
LLMs多任务指令微调Multi-task instruction fine-tuning
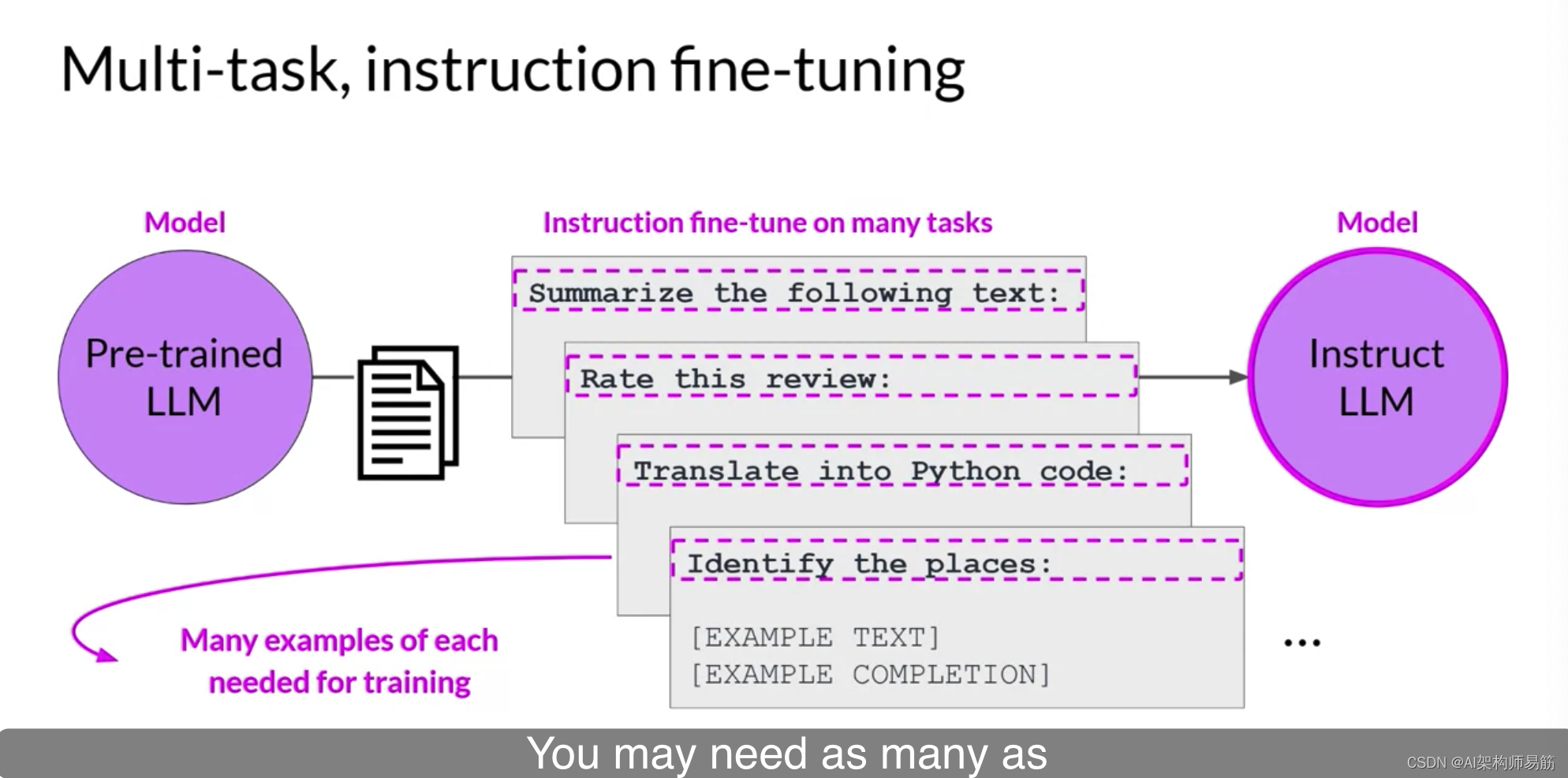
多任务微调是单任务微调的扩展,其中训练数据集包括多个任务的示例输入和输出。在这里,数据集包含指导模型执行各种任务的示例,包括摘要、评论评分、代码翻译和实体识别。您在这个混合数据集上训练模型,以便它可以同时提高模型在所有任务上的性能,从而避免灾难性遗忘的问题。经过多次迭代的训练,使用示例计算的损失用于更新模型的权重,从而产生一个已经学会如何同时擅长多种不同任务的指导模型。多任务微调的一个缺点是它需要
多任务微调是单任务微调的扩展,其中训练数据集包括多个任务的示例输入和输出。在这里,数据集包含指导模型执行各种任务的示例,包括摘要、评论评分、代码翻译和实体识别。

您在这个混合数据集上训练模型,以便它可以同时提高模型在所有任务上的性能,从而避免灾难性遗忘的问题。经过多次迭代的训练,使用示例计算的损失用于更新模型的权重,从而产生一个已经学会如何同时擅长多种不同任务的指导模型。
多任务微调的一个缺点是它需要大量的数据。您的训练集中可能需要多达50-100,000个示例。然而,组装这些数据可能是非常值得的,并且值得付出努力。由此产生的模型通常非常有能力,并适用于在多个任务上需要良好性能的情况。
让我们来看一下使用多任务指导微调训练的一系列模型。指导模型的差异基于微调期间使用的数据集和任务。一个例子是FLAN模型家族。FLAN,代表Fine-tune LAnguage Net微调语言网络,是用于微调不同模型的一组特定指令。因为他们的FLAN微调是训练过程的最后一步,所以原始论文的作者称其为预训练主菜的比喻性甜点,非常贴切的名字。

FLAN-T5是T5基础模型的FLAN指导版本,而FLAN-PALM是PLAM基础模型的FLAN版本。您

明白了,FLAN-T5是一个很好的通用指导模型。总体而言,它已经在473个数据集上进行了微调,涵盖了146个任务类别。

这些数据集是从其他模型和论文中选出的,如此处所示。现在不用担心阅读所有的细节。如果您感兴趣,您可以在视频后通过阅读练习访问原始论文,并仔细查看。
FLAN-T5用于摘要任务的一个示例提示数据集是SAMSum。它是Muffin任务和数据集的一部分,用于训练语言模型以总结对话。

SAMSum是一个包含16,000个类似信使的对话和摘要的数据集。这里显示了三个示例,对话在左边,摘要在右边。对话和摘要是由语言学家专门为生成高质量的语言模型训练数据集而设计的。

语言学家被要求创建与他们每天会写的对话类似的对话,反映了他们真实生活中信使对话的主题比例。然后,语言专家创建了包含重要信息和对话中人们名称的简短摘要。
这里是一个设计用于与这个SAMSum对话摘要数据集一起工作的提示模板。模板实际上由几个不同的指令组成,所有这些指令基本上都要求模型做同样的事情。总结一下对话。例如,
简要总结该对话。

这个对话的摘要是什么?

那次对话发生了什么?

包括说同一指令的不同方式有助于模型泛化并表现得更好。就像您之前看到的提示模板一样。您会看到,在每种情况下,SAMSum数据集中的对话都被插入到模板中,

无论对话字段出现在哪里。
摘要用作标签。

在将这个模板应用到SAMSum数据集的每一行之后,您可以用它来微调对话摘要任务。
虽然FLAN-T5是一个表现出许多任务中良好能力的通用模型,但您可能仍然会发现它在您特定用例的任务上有改进的空间。例如,假设您是一名数据科学家,正在构建一个应用程序来支持您的客户服务团队,通过聊天机器人处理接收到的请求,就像这里显示的那样。

您的客户服务团队需要每个对话的摘要,以识别客户正在请求的关键操作,并确定应采取什么行动作为回应。

SAMSum数据集赋予FLAN-T5一些总结对话的能力。然而,数据集中的示例主要是关于朋友之间关于日常活动的对话,并且与客户服务聊天中观察到的语言结构没有太多重叠。
您可以使用更接近与您的机器人发生的对话的对话数据集对FLAN-T5模型进行额外的微调。这正是您将在本周的实验室中探索的准确场景。
您将使用一个名为dialogsum的额外领域特定摘要数据集来提高FLAN-T5对总结支持聊天对话的能力。这个数据集包括超过13,000个支持聊天对话和摘要。

dialogsum数据集不是FLAN-T5训练数据的一部分,所以模型以前没有看到这些对话。
让我们来看一个来自dialogsum的例子,并讨论进一步微调如何改善模型。这是一个典型的dialogsum数据集中的示例,对话是在酒店前台与客户和工作人员之间进行的。聊天已经应用了一个模板,以便在文本开始时包括总结对话的指令。

现在,让我们看看在没有进行任何额外微调之前,FLAN-T5对这个提示的反应是什么,注意现在提示在左边被压缩了,以便您有更多的空间来检查模型的完成。这是模型对指令的反应。您可以看到,模型能够识别出对话是关于Tommy的预订。

然而,它没有像人工生成的基线摘要那样做得好,其中包括了重要信息,比如Mike要求提供便于办理入住的信息,

而模型的完成还发明了原始对话中没有包括的信息。具体来说,酒店的名字

和它所在的城市。

现在,让我们看看模型在对dialogsum数据集进行微调后的表现如何,希望您会同意,这更接近人工生成的摘要。没有捏造的信息,摘要包括所有重要的细节,包括参与对话的两个人的名字。

这个例子使用公共dialogsum数据集来演示在自定义数据上进行微调。
在实践中,通过使用您公司自己的内部数据进行微调,您将获得最大的收益。

例如,来自您的客户支持应用程序的支持聊天对话。这将帮助模型学习您的公司如何喜欢总结对话以及对您的客户服务同事最有用的是什么。
我知道这里有很多东西需要消化。但不用担心,这个例子将在实验室中进行讲解。您将有机会亲自看到这一切并尝试一下。
微调时您需要考虑的一件事是如何评估您的模型完成的质量。在下一个视频中,您将了解几种可以用来确定您的模型表现如何以及您的微调版本比原始基础模型好多少的指标和基准。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/notob/multi-task-instruction-fine-tuning
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)