
大模型微调的常见方法总结(非常详细)零基础入门到精通,收藏这一篇就够了
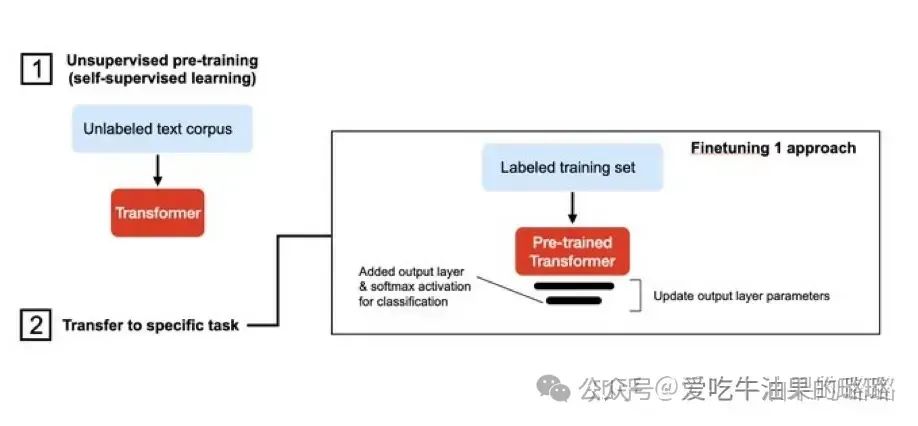
微调是指调整大型语言模型(LLM)的参数以适应特定任务的过程。这是通过在与任务相关的数据集上训练模型来完成的。所需的微调量取决于任务的复杂性和数据集的大小。在深度学习中,微调是一种重要的技术,用于改进预训练模型的性能。除了微调ChatGPT之外,还有许多其他预训练模型可以进行微调。大模型微调如上文所述有很多方法,并且对于每种方法都会有不同的微调流程、方式、准备工作和周期。
前言
微调是指调整大型语言模型(LLM)的参数以适应特定任务的过程。这是通过在与任务相关的数据集上训练模型来完成的。所需的微调量取决于任务的复杂性和数据集的大小。
在深度学习中,微调是一种重要的技术,用于改进预训练模型的性能。除了微调ChatGPT之外,还有许多其他预训练模型可以进行微调。
PEFT是什么
PEFT(Parameter-Efficient Fine-Tuning)是hugging face开源的一个参数高效微调大模型的工具,里面集成了4种微调大模型的方法,可以通过微调少量参数就达到接近微调全量参数的效果,使得在GPU资源不足的情况下也可以微调大模型。
微调方法
微调可以分为全微调和重用两个方法:
-
全微调(Full Fine-tuning):全微调是指对整个预训练模型进行微调,包括所有的模型参数。在这种方法中,预训练模型的所有层和参数都会被更新和优化,以适应目标任务的需求。这种微调方法通常适用于任务和预训练模型之间存在较大差异的情况,或者任务需要模型具有高度灵活性和自适应能力的情况。Full Fine-tuning需要较大的计算资源和时间,但可以获得更好的性能。
-
部分微调(Repurposing):部分微调是指在微调过程中只更新模型的顶层或少数几层,而保持预训练模型的底层参数不变。这种方法的目的是在保留预训练模型的通用知识的同时,通过微调顶层来适应特定任务。Repurposing通常适用于目标任务与预训练模型之间有一定相似性的情况,或者任务数据集较小的情况。由于只更新少数层,Repurposing相对于Full Fine-tuning需要较少的计算资源和时间,但在某些情况下性能可能会有所降低。
微调预训练模型的方法:
-
微调所有层:将预训练模型的所有层都参与微调,以适应新的任务。
-
微调顶层:只微调预训练模型的顶层,以适应新的任务。
-
冻结底层:将预训练模型的底层固定不变,只对顶层进行微调。
-
逐层微调:从底层开始,逐层微调预训练模型,直到所有层都被微调。
-
迁移学习:将预训练模型的知识迁移到新的任务中,以提高模型性能。这种方法通常使用微调顶层或冻结底层的方法。
Fine tuning
经典的Fine tuning方法包括将预训练模型与少量特定任务数据一起继续训练。在这个过程中,预训练模型的权重被更新,以更好地适应任务。所需的Fine-tuning量取决于预训练语料库和任务特定语料库之间的相似性。如果两者相似,可能只需要少量的Fine tuning。如果两者不相似,则可能需要更多的Fine tuning。

Prompt Tuning(P-tuning)
Prompt Tuning 是2021年谷歌在论文《The Power of Scale for Parameter-Efficient Prompt Tuning》中提出的微调方法。参数高效性微调方法中实现最简单的方法还是Prompt tuning(也就是我们常说的P-Tuning),固定模型前馈层参数,仅仅更新部分embedding参数即可实现低成本微调大模型。

经典的Prompt tuning方式不涉及对底层模型的任何参数更新。相反,它侧重于精心制作可以指导预训练模型生成所需输出的输入提示或模板。主要结构是利用了一个prompt encoder(BiLSTM+MLP),将一些pseudo prompt先encode(离散token)再与input embedding进行拼接,同时利用LSTM进行 Reparamerization 加速训练,并引入少量自然语言提示的锚字符(Anchor,例如Britain)进一步提升效果。然后结合(capital,Britain)生成得到结果,再优化生成的encoder部分。

但是P-tuning v1有两个显著缺点:任务不通用和规模不通用。在一些复杂的自然语言理解NLU任务上效果很差,同时预训练模型的参数量不能过小。具体的效果论文中提到以下几点:
-
Prompt 长度影响:模型参数达到一定量级时,Prompt 长度为1也能达到不错的效果,Prompt 长度为20就能达到极好效果。
-
Prompt初始化方式影响:Random Uniform 方式明显弱于其他两种,但是当模型参数达到一定量级,这种差异也不复存在。
-
预训练的方式:LM Adaptation 的方式效果好,但是当模型达到一定规模,差异又几乎没有了。
-
微调步数影响:模型参数较小时,步数越多,效果越好。同样随着模型参数达到一定规模,zero shot 也能取得不错效果。
-
当参数达到100亿规模与全参数微调方式效果无异。
代码示例:
from peft import PromptTuningConfig, get_peft_model
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
Prefix Tuning
2021年论文《Prefix-Tuning: Optimizing Continuous Prompts for Generation》中提出了 Prefix Tuning 方法。与Full-finetuning 更新所有参数的方式不同,该方法是在输入 token 之前构造一段任务相关的 virtual tokens 作为 Prefix,然后训练的时候只更新 Prefix 部分的参数,而 Transformer 中的其他部分参数固定。
prefix-tuning技术,相对于fine-tuning,在调节模型的过程中只优化一小段可学习的continuous task-specific vector(prefix)而不是整个模型的参数。该方法其实和构造 Prompt 类似,只是 Prompt 是人为构造的“显式”的提示,并且无法更新参数,而Prefix 则是可以学习的“隐式”的提示。手动尝试最优的提示无异于大海捞针,于是便有了自动离散提示搜索的方法,但提示是离散的,神经网络是连续的,所以寻找的最优提示可能是次优的。

代码示例:
peft_config = PrefixTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
GPT在P-tuning的加持下可达到甚至超过BERT在NLU领域的性能。下图是细致的对比:

P-tuning v2
V2版本主要是基于P-tuning和prefix-tuning技术,引入Deep Prompt Encoding和Multi-task Learning等策略进行优化的。实验表明,仅精调0.1%参数量,在330M到10B不同参数规模LM模型上,均取得和Fine-tuning相比肩的性能。

论文《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》从标题就可以看出,P-Tuning v2 的目标就是要让 Prompt Tuning 能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌 Fine-tuning 的结果。也就是说当前 Prompt Tuning 方法在这两个方面都存在局限性。
不同模型规模:Prompt Tuning 和 P-tuning 这两种方法都是在预训练模型参数规模够足够大时,才能达到和Fine-tuning 类似的效果,而参数规模较小时效果则很差。
不同任务类型:Prompt Tuning 和 P-tuning 这两种方法在 sequence tagging 任务上表现都很差。

v1到v2的可视化:蓝色部分为参数冻结,橙色部分为可训练部分,可以看到右侧的p-tuning v2中,将continuous prompt加在序列前端,并且每一层都加入可训练的prompts。在左图v1模型中,只将prompt插入input embedding中,会导致可训练的参数被句子的长度所限制。此外P-Tuning v2还包括以下改进:
-
移除了Reparamerization加速训练方式;
-
采用了多任务学习优化:基于多任务数据集的Prompt进行预训练,然后再适配的下游任务。
-
舍弃了词汇Mapping的Verbalizer的使用,重新利用[CLS]和字符标签,跟传统finetune一样利用cls或者token的输出做NLU,以增强通用性,可以适配到序列标注任务。
P-Tuning v2几个关键设计因素:
-
Reparameterization:Prefix Tuning 和 P-tuning 中都有 MLP 来构造可训练的 embedding。论文发现在自然语言理解领域,面对不同的任务以及不同的数据集,这种方法可能带来完全相反的结论。
-
Prompt Length:不同的任务对应的最合适的 Prompt Length 不一样,比如简单分类任务下 length=20 最好,而复杂的任务需要更长的 Prompt Length。
-
Multi-task Learning 多任务对于 P-Tuning v2 是可选的,但可以利用它提供更好的初始化来进一步提高性能。
-
Classification Head 使用 LM head 来预测动词是 Prompt Tuning 的核心,但我们发现在完整的数据设置中没有必要这样做,并且这样做与序列标记不兼容。P-tuning v2 采用和 BERT 一样的方式,在第一个 token 处应用随机初始化的分类头。
代码示例:
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
AdaLoRA
预训练语言模型中的不同权重参数对下游任务的贡献是不同的。因此需要更加智能地分配参数预算,以便在微调过程中更加高效地更新那些对模型性能贡献较大的参数。
具体来说,通过奇异值分解将权重矩阵分解为增量矩阵,并根据新的重要性度量动态地调整每个增量矩阵中奇异值的大小。这样可以使得在微调过程中只更新那些对模型性能贡献较大或必要的参数,从而提高了模型性能和参数效率。
代码示例:
peft_config = AdaLoraConfig(peft_type="ADALORA", task_type="SEQ_2_SEQ_LM", r=8, lora_alpha=32, target_modules=["q", "v"],lora_dropout=0.01)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
GPT4模型微调分类
1. Adapter-based Methods(基于适配器的方法):
《Parameter-Efficient Transfer Learning for NLP》提出针对 BERT 的 PEFT微调方式,拉开了 PEFT 研究的序幕。他们指出,在面对特定的下游任务时,如果进行 Full-Fintuning(即预训练模型中的所有参数都进行微调),太过低效;而如果采用固定预训练模型的某些层,只微调接近下游任务的那几层参数,又难以达到较好的效果。
于是他们设计了如下图所示的 Adapter 结构,将其嵌入 Transformer 的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的 Adapter 结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数),他们将 Adapter 设计为这样的结构:
首先是一个 down-project 层将高维度特征映射到低维特征;然后过一个非线形层之后,再用一个 up-project 结构将低维特征映射回原来的高维特征;同时也设计了 skip-connection 结构,确保了在最差的情况下能够退化为identity(类似残差结构)。
这种方法节省了资源,因为它不需要对整个模型进行微调。示例有AdapterDrop、Parallel Adapter、Residual Adapter等。

2. Prompt-based Methods(基于提示的方法):
这个分支侧重于使用连续的提示(如嵌入向量)来调整模型的行为,而不是直接修改模型的权重。这类方法通常用于生成任务,例如文本生成。提示可以视为模型输入的一部分,它们会被训练以激发模型生成特定的输出。示例包括Prefix-tuning、Prompt tuning等,参加上文介绍。
3. Low-rank Adaptation(低秩适配):
低秩适配方法致力于将模型权重的改变限制在一个低秩子空间内。这通常涉及对模型的权重矩阵进行分解,只微调其中的一小部分参数。这样可以有效减少计算资源的消耗,同时仍然允许模型有足够的灵活性来学习新任务。LoRA和它的变种,如Q-LoRA、Delta-LoRA、LoRA-FA等,都属于这个类别。
4. Sparse Methods(稀疏方法):
这个分支包括那些仅更新模型中一小部分参数的方法。这些参数被选为最有可能影响到任务性能的,而其他参数则保持不变。稀疏方法的优点在于它们通常能够更高效地利用资源。例如有Intrinsic SAID、Fish Mask、BitFit等。
5. Others(其他方法):
这一分支可能包括不易归类到上述任何一类的其他方法,或者是结合了多种技术的混合方法。这些方法可能包括特定的结构改变、算法优化等,用以提高微调过程的效率或者效果。
大模型微调步骤总结
大模型微调如上文所述有很多方法,并且对于每种方法都会有不同的微调流程、方式、准备工作和周期。然而大部分的大模型微调,都有以下几个主要步骤,并需要做相关的准备:
准备数据集:
收集和准备与目标任务相关的训练数据集。确保数据集质量和标注准确性,并进行必要的数据清洗和预处理。
选择预训练模型/基础模型:
根据目标任务的性质和数据集的特点,选择适合的预训练模型。
设定微调策略:
根据任务需求和可用资源,选择适当的微调策略。考虑是进行全微调还是部分微调,以及微调的层级和范围。
设置超参数:
确定微调过程中的超参数,如学习率、批量大小、训练轮数等。这些超参数的选择对微调的性能和收敛速度有重要影响。
初始化模型参数:
根据预训练模型的权重,初始化微调模型的参数。对于全微调,所有模型参数都会被随机初始化;对于部分微调,只有顶层或少数层的参数会被随机初始化。
进行微调训练:
使用准备好的数据集和微调策略,对模型进行训练。在训练过程中,根据设定的超参数和优化算法,逐渐调整模型参数以最小化损失函数。
模型评估和调优:
在训练过程中,使用验证集对模型进行定期评估,并根据评估结果调整超参数或微调策略。这有助于提高模型的性能和泛化能力。
测试模型性能:
在微调完成后,使用测试集对最终的微调模型进行评估,以获得最终的性能指标。这有助于评估模型在实际应用中的表现。
模型部署和应用:
将微调完成的模型部署到实际应用中,并进行进一步的优化和调整,以满足实际需求。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)