能够灵活扩展到数百种模型和数据集。具体来说,我们首先建立一个模型注册表,模型加载器可以通过识别确切的层精确地附加适配器到预训练模型。然后,我们开发了一个数据描述规范,允许数据处理器通过对齐相应列来收集数据集。此外,我们提供了高效微调方法的即插即用实现,使训练器可以通过替换默认方法来激活。我们的设计允许这些模块在不同的训练方法中重复使用,大大降低了新方法的集成成本。
LLAMAFACTORY采用PyTorch(Paszke等,2019)实现,并受益于开源库,如Transformers(Wolf等,2020)、PEFT(Mangrulkar等,2022)和TRL(von Werra等,2020)。在此基础上,我们提供了一个更高层次的抽象框架。此外,我们使用Gradio(Abid等,2019)构建了LLAMABOARD,使用户能够无需编码就能进行LLMs的微调。
表1:LLAMAFACTORY中的高效微调技术。兼容的技术标记为 ✓ \checkmark ✓,不兼容的标记为 X \boldsymbol{X} X。
| 冻结微调 | GaLore | LoRA | DoRA | |
|---|---|---|---|---|
| 混合精度 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
| 检查点 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
| 闪存注意力 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
| S 2 S^{2} S2注意力 | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
| 量化 | X X X | X X X | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
| Unsloth | X X X | X X X | ✓ \checkmark ✓ | X X X |
LLAMAFACTORY采用Apache-2.0许可证开源。它在GitHub上已获得超过13,000颗星和1,600个分支[1],并且数百个开源模型已基于LLAMAFACTORY构建在Hugging Face Hub上[2]。例如,著名的GemSUra-7B(Nguyen等,2024)是基于LLAMAFACTORY构建的,首次揭示了Gemma(Mesnard等,2024)的跨语言能力。此外,数十项研究利用我们的框架探索LLMs中的新方法,如Wang等(2023a);Yu等(2023);Bhardwaj等(2024)。
2 高效微调技术
高效LLM微调技术可以分为两大类:一类专注于优化,另一类旨在减少计算。高效优化技术的主要目标是在保持成本最低的情况下调整LLMs的参数。另一方面,高效计算方法旨在减少LLMs所需计算的时间或空间。LLAMAFACTORY中包含的方法列在表1中。我们将介绍这些高效微调技术,并展示将它们纳入我们框架中所实现的显著效率提升。
2.1 高效优化
首先,我们概述了LLAMAFACTORY中使用的高效优化技术。冻结微调方法(Houlsby等,2019)涉及在微调少数解码器层的小子集中微调剩余参数时冻结大部分参数。另一种称为梯度低秩投影(GaLore)(Zhao等,2024)的方法将梯度投影到低维空间,以内存高效的方式促进全参数学习。相反,低秩适应(LoRA)(Hu等,2022)方法冻结所有预训练权重,并在指定层引入一对可训练的低秩矩阵。与量化结合,这种方法被称为QLoRA(Dettmers等,2023),进一步减少了内存使用。权重分解低秩适应(DoRA)(Liu等,2024)方法将预训练权重分解为幅度和方向组件,仅在方向组件上应用LoRA以增强LLMs的微调。LoRA+(Hayou等,2024)旨在克服LoRA的次优性。
2.2 高效计算
在LLAMAFACTORY中,我们整合了一系列高效计算技术。常用的技术包括混合精度训练(Micikevicius等,2018)和激活检查点(Chen等,2016)。从注意力层的输入输出(IO)开销的检查中获得启示,闪存注意力(Dao等,2022)引入了一种硬件友好的方法来增强注意力计算。 S 2 S^{2} S2注意力(Chen等,2024b)解决了在块稀疏注意力中扩展上下文的挑战,从而减少了微调长上下文LLMs的内存使用。各种量化策略(Dettmers等,2022a;Frantar等,2023;Lin等,2023;Egiazarian等,2024)通过使用较低精度表示减少了大型语言模型(LLMs)的内存需求。然而,量化模型的微调仅限于基于适配器的技术,如LoRA(Hu等,2022)。Unsloth(Han和Han,2023)结合Triton(Tillet等,2019)实现了LoRA的反向传播,从而减少了梯度下降过程中的浮点操作(FLOPs),加快了LoRA的训练。
LLAMAFACTORY将这些技术有效地结合成一个统一的结构,极大地提升了LLM微调的效率。这将使内存占用从混合精度训练(Micikevicius等,2018)每个参数18字节或bfloat16训练(Le Scao等,2022)每个参数8字节降至仅0.6字节每个参数。我们将在接下来的部分详细介绍我们的框架。

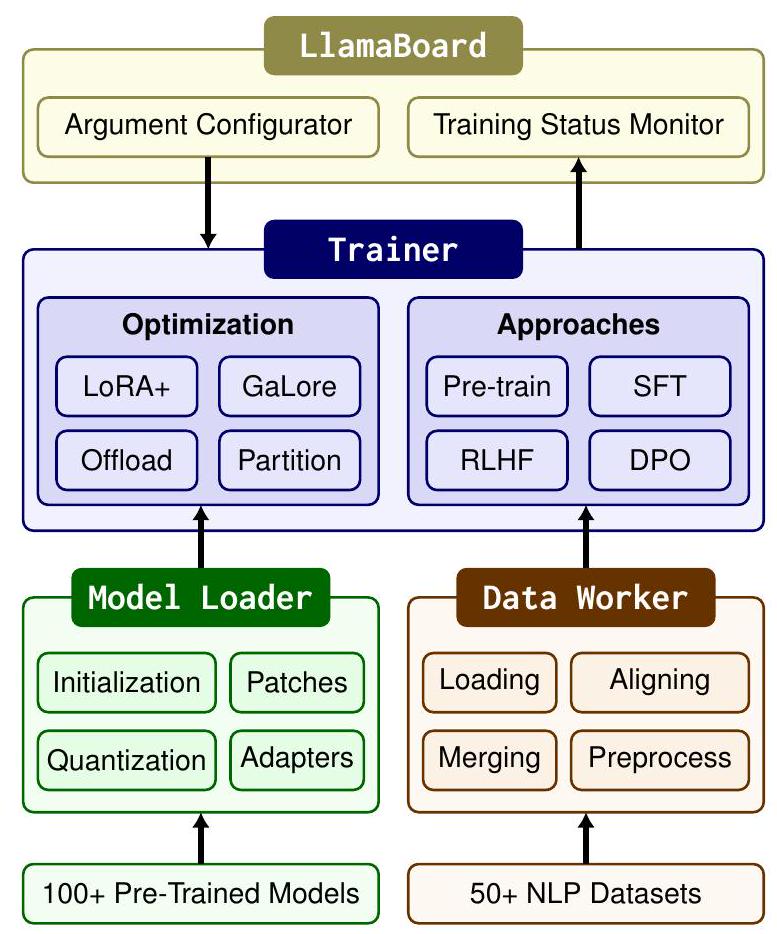
图1:LLAMAFACTORY的架构。
3 LlAMAFACtORY框架
LLAMAFACTORY由三个主要模块组成:模型加载器、数据处理器和训练器。模型加载器为微调准备各种架构,支持超过100种LLMs。数据处理器通过一个精心设计的管道处理来自不同任务的数据,支持50多个数据集。训练器统一了高效微调方法,以适应不同任务和数据集上的这些模型,提供四种训练方法。LLAMABOARD为上述模块提供了友好的可视界面,使用户能够以无需编码的方式配置和启动单个LLM微调过程,并实时监控训练状态。我们在图1中展示了LLAMAFACTORY的整体架构。
3.1 模型加载器
模型初始化 我们使用了 Transformers 的 AutoModel API(Wolf 等,2020)来加载模型并初始化参数。为了使我们的框架与不同的模型架构兼容,我们建立了一个模型注册表来存储每个层的类型,从而更容易地利用高效的微调技术。在标记器的词汇量超过嵌入层容量的情况下,我们会调整该层的大小,并使用嘈杂均值初始化来初始化新参数。为了确定 RoPE 缩放的比例因子(Chen 等,2023),我们将其计算为输入序列最大长度与模型上下文长度的比值。
模型补丁 为了启用快闪注意力和 S 2 \mathrm{S}^{2} S2 注意力,我们使用一个 monkey patch 来替换模型的前向计算。然而,自从 Transformers 4.34.0 开始支持快闪注意力,我们使用 API 来启用快闪注意力。为了防止动态模块过度分区,我们在使用 DeepSpeed ZeRO-3(Rasley 等,2020)进行优化时,将混合专家(MoE)块设置为叶子模块。
模型量化 可以通过 bitsandbytes 库(Dettmers,2021)将模型动态量化为 8 位或 4 位,使用 LLM.int8(Dettmers 等,2022a)。对于 4 位量化,我们利用双量化和 4 位正常浮点作为 QLoRA(Dettmers 等,2023)。我们还支持对通过后训练量化(PTQ)方法量化的模型进行微调,包括 GPTQ(Frantar 等,2023)、AWQ(Lin 等,2023)和 AQLM(Egiazarian 等,2024)。请注意,我们无法直接微调量化权重;因此,量化模型仅与基于适配器的方法兼容。
适配器附加 我们通过模型注册表自动识别适当的层来附加适配器。适配器默认附加到部分层以节省内存,但将其附加到所有线性层可能会获得更好的性能(Dettmers 等,2023)。PEFT(Mangrulkar 等,2022)库提供了一种非常便捷的方式来附加适配器,如 LoRA(Hu 等,2022)、rsLoRA(Kalajdzievski,2023)和 DoRA(Liu 等,2024)。我们用 Unsloth(Han 和Han,2023)的反向计算替换 LoRA 的计算以加速。为了进行从人类反馈中的强化学习(RLHF),我们在模型上添加一个值头,即将每个标记的表示映射到一个标量的线性层。
精度适应 我们根据设备的能力处理预训练模型的浮点精度。
表2:LLAMAFACTORY 中的数据集结构。
| 纯文本 | [ { [\{ [{ “text”: “…”}, {“text”: “…”}] |
|---|---|
| 类似羊驼的数据 | [ { [\{ [{ “instruction”: “…”, “input”: “…”, “output”:“…”}] |
| ShareGPT 类似数据 | [ { [\{ [{ “conversations”: [{“from”: “human”, “value”:“…”}, {“from”: “gpt”, “value”: “…”}]}] |
| 偏好数据 | [ { [\{ [{ “instruction”: “…”, “input”: “…”, “output”:“…”}] |
| 标准化数据 | { \{ { “prompt”: [{“role”: “…”, “content”: “…”}],“response”: [{“role”: “…”, “content”: “…”}],“system”: “…”, “tools”: “…”} |
设备能力。对于 NVIDIA GPU,如果计算能力为 8.0 或更高,则使用 bfloat16 精度。否则,采用 float16。我们对 Ascend NPU 和 AMD GPU 使用 float16,对非 CUDA 设备使用 float32。请注意,使用 float16 精度加载 bfloat16 模型可能会导致溢出问题。在混合精度训练中,我们将所有可训练参数设置为 float32。然而,在 bfloat16 训练中,我们保留可训练参数为 bfloat16。
3.2 数据处理工作者
我们开发了一个数据处理流水线,包括数据集加载、数据集对齐、数据集合并和数据集预处理。它将不同任务的数据集标准化为统一格式,使我们能够在各种格式的数据集上微调模型。
数据集加载 我们利用 datasets 库(Lhoest 等,2021)加载数据,允许用户从 Hugging Face Hub 加载远程数据集,或通过脚本或文件读取本地数据集。datasets 库显著减少了数据处理过程中的内存开销,并使用 Arrow(Apache,2016)加速样本查询。默认情况下,整个数据集会下载到本地磁盘。但是,如果数据集太大无法存储,我们的框架提供数据集流式传输,可以在不下载的情况下迭代访问数据集。
数据集对齐 为了统一数据集格式,我们设计了数据描述规范来描述数据集的结构。例如,羊驼数据集有三列:指令、输入和输出(Taori 等,2023)。我们将数据集转换为与数据描述规范兼容的标准结构。表2 展示了一些数据集结构的示例。
数据集合并 统一的数据集结构为合并多个数据集提供了高效的方法。对于非流式模式的数据集,我们在训练之前简单地将它们连接起来,然后对数据集进行洗牌。然而,在流式模式下,简单地连接数据集会妨碍数据洗牌。因此,我们提供了方法来交替地从不同数据集中读取数据。
数据集预处理 LLAMAFACTORY 旨在微调文本生成模型,主要用于聊天补全。聊天模板是这些模型的关键组成部分,因为它与这些模型的遵循指令能力密切相关。因此,我们提供了数十个聊天模板,可以根据模型类型自动选择。我们应用标记器对应用聊天模板后的句子进行编码。默认情况下,我们仅在完成时计算损失,而忽略提示(Taori 等,2023)。可选地,在执行生成式预训练时,我们可以利用序列打包(Krell 等,2021)来减少训练时间,这在执行生成式预训练时会自动启用。附录 C 显示了我们模板设计的细节。
3.3 训练器
高效训练 我们将 LoRA+(Hayou 等,2024)和 GaLore(Zhao 等,2024)等最先进的高效微调方法集成到训练器中,通过替换默认组件实现。这些训练方法与训练器独立,使它们易于应用于各种任务。我们在预训练和 SFT 中使用 Transformers 的训练器(Wolf 等,2020),而在 RLHF 和 DPO 中采用 TRL 的训练器(von Werra 等,2020)。定制的数据收集器被利用来区分不同训练方法的训练器。为了匹配偏好数据的训练器的输入格式,我们在一个批次中构建 2 n 2 n 2n 个样本,其中前 n n n 个样本是已选择的示例,后 n n n 个样本是被拒绝的示例。
模型共享 RLHF 允许在消费者设备上进行 RLHF 训练对于 LLM 微调是一个有用的特性。然而,这很困难,因为 RLHF 训练需要四个不同的模型。为了解决这个问题,我们提出了模型共享 RLHF,使整个 RLHF 训练不需要超过一个预训练模型。具体来说,我们首先使用奖励建模的目标函数训练一个适配器和一个值头,使模型能够计算奖励分数。然后我们初始化另一个适配器和值头,并使用 PPO 算法(Ouyang 等,2022)对它们进行训练。在训练过程中,适配器和值头通过 PEFT(Mangrulkar 等,2022)的 set_adapter 和 disable_adapter API 动态切换,使预训练模型同时充当策略、价值、参考和奖励模型。据我们所知,这是第一个支持在消费者设备上进行 RLHF 训练的方法。
分布式训练 我们可以将上述训练器与 DeepSpeed(Rasley 等,2020)结合起来进行分布式训练。利用 DeepSpeed ZeRO 优化器,可以通过分区或卸载进一步减少内存消耗。
3.4 实用工具
加速推理 在推理时,我们从数据处理工作者那里重用聊天模板来构建模型输入。我们支持使用 Transformers(Wolf 等,2020)和 vLLM(Kwon 等,2023)对模型输出进行采样,两者都支持流式解码。此外,我们实现了一个类似 OpenAI 风格的 API,利用 vLLM 的异步 LLM 引擎和分页注意力,提供高吞吐量的并发推理服务,便于将微调的 LLM 部署到各种应用中。
全面评估 我们包括几个评估 LLM 的指标,包括多选任务,如 MMLU(Hendrycks 等,2021)、CMMLU(Li 等,2023a)和 C-Eval(Huang 等,2023),以及计算文本相似度得分,如 BLEU-4(Papineni 等,2002)和 ROUGE(Lin,2004)。
3.5 LLAMABOARD:LLAMAFACTORY 的统一界面
LLAMABOARD 是基于 Gradio(Abid 等,2019)的统一用户界面,允许用户在不编写任何代码的情况下定制 LLM 的微调。它提供了简化的模型微调和推理服务,使用户能够轻松地在实践中利用 100 多个 LLM 和 50 多个数据集。LLAMABOARD 具有以下显著特点:易于配置 LLAMABOARD 允许用户通过与 Web 界面交互来自定义微调参数。我们为许多参数提供了默认值,这些默认值适用于大多数用户,简化了配置过程。此外,用户可以在 Web UI 上预览数据集,以检查其自定义格式。
可监控的训练 在训练过程中,训练日志和损失曲线会实时可视化和更新,使用户能够监控训练进度。这一功能为分析微调过程提供了有价值的见解。
多语言支持 LLAMABOARD 提供本地化文件,方便集成新语言以渲染界面。目前我们支持三种语言:英语、俄语和中文,这使更广泛的用户可以利用 LLAMABOARD 对 LLM 进行微调。
4 实证研究
我们从两个角度系统评估了 LLAMAFACTORY:1)训练效率,包括内存使用、吞吐量和困惑度。2)适应下游任务的有效性。
4.1 训练效率
实验设置 我们利用 PubMed(Canese 和 Weis,2013)数据集,其中包含超过 3600 万条生物医学文献记录。我们从文献摘要中提取约 40 万个标记以构建训练示例。我们使用生成式预训练目标和各种高效微调方法微调 Gemma-2B(Mesnard 等,2024)、Llama2-7B 和 Llama2-13B(Touvron 等,2023b)模型。我们比较了完全微调、冻结微调、GaLore、LoRA 和 4 位 QLoRA 的结果。微调后,我们计算训练示例的困惑度,以评估不同方法的效率。我们还将预训练模型的困惑度作为基线。有关更多实验细节,请参阅附录 D.1。
结果 训练效率结果如表 3 所示,其中内存指的是训练期间消耗的内存峰值,吞吐量计算为每秒训练的标记数,PPL 表示模型在训练示例上的困惑度。由于完全微调 Llama213B 导致内存溢出,因此未记录结果。我们观察到 QLoRA 一贯具有最低的内存占用,因为预训练权重以较低精度表示。LoRA 利用 Unsloth 层中的优化,具有更高的吞吐量。GaLore 在大型模型上实现较低的 PPL,而 LoRA 在较小模型上具有优势。
表 3:使用不同微调方法比较 LLAMAFACTORY 的训练效率。每个模型中 GaLore、LoRA 和 QLoRA 中的最佳结果已加粗显示。

表 4:使用不同微调方法比较 LLAMAFACTORY 在特定任务上的性能(以 ROUGE 衡量)。每个模型的最佳结果已用下划线标记,每个任务的最佳结果已加粗显示。

4.2 下游任务微调
实验设置 为了评估不同高效微调方法的有效性,我们比较了在下游任务微调后各种模型的性能。我们使用 CNN/DM(Nallapati 等,2016)、XSum(Narayan 等,2018)和 AdGen(Shao 等,2019)三个代表性文本生成任务的 2000 个示例和 1000 个示例构建训练集和测试集。我们选择几个指令调整的模型,并使用不同的微调方法按照序列到序列任务进行微调。我们比较了完全微调(FT)、GaLore、LoRA 和 4 位 QLoRA 的结果。微调后,我们计算了每个任务的测试集上的 ROUGE 分数(Lin,2004)。我们还将原始指令调整模型的分数作为基线。有关更多实验细节,请参阅附录 D.2。
结果 下游任务的评估结果如表 4 所示。我们报告了每个 LLM 和每个数据集的 ROUGE-1、ROUGE-2 和 ROUGE-L 的平均分数。由于 GaLore 方法不适用于 Gemma-7B 模型,因此表中未包含 Gemma-7B 的一些结果。从结果中的一个有趣发现是,LoRA 和 QLoRA 在大多数情况下表现最佳,除了 Llama2-7B 和 ChatGLM3
6
B
6 \mathrm{~B}
6 B 模型在 CNN/DM 和 AdGen 数据集上表现较差。
这一现象突显了这些高效微调方法在调整 LLM 模型到特定任务上的有效性。此外,我们观察到 Mistral-7B 模型在英语数据集上表现更好,而 Qwen1.5-7B 模型在中文数据集上获得更高分数。这些结果表明,微调模型的性能也与它们在特定语言上的固有能力相关。
5 结论与未来工作
在本文中,我们展示了 LLAMAFACTORY,一个用于高效微调 LLM 的统一框架。通过模块化设计,我们最小化了模型、数据集和训练方法之间的依赖关系,并提供了一种集成方法,用于使用各种高效微调技术微调超过 100 个 LLM。此外,我们提供了一个灵活的 Web UI LLAMABOARD,可以在无需编码的情况下进行自定义微调和评估 LLM。我们在语言建模和文本生成任务上对我们的框架的效率和有效性进行了实证验证。
在未来,我们将持续将 LLAMAFACTORY 与最先进的模型和高效微调技术保持同步。我们也欢迎开源社区的贡献。在未来的版本中,我们将探索更先进的并行训练策略和 LLM 的多模态高效微调。
6 更广泛的影响和负责任的使用
LLAMAFACTORY 吸引了大量对 LLM 感兴趣的个人,探索微调自己模型的可能性。这对开源社区的增长做出了重要贡献。它正受到越来越多的关注,并被列为 Awesome Transformers 3 { }^{3} 3 中高效微调 LLM 框架的代表之一。我们预计从业者将在我们的框架上构建他们的 LLM,从而为社会带来好处。在使用 LLAMAFACTORY 进行 LLM 微调时,遵守模型许可是强制的,从而防止任何潜在的误用。
表 5:LLAMAFACTORY 与现有 LLM 微调框架的功能比较。

更多推荐

 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)